5. 배치 처리 성능 비교
지난 포스팅에서 JPA 기반 및 JDBC 기반으로 스프링 배치 처리 코드를 구현해서 테이블 복사 작업을 수행할 수 있었다. 그리고 조금 더 상세한 성능 계측을 위해 데이터 개수를 10000개로 늘이고 JUnit 테스트 코드 작성도 같이 해본다.
데이터를 최종 11000개에 준하는 개수로 늘이고 테스트를 수행해보자.
1) JPA 배치 처리 vs JDBC 배치 처리
@Slf4j
@SpringBootTest
public class JdbcJpaPerformanceTest {
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private JobLauncher jobLauncher;
@Autowired
private JobRegistry jobRegistry;
private long executeBatchJob(String jobName) throws Exception {
UUID parameter = UUID.randomUUID();
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", parameter.toString())
.toJobParameters();
Job job = jobRegistry.getJob(jobName);
long startTime = System.nanoTime();
jobLauncher.run(job, jobParameters);
long endTime = System.nanoTime();
return endTime - startTime;
}
@BeforeEach
public void setUp() {
jdbcTemplate.execute("TRUNCATE TABLE AfterEntity;");
}
@AfterEach
public void cleanup() {
jdbcTemplate.execute("TRUNCATE TABLE AfterEntity;");
}
@DisplayName("JDBC 기반 배치 처리 실행시간 < JPA 기반 배치 처리 실행시간")
@Test
public void test() throws Exception {
// given & when
long jdbcBatchExecutionTime = executeBatchJob("jdbcFirstBatchJob");
jdbcTemplate.execute("TRUNCATE TABLE AfterEntity;");
long jpaBatchExecutionTime = executeBatchJob("firstJob");
// then
assertThat(jpaBatchExecutionTime)
.describedAs(
String.format(
"JDBC Batch 실행시간: %d nanoseconds, JPA Batch 실행시간: %d nanoseconds",
jdbcBatchExecutionTime, jpaBatchExecutionTime))
.isGreaterThan(jdbcBatchExecutionTime);
}
}동일 작업에 대하여 JDBC 배치 처리와 JPA 배치 처리를 수행한다. 불필요한 객체 생성, 캐싱, 매핑 등의 과정 없이 SQL 쿼리 실행과 결과 반환에 집중하고 직접 데이터베이스와 통신하기 때문에 JDBC 배치 처리가 훨씬 빠를 것으로 예상하고 테스트 코드를 작성한 다음, 테스트를 수행했다.
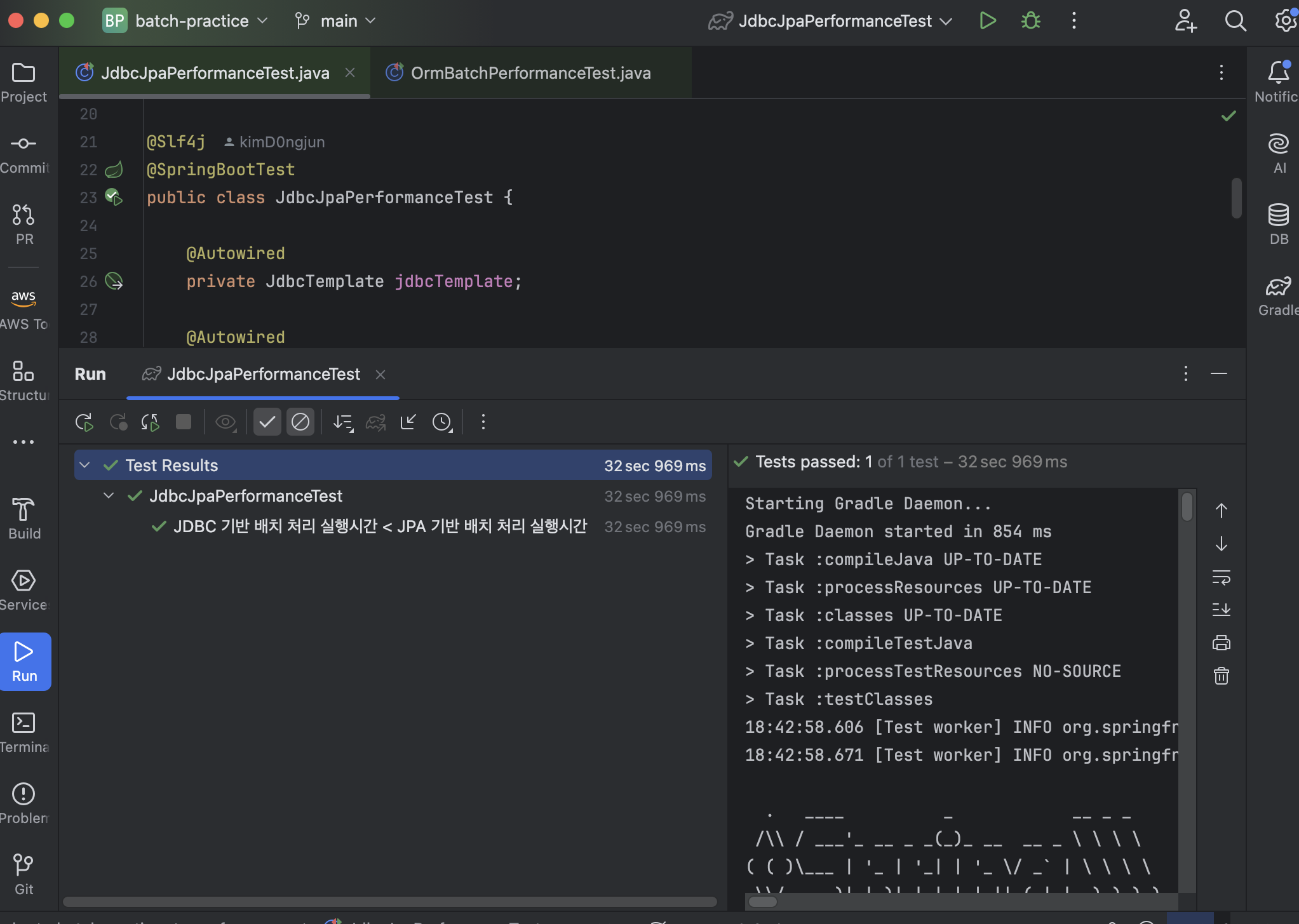
역시나 예상은 예상대로... 그래서 다음 시나리오를 구현하려다가 문득 든 궁금증
그래도 JPA 배치 처리가 JPA 기본제공 CRUD 메소드보단 빠르겠지..?
2) JPA 배치 처리 vs JPA 기본제공 메소드
JPA 기본제공 메소드를 테스트에서 활용하기 위해 JpaRepository 인터페이스 기반 두 엔티티의 DAO를 의존성 주입받아서 테스트 코드를 작성했다.
@Slf4j
@SpringBootTest
public class OrmBatchPerformanceTest {
@Autowired
private JdbcTemplate jdbcTemplate;
@Autowired
private JobLauncher jobLauncher;
@Autowired
private JobRegistry jobRegistry;
@Autowired
private BeforeJpaRepository beforeJpaRepository;
@Autowired
private AfterJpaRepository afterJpaRepository;
// JPA 기반 ORM 메소드 실행시간 계측 메소드
private long executeOrmMethod() {
long startTime = System.nanoTime();
List<BeforeEntity> beforeEntities = beforeJpaRepository.findAll();
List<AfterEntity> afterEntities =
beforeEntities.stream().map(e -> new AfterEntity(e.getUsername())).toList();
// JPA 배치 처리의 메소드 호출과 조건을 동일시하기 위한 단일 저장 반복 처리
for (AfterEntity afterEntity : afterEntities) {
afterJpaRepository.save(afterEntity);
}
long endTime = System.nanoTime();
return endTime - startTime;
}
// JPA 기반 배치 처리 실행시간 계측 메소드
private long executeBatchJob() throws Exception {
UUID parameter = UUID.randomUUID();
JobParameters jobParameters = new JobParametersBuilder()
.addString("date", parameter.toString())
.toJobParameters();
Job job = jobRegistry.getJob("firstJob");
long startTime = System.nanoTime();
jobLauncher.run(job, jobParameters);
long endTime = System.nanoTime();
return endTime - startTime;
}
@BeforeEach
public void setUp() {
jdbcTemplate.execute("TRUNCATE TABLE AfterEntity;");
}
@AfterEach
public void cleanup() {
jdbcTemplate.execute("TRUNCATE TABLE AfterEntity;");
}
@DisplayName("JPA 배치 처리 기반 실행시간 < ORM 기반 실행시간")
@Test
public void test() throws Exception {
long jpaMethodExecutionTime = executeOrmMethod();
jdbcTemplate.execute("TRUNCATE TABLE AfterEntity;");
long jpaBatchExecutionTime = executeBatchJob();
// then
assertThat(jpaMethodExecutionTime)
.describedAs(
String.format(
"ORM 메소드 실행시간: %d nanoseconds, JPA Batch 실행시간: %d nanoseconds",
jpaMethodExecutionTime, jpaBatchExecutionTime))
.isGreaterThan(jpaBatchExecutionTime);
}
}그래도 JPA 배치 처리가 훨씬 빠르겠지... 하면서 테스트를 돌려봤는데...
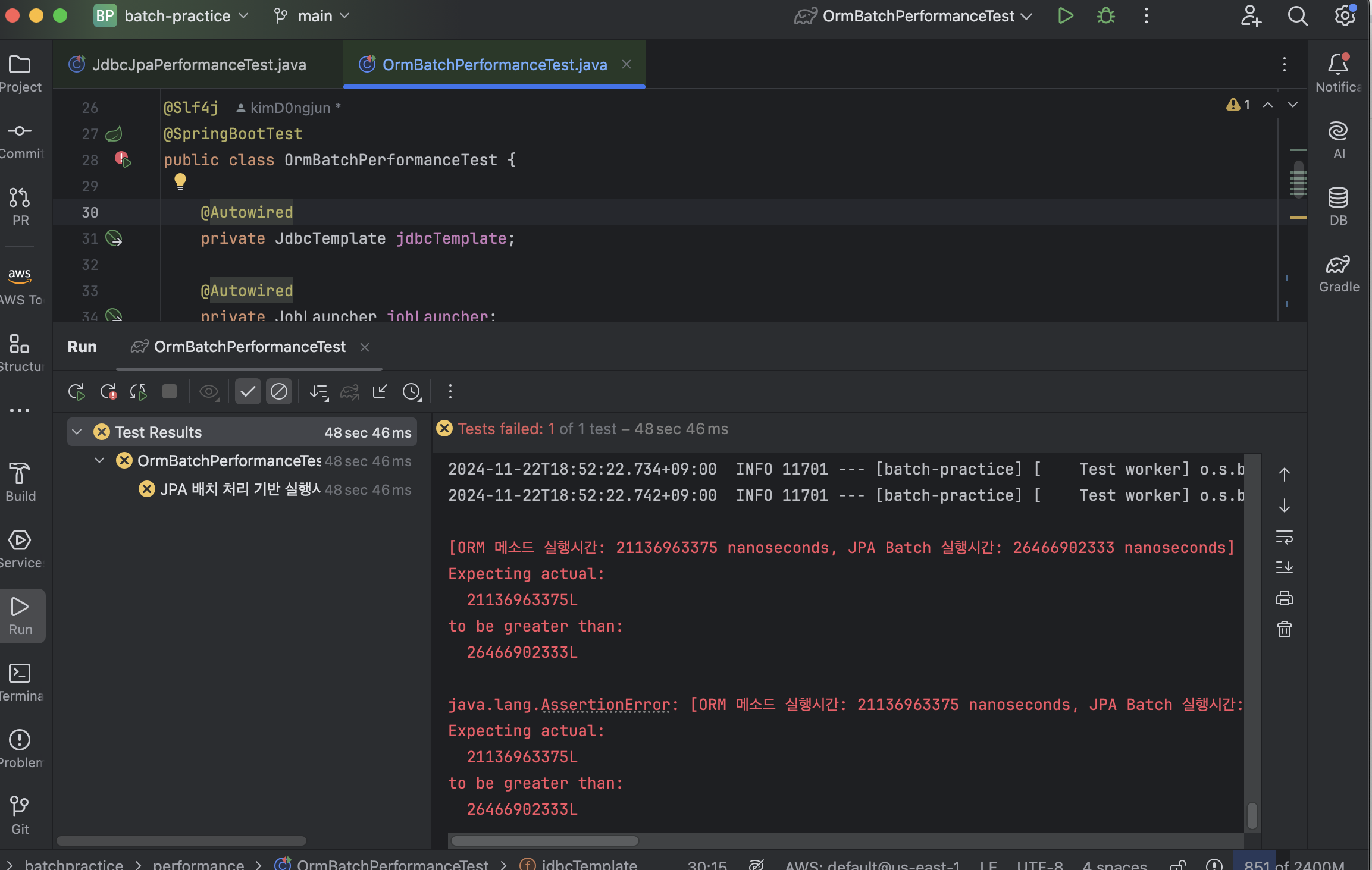
????
JPA 기본제공 메소드로 테이블 복사한 작업이 JPA 배치 처리보다 근소하게 빠르다고 나왔다. 물론 데이터의 양이 더 많아지면 분명 차이는 생기겠지만 그래도 내 예상을 엇나간 것이 좀 놀라웠다.
// Batch Config
@Bean
public Step firstStep() {
log.info("JPA: 첫 번쨰 스탭");
return new StepBuilder("firstStep", jobRepository)
.<BeforeEntity, AfterEntity>chunk(100, transactionManager)
.reader(beforeReader()) // 읽기 메소드 파라미터
// ...
@Bean
public RepositoryItemReader<BeforeEntity> beforeReader() {
return new RepositoryItemReaderBuilder<BeforeEntity>()
.name("beforeReader")
.pageSize(100) // findAll 메소드의 페이징 처리
.methodName("findAll")
.repository(beforeJpaRepository)
.sorts(Map.of("id", Sort.Direction.ASC)) // 자원 낭비 방지용 sort
.build();
}청크 사이즈가 문제인가 해서, 배치 처리에서 페이지 조회 사이즈와 청크 사이즈를 100으로 늘이고 다시 테스트를 진행해봤다.
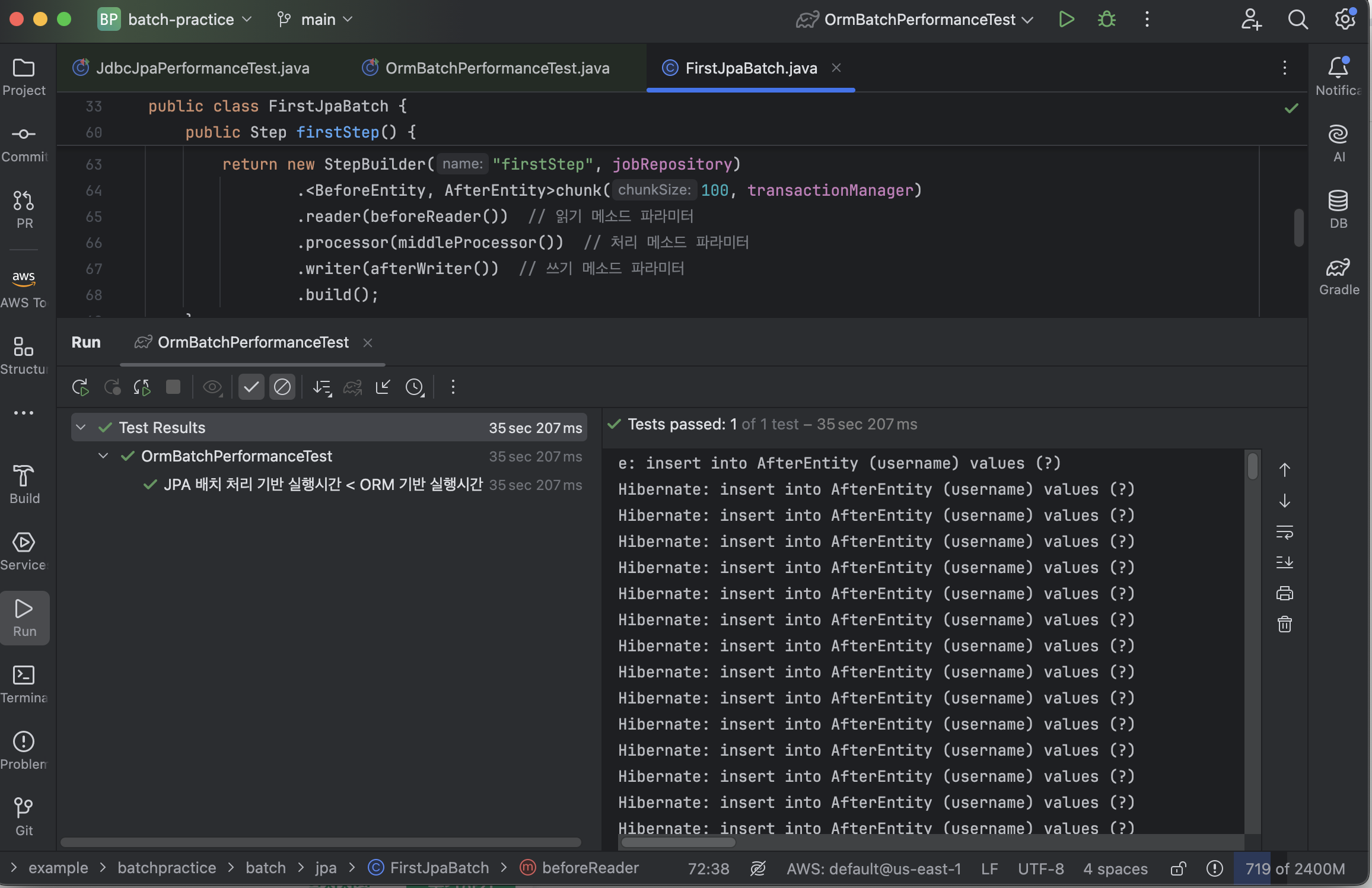
그 결과, 이번에는 테스트가 통과되는 것을 확인할 수 있었다. JPA 배치 처리에서는 데이터를 일정 단위(청크)로 읽고 처리해서 그 단위가 끝날 때마다 커밋되는데 예를 들어, 청크 사이즈를 100으로 설정하면, 100개씩 처리하고 커밋함으로써 한 번에 너무 많은 데이터를 커밋하지 않고, 적당한 크기로 나누어 처리하기 때문에 데이터베이스에 부담을 줄여주는 것이기 때문에 성능이 향상된 것이 아닌가 추측된다. 어찌됐든 현재 코드는 저장 단계에서 JPA 기본제공 메소드 save()를 사용하고 있으므로.
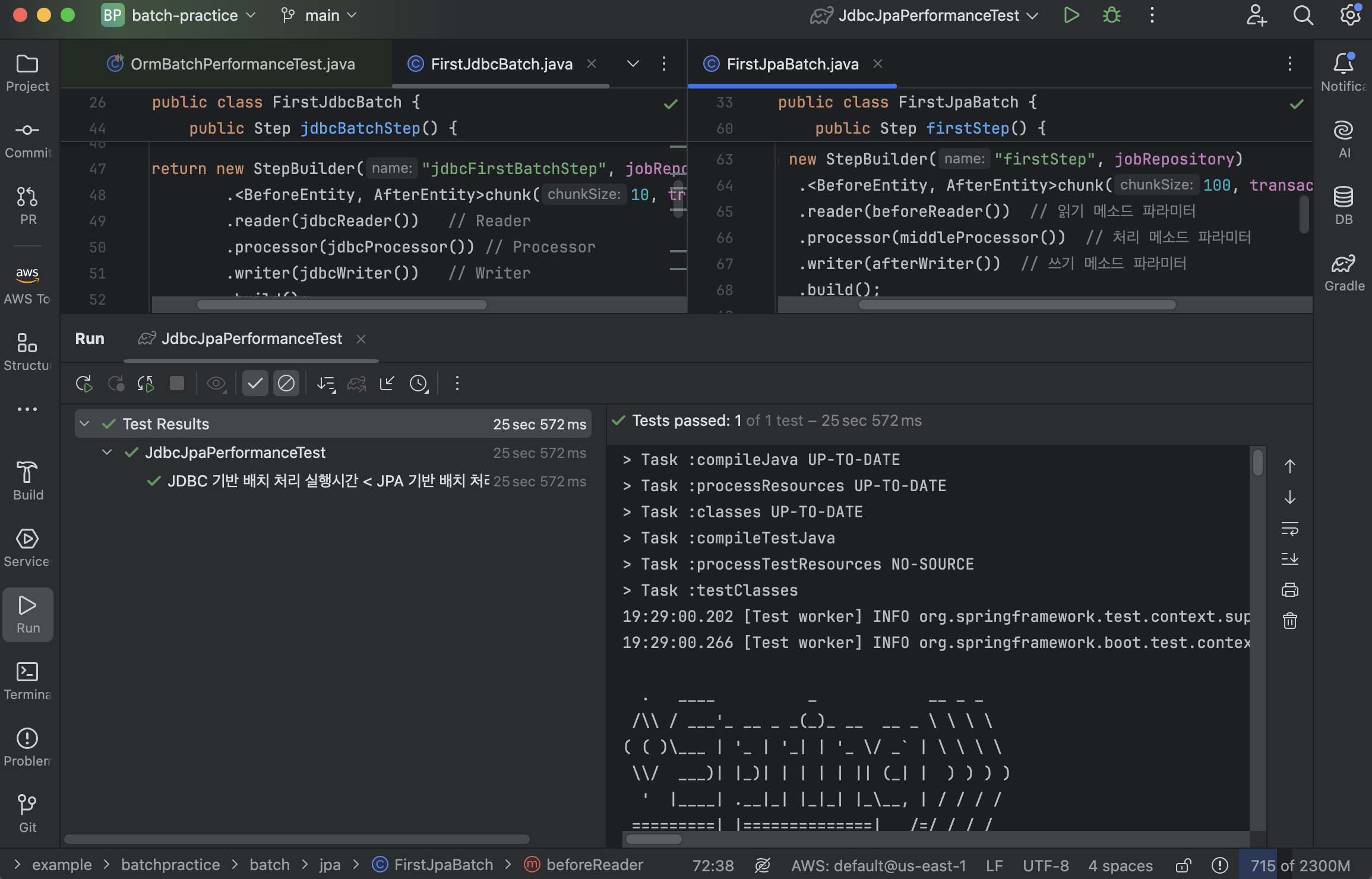
그렇지만 청크 단위를 100으로 늘인 JPA 배치 처리여도 청크 단위가 10인 JDBC 배치 처리보다는 느린 성능을 보이는 것은 매한가지였다.
3) 테스트 결과 정리
| 테스트 시나리오 | 성능이 더 좋은 방식 |
|---|---|
| 청크 10개 JDBC vs 청크 10개 JPA | JDBC 배치처리 |
| 청크 10개 JPA vs JPA 기본제공 메소드 | 기본제공 메소드 |
| 청크 100개 JPA vs JPA 기본제공 메소드 | JPA 배치처리 |
| 청크 10개 JDBC vs 청크 100개 JPA | JDBC 배치처리 |
테스트를 통해 얻은 결론은 다음과 같다.
1. 청크 단위를 전략적으로 선택해야 한다.
2. JPA는 배치 처리에 엄청 적합하진 않다.
3. 배치 처리를 사용한다면 JDBC를 활용하자.
6. 배치 처리 - 테이블 업데이트
RDBMS 영속성 내에서의 스프링 배치 처리 시나리오로 이번에는 단일 테이블 내에서 특정 필드에 따라 데이터를 업데이트하는 것을 일괄 처리해볼 예정이다.
시나리오 및 그에 따른 엔티티(WInEntity)는 다음과 같다.
WinEntity 테이블 내의 win 필드가 10 이상이면 reward 필드를
true로 업데이트한다.
@Entity
@Getter
@Setter
public class WinEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private Long win;
private Boolean reward;
}사실 위의 테스트를 거친 결과 JDBC 기반 스프링 배치를 구현해야 하지만... 그래도 편의성이 좋은 JPA 기반으로 다시 스프링 배치를 구현했다.(개념 학습하는 단계라고 나름 핑계를 대본다)
1) JPA 기반 스프링 배치 구현
(1) 코드 구현
@Slf4j
@Configuration
@RequiredArgsConstructor
public class SecondJpaBatch {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private final WinJpaRepository winJpaRepository;
@Bean
public Job secondJob() {
log.info("win 엔티티 테이블 조건부 처리");
return new JobBuilder("secondJob", jobRepository)
.start(secondStep())
.build();
}
/**
* 단위 스뱁의 구성 : 읽기 -> 처리 -> 쓰기
* 이 작업 순서 진행 단위가 chunk, 대량의 데이터를 얼만큼 끊어서 처리할 지
* (너무 작으면 IO 처리 많아지면서 오버헤드, 너무 적으면 리소스 사용 비용 상승 및 실패 부담)
*/
@Bean
public Step secondStep() {
log.info("두 번째 스탭");
return new StepBuilder("secondStep", jobRepository)
.<WinEntity, WinEntity> chunk(10, transactionManager)
.reader(winReader())
.processor(trueProcessor())
.writer(winWriter())
.build();
}
// WinEntity 테이블에서 읽어오는 Reader
@Bean
public RepositoryItemReader<WinEntity> winReader() {
return new RepositoryItemReaderBuilder<WinEntity>()
.name("winReader")
.pageSize(10)
.methodName("findByWinGreaterThanEqual")
.arguments(Collections.singletonList(10L)) // WinEntity 의 win 필드가 10 이상인 데이터들 조회
.repository(winJpaRepository)
.sorts(Map.of("id", Sort.Direction.ASC))
.build();
}
// 읽어온 데이터를 처리하는 Process
@Bean
public ItemProcessor<WinEntity, WinEntity> trueProcessor() {
return item -> {
item.setReward(true);
return item;
};
}
// WinEntity 에 처리한 결과를 저장(Write)
@Bean
public RepositoryItemWriter<WinEntity> winWriter() {
return new RepositoryItemWriterBuilder<WinEntity>()
.repository(winJpaRepository)
.methodName("save")
.build();
}
}코드 구현은 앞의 테이블 복사 시나리오 과정과 유사하기 때문에 별도의 설명은 생략한다. 다만 차이점이라면, Reader 단계에서 호출하는 JPA 메소드는 파라미터 인자가 필요하기 때문에 arguments(Collections.singletonList(10L)) 코드가 추가됐다는 것과, 단일 테이블 내에서만 이뤄지기 때문에 trueProcessor() 메소드의 제네릭 엔티티가 동일하다는 점이다.
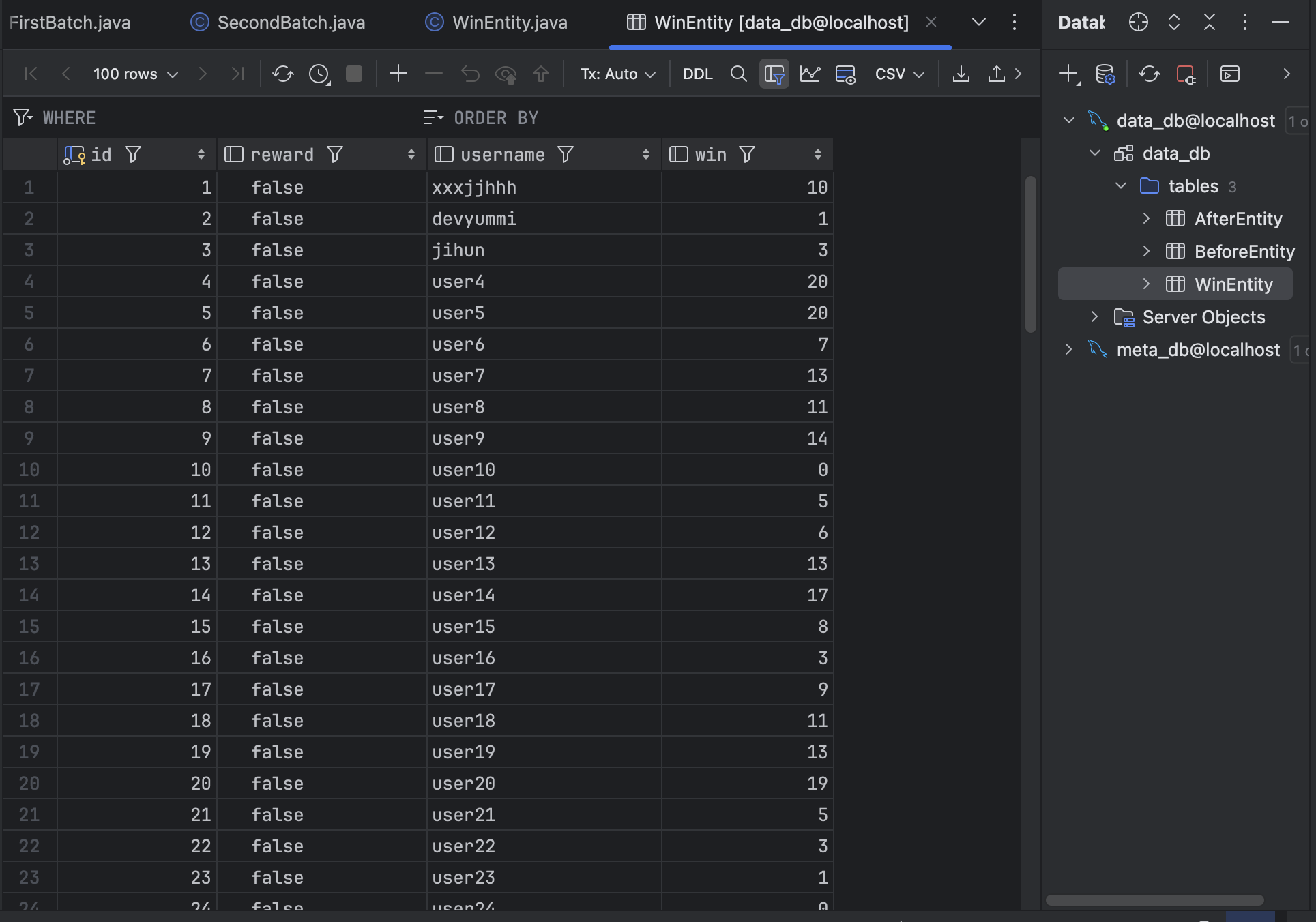 win 필드가 다양하게 초기화되어있고, reward 필드는 전부
win 필드가 다양하게 초기화되어있고, reward 필드는 전부 false로 정해지도록 데이터를 산입했다. 이제 우리가 할 배치 처리 작업은 win 필드가 10점 이상이면 reward 필드가 true로 업데이트하는 것이다.
(2) 실행 결과
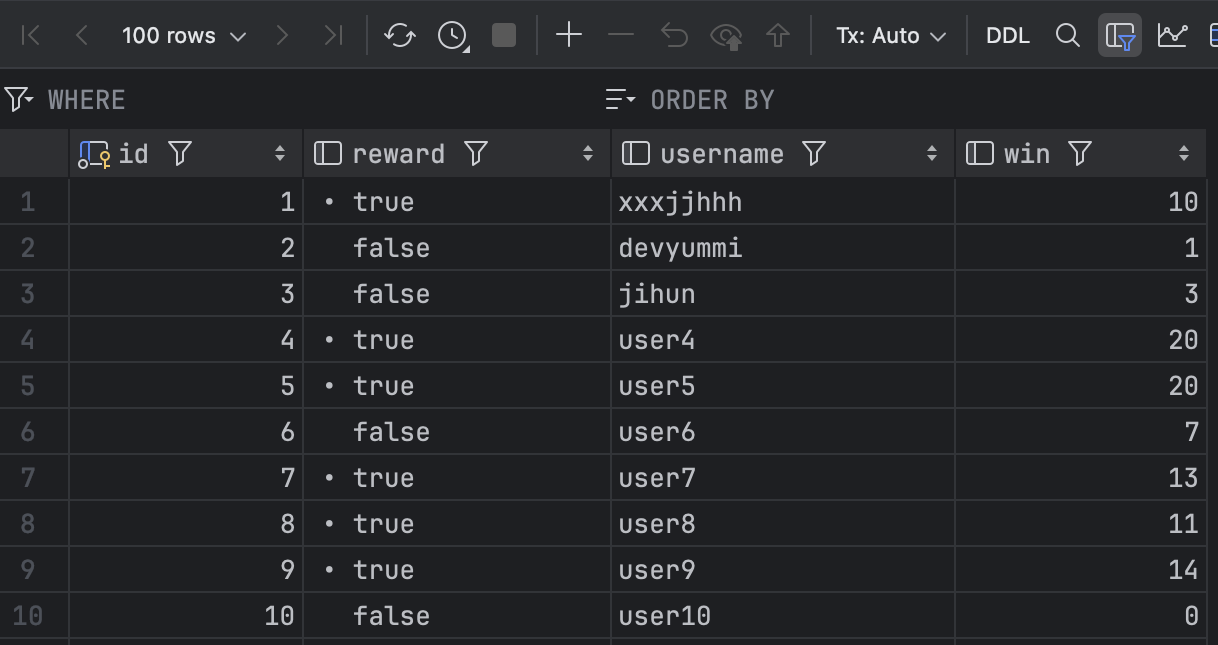
성공적으로 10점 이상인 win 필드를 가진 데이터는 reward가 true로 업데이트된 것을 확인할 수 있다.
다음 포스팅부터는 RDBMS가 아닌 NoSQL(Redis, MongoDB) 영속성을 기반으로 스프링 배치를 구현해본다.
