개념
하나의 큰 문제를 작고 유사한 하위 문제로 나누고, 각 하위 문제를 독립적으로 해결한 뒤, 그 결과를 결합해서 원래 문제를 푼다.
분할(Divide) : 문제를 더 작은 동일한 형태의 문제로 분할한다.
정복(Conquer) : 분할된 문제를 재귀적으로 해결한다. 더 이상 쪼갤 수 없을 때까지.
조합(Combine) : 해결된 하위 문제들의 결과를 합쳐서 원래 문제의 해를 만든다.
참고한 블로그 : https://olrlobt.tistory.com/45
장점
빠른 처리 속도 : 큰 문제를 작은 하위 문제로 분할하고 해결하여 전체 문제를 해결하는 데 걸리는 시간을 줄일 수 있다.
병렬화 용이 : 하위 문제들이 독립적이기 때문에 병렬 처리가 가능하여 성능이 향상.
유연성 : 문제와 복잡도와 데이터 크기에 상관없이 적용할 수 있다.
단점
추가 메모리 사용 : 문제를 나눌 때마다 각 단계에서 메모리 사용이 증가할 수 있다.
최악의 경우 성능 저하 : 일부 경우에는 최악의 시간 복잡도가 증가할 수 있다.
구현의 복잡성 : 분할, 정복, 결합 과정을 구현하는 데 복잡한 논리와 코드가 필요할 수 있다.
예시
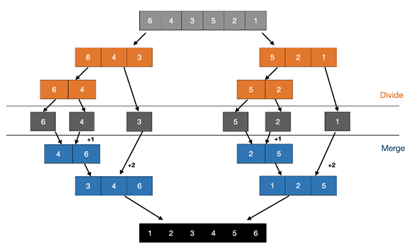
병합 정렬
하나의 배열을 반으로 나누고, 각각을 정렬한 뒤, 두 정렬된 배열을 병합해서 전체 정렬함. 항상 O(N log N)의 시간 복잡도 보장. 데이터 양이 많을수록 효율적.
Divide : 리스트를 절반으로 계속 분할
[4, 2, 5, 1, 3]
→ [4, 2] / [5, 1, 3]
→ [4] [2] / [5] [1, 3]
→ [4] [2] / [5] [1] [3]Conquer : 각 하위 리스트를 재귀적으로 정렬
[4] [2] → [2, 4]
[1] [3] → [1, 3]
[5] 그대로
→ [2, 4], [5], [1, 3]Combine : 두 개의 정렬된 리스트를 병합
[5] + [1, 3] → [1, 3, 5]
[2, 4] + [1, 3, 5] → [1, 2, 3, 4, 5]작은 단위(길이 1 배열)는 당연히 정렬된 상태이고, 이 정렬된 조각들을 하나씩 비교하면서 병합만 잘 해주면, 전체가 정렬됨.
시간 복잡도
Divide는 log₂N 단계로 나눈다. → log N
Merge는 각 단계마다 N개의 데이터를 합친다. N
전체 logN * N = O(N log N)
항상 N log N이다. 최악도 동일함.
수열의 빠른 합
sum(1..n)을 그냥 1부터 n까지 더하면 O(N).
하지만 분할정복으로 좌우 반 나눠서 합치면 O(log N) 가능함.
sum(1..8) -> sum(1..4) + sum(5..8)
sum(1..4) -> sum(1..2) + sum(3..4)
sum(1..2) -> 1 + 2
sum(3..4) -> 3 + 4
sum(5..8) -> ...
마지막에는 다 더해서 올라온다. 전체 합은 36단순히 쪼갰다가 더한 것 이기 때문에, 메모이제이션이 없으면, O(N)과 차이가 없다. DP와 함께 사용하거나, 복잡한 규칙이 있는 수열일 경우는 효과가 커진다.
시간 복잡도
일반 재귀는 O(N) 호출 수 가 많다.
분할 정복 + 메모이제이션은 O(logN) 가능하다.
이진 탐색 (Binary Search)
정렬된 배열에서 어떤 값을 빠르게 찾고 싶을 때, 중간값과 비교해서 절반식 범위를 줄여나가는 방법.
예시로 [3, 7, 12, 19, 24, 31]이 있을 때
mid = 12(3번째 요소) → 19 > 12 이므로 오른쪽으로 간다.
그러면 다음 범위는 [19, 24, 31] mid = 24 19 < 24 왼쪽으로 간다.
남은 범위는 [19] 여기에서 찾았다. 총 3번 비교함. O(log N)
중요 포인트
배열이 정렬되어 있어야 함.
매 단계마다 범위 절반씩을 제거한다. O(log N)
