완전 탐색 (Exhaustive Search)
참고한 블로그 https://hongjw1938.tistory.com/78
완전탐색은 간단히 가능한 모든 경우의 수를 다 체크해서 정답을 찾는 방법이다. 즉, 무식하게 가능한 거 다 해보겠다는 방법을 의미한다.
이 방법은 무식하게 한다는 의미로 "Brute Force"라고도 부르며, 직관적이어서 이해하기 쉽고 문제의 정확한 결과값을 얻어낼 수 있는 가장 확실하며 기초적인 방법이다.
시간과 메모리 소모가 크다. 하지만 경우의 수 자체가 적은 경우에는 가장 확실하다. 어쨌든 정답을 도출할 수 있으므로
5가지의 방법이 있다
Brute Force 기법 - 반복 / 조건문을 활용해 모두 테스트하는 방법
순열(Permutation) - n개의 원소 중 r개의 원소를 중복 허용 없이 나열하는 방법
재귀 호출
비트마스크 - 2진수 표현 기법을 활용하는 방법
BFS, DFS를 활용하는 방법
브루트 포스
정의 : 모든 경우의 수를 계산하여 문제를 해결하는 방법
특징 : 비효율적이지만 확실한 방법으로, 가능한 모든 경우를 전부 탐색.
시간 복잡도 : O(n^k) (n: 데이터 크기, k: 탐색 범위)
예시
# 배열 내 두 수의 합이 주어진 목표 값과 일치 모든 경우 찾음
# 두 수의 합이 target과 일치하는 모든 쌍을 찾는 브루트 포스
def find_pairs(arr, target):
result = []
n = len(arr)
# 모든 가능한 쌍을 검사해야함. (이중 for문)
for i in range(n):
for j in range(i + 1, n):
if arr[i] + arr[j] == target:
result.append((arr[i], arr[j]))
return result
# 예시 배열과 목표 값
arr = [2, 4, 3, 6, 7]
target = 9
# 실행
print(find_pairs(arr, target))
# 결과
[(2, 7), (3, 6)]
# 위 코드에서는 배열의 모든 요소를 순회하며 가능한 쌍을 모두 확인함. 시간 복잡도 O(n^2)비트마스크 (Bitmask)
정의 : 비트 연산을 통해서 부분 집합을 표현하는 방법을 의미한다.
특징 : 각 원소의 포함 여부를 비트로 표현해 탐색을 진행하며, 메모리 사용량이 적고 코드가 간결.
유용성 : 집합의 모든 부분 집합을 탐색하는 문제에서 자주 사용.
AND, OR, NOT, XOR, Shift 이런것들을 활용하여
특정 숫자를 제거, 토글 연산, 숫자 추가 하기 등을 할 수 있다.
재귀(Recursion)
정의 : 함수가 자기 자신을 호출하는 구조
특징 : 각 원소가 두 가지 선택지를 가질 때 유용하며, 코드가 간결하고 이해하기 쉽지만, 스택 오버플로우 발생 가능성.
중요한 점은
재귀를 탈출하기 위해 탈출 조건이 필요. 리턴에 주의해야 함.
현재 상태를 저장하는 파라미터가 필요함. 그래야 종료 조건을 정할 수 있다.
팩토리얼 예시
# 재귀 함수로 팩토리얼 계산
def factorial(n):
if n == 1: # 종료 조건 (base case)
return 1
return n * factorial(n - 1) # 자기 자신을 호출
# 실행
print(factorial(5)) # 5! = 5 * 4 * 3 * 2 * 1 = 120
# 결과 120순열과 조합
순열 : 서로 다른 n개 중 r개를 순서 있게 선택하는 방법
순서에 따라 [1, 2]와 [2, 1]은 각각 카운팅 들어감
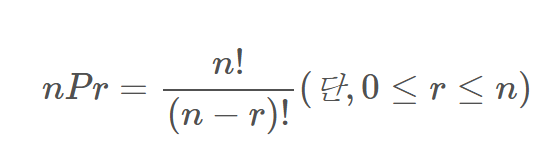
조합 : 서로 다른 n개 중 r개를 순서 없이 선택하는 방법
순서와 상관 없이 [1, 2]와 [2, 1]은 같은 것임!
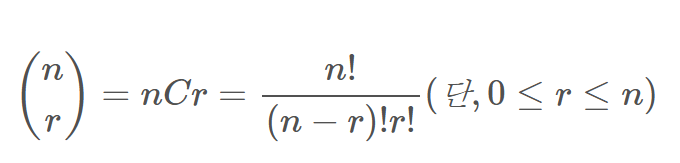
너비 우선 탐색 (BFS)
정의 : 큐(Queue)를 사용해 한 단계씩 인접 노드를 탐색하는 방법
특징 : 최단 경로를 보장하며, 모든 경로의 깊이가 동일할 때 유리.
장점 : 최단 경로 보장
단점 : 많은 노드를 저장해야 하므로 메모리 소모가 큼
시간 복잡도: O(V + E) (V: 노드 수, E: 간선 수)
깊이 우선 탐색 (DFS)
정의 : 스택(Stack) 또는 재귀를 사용해 한 노드의 가장 깊은 경로까지 탐색하는 방법
특징 : 경로 탐색에 적합하며, 메모리 사용이 적다.
장점 : 저장 공간이 적다
단점 : 잘못된 경로로 깊이 들어갈 수 있음
시간 복잡도: O(V + E) (V: 노드 수, E: 간선 수)
BFS vs DFS
최단 경로 문제 → BFS가 유리
이유 : BFS는 너비 우선으로 탐색하며 같은 깊이의 노드부터 방문 → 가장 먼저 도달한 경로가 최단 경로.
특징 : 큐 사용, 단계별 탐색, 가중치 없는 그래프에서 최단 경로 보장.
조건부 경로 탐색 → DFS가 유리
이유 : DFS는 한 방향으로 깊게 탐색 후 조건이 맞지 않으면 백트래킹하여 다른 경로 탐색.
특징 : 모든 경로 탐색 가능, 특정 노드를 반드시 거치는 조건 등에서 유리.
이분 탐색 (Binary Search)
참고한 블로그 https://velog.io/@kimdukbae/이분-탐색-이진-탐색-Binary-Search
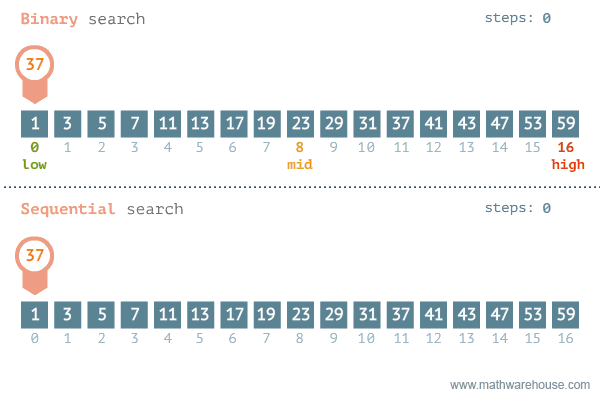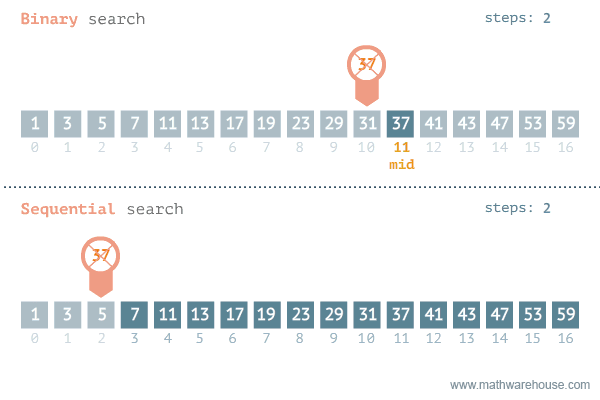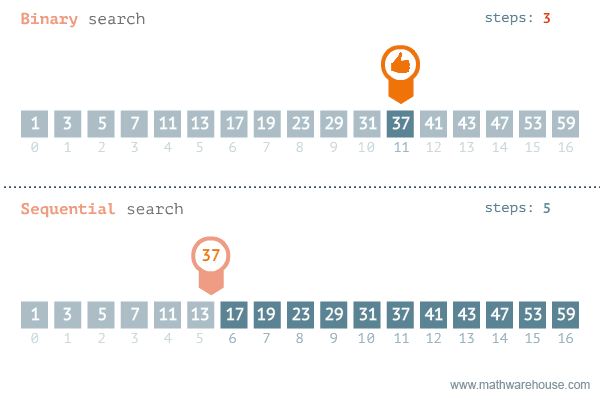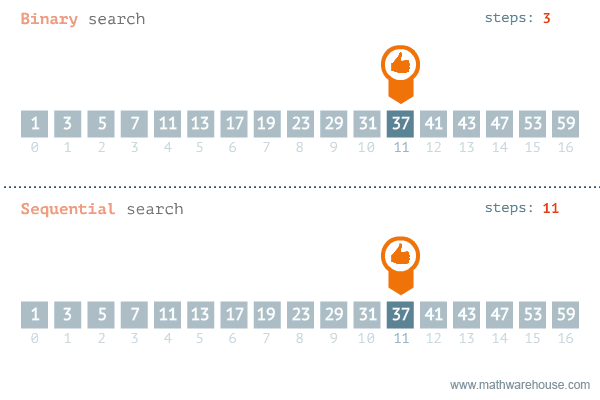
이분(이진) 탐색은 정렬되어 있는 리스트에서 탐색 범위를 절반씩 좁혀가며 데이터를 탐색하는 방법이다.
이진 탐색은 배열 내부의 데이터가 정렬되어 있어야만 사용할 수 있는 알고리즘이다.
변수 3개(start, end, mid)를 사용하여 탐색한다. 찾으려는 데이터와 중간점 위치에 있는 데이터를 반복적으로 비교해서 원하는 데이터를 찾는 것이 이진 탐색의 과정이다.
시간 복잡도 : O(log n)
단계마다 탐색 범위를 반으로(÷2) 나누는 것과 동일하므로 위 시간 복잡도를 가지게 된다.
예를 들어 처음 데이터의 개수가 32개라면, 이론적으로 1단계를 거치면 약 16개의 데이터가 남고, 2단계에서 약 8개, 3단계에서 약 4개의 데이터만 남게 된다. 즉 이진 탐색은 탐색 범위를 절반씩 줄이고, O(logN)의 시간 복잡도를 보장한다.
의 시간 복잡도를 보장한다.
조건 : 배열이 정렬된 상태.
동작 과정
- 배열의 중앙값과 찾고자 하는 값을 비교
- 찾고자 하는 값이 중앙값보다 크면 오른쪽 범위를, 작으면 왼쪽 범위를 탐색
- 값을 찾으면 탐색 종료, 그렇지 않으면 범위가 사라질 때까지 계속 진행
핵심은 mid로 절반씩 줄여가고, 찾고자 하는 값에 따라 왼쪽으로 절반 줄지, 오른쪽 으로 절반 줄지 그렇게 해서 0부터 N까지 조회를 하는게 조회 속도가 압도적으로 많게 되는 거임.
def binary_search(arr, target):
low, high = 0, len(arr) - 1
while low <= high: // 엇 크로스가 될 때까지
mid = (low + high) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
low = mid + 1
else:
high = mid - 1
return -1 # 값을 찾지 못한 경우