오늘은 간담회 발표가 있어서 30분 정도 늦게참여했다.
미리 예정되어있던 일정이라, 아침에 미리 아티클 작성은 해놨다.
-첫번째 아티클
https://yozm.wishket.com/magazine/detail/1632/
[주제]
- ‘화해’DW팀이 들려주는 데이터 리터러시 이야기
[아티클 요약]
- 데이터 리터러시: 데이터 문해력
데이터를 잘 활용한다는 것은 → 데이터를 활용해 문제를 잘 정의하고 해결할 수 있다는 것
그러기 위해선, 1)데이터/실험 기반 사고방식, 2)분석흐름대로 데이터를 탐색할 수 있는 환경, 3)분석가들의 도움
분석가들은 너무 많거나 때로는 의미 없는 데이터를 보려는 상황에서 인터뷰를 통해 문제정의-솔루션-측정 지표를 간결화해옴.
ex. 해결하려는 문제: 신규 기능에 대한 인지 부족
솔루션: 신규 기능에 대한 브랜딩을 통한 신규 인지 강화
측정 지표: 이벤트 조회자수, 이벤트 참여자수
*필요한 것
1)데이터/실험 기반 사고방식
실험 프로세스/실험보드 → 모든 엄무가 데이터와 실험 기반으로 이루어지도록 만들기. 따라서 “실험 프로세스를 도입”
실험 프로세스는 다음과 같다.
*해결하려는 문제-문제정의,
관련 OKR(Objectives and Key Results)-전사 목표와 align한지,
측정 지표-문제와 지표가 align 되어있는지, 측정가능한 것인지,
가설 검증기준-성공 여부를 어떻게 판단할 것인지,
검증 후 변화될 액션-의미없는 액션을 하는 게 아닌지,
결과-검증 기준으로 결과가 나왔는지,
학습한 점-어떤 학습을 했고, 다음 실험에는 어떻게 반영될 것인지 ]*
2)분석 흐름대로 데이터를 탐색할 수 있는 환경
-데이터 맵
인풋 지표 원칙 1.측정 가능하고 2.직접적 control 가능해야함.
-대시보드
지표가 흐름대로 잘 진행되는지 확인할 수 있는 환경
KPI대시보드에서 최상위 문제를 발견하면, 각 지표와 관련된 하위 지표들이 구성된 분석 대시보드에서 원인 짐작 가능
*KPI: 핵심성과지표(Key Performance Indicator)
3)분석가의 도움
데이터추출, 분석 내용 리포팅에 + 문제정의/원인분석/액션 아이템까지 도출해 협업팀이 실행에 옮기도록 만들어야하는 것이 분석가의 역할!!
데이터 플랫폼의 핵심 3가지_ 1.모든 원천데이터가 있는 데이터 레이크, 2.신속정확 데이터 추출을 위해 구조화된 데이터 웨어하우스, 3.데이터 레이크/웨어하우스 내에 어떤 데이터가 있는지 쉽게 알게해주는 데이터 카탈로그
[인사이트]
아티클을 읽을 때, 해결하려는 문제를 먼저 보고 답을 보지 않은채 측정 지표가 무엇이 필요할까.. 어떻게 간소화할 수 있을까 고민해봤는데 명확히 떠오르지 않았다..! 그래서 문제정의-솔루션-측정지표에 맞는 사고방식을 토대로 데이터를 다루는 경험을 많이 쌓아야겠다고 생각했다.
그리고 나는 사고방식과 실험 프로세스를 먼저 설정하는 것에 대해 대단히 공감했다. 왜냐하면 팀플로 통계분석을 진행했던 적이 있는데, 프로세스 절차마다 align한지를 크게 신경쓰지 않고 해결하려는 문제에만 집중하다보니, 전체적인 흐름에 오류가 생겨 뒤엎고 다시 했던 경험이 있다. 학교 수업 프로젝트도 이런데, 회사 업무라면 더더욱 이 과정이 중요할 것이라 생각했다. 또 나도 데이터를 분석해야하거나 분석할 거리가 생긴다면, 이 프로세스에 맞게 노션에 정리해서 취업에 활용할 수 있게 만들어야겠다.
그리고 실제로 SQL 실습을 하다보니, 데이터 웨어하우스를 업무에 가장 큰 도움을 준 요소라고 말했다는 점에 적극 공감이 되었다. SQL을 알아도 웨어하우스가 없거나 서버연결을 못하면 아무런 의미가 없는 것 같다ㅜㅜ
마지막까지 글을 읽으며 든 생각은, 네이버나 카카오같은 대놓고(?) IT기업도 아닌 화장품플랫폼 ‘화해’에서도 이렇게나 deep한 수준의 데이터 업무를 실행하는 것을 보고 ‘아직 갈길이 멀다 + 데이터를 만질 수 있는 능력은 정말정말 필요하구나!’ 라고 느껴서 열심히 공부 해두면 내가 희망하는 직무에 충분히 비벼볼만 하겠다는 생각이 들었다. 화이팅 해야겠다🧐.
.
.
-두번째 아티클
https://yozm.wishket.com/magazine/detail/1816/
[주제]
- 데이터 해석 오류
[아티클 요약]
- 데이터 해석 오류 유형
1)생존자 편향의 오류
<오류상황>
-전체 사용자가 아닌 이탈자만을 대상으로 분석함
-전체 전투기가 아닌 무사귀환전투기만을 대상으로 분석함
2)심슨의 역설
:전체 지표와 그룹을 나눈 지표의 방향성이 다르게 나타나는 상황
오히려 이때는, 전체 집단의 지표 뿐만 아니라 집단을 나누어 지표를 확인하는 과정이 필요 !
인구통계학적 특성(성별, 연령대, 기기타입, 신규/기존 여부 등) 등의 기준들을 미리 정하여, 지표를 살펴보는 것이 효과적.
3)상관관계를 통한 성급한 일반화
ex. 이벤트 페이지의 조회수 지표 증감 - 매출 지표 증감 경향성 비슷
⇒ 이벤트 페이지 조회수가 매출에 영향?? ====성급한 일반화일 수 있다
4)목적에 맞지 않는 지표 선택
*CTA(Call To Action)유저의 행동을 유도하는 버튼
<CTA버튼 조회 유저수(중복 제거) 대비 CTA 버튼 클릭 유저수(중복제거)>
↔ <CTA 버튼 조회수 대비 CTA버튼 클릭>
cf. 칼 세이건의 세이건 표준을 참고하면 좋다
[인사이트]
상관관계를 통한 일반화를 직접 오류로 범해봤던 경험이 있어, 약간의ptsd가 왔다.(ㅋㅋㅋ) 정말 상관관계는 인관관계가 아님을 다시한번 명심하게 했다. Ott 재구독 의향 조사에 대한 통계적 조사를 진행했을 때, 1.구독 개수와 재구독 의향 조사, 2.만족도와 재구독 의향 조사를 진행했었다. 여기에선 일일이 설명하기엔 길지만, 범주화의 오류도 있었다. (전체범주-부분범주). 이 오류가 생존자 편향 또는 심슨의 역설이었던 것 같은데, 너무 범하기 쉬운 오류들과 흔한 상황이라 앞으로 데이터 분석을 할 때 이러한 오류를 더욱 경계해야겠다고 생각했다. 그리고 세이건 표준도 찾아봐야겠다.
.
.
.
이렇게 아티클 팀스터디를 끝내고(오늘은 아티클이 2개라 시간이 오래걸렸다) SQL 2 주차 강의를 듣기 시작했다.
2-1. 엑셀 대신 SQL로 한번에 계산하기
배운개념: SUM, AVERAGE, COUNT, MAX, MIN
오늘 많은 코드를 써본 것 같은데, 간단히 정리해보자면
SELECT food_preparation_time,
delivery_time,
food_preparation_time + delivery_time as total time
from food_orders연산함수
합계 - ex.select SUM (food_preparation_time)
평균 - ex.select AVG(delivery_time)
★함수하고 ()괄호 안에 칼럼 삽입하는 것 있지말기
개수세기
select count(1) count_of_orders
from food_orders의미:count_of_orders 컬럼의 전체 개수를 알려줘
select count(distinct customer_id) count_of_customers
from food_orders의미:고유한 customer_id개수="중복없는 고객의 수"
최댓값, 최솟값 구하기(값들의 범위 구하기)
select MIN(quantity) as min_quantity,
MAX(quantity) as max_quantity
from food_orders.
.
2.3[실습문제]
문제_1.
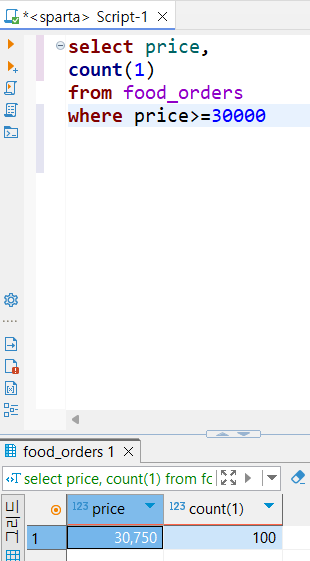
❓주문금액이 30,000원 이상인 주문건의 개수 구하기
✅사고과정
⏺️어떤 테이블에서 뽑을 것인가 >from food_orders
⏺️어떤 컬럼을 이용할 것인가 >price, order_id
⏺️어떤 조건을 지정해야하는가 >where price>=30000
⏺️어떤 함수를 이용해야하는가 >count(1) or count(order_id)
➡️
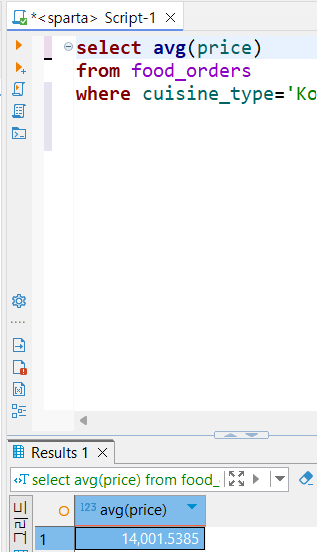
❓한국음식점의 주문 당 평균음식 가격 구하기
✅사고과정
⏺️어떤 테이블에서 뽑을 것인가 >from food_orders
⏺️어떤 컬럼을 이용할 것인가 >price, cuisine_type
⏺️어떤 조건을 지정해야하는가 >where cuisine_type='Korean'
⏺️어떤 함수를 이용해야하는가 >avg(price)
➡️
🔴내가 겪었던 오류_1
select 칼럼, <- 여기서 쉼표를 까먹어서 오류났었음
함수()
🔴내가 겪었던 오류_2
select, 함수, where 등등에 심취해서 from 테이블을 입력안함.
사고과정 첫번째 단계인 만큼, 제일 먼저 떠올리는 습관을 들이자(까먹기 쉬우니..!)
.
.
2-4.GROUP BY로 범주화하기
코드예시 ▽
select cuisine_type,
sum(price) sum_of_price
from food_orders
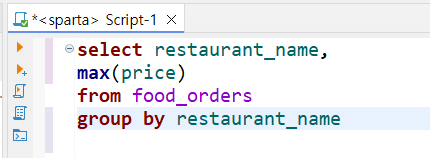
group by cuisine_type❓음식점별 주문 금액 최댓값 조회하기
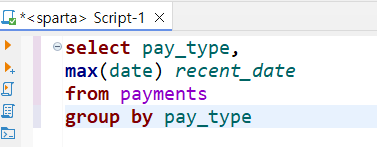
❓결제타입별 가장 최근 결제일 조회하기
지금은 강의를 다보고 따라해보기보다는,
질문만 보고 먼저 실행할대로 다 해보고 막히면 강의를 틀고 어디서,왜 오류가 나는지 확인하고
실행되면, 쿼리식을 잘 작성한게 맞는지 확인차 용도로 강의를 열씨미 듣구있다!
그래서 조금 오래걸리기는 하는데, 지금은 투자할 수 있는 시간도 많고 실습을 많이 해봐서 기억에도 더 오래가는 듯하다 ~!
다만 ㅠㅠ 코드를 입력한걸 메모장에 옮겨놓거나, 바로 벨로그에 쓰는 방법을 고안해봐야겠다... TIL을 쓸 때 다시 새로 쿼리를 작성해 실행을 돌리고 복붙하고,,이미지 캡처를 하다보니.... TIL쓰는데 시간이 너무 오래걸린다 ㅠㅠ
사담이지만, 오늘 간담회 발표를 잘 마쳐서 너무너무 뿌듯하다. 방학에도 발표는 끝나지를 않는구나. 하하하. 진짜 내 장점으로 잘 유지해야겠다.
⭐내일 할 것!
△아티클 스터디(만약 한다면..?설날전에 끝내자고 제안해보고싶다..)
아티클 스터디 안하면 3강진입 gogo~!
-2주차 완강+숙제문제
-걷기반 2) 문제 풀고 오답 정리
