오늘은 아티클 스터디가 없는 날이다.
그래서 자습시간이 길었다. 오랜시간 쭉 이어서 하니까 흐름이 안끊기고 좋았다..! 😊
오늘 공부한 것 목차!
-order by
-숙제
-replace
-substr
-concat
-실습문제
ORDER BY : 결과 정렬
기본구조
select 카테고리컬럼(원하는컬럼 아무거나),
sum(계산 컬럼),
from
group by 카테고리컬럼(원하는컬럼 아무거나)
order by 정렬을 원하는 컬럼 (카테고리컬럼(원하는컬럼 아무거나), sum(계산 컬럼) 둘 다 가능)
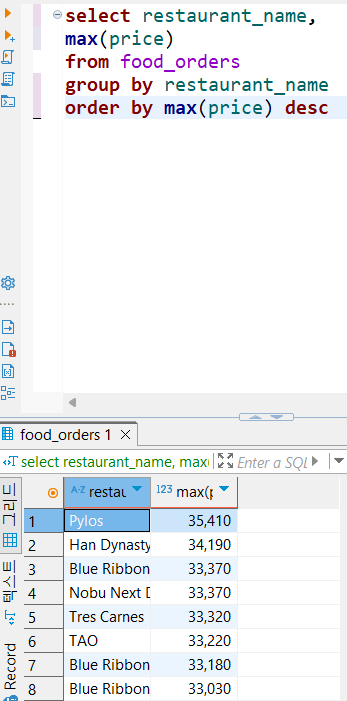
문제1: 음식점별 주문 금액 최댓값 조회하기-최댓값 기준 내림차순 정렬
문제2
차이
select name
from customers
order by name
→name만 나옴
select *
from customers
order by name
→name 오름차순에 따라 고객의 모든 칼럼이 나옴
select *
from customers
order by gender,name→ female중에서 이름 오름차순 정렬되고, female끝나고 maleㄱ 부터 시작
.
.
.
숙제 풀기전 기본 구조 복습~
select
from
where
group by
order by2주차 숙제문제
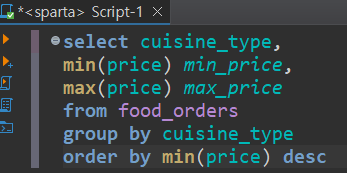
❓음식 종류별 가장 높은 주문 금액과 가장 낮은 주문금액을 조회하고, 가장 낮은 주문금액 순으로 (내림차순) 정렬하기
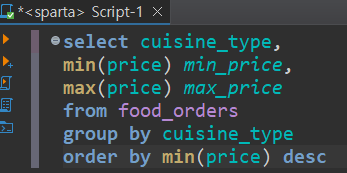
select cuisine_type,
min(price) min_price,
max(price) max_price
from food_orders
group by cuisine_type
order by min(price) desc한번 더 정리!
- 오름차순: 작은 값에서 큰 값으로
- 내림차순: 큰 값에서 작은 값으로
이 문제에서는 가장 낮은 주문금액을 기준으로 내림차순 정렬이겠지!
🔶처음에 조금 헷갈렸던 이유.
가장 낮은 주문금액 순으로 (내림차순) 정렬하기
라는 문장은
<가장 낮은 주문금액을 기준으로 내림차순 정렬하시오> 라는 뜻인지,
<가장 낮은 주문금액 순으로 정렬하기(가장 낮은 순부터 정렬하니까 아래로 갈 수록 점점 가격이 높아짐)> 라는 뜻인지 혼동이 왔음..ㅜ
그냥 낮은금액이면 'MIN()'쓰고 내림차순 있으니까 decs하면 될 듯
.
3주차
3-2.Query 결과를 바로 사용할 수 없는 경우
🔴데이터에 잘못입력된 값이 있는 경우
1)특정 문자를 다른 문자로 바꾸기
replace (바꿀 컬럼, 현재 값, 바꿀 값)
🔴주소 전체가 아니라 '시도'정보만 필요할 때
2)원하는 문자만 남기기/뽑기
substr (조회할 컬럼, 시작 위치, 글자 수)
🔴보고서 작성시, '사업장[지역]'과 같은 형태로 문제 포맷을 변경하고 싶을때
3)여러 컬럼의 문자를 합치기
concat(붙이고 싶은 값1, 붙이고 싶은 값2, 붙이고 싶은 값3, .....)
- 여기서 붙이고 싶은 값이 특수문자라면,
ex.'-', '[', ']'
이런식으로 작은 따옴표로 연결하기
.
CONCAT 실습 코드
#1
select restaurant_name "원래 이름",
addr "원래 주소",
concat('[', substring(addr, 1, 2), '] ', restaurant_name) "바뀐 이름"
from food_orders
where addr like '%서울%'
#2
아래처럼 concat 여러개 할 수도 있음
select restaurant_name "원래 이름",
addr "원래 주소",
concat(restaurant_name, '-', cuisine_type) "음식타입별 음식점",
concat('[', substring(addr, 1, 2), '] ', restaurant_name) "바뀐 이름"
from food_orders
where addr like '%서울%'
#3
이렇게 입력하면,
select restaurant_name "원래 이름",
addr "원래 주소",
concat(restaurant_name, '-', cuisine_type) "음식타입별 음식점",
concat('[', substring(addr, 1, 2), '] ', restaurant_name) "바뀐 이름"
from food_orders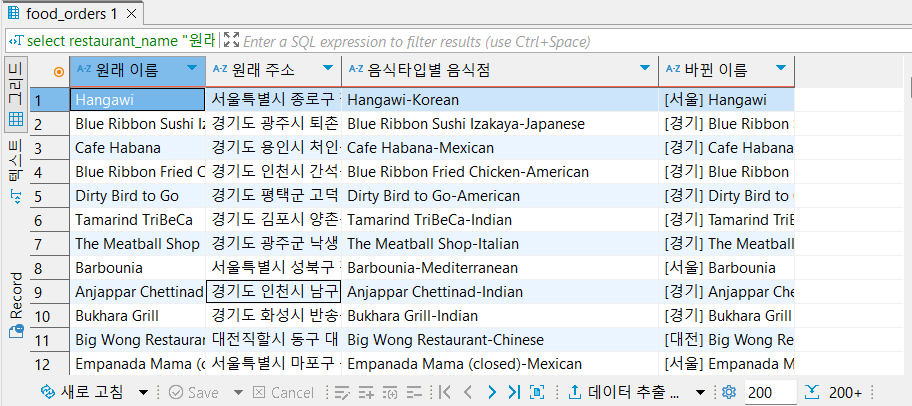
요롷게 나온다. <서울말고도 모든 지역 적용>
.
.
종합해보자면
💠여기서 배운 기본 구조💠
replace(바꿀 컬럼, 현재 값, 바꿀 값) substr(조회할 컬럼, 시작 위치, 글자 수) concat(붙이고 싶은 값1, 붙이고 싶은 값2, 붙이고 싶은값3, ...)
2-4.실습] 문자 데이터를 바꾸고, GROUP BY 사용하기
1번문제. 서울 지역의 음식 타입별 평균 음식 주문금액 구하기(출력 : ‘서울’, ‘타입’, ‘평균 금액’)
#💦나 혼자 시도한 사고과정
불러올 테이블: from food_order
필요한 칼럼: addr, cuisine_type, price
사용할 조건: substr(addr,1,2) "지역", cuisine_type "타입", where addr like "%서울%", group by cuisine_type
사용할 함수: avg(price) "평균 금액"
🚫주의할 사항: group by절에는 as 별명 을 못쓴다고 한다. select절에 써야한다.
💦나혼자 써본 코드
select avg(price) "평균 금액",
substr(addr,1,2) "지역",
cuisine_type "타입"
from food_orders
where addr like "%서울%"
group by cuisine_type 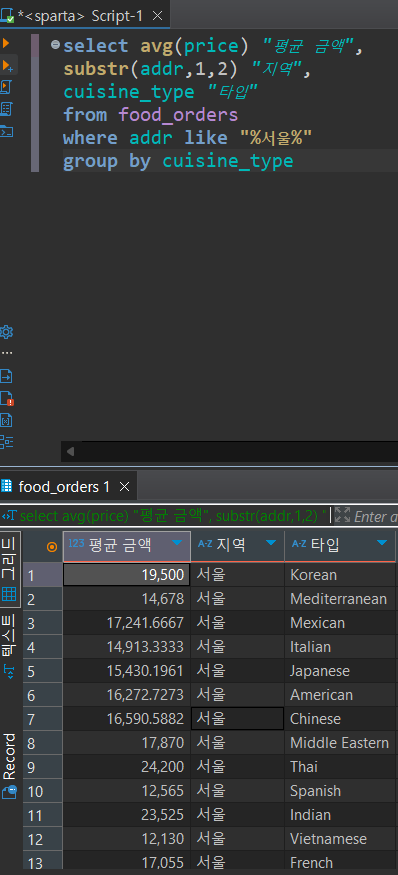
그럼 이렇게 나왔음.
⏺️강의에서 설명해주신 모범답안
select substr(addr,1,2) "지역",
cuisine_type "타입",
avg(price) "평균 금액"
from food_orders
where addr like "%서울%"
group by 1,2 ▽
두 차이는, select절에 컬럼 순서배열을 잘해서 결과(지역,타입,평균가격)를 읽기가 편했다는 점이었다. 출력 결과에 대한 차이는 이게 전부였다. 다만,
⭐group by 1,2 처럼 숫자로 열을 설정할 수 있었다는 점..!
을 꼭 기억하고 유용하게 써먹어봐야겠다.
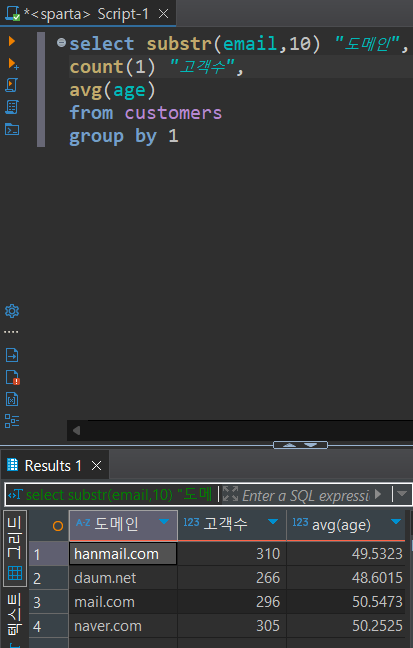
2번문제. 이메일 도메인별 고객 수와 평균 연령 구하기
💦오잉,, 도메인으로 어떻게 묶지..? count 뒤에 뭐를 쓰더라..?
강의의 힘을 조금 빌렸다..ㅠ
3번문제. '[지역(시도)]음식점이름(음식종류) 컬럼을 만들고, 총 주문건수 구하기
💦역시나 처음에 혼자해봄. 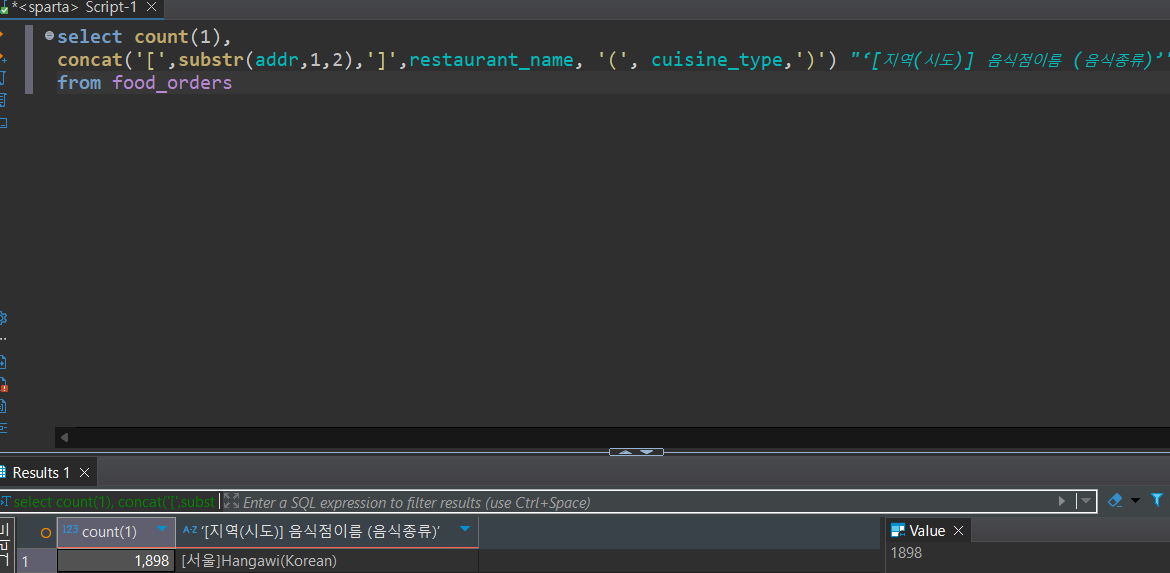
뭔가 이상함....😶
고민하다가.. 강의확인▽
select concat('[', substring(addr, 1, 2), '] ', restaurant_name, ' (', cuisine_type, ')') "바뀐이름",
count(1) "주문건수"
from food_orders
group by 1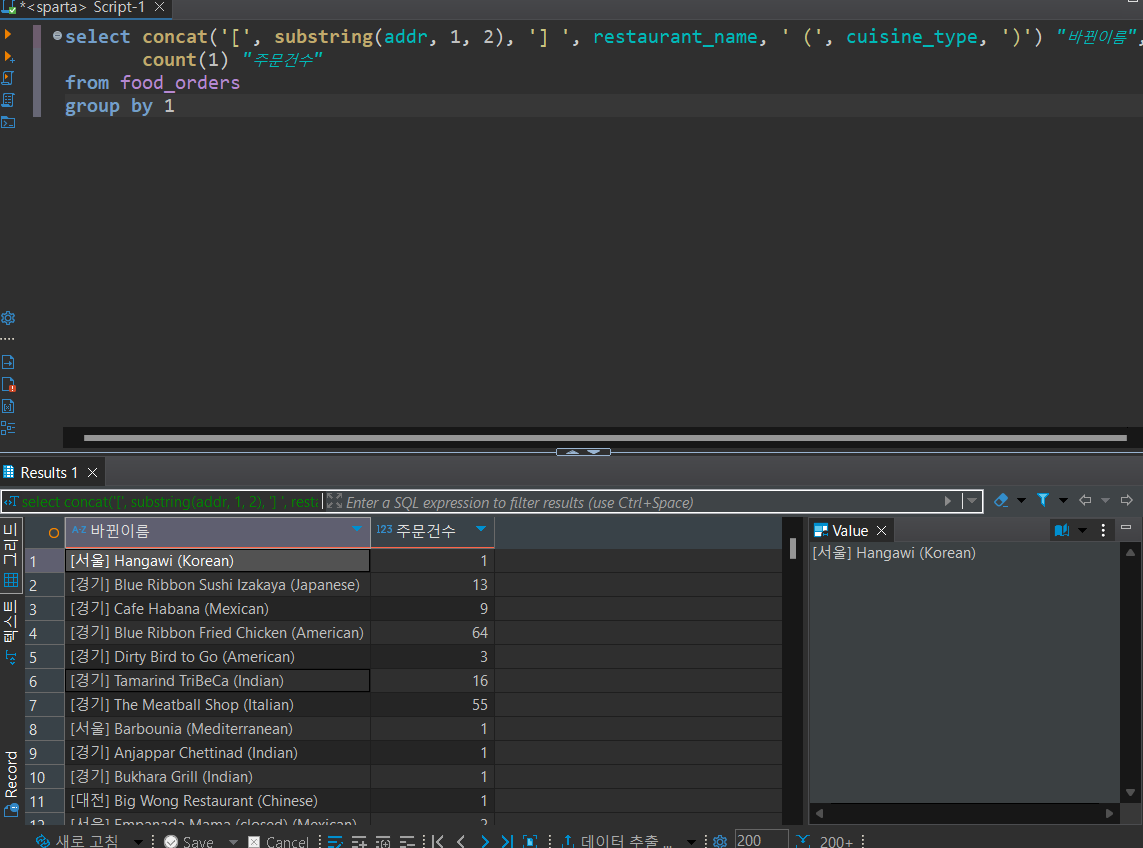
이거지...
새 칼럼은 침착하게 잘 만들었는데, 오늘 많이 실수했던 것은..!
" group by 새 칼럼 "
해서 '음식점 별'로 총 주문건수가 뜨게 했어야 했다..! 아직 익숙하지 않다 보니까 ✅어떤 열을 먼저 써야할지, ✅문제에서 '음식점 별'이라는 말은 없지만 group by를 써야 했던 것, ✅concat쓸 때도 괄호 ' (' 처럼 공백을 넣는 센스...!
이번에 푼 3문제는 정말 모두 유익했던 문제였다!!
월요일에 다시 한 번 복습을 해봐야겠다.
그리고 뭔가 이제 좀 더 웅장(?) 해진 느낌이라 재밌다 ㅋㅋㅋ ㅠ
다음시간에 학습할 것!
월요일에도 자습시간이 기니까 , 초반에 오늘 틀렸던 문제를 복습하고
3주차 완강 해야겠다 !!!
얼른 SQL끝내고 Phython시작해야지 !!
첫주 고생했다 나 자신,,~!
