코드카타
📍595. Big Countries
📍1148. Article Views I
📍1683. Invalid Tweets
My sql 문자열 길이 가져오기
참고링크
- 영어
SELECT LENGTH('Hello');
#결과 5SELECT CHAR_LENGTH('Hello');
#결과 5- 한글
🔻획 수로 셈
SELECT LENGTH('안녕');
#결과 6🔻글자 수로 셈
SELECT CHAR_LENGTH('안녕');
#결과 2📍1378. Replace Employee ID With The Unique Identifier
📍1068. Product Sales Analysis I
5문제 가볍게 풀어줬다~!
아티클스터디
📃오늘의 아티클
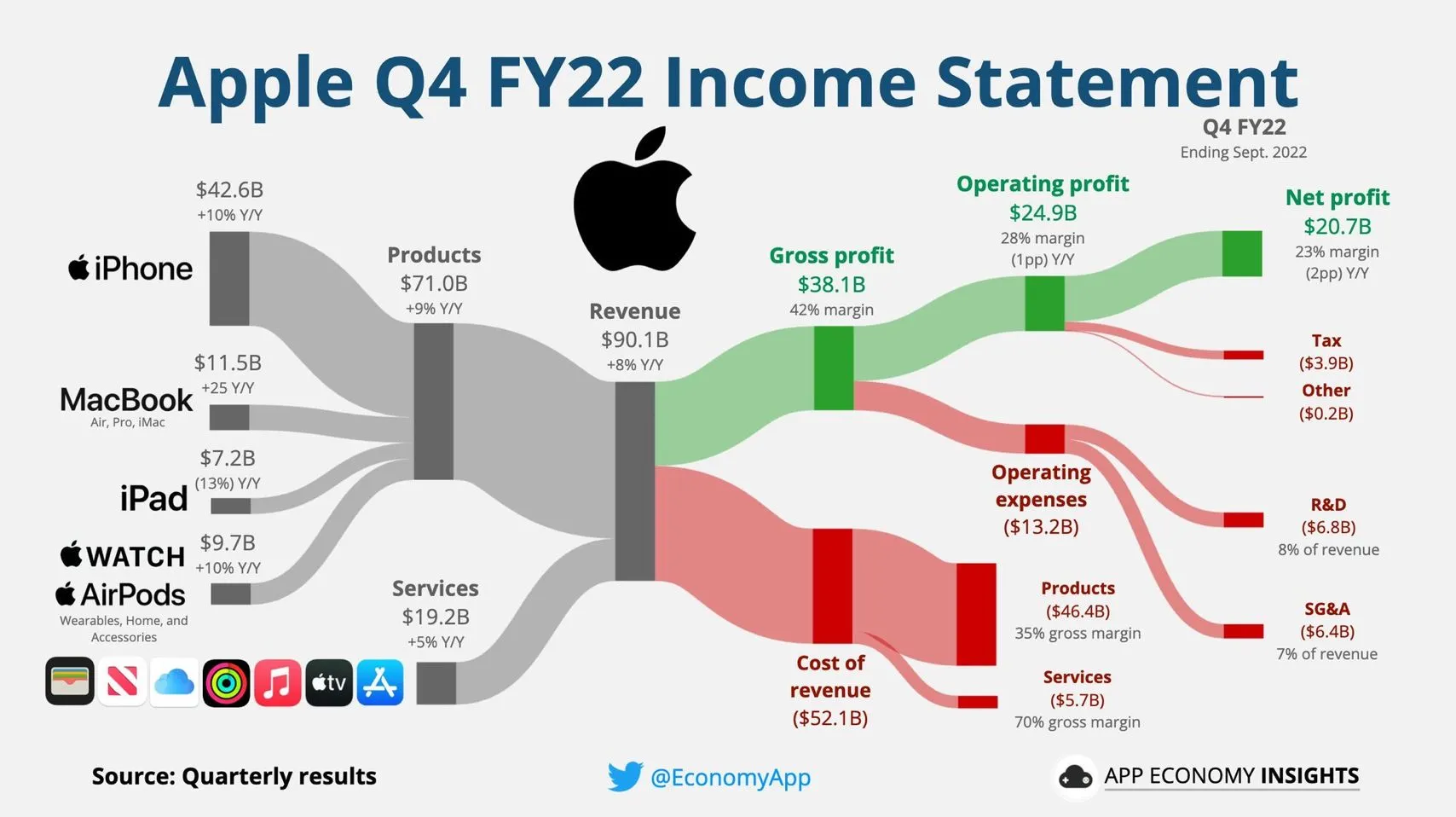
언제 어떤 차트를 사용해야 할까
-
요약 : 6가지의 시각화 주요목적들과 목적에 맞는 다양한 시각화 유형들
-
주요 포인트 :
-
< 1.비교 > 데이터 포인트들 간의 차이점이나 유사점을 보여주고 싶을 때
- 바 차트: 다른 그룹 간의 수치를 비교할 때
- 선 차트: 시간에 따른 데이터 변화를 비교할 때
- 레이더 차트: 다차원 데이터를 비교할 때
(ex.선수들의 경기 능력-속도, 힘, 기술 등)
-
< 2.추세 > 데이터의 시간에 따른 변화를 보여줄 때
- 바 차트: 불연속적인 데이터 포인트가 시간의 흐름에 따라 변하는 모습을 보여주기 위해 (ex. 회사의 분기별 매출)
- 선 차트: 시간의 흐름에 따른 연속적인 데이터의 추세를 나타낼 때
(ex.웹사이트 일일 방문자 수로 방문자 수의 증감 추세를 파악) - 면적 차트: 선 아래 면적 활용
(ex.총량 변화- 연도별 강수량 변화)
-
< 3.구성 > 전체에서 각 부분이 어떤 비중을 차지하는지
- 파이 차트: 전체 중 부분의 비율을 파이의 각도로 표현
(ex.시장 점유율) - 누적 바 차트: 총합을 구성하는 각 부분의 비율을 바의 길이로 표현
(ex.전체 매출 중 각 제품 카테고리가 차지하는 비율을 비교할 때) - 트리맵: 부분의 비율을 사각형 면적으로 나타냄
(ex.웹사이트 트래픽을 다양한 소스별로 구분하여 보여줄 때)
- 파이 차트: 전체 중 부분의 비율을 파이의 각도로 표현
-
< 4.분포 > 데이터가 어떤 범위 내에서 어떻게 분포하는지
⇒ 데이터가 집중되어 있는 부분, 흩어져 있는 부분, 이상치 등을 식별 가능
- 히스토그램: 연속적인 데이터의 각 구간별 빈도수를 나타낼 때
(ex.시험 점수의 분포)
- 박스 플롯: 최솟값, 최댓값, 중앙값과 사분위수를 나타낼 때
(ex.주식 시장에서 가격 변동성, 중간값, 이상치 등을 나타내기 위해)
- 산점도: 두 변수 간의 데이터 분포를 나타낼 때
(ex.다양한 연령대 사람들의 소득 수준을 산점도로 표현→ 특정 연령대에서의 평균 소득 수준이나 소득의 분포 범위를 확인) -
< 5.상관관계 > 변수들 사이의 상호작용, 인과, 상관성 분석
⇒ 데이터가 집중되어 있는 부분, 흩어져 있는 부분, 이상치 등을 식별 가능
- 산점도: 두 변수 간의 상관관계를 나타낼 때 적합
(ex.교육수준-소득)
- 히트맵: 각 셀의 색상 강도를 통해 상관관계 표현
- 네트워크: 개체 간의 관계나 연결망을 시각화
(ex.페이스북에서 사용자들이 어떻게 서로 연결되어있는지, 누가 중심 역할을 하는지) -
< 6.흐름 > 데이터가 시간이나 공간을 통해 어떻게 이동하고 변화하는지 시각화할 때
- 네트워크: 연결선은 흐름의 방향을 나타낼 수 있음.
(ex.감염자 간의 상호작용 및 전염병 전파 경로를 시각화)
- 생키 다이어그램: 양의 흐름과 그 크기를 나타낼 때
(ex.에너지, 자재, 비용등의 흐름을 나타낼 때)
- 스트림 그래프: 시간에 따른 다양한 데이터의 흐름을 연속적으로 나타낼 때
(ex.음악 스트리밍 서비스에서 시간대별 장르별 스트리밍 양을 보여줄 때)인사이트💭
주요 시각화 목적을 6개로 나누어서 각각의 시각화 방법을 살펴보니, 머릿속에 더 정리가 잘 된 느낌이다. 산점도나 바차트 등은 2개 이상의 목적을 달성하기 위해 사용될 수 있다는 점을 알게되어, 목적에 맞게 사용하는 것이 더욱 중요하겠다 라는 생각이 들었다. (단순 그룹간 수치 비교할 것인지, 불연속적 포인트의 데이터들을 시간의 흐름에 따라 나타낼것인지)
또한, 흐름 파트에서 이름을 처음들어보는 차트들도 있었다. 모양은어디선가 봤지만 이름은 몰랐던.! 처음봤지만 예시들이 나와있어서 이해하는데 어렵지는 않았다.
시각화 프로젝트 전에 차트 종류와 내용,방법을 정리해놓아, 조금 더 수월하게 프로젝트를 진행할 수 있을 것 같다는 느낌이 든다.
관련 사례
--
-
데이터 전처리&시각화
3주차
#
import pandas as pd
#
import seaborn as sns
#
data = sns.load_dataset('tips')
data#데이터 저장하기
#index=True가 기본값
data.to_csv("tips_data.csv")
#
df = pd.read_csv('tips_data.csv')
df
df.to_csv("tips_data.csv", index=False).
.
🔻
data.to_csv("tips_data.csv", index=False)(오른쪽)와 차이

.
.
#폴더 생성해서 경로지정
df.to_csv("temp/tips_data.csv", index=False) 
폴더는 여기서 생성 가능 ~!!😊
#pip install openpyxl 터미널 작성후, 엑셀 파일도 생성
df.to_excel("temp/tips_data.xlsx", index=False) #인덱스
#콤마(,)빼먹지마 !!!
df=pd.DataFrame({
'A':[1,2,3],
'B':['a','b','c']
})
df
#인덱스 개별 설정하기
df=pd.DataFrame({
'A':[1,2,3],
'B':['a','b','c']
})
df
🔻
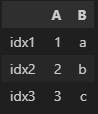
df=pd.DataFrame({
'A':[1,2,3],
'B':['a','b','c']
}, index=['idx1', 'idx2', 'idx3'])
df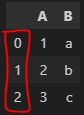
오 !!😮
.
#특정 인덱스만 빼내기
df.loc['idx2']
#'A'를 인덱스로 설정
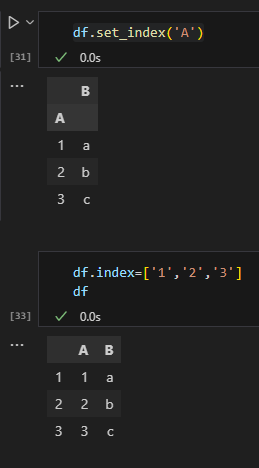
df.set_index('A')
#다시 1,2,3으로 인덱스 설정
df.index=['1','2','3']
#리셋 인덱스
df.reset_index
df.reset_index(drop=True)
차이는 아래와 같다 !!⭐
3-2.컬럼
data = { 'name':['Alice', 'Bob', 'Charlie'],
'age':[25,30,35],
'gender':['female', 'male', 'male']
}
df=pd.DataFrame(data)
df
df['name']
df.columns
df.columns=['이름','나이','성별']
df
df = df.rename(columns={'이름':'name', '나이':'age', '성별':'남/여'})
df
df['스포츠']='축구'
df
del df['스포츠']
df
3-3.데이터 확인
#null값이면 True로 나타남
df.isna()
#B열에서 null값만 불러오고싶다?
df[df['B'].isna()]
#데이터타입 확인
df['total_bill'].dtype
#데이터타입 바꾸기
df['total_bill'].astype(str)
##xx.xx이런 값이 있어서 int로 바로 못바꿈(에러남). 따라서 float으로 바꾸고 다시 int로 바꿈
df['total_bill'].astype(float).astype(int)
df['total_bill'].astype(float)
df['total_bill'].dtypes
#전체 확인하고싶으면 df.dtypes
3-4.데이터 선택 (iloc)
df.iloc[0:4]
#df.iloc[0:5:2] 이렇게도 변형가능(슬라이싱)
#df.iloc[:]
df.iloc[:,0] #행 전체, 열 인덱스0만
# 잘못된 예시 df.loc[2:,'A']
#이유는 인덱스 값이 아니라서
#올바른예시
df.loc['c':,'A']
#iloc는 숫자값으로 슬라이싱, loc는 인덱스랑 컬럼명으로 슬라이싱
추가로,
헷갈림주의 !💥
.iloc(숫자값 슬라이싱)은 마지막 인덱스 포함❌
.loc(인덱스명 슬라이싱)은 해당 값 포함⭕
df.loc[:,'A'] = df['A'] A열에 대해서만 전체 행을 불러오는 표현은 이렇게 2가지로 쓸 수 있다 !
.
.
But,, 여러 개의 열을 불러오고싶을 때
df['A','B'] ❌
⛔오류 이유? KeyError: ('A', 'B')
📌해결방법
1️⃣리스트 형태로 묶어주기
df[['A','B']] ⭕
또는
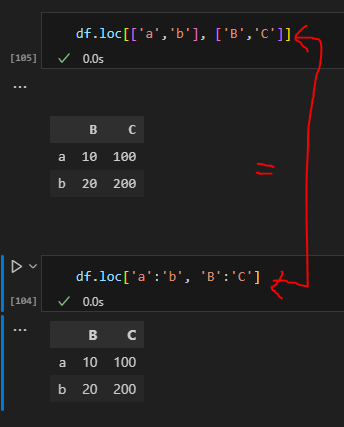
2️⃣ : 이용하기
ex. df.loc['a':'b', 'B':'C']
.
.
불리언인덱싱 => 조건에 참인 것을 불러옴
df[df['sex']=='Male']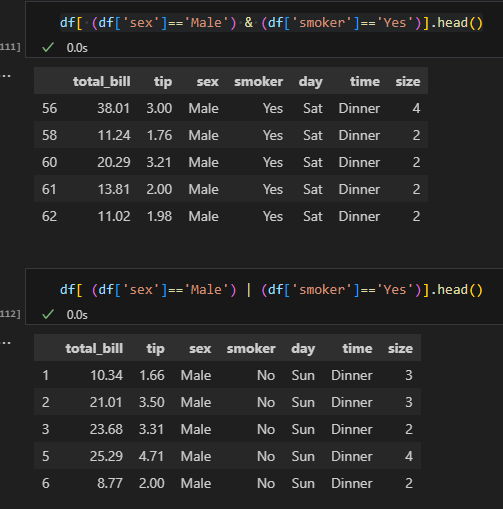
🔺 &(and), |(or) 이용 예시
df.loc[df['size']>3, 'tip':'smoker']
이렇게도 응용가능 .
.
#isin 메서드 활용
#숫자형태
df.loc[df['size'].isin([1,2])]
#문자형태
df.loc[df['day'].isin(['Sun','Thur'])]🔺사이즈가 1,2인 것만 찾기
.
.
그냥 df['tip']<2만 입력하면 True/False인지 판별
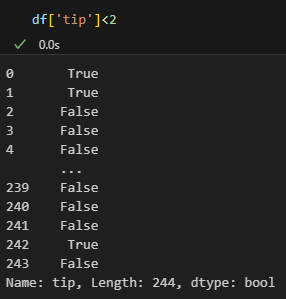
이걸 예를들어 condition이라는 변수에 담고 함수에 넣으면 해당하는 값들만 찾을 수 있다!
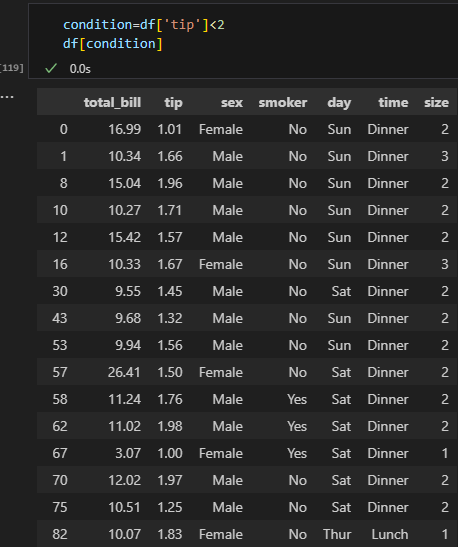
con1=df['size']>=3
con2=df['tip']<2
df[con1&con2]여러 조건을 담아줄 때, 이 방법의 유용성이 더 돋보인다.
**
\역슬래시 기호는 줄바꿈을 도와준다.
ex.
cond=(df['sex'] == 'Male')\
&(df['tip']>3)\
&(df['smoker']=='Yes')\
&(df['total_bill']>=20)\
&(df['size']==4)
df[cond]#object 타입의 created_at을
pd.to_datetime(df['created_at'])
#타입변경
df['created_at']=pd.to_datetime(df['created_at'])
#확인
df.info()
#새로운 컬럼 생성
df['revenue'] = df['total_bill'] + df['tip'] .
.
라이브세션 듣고 3-6 데이터 병합보니까, 강의 자료랑 실습하시는 데이터가 다르고, 강의자료에 올라와있는 예시가 너무 불충분함..
=>라이브 세션 복습 데이터로 직접 실습해볼 필요 있을 것같음
.
.
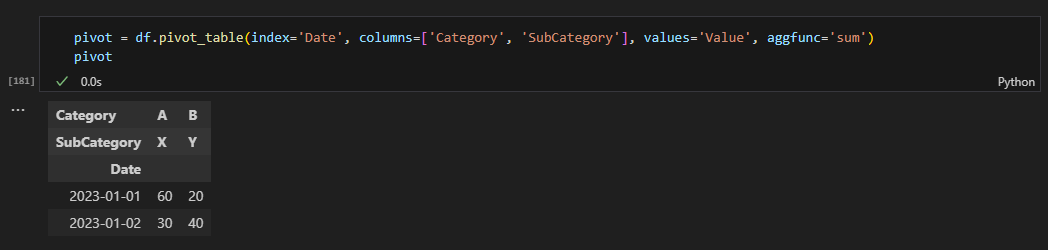
3-6. 데이터 집계
df.groupby('Category').mean()
df.groupby('Category').sum()
df.groupby('Category').count()
df.groupby('Category').max()
df.groupby('Category').min()#카테고리 별 value가 리스트로 묶여나옴
df.groupby('Category').agg(list)
#응용ver
df[['day','total_bill','tip','size']].groupby('day').mean().
.
!! 집계 뒤에 () 소괄호 빼먹지 마 !!
df['size'].mean()왜 값이 .. 원하는 대로 안나오나 했 네.... 바보....
.
.
어랏...?? 왜 !!
강의랑 다르지..? 강의랑 똑같게 df값 넣었는데... NaN값이 나와야하는데.. 안나온다....(이거 문제 아니냐고...)
뭐가 잘못된거지...
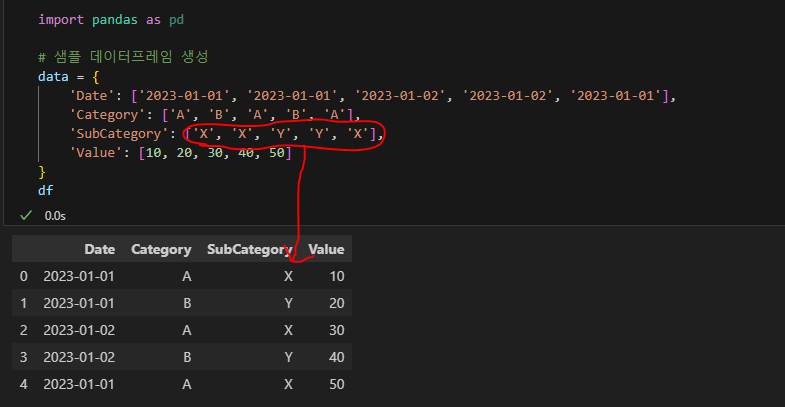
요거 ..오늘 거의 200개를 써서 그런가..??
여기서부터 오류가 있는 듯 하다..😣 (헤맨 시간이 넘 아깝쟈나...)
느낀점&회고
오늘 아티클 스터디는 쫌 특별했다(?) !! 왜냐하면.. 아티클 모음에 있는 링크가 아니었고, 내가 개인적으로 찾은 아티클이었기 때문이다. 다음주에 팀원들과 시각화 프로젝트를 진행해야할텐데, 코드를 학습하고 시각화하는 방법을 아는 것도 정말 중요하지만, '우리가 어떤 내용을 보여주기 위해서 어떤 차트를 활용하는 것이 좋고 또 그 예시는 무엇인지'도 충분히 학습할 필요성이 있다고 생각했기 때문에, 내가 먼저 팀원들에게 아티클 제안을 드렸다 !! 모두 흔쾌히 좋아해주셔서 재밌게 진행했다 ㅎㅎ😊
.
그리고,
오늘 TIL을 보면 알겠지만.. 후반부에 샘플 데이터 프레임 가져오는 것 말고는.. 강의를 보며 코드 하나하나 따라했다.. 시간을 정말 많이쓰고 셀만 200개를 썼다... (중간에 이것저것 해본거 지운거까지 포함하면 200개가 훌쩍 넘을것이다..) 근데 !!! 정말 튜터님 말씀대로 손이 기억을 좀 하는 듯하다..? 아 결측치까지 보고싶은데? 생각만했는데 뭔가 손이 알아서 괄호 안에 dropna=False를 쓰고있었다...!!😮😮😮 (알고리즘보다 판다스가 훨씬 재밌다 후후후)
오늘 라이브세션 내용을 다 복습하지 못했는데, 내일 이 복습까지 하면 !! 뭔가 감은 잡을 수 있을 것 같기도..? 하다ㅏ..(어쩌면 하루종일 세뇌당한걸지도..)
살짝 손도 저리고 뇌도 저리니..오늘은 여기서 마쳐야겠다..
내일 오전에는 QCC(sql)에 집중하고 오후에 다시 파이썬 열공해야지 !!! 🤗💫
