코드카타
sql
📍1581. Customer Who Visited but Did Not Make Any Transactions
.
📍197. Rising Temperature
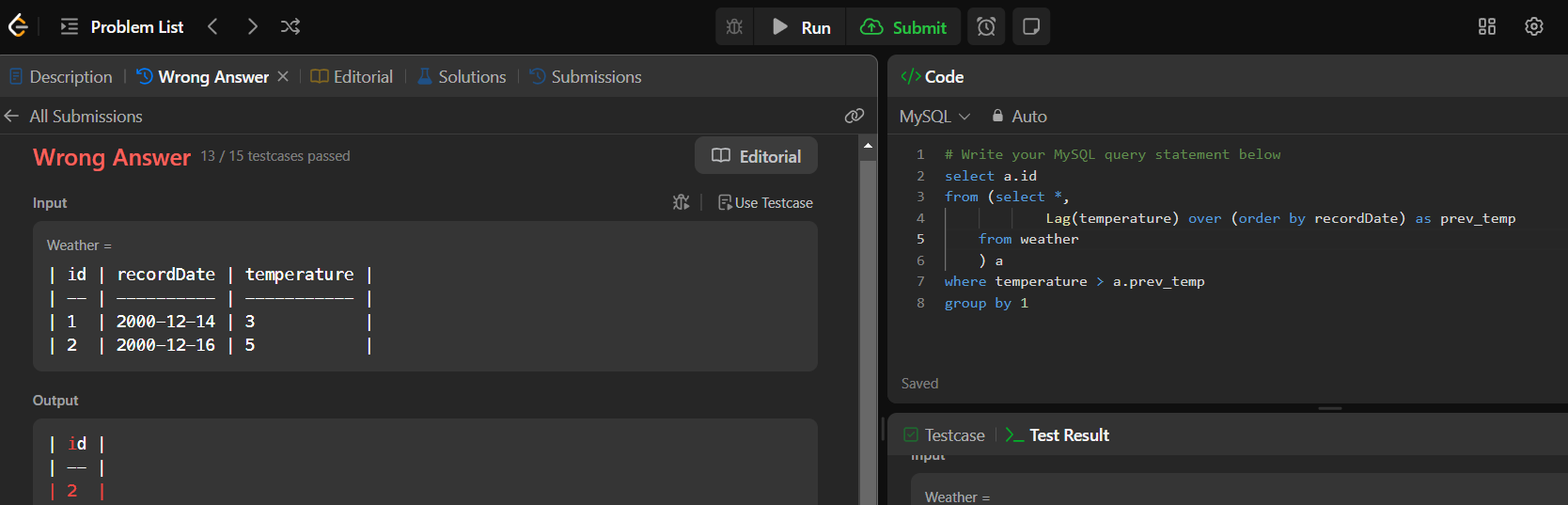
아니 ㅋㅋ 어제라며 !! 왜 2일 간격도 있는건데 !!
아..'어제'라는 조건도...내가..필터링해줘야하는거구나...
select a.id
from (select *,
Lag(recordDate) over (order by recordDate) as prev_date,
Lag(temperature) over (order by recordDate) as prev_temp
from weather
) a
where a.recordDate = date_add(a.prev_date,INTERVAL 1 DAY)
and a.temperature > a.prev_temp
group by 1LAG로 temp만 밀어줬었는데, 날짜 조건도 추가했었어야해서 date도 밀어줬다..!
.
📍1661. Average Time of Process per Machine
select e.machine_id,
round(avg(e.end_time - s.start_time),3) as processing_time
from (select machine_id, process_id, timestamp as end_time
from Activity
where activity_type ='end') e
join
(select a.machine_id, a.process_id, a.timestamp as start_time
from Activity a
where a.activity_type ='start') s
on e.machine_id=s.machine_id
and e.process_id=s.process_id
group by 1QCC
#전년 대비 GNP가 감소한 국가 =전년이 더 큼
#인구가 1천만 명 이상인 국가 수
#이전 연도 GNP =0 이거나 null인 경우 제외
select count(Code) as COUNTRY_COUNT
from country
where GNPOld > GNP
and population >= 10000000
and GNP is not null
and GNP >0select district, round(avg(Population),0) as AVERAGE_POPULATION
from city
where district in (select district
from city
group by district
having count(ID) >= 3)
group by district
order by AVERAGE_POPULATION desc내가 제출한 쿼리의 문제점
group by s.continent having max(s.population)
사실.. 답을 제출할 때 이미 이렇게 작성한 결과가 틀린 값이라는 걸 알고있었다.. 이미 group by로 임의로 묶이고 having이 작동되니까.. 정확한 max를 불러올 수 없다는 걸..
틀릴까봐 불안한 마음에 1,2번 필요 이상의 검토, (쓸데없는)대/소문자 디테일을 챙기느라, 이 사실을 깨달았을 때 나에게 주어진 시간은 충분하지 않았다...
where문으로 서브쿼리를 옮겨도 보고 서브쿼리 안에서 order by desc로 정렬도 해보았건만,, 뭔가 하나씩 뒤틀렸다 !!😳💦
(내 얘기는 그만하고....)
.
max썼을 때, continent랑 population은 잘 나왔는데 city_name, country_name이 다르게 나왔다.
max로 풀거라면,,
- 서브쿼리 안에 있는 max(population)을 on으로 묶어줬어야했다.
max(population)와 continent 둘 다 on으로 조건 걸어줘도 좋다!
🔻
with c as (
select co.continent, max(ci.population) as max_population
from country co
join city ci
on co.code=ci.countrycode
group by 1
)
select ci.name city_name, co.name country_name, co.continent, ci.population
from country co
join city ci
on co.code=ci.countrycode
join c
on c.continent = co.continent
and ci.population = c.max_population
order by 4 desc🩵튜터님's tip
:[max만 가져오는게 아니라 max가 포함된 다른 정보들도 가져와야한다면
rank 쓰는게 좋음]
rank() over (partition by - order by -)
select city_name, country_name, continent, population
from (select ci.name as city_name, c.name as country_name, continent, ci.population,
rank() over(partition by continent order by ci.population desc) as rk
from city ci
join country c
on ci.countrycode = c.code
) a
where rk = 1
order by 4 descwith 구문으로 접근하기
with a as (select ci.name as city_name, c.name as country_name, continent, ci.population,
rank() over(partition by continent order by ci.population desc) as rk
from city ci
join country c
on ci.countrycode = c.code
)
select city_name, country_name, continent, population
from a
where rk = 1
order by 4 desc라이브세션_3회차 복습
| 메서드 | 기준이 되는 DataFrame | 어떻게 합쳐질까? | 공통된 열 필요? | 주요 사용 예시 |
|---|---|---|---|---|
join() | 왼쪽 DataFrame (df1.join(df2)) | 왼쪽을 기준으로 오른쪽을 붙임 (인덱스 기준) | ❌ (기본적으로 인덱스 기준) | 인덱스를 기준으로 데이터를 합칠 때 |
merge() | 따로 없음 (on=으로 기준 정함) | 공통된 열을 기준으로 합침 (SQL의 JOIN처럼) | ✅ (기본적으로 on= 필수) | 두 DataFrame에서 공통된 값을 기준으로 합칠 때 |
concat() | 따로 없음 | 그냥 위아래(행)나 좌우(열)로 단순히 이어붙임 | ❌ (그냥 인덱스 기준으로 정렬) | 데이터를 쌓을 때 (예: 여러 개의 비슷한 데이터 합칠 때) |
.
.
⭐ values 에 리스트를 입력 할 경우 → 각 값에 대한 테이블이 연속적으로 생성됩니다.
🔺이 말을 예시로 이해해보자.
1. 일단 샘플데이터가 딕셔너리 형태라면,
import pandas as pd
# 샘플 데이터 생성
data = {
'지점': ['서울', '서울', '부산', '부산', '대구', '대구'],
'년도': [2023, 2024, 2023, 2024, 2023, 2024],
'매출': [100, 150, 200, 250, 180, 220],
'이익': [20, 30, 50, 60, 40, 55]
}
df = pd.DataFrame(data)
# pivot_table 사용 (values에 '매출'과 '이익'을 리스트로 입력)
pivot = df.pivot_table(index='년도', columns='지점', values=['매출', '이익'])
print(pivot)🔻
매출 이익
지점 대구 부산 서울 대구 부산 서울
년도
2023 180 200 100 40 50 20
2024 220 250 150 55 60 30🔥 여기서 핵심 포인트
values=['매출', '이익']을 넣으면
→ 매출에 대한 테이블, 이익에 대한 테이블이 연속적으로 출력!
즉, 지점별 '매출' 테이블과 '이익' 테이블이 같은 구조로 나란히 정렬된다!
--
✅cf. 딕셔너리 장점
pandas.DataFrame()을 사용할 때,
딕셔너리를 넣으면 자동으로 열(column)과 값(value)을 매칭해서 DataFrame을 만들어 준다.
즉, 키(key)는 열 이름, 값(value)은 각 행(row)의 데이터 리스트가 된다!
.
2.샘플 데이터가 리스트 형태라면,
df = pd.DataFrame(
[
['서울', 2023, 100, 20],
['서울', 2024, 150, 30],
['부산', 2023, 200, 50],
['부산', 2024, 250, 60],
['대구', 2023, 180, 40],
['대구', 2024, 220, 55]
],
columns=['지점', '년도', '매출', '이익'] # 컬럼 이름 지정
)이중리스트형태여도 columns 지정해주면 1번과 같은결과가 나온다.
✅cf.리스트 형태는 "행(row) 중심"으로 만들기 좋다!
💠lambda
기본적으로 람다의 존재는 알고 있었지만, 다른 함수와 같이 사용된 예시는 처음보는 거였다,,!
# lambda 함수를 이용한 정렬
mylist = ['apple', 'banana', 'cherry']
mylist2 = sorted(mylist, key=lambda x: len(x))
print(mylist2)이해 했는데,
갑자기 sort()와 sorted()가 궁금해졌다.
🔽
sort() :: list.sort() method is only defined for lists
⭐기존의 리스트를 정렬, 리스트 내에서만 정의될 수 있음
sorted() :: the sorted() function accepts any iterable.
⭐새로운 정렬된 리스트를 만들어낸다.
아, 그래서 mylist2라는 새로운 변수에 담아준거구나 !
.
💠split
.split('.') 로 작성하면 .구분자를 기준으로 데이터를 나눈다는 사실!
근데 그 밑에 이러한 예시가 있었다.
# df 에 x 컬럼추가
df2['x']="aa.bb.cc.dd.ee.ff.gg"이것의 결과는,
id x
0 1 aa.bb.cc.dd.ee.ff.gg
1 2 aa.bb.cc.dd.ee.ff.gg
2 3 aa.bb.cc.dd.ee.ff.gg이렇게 나온다.
이걸 왜?
나중에 .split()을 써서 문자열을 분리할 때 사용할 수 있는 데이터 형태를 만드는 과정!
# "x" 컬럼을 "."을 기준으로 분리
df2['x_split'] = df2['x'].str.split(".")
print(df2)
#실행결과
id x x_split
0 1 aa.bb.cc.dd.ee.ff.gg ['aa', 'bb', 'cc', 'dd', 'ee', 'ff', 'gg']
1 2 aa.bb.cc.dd.ee.ff.gg ['aa', 'bb', 'cc', 'dd', 'ee', 'ff', 'gg']
2 3 aa.bb.cc.dd.ee.ff.gg ['aa', 'bb', 'cc', 'dd', 'ee', 'ff', 'gg']각 행마다 다른 값을 넣고 싶다면, 리스트 형식으로 넣자!
import pandas as pd
# 샘플 데이터 생성
df2 = pd.DataFrame({'id': [1, 2, 3]}) # 기존 DataFrame
# 각 id별로 다른 값을 할당
df2['x'] = ["aa.bb.cc", "dd.ee.ff", "gg.hh.ii"]
print(df2) id x
0 1 aa.bb.cc
1 2 dd.ee.ff
2 3 gg.hh.ii위와 동일하게 split 사용하면,
df2['x_split'] = df2['x'].str.split(".")
print(df2)
#실행결과
id x x_split
0 1 aa.bb.cc ['aa', 'bb', 'cc']
1 2 dd.ee.ff ['dd', 'ee', 'ff']
2 3 gg.hh.ii ['gg', 'hh', 'ii']개인과제
5️⃣번
답을 고치려고 한 50번 수정하다가 얻어걸려서 이게 왜 제대로 나오는지도 모름...
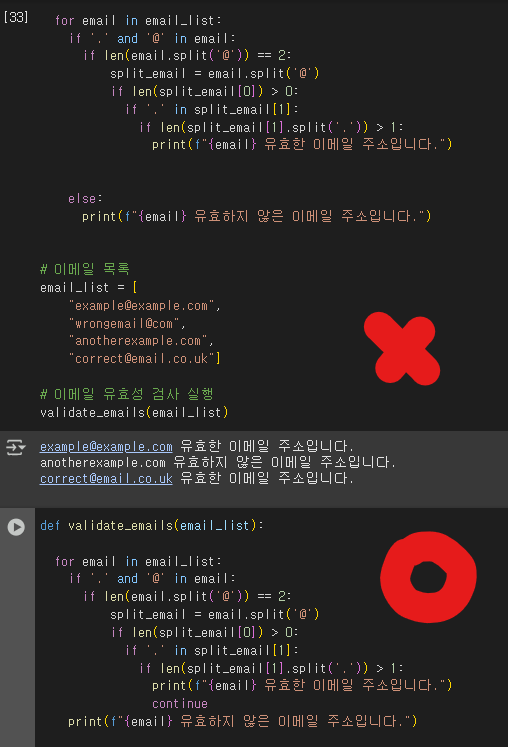
#실행결과
example@example.com 유효한 이메일 주소입니다.
wrongemail@com 유효하지 않은 이메일 주소입니다.
anotherexample.com 유효하지 않은 이메일 주소입니다.
correct@email.co.uk 유효한 이메일 주소입니다.일단 비교하면서 더 공부해봐야겠다..!
6,7번은 건들긴 했는데... til에 쓸 정도로 완성하지는 못해서... wil에 올리거나 과제 풀이 복습하면서 같이 올려야겠다..😵😵😵
느낀점&회고
코드카타 해설을 듣고 점심을 먹고 나니.. 집중이 잘 안돼서... 바로 짐싸서 카페로 나갔다.. 확실히 공간이 바뀌니 환기할 수 있었다.
.
1. sql과 python을 둘 다 잘 쓰기 위해서.. 시간 분배에 신경써야할 것같다. 주말동안 고민해봐야겠다. 그리고 앞으로 코드카타도 sql만큼은 시간을 재면서 해봐야겠다..
2.틀렸다면 어떻게 요리조리 고쳐가면서 accept만 시키지말고, 어디서 왜 틀렸고 어떻게 해결했는지, 다시 안틀리려면 어떻게 할 것인지까지 til에 기록해야겠다. QCC에서는 정답인지, 오답인지 알 수가 없으니까 말이다...
3.아 !! 그리고 이렇게 시간관리 능력을 기름과 동시에 !! 튜터님(해설맨 ㅋㅋ🩵🩵)이 항상 하시는 것처럼 max, min등을 이용해서 값의 range를 구해서 제대로 값이 나온건지를 확인한다던가.. 이런식의 사고 능력도 길러봐야겠다!!!⭐⭐⭐
.
참 여러모로 배우는게 많은 한 주였다. 🫠☁️
"I am not afraid of storms for .
I am learning how to sail my ship ."
.
-Helen keller-
