
코드카타
- Managers with at Least 5 Direct Reports
where id in( 서브쿼리 )를 사용해서 풀어줬다.
❌겪었던 오류
where id =( 서브쿼리에서 구한 manageid )로 했을 때는 Testcase에선 Accepted 됐지만,
4/11 에서 런타임 에러가 났다.
🔻🔻🔻
학습 회고 💭
- 두 코드의 주요 차이점
- 첫 번째 코드
(IN 사용)
:id IN (서브쿼리)는 서브쿼리가 여러 개의 managerid를 반환할 수 있는 경우에도 동작. 즉, 다중 행 결과를 처리 가능. - 두 번째 코드
(= 사용)
:id = (서브쿼리)는 서브쿼리가 정확히 하나의 값만 반환해야 함. 다중 행이 반환되면 오류 발생.
Testcase 1~3에서는 우연히 단일 행만 반환되어 Accepted 된 걸로 추정,
testcase에서는 다중 행이 반환되며 = 연산자가 이를 처리하지 못해 런타임 오류 발생.
⭐핵심 교훈 !!
단일 값 비교에는 =, 다중 값 비교에는 IN을 사용해야 함. 서브쿼리 결과 행 수를 예측하고 적절한 연산자를 선택하는 것이 중요하겠다.
.
- Confirmation Rate
select a.user_id
, round(sum(a.act)/count(a.user_id),2) as confirmation_rate
from (select s.user_id,
case when action='timeout' then 0
when c.user_id is null then 0
else 1
end as act
from signups s
left join confirmations c
on s.user_id= c.user_id
) a
group by a.user_id휴 하나씩 차근차근 돌려보면서 하니까 할만했다.
.
- Not Boring Movies
후 잠깐 쉬었다가는 느낌~
.
- Average Selling Price
select p.product_id
, round((sum(u.units*p.price)/sum(u.units)),2) as average_price
from prices p
join UnitsSold u
on p.product_id = u. product_id
where price in ( select price
from prices p
join UnitsSold u
on p.product_id = u. product_id
where p.start_date <= u.purchase_date <= p.end_Date
)
group by 1 맨처음에 이렇게 작성했었는데, 오답이었다. ㅜ
날짜를 넣어서 추가로 조회해보니, purchase 데이터와 end 데이터가 맞지 않았다🔻
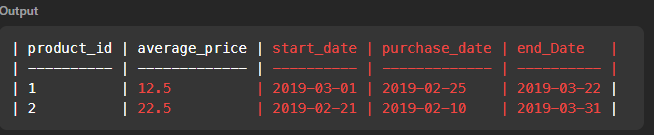
아.. price만 조건 먹이고 .. 그리고 where도 저렇게 연속 부등호를 사용하면 안될 때가 있다고 한다. (하나씩 연결해주는 게 안전)
.
이건 좀 찾아볼 필요가 있는 것 같아서, 구글링을 해봤더니
on절에 날짜 조건을 같이 써준것이다 !!
나는 공통걸럼만 되는 줄 알았는데.. 생각해보니까 예전에 LAG를 사용해서 묶을때 on절에
e. 작년 + 1 = d. 올해뭐 대충 이런식으로 간단한 연산자까지 넣었던게 기억이 났다 ~!!
무튼 그래서 1차수정🔻
select p.product_id
,round((sum(u.units*p.price)/sum(u.units)),2) as average_price
from prices p
left join UnitsSold u
on p.product_id = u. product_id
and p.start_date <= u.purchase_date
and u.purchase_date <= p.end_Date
group by 1test결과는 accept돼서 바로 실행돌려봤는데,,,
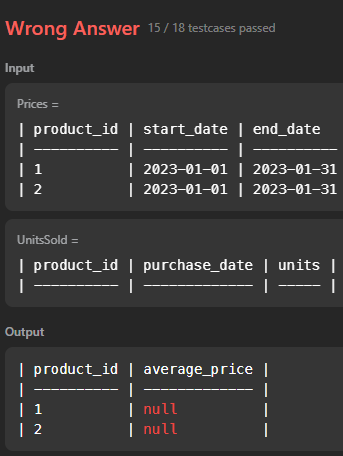
널값 처리도 안해줬었네... ifnull 추가해줬다.
select p.product_id
,ifnull(round((sum(u.units*p.price)/sum(u.units)),2),0) as average_price
from prices p
left join UnitsSold u
on p.product_id = u. product_id
and p.start_date <= u.purchase_date
and u.purchase_date <= p.end_Date
group by 1되게 잔잔바리 조건이 많았던 문제 같아서, 배울점이 있었던 것 같다.
.
📌효원님의 풀이
효원님이 예전에 푸셨던 것 같아, 찾아봤는데 COALESCE을 사용하신 것도 인상적이었다 !!!!👍👏
.
.
- Project Employees I
가볍게 풀었다.
파이썬 개인과제 해설
%_문자열 포맷팅 자릿수 지정
%d는 정수로, %f는 실수로, %s는 문자열을 포맷팅
-
정수
%5d 처럼 쓰면 5자리를 빈공간으로 채워 포맷팅
%05d처럼 쓰면 5자리에서 앞 자리를 0으로 채워 나타내줌 -
실수
%.2f 처럼 몇번째 자리까지 나타낼 것인지
(마지막 자리는 그 다음자리의 숫자가 반올림된 결과를 반영하여 포맷팅)

8번문제 못풀었던거 해설 + 입문자용 추가문제 올려주신거 하고싶었는데.. 오늘 일정이 넘 빡빡해서...주말에 해야할 것 같다 ㅠㅠ
아티클스터디
오늘의 아티클
파이썬 초보자가 저지르는 실수 10가지
.
- 요약 : 초보자가 자주 저지르는 실수 10가지
- 주요 포인트 :
-
import *로 모든 모듈을 함께 불러옴
:불러오는데 오랜 시간이 걸리거나 변수간 충돌 발생 가능 -
except절에 예외를 지정하지 않음
:권장되지 않는 사항이며, try/except를 사용할 때에는 except 절에 예외를 꼭 작성해야함 -
수학계산에 Numpy를 사용하지 않음
: 벡터 기반 Numpy가 for 루프(연산)보다 효율적이고 빠름 -
이전에 열었던 파일을 닫지 않음
: with구문을 사용하여, 예외가 발생하더라도 정상적으로 파일을 닫을 수 있게하기with open('dataset.txt', 'w' as f: f.write('new_data') -
PEP8의 가이드라인을 벗어남
: 파이참을 사용할 때 PEP8 가이드라인에 따르지 않은 경우, 밑줄이 뜸. 이 밑줄에 마우스를 가져다 대면 수정 가이드를 제시해줌. -
딕셔너리를 사용할 때
.keys,.values를 적절하게 사용하지 않음
: print(key), print(value) 로 단순히 표현 가능 -
컴프리헨션을 아예 사용 안하거나 언제나 사용하거나
: 매우 효율적이기에 사용하는 것이 좋지만, 정도를 넘는 과도한 사용은 비추 -
range(len())사용
:enumerate/ 두가지 리스트를 함께 반복하는 경우zip을 활용해 더 효율적으로 처리할 수 있음 -
+연산자를 사용한 문자열 연결
: f-string을 사용하자 -
Mutable value를 디폴트 매개 변수로 사용할 때
:Mutable value 를 리스트라고 할 때, 정의한 함수를 호출할 때마다, 리스트는 이전 호출의 값을 계속 저장한다. 따라서 이럴 땐, 리스트의 디폴트 값을 None으로 설정하고 if구문을 아래에 추가해줘야한다.# 실수 상황 def my_function(i,my_list=[]): my_list.append(i) return my_list # 해결방법 def my_function(i,my_list=None): if my_list is None: my_list = [] my_list.append(i) return my_list >>> my_function(1) [1] >>> my_function(2) [2] >>> my_function(3) [3]인사이트
이 아티클에서 언급된 10가지 실수 중에서,
내가 하고있는 실수도 있었고, 아직 파이썬 기능을 다 알지 못해 이해가 안가는 실수도 있었다. 그래서 더더욱 잘 정리해두고, 계속 공부하면서 두고두고 읽어봐야겠다. 코드를 같이 작성되어있어 직관적으로 비교 및 이해를 할 수 있었다.
파이썬 개인과제를 복습하면서 오늘 아티클 스터디 내용도 같이 참고해야겠다 !
-
Pandas 라이브세션
내일 실습수업을 나갈 예정이니,
오늘은 이론을 간단하게 정리해야겠다.
대학교 통계 수업을 잘 들어놓은 덕에.. 그나마 숨쉴 틈은 있었다. (이것도 아녔으면..진작 멘붕이었을 듯 ㅠ)
🚩 이상치(Outlier) 는 전체 데이터 범위에서 벗어난 값을 의미하는데, 일반적으로는 정규분포를 기준으로 판단한다.
🚩 결측치(Missing Value) 는 데이터 수집 과정에서 누락되거나 잘못 입력 된 값을 뜻한다.
02.결측치 파헤쳐보기
결측치 처리는 크게 두가지 방법으로 나뉜다.
보편적으로 1.제거, 필요상황에 따라 2.대체 가 있다.
제거를 위한 주요 코드
# 컬럼별 결측치 총합 몇개인지
df3.isnull().sum()
# 결측치가 있는 행들은 모두 제거
df3.dropna()
#또는
df3.dropna(axis=0, how='any')
# 전체 행이 결측값이거나 결측값이 너무 많아 열 자체를 삭제해주고 싶을 때
df3.dropna(how='all')
# 마지막에, 결측지 잘 제거됐나 확인해보기
df3.isnull().sum().
.
대체를 위한 주요 코드
[범주형변수라면..]
최빈값으로 대체 => .mode 이용
[수치형변수라면..]
중앙값, 평균값
그외, 인접한 행의 값 이용
# df3 의 Interaction type 컬럼을 fillna함수를 이용하여 채워줄건데,
# mode() 함수를 사용하여 최빈값을 넣어주기.
# [0]을 통해 시리즈(mode output형태) 중 단일값을 가져오기.
df3 = df3['Interaction type'].fillna(df3['Interaction type'].mode()[0])
# 결측치 대체: 평균값
# sw는 임의 컬럼명이라는 점 참고하기
df['sw'] = df['sw'].fillna(df['sw'].mean())
df.isnull().sum()
# 결측치 대체: 중간값
# inplace=True 로 하면 원본 데이터가 바뀜
df['sw'] = df['sw'].fillna(df['sw'].median())
df.isnull().sum()
# 결측치 대체: 바로 위 값으로 대체
df['sw'] = df['sw'].fillna(method='ffill')
df.isnull().sum()
# 결측치 대체: 바로 아래 값으로 대체
df['sw'] = df['sw'].fillna(method='bfill')
#df.isnull().sum()참고로, inplace=True 로 하면 원본 데이터가 바뀜
이부분에 대한 설명을 덧붙이자면,
기본값은 inplace=False이다.
구글링을 좀 하다보면, inplace=True를 굳이 사용하는 것은 권장하지 않는다는 글들이 종종 보인다.
🔻이유
버그를 일으킬 가능성이 있는 위험한 방법이므로 사용할 이유가 없다.
inplace = True를 사용한다고 해서 성능 향상에 큰차이가 없다.
가독성 좋은 pandas코드를 위해서는 사용하지 않는것이좋다.
추후에 업데이트 되면서 사용하지 않을 가능성이 높다.
나역시도 복습하다가
이부분을 간과하고 데이터를 날려본 입장으로써...😮
프로젝트에서도 아주아주 특별한 이유가 있지 않는 한 이건 잘 사용하지 않을 것 같다.
03. 이상치 파헤쳐보기
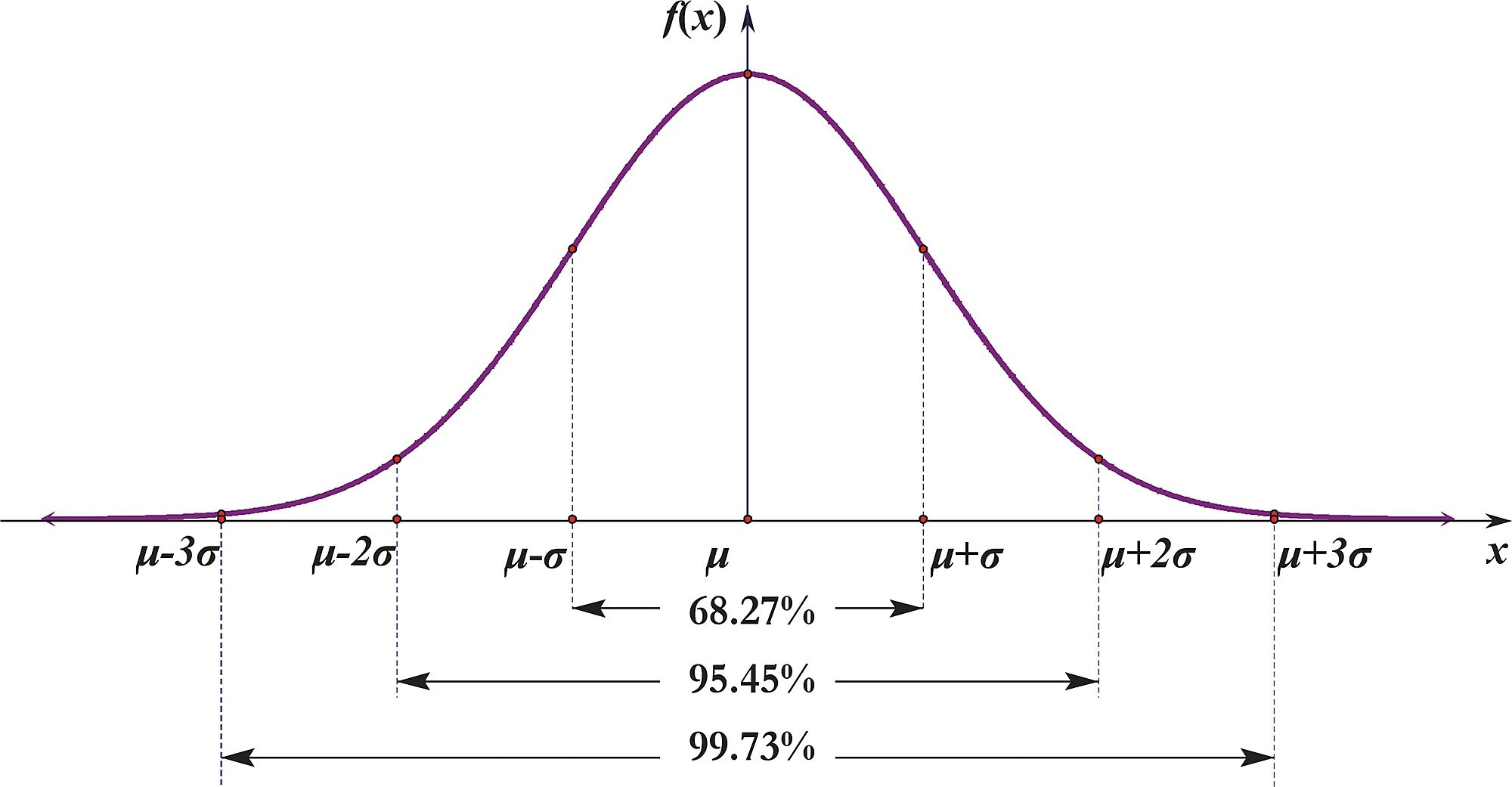
1. z-score
: 해당 데이터가 평균으로부터 몇 표준편차만큼 떨어져있는 지를 알려준다. 일반적으로 95% 신뢰수준을 사용하고, 'Z-score 1.96'을 사용하면 된다.
2. IQR(Inter Quartile Range)
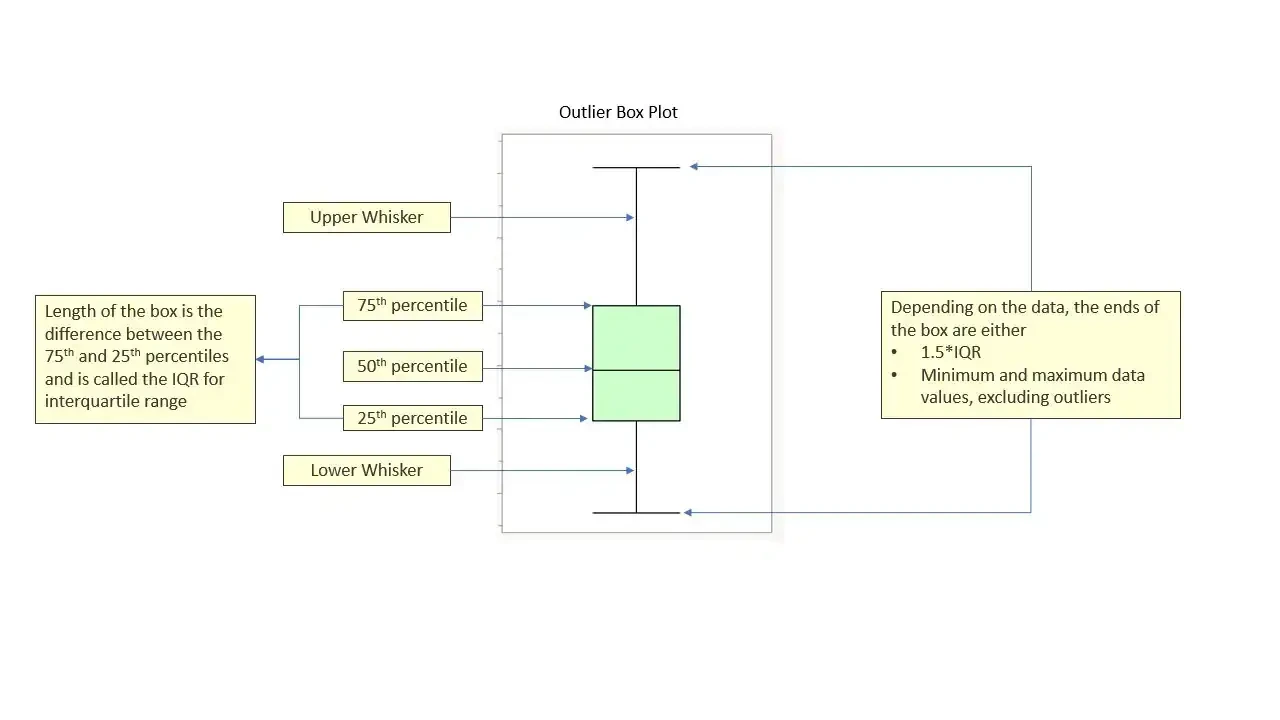
-
Q3 : 100개의 데이터로 가정 시, 25번째로 높은 값에 해당.
-
Q1 : 100개의 데이터로 가정 시, 75번째로 높은 값에 해당.
-
IQR : Q3 - Q1의 차이를 의미.
-
이상치 : Q3 + 1.5 IQR보다 높거나 Q1 - 1.5 IQR보다 낮은 값을 의미.
.
.
앞으로 나는
fillna( )를 통해 결측값을 채우기도,dropna( )를 통해 결측값을 지우기도,replace( )를 통해 값을 변경하기도 할 수 있어야한다.
느낀점&회고
생각보다 .. 오늘 일정이 빡빡했다...
1.코드카타 막혀서 구글링하다가
2.파이썬 과제 해설 불려갔다가
3.점심먹고
4.아티클 스터디..
5.코드카타 막힌거 해결했더니
6.판다스 라이브세션 듣고나니 16:30..
7.줌 들은거 코드 복습 +정리 좀 하다가
8.저녁먹고
9.과제 좀 보다가(과제가 어려워서라기보다는 그냥 뇌가 멈춤)
10.TIL 작성ADHD의 하루인가요 ????
되게 뭐 하나를 진득하게 할 수 없는 일정이었던 것 같다..!!
.
이번주가 되게 고비인 것 같다. 이번주 잘 버티면 프로젝트도 잘 시작할 수 있을 것 같고,
여기서 밀리면 프로젝트까지 영향이 가고 ... 4월에도 힘들 것 같다.
My brain is in overdrive
내일은 더 화이팅🥨


헉 영광입니다 ㅎㅎ 저도 잘 보고 배우고 있습니다 우수 TIL 선정 축하드려요~~👏