코드카타
SQL
- Employee Bonus
where bonus<1000 or bonus is null
- Students and Examinations
📌이 문제의 포인트는, 시험에 응시하지 않아도 count가 0으로 결과에 포함되어야하는 것 같다.
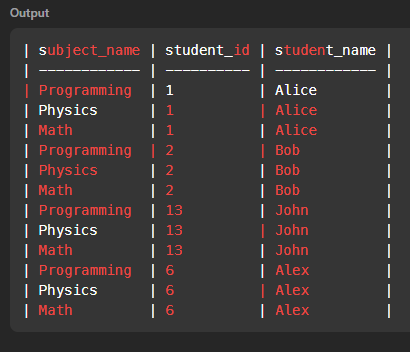
🔺
from subjects s cross join students st 의 결과
cross join으로 과목이름들을 다 불러오긴 했지만..
밑에 바로 left join으로 다중조인해주는 것, e.student_id 를 count 하는것을 여러 시도 끝에 알게되어.....생각보다 너무 오래걸렸다...
select st.student_id, st.student_name, s.subject_name,
count(e.student_id) as attended_exams
from subjects s
cross join students st
left join examinations e
on s.subject_name=e.subject_name
and e.student_id = st.student_id
group by 1,3
order by 1,3난 언제쯤.. sql을 잘할 수 있을까...
python라이브세션 복습
✅테이블결합 복습
- ⏩ merge
#컬럼명 같을 때
merge_df = pd.merge(df2,df3, how='inner',on='Customer ID')
#컬럼명 다를 때
merge_df = pd.merge(df2,df3,how='inner', left_on='Customer ID', right_on='user id')공통 컬럼이 다를 때, 둘다 그대로 유지되다 보니 컬럼 수가 1개 더 많이 조회됨을 알 수 있었다.
공통 컬럼 없을 때
- ⏩ join
그냥 갖다 붙임
df.join(df3, how='right')오른쪽에 단순 결합! (인덱스 기준)
-
⏩ concat (함수)
예시형태
pd.concat([df2,df3]) -
⏩ append (메서드)
df2.append(df3)는
pd.concat([df2,df3])와 같은 의미! -
⏩ pivot_table
🤔 --축으로 ~~별 !! 개수* 구하기
pd.pivot_tabel(데이터명, index='--', columns='~~', value='!!', aggfunc='count'실습예제로 해본 aggfunc 기능확인은 아래와 같다.
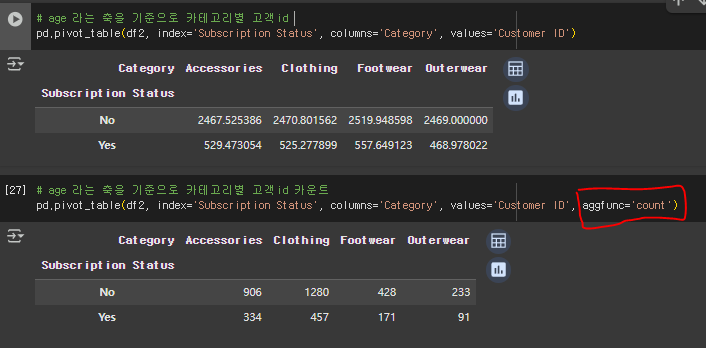
🔻문제만 보고 풀어보기
사용 데이터명: df2
# age, Category 라는 축을 기준으로 성별 Previous Purchases 최소, 최대, 평균, 중앙값 구하기
pd.pivot_table(df2, index=['Age','Category'], columns='Gender', values='Previous Purchases', aggfunc=['min','max','mean','median'])
# 성별을 축으로 하고, 사이즈, 나이별 고객id 고유하게 카운트
pd.pivot_table(df2, index='Gender', columns=['Size','Age'], values='Customer ID', aggfunc='nunique')- ⏩ lambda
#람다를 사용한 실습 예제
mylist = ['apple', 'banana', 'cherrycherry','kiwi','orange','watermellon']
mylist2 = sorted(mylist, key=lambda x: len(x))
#my list len(x)역순으로 정렬하기
#sort()이용 ver
#1.
mylist.sort(key=lambda x: len(x), reverse=True)
#2. [::-1] 이용은 먼저 길이순 정렬 뒤, 뒤집어야함
mylist.sort(key=lambda x: len(x))
mylist = mylist[::-1]
#단독으로 길이기준 정렬 못하고 sort()와 조합해야함
#알파벳이 기준이면, 한줄로 가능🔻
#mylist = mylist[::-1]
#sorted() 이용 ver
mylist2 = sorted(mylist, key=lambda x: len(x), reverse=True)
- ⏩ split
#기본 구조
.split('.')
#실습예제
st="aa.bb.cc.dd.ee.ff.gg"
st.split('.')
#결과
#['aa', 'bb', 'cc', 'dd', 'ee', 'ff', 'gg']
st.split('.')[6]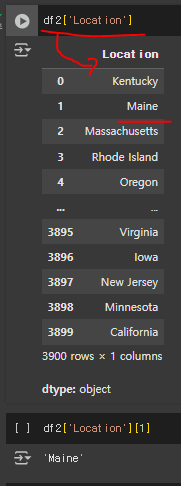
# . 으로 쪼갠 것 중 인덱스 2번에 해당하는 값은?
df2['x'][0].split('.')[2]
#cc
# .으로 쪼갠 문자덩어리 개수는?
len(df2['x'][0].split('.'))
✅inline if
inline if
사용구조
🔻
결과값(조건만족할 때) if 조건 else 조건안만족할 때
if 있고 없고 차이가 궁금했는데 range(7)일땐, 있고 없고의 차이가 없었다.
하지만, 범위를 바꿔서도 해봤을때,
aa.bb만을 x로 지정해서 range(3)으로 했을 때,
if 구문을 안써주면
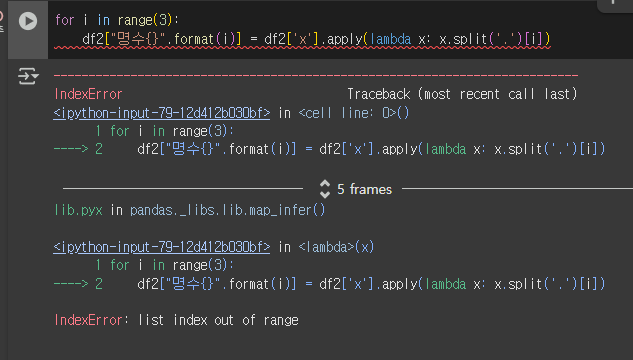
이런 범위에 대한 인덱스 오류가 발생했다.
- ⏩ rrule
start_date = datetime(2024, 2, 1)
end_date = datetime(2024, 3, 1)
daily_rule = rrule(WEEKLY, dtstart=datetime(2023, 2, 1), until=datetime(2023, 3, 1))
a=[]
for date in daily_rule:
a.append(date.strftime('%Y-%m-%d'))
print(a)
#strftime:date_format과 유사(객체를 지정한 문자열 포맷으로 변환)
mask =(df3['Time stamp2'].isin(a))
✅ isin(a)의 역할
df3['Time stamp2']: 이 컬럼의 각 값을 하나씩 확인.
.isin(a): 해당 값이 a라는 변수(예: 리스트, 집합 등)에 포함되어 있는지 체크.
결과: 각 행에 대해 True 또는 False를 반환하는 불리언
✅.dt
복습한 코드 [str 날짜를 datetime64로 변환후 다시 str로 변환]
df3['Time stamp2'] = pd.to_datetime(df3['Time stamp'], dayfirst=True).dt.strftime('%Y-%m-%d').
📌.dt:
datetime64 객체에 접근할 때 사용하는 속성. 이를 통해 날짜/시간 관련 메서드(예: strftime, year, month 등)를 호출 가능.
.
데이터 전처리&시각화
import matplotlib.pyplot as plt로 불러와주고!
선그래프를 그리기 위해서
plt.plot(x, y)
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.title('Example Plot')
plt.show()가 필요하다.
- 🔻seaborn 에서 데이터셋을 불러오는 코드 !
import seaborn as sns
# 'flights' 데이터셋 불러오기
flights_data = sns.load_dataset('flights')
# 데이터셋 확인
print(flights_data.head())- 🔻선 그래프 그리기_ 실습ver
#데이터입력
df=pd.DataFrame({
'A': [1,2,3,4,5],
'B': [5,4,3,2,1]
})
df
#그리기
df.plot(x='A',y='B')
plt.show()- 🔻 스타일 설정
#아래와 같이 사용가능
df.plot(x='A', y='B', color='green', linestyle='--', marker='o')
#라벨도 붙여줄 수 있다 !
label='Data Series'
#legend 메서드로도 구현 가능
ax.legend(['Data Series'])라벨이 머냐면,,

- 🔻 축,제목
ax.set_xlabel('X-axis Label')
ax.set_ylabel('Y-axis Label')
ax.set_title('Title of the Plot').
- 🔻 텍스트를 추가해서 강조해주기!
ax.text(3,3, 'Some Text', fontsize=12)
#여러개 넣고 싶으면 아래로 계속해서 적어주면 된다
ax.text(2,2, 'other Text', fontsize=10).
- 🔻 사이즈 설정
plt.figure(figsize=(18,6))만약, 잘 안바뀌는 것 같다.??
❌원인=> plt.figure에 대한 사이즈랑 만든 plot에 대한 사이즈 자체가
같은 figure가 아니기 때문.
subplots으로 해결해줄 수 있다.
fig, ax = plt.subplots(figsize=(12,6))
ax=df.plot(x='A', y='B', color='red', linestyle='--', marker='o', ax=ax)
.
.
.(아래 내용)느낀점&회고
오늘 유난히 피곤했다. 졸거나 학습을 중단했던 건 아니었지만,
학습에서 느끼는 뿌듯함이나 성취감이 없었다. 그냥 해야돼서 하는 느낌.. 이러니까 더 쉽게 지친 것 같다.
.
아침부터 sql 코드카타가 잘 안풀리고 rank( )도 실전(QCC)에서 못써먹고.. 스스로가 좀 답답하고 지금까지 뭘 한거지 싶었다. 흑흑.. 세션 복습 나름 데이터 이리저리 만지면서 잘 했다고 생각했는데.. 아니었나바..ㅠ
살짝 우울한 월요일이었는데, 내일은 오늘같지 않도록 더 열심히 알차게 보내야겠다. 그냥 월요병인가..?
.
캠프에서 잘 버티고 계신 분들 모두, 정말 멋있으신 것 같다 ! ⭐
.
기분좋은 음악을 틀고 샤워하면서 .. 힐링하고 자야지..💭💫

판다스는 진짜 치라고 해서 치긴 하는데 뭔지 모르겠다는 느낌이 너무 들어요 계속