개인과제 해설
SQL
으악 !! 결과 하나하나 캡처해서 비교해둔게,,!! 날아갔다....!>!>!>!!>허거덩거덩스다 ㄹㅇ
후 그치만 코드는 살아있음 !!!!!!!
.
1번 틀린게 충격이었고(난이도 쉬움보고 또 대충생각했지...) 4번 문제 잘못이해하고 풀어서 생각보다 쉬운데? 했던게 진짜 tyman's law 그 자체였음 ㅋㅋㅋㅋㅋㅋㅋㅋ
프로젝트 당분간 없으니 다시 sql 문풀 집중해야할 것같다 !!!
#1
select ad_id,
round((sum(case when event_type='click' then 1 else 0 end)*100/
sum(case when event_type='impression' then 1 else 0 end)),2) as ctr
from ad_events
group by 1
order by 1
#2
select distinct customer_id
from customer_orders co
join products p
on co.product_id =p.product_id
group by 1
having count(distinct(product_category))>=3
order by 1
#2-1. product_category 추가되더라도 안전한 방법
select distinct customer_id
from customer_orders co
join products p
on co.product_id =p.product_id
group by 1
having count(distinct(product_category))
>=(select count(distinct product_category) from products)
order by 1
#3
select user_id, post_date,
round(avg(post_count) over (partition by user_id
order by post_date
rows between 2 preceding
and current row),2) as rolling_avg_3d
from blog_posts
order by 1,2
#4
with oc as
(select max(order_id) as max_order_id
from orders)
select
case when order_id % 2 !=0 and order_id != max_order_id then order_id +1
when order_id % 2 != 0 and order_id = max_order_id then order_id
else order_id -1
end as cor_order_id,
item
from orders
cross join oc
order by 1.
알고리즘
다행히(?) 1.리스트 부분은 다 맞았다.
문제는 2. 문자열인데 아직 인덱싱, 슬라이싱 etc..에 약한 것 같다. 절반은 못풀었고 절반은 나와 제미나이의 합작품이라 제대로된 복습이 꼭 필요할 것 같다ㅜㅜ!! 정말 교과서 같은 무아튜터님의 해설세션이었다 !!
무튼 그래서 낼 알고리즘 2.문자열부터 복습해야겠다.
그외, 오늘 배운 것
🔻
집에서 보는 코테 - 정답률이 중요하다
라이브코딩 - 문제 세세하게 안준다. 면접관과의 소통이 중요하다.
고난이도SQL을 위해서는 아래와 같은 능력이 필요하다.
window(MA) / window(preceding)
self join / cross join
case when 응용
통계학 기초_ 1주차
통계와 데이터 기반 의사결정
- 데이터를 요약하고 패턴 발견 가능
- 추론을 통해 결론을 도출하는 과정에 사용
예시
☑️ 고객 만족도 설문조사 분석
☑️ Clustering - 고객 유형별 세그먼트 etc
기술통계와 추론통계
기술통계
: 평균, 중앙값, 분산, 표준편차 등
데이터에 대한 대략적인 특징을 간단하고 쉽게 나타냄
평균
모든 데이터를 더한 후 데이터의 개수로 나누어 계산
중앙값
데이터들을 크기 순서대로 정렬했을 때, 중앙에 위치한 값
분산
각 데이터 값에서 평균을 뺀 값을 제곱한 후, 이를 모두 더한 후 데이터 개수로 나눔
=> 데이터 값들이 평균으로 부터 얼마나 떨어져 있는지 = 흩어짐의 정도를 알 수 있게함.
표준편차
분산에 제곱근을 취하여 계산.
분산에 비해 직관적일 수 있음.(분산은 제곱단위로 표현, 표준편차는 원래 데이터 값과 동일한 단위로 변환)
추론통계
:표본 데이터를 통해 모집단의 특성을 추정하고 가설을 검증하는 통계방법. = 데이터의 일부를 가지고 전체를 추정
신뢰구간
: 모집단의 평균이 특정 범위 내에 있을 것이라는 확률
일반적으로 95% 신뢰구간 사용
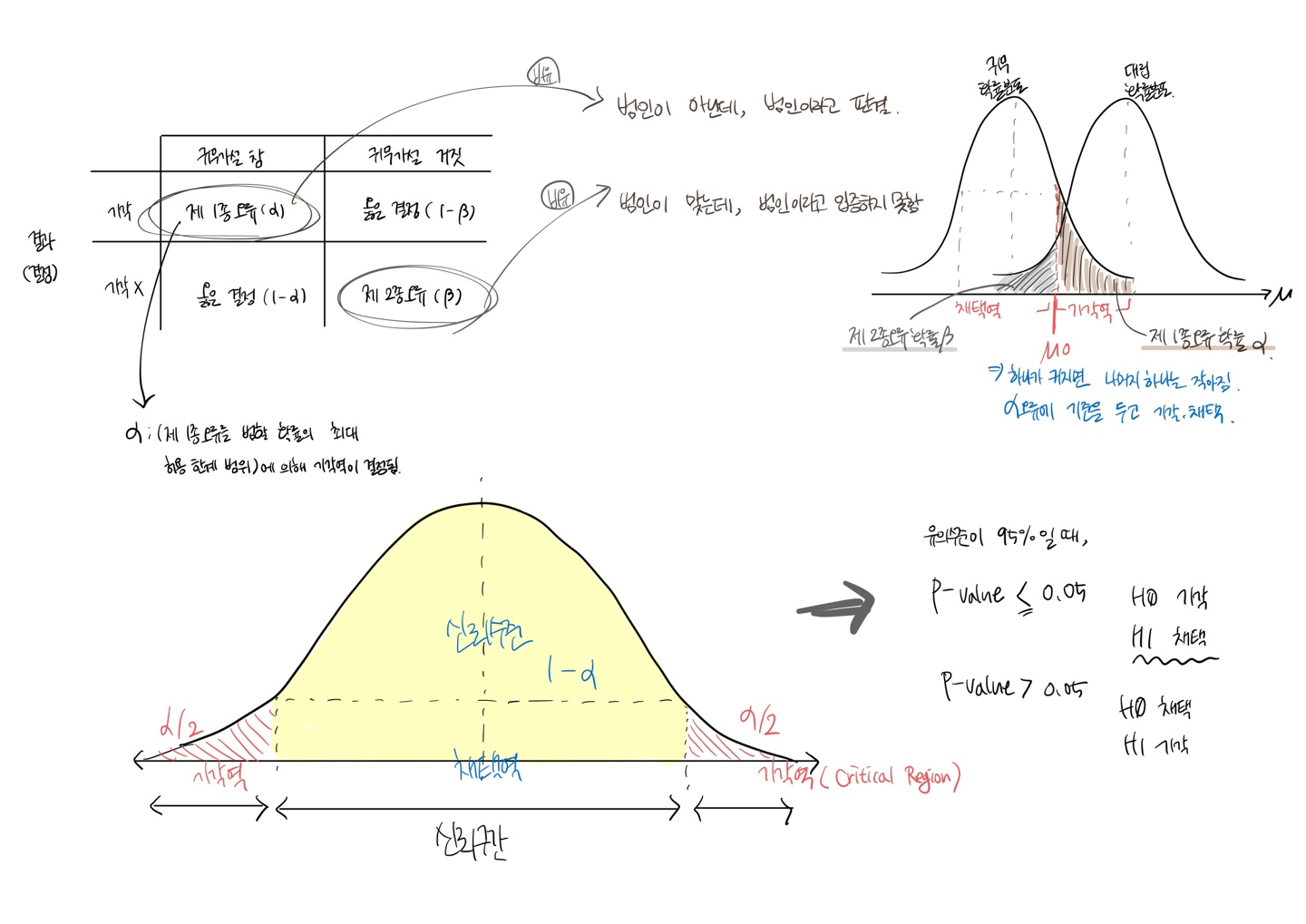
가설검정
귀무가설 (영가설) H0
대립가설 (연구가설) H1
p-value - 일반적으로 95% 신뢰수준을 사용하므로, 유의수준은 5% 즉 p값은 0.05가 된다.
갑자기 예전에 배웠던 내용들이 생각나서, 직접 다시한 번 정리해봤다.
다양한 분석방법
#위치추정(평균,중앙값)
import numpy as np
mean = np.mean(data)
median = np.median(data)
#변이추정(분산, 표준편차, 범위)
#범위(R)=최댓값-최솟값
variance = np.var(data)
std_dev = np.std(data)
data_range = np.max(data) - np.min(data)
#데이터분포(히스토그램, 박스플롯)
import matplotlib.pyplot as plt
plt.hist(data, bins=5)
plt.title('histogram')
plt.show()
plt.boxplot(data)
plt.title('boxplot')
plt.show()이진 데이터와 범주데이터
이진 데이터
특정사건의 발생 유무와 같이 두 가지 값으로 이루어진 데이터
범주형 데이터
: 수치로 측정이 불가능한 자료
최빈값 코드
satisfaction = ['satisfaction', 'satisfaction', 'dissatisfaction',
'satisfaction', 'dissatisfaction', 'satisfaction', 'satisfaction',
'dissatisfaction', 'satisfaction', 'dissatisfaction']
satisfaction_counts = pd.Series(satisfaction).value_counts()
satisfaction_counts.plot(kind='bar')
plt.title('satisfaction distribution')
plt.show()상관관계
:두 변수 간의 관계를 측정하는 방법
study_hours = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
exam_scores = [95, 90, 85, 80, 75, 70, 65, 60, 55, 50]
correlation = np.corrcoef(study_hours, exam_scores)[0, 1]
print(f"공부 시간과 시험 점수 간의 상관계수: {correlation}")
plt.scatter(study_hours, exam_scores)
plt.show()correlation = np.corrcoef(study_hours, exam_scores)[0, 1]
에서 [0,1] 의 의미는 행렬좌표(?)인듯하다.

따라서 [0,1]과 [1,0] 결과는 동일하다.
기억할 것 ! 넘파이에서 상관관계를 구하고 싶을 땐,
correlation이나 correlate기 아니라 np.corrcoef!
상관관계 != 인과관계
다변량 분석 - 여러 데이터들끼리 서로 관련이 있는지
data = {'TV': [230.1, 44.5, 17.2, 151.5, 180.8],
'Radio': [37.8, 39.3, 45.9, 41.3, 10.8],
'Newspaper': [69.2, 45.1, 69.3, 58.5, 58.4],
'Sales': [22.1, 10.4, 9.3, 18.5, 12.9]}
df = pd.DataFrame(data)
#산점도 여러개, 1:1 관계에선 히스토그램
# \(우하향) 기준으로 위아래 대칭
sns.pairplot(df)
plt.show()
df.corr()
#heatmap_color
sns.heatmap(df.corr())연습문제
- 어느 학교의 학생들 10명의 수학 점수는 다음과 같습니다: 78, 82, 85, 88, 90, 92, 94, 96, 98, 100. 이 데이터의 평균을 구하세요.

잉,, 뭐지 ...? 내가 틀린건가...?
- 4번 문제의 학생 수학 점수의 중앙값을 구하세요.
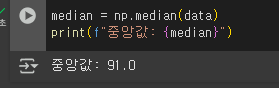
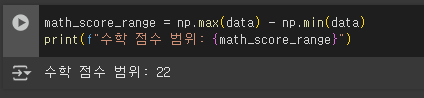
6.4번 문제의 학생 수학 점수 데이터의 범위(Range)를 구하세요.
7.1. 학생들의 수학 점수와 영어 점수가 각각 다음과 같을 때, 두 변수 간의 상관관계가 양의 상관관계인지, 음의 상관관계인지, 상관관계가 없는지 설명하고 그 이유를 얘기하세요.
1. 수학 점수: 78, 82, 85, 88, 90, 92, 94, 96, 98, 100.
2. 영어 점수: 70, 75, 80, 85, 85, 90, 90, 95, 95, 100.

: 매우 강한 양의 상관관계이다. 수학점수가 높을 수록 영어점수도 높은 경향성을 보인다.
느낀점&회고
오늘 새로운 조가 편성됐다 ! 팀원분들 다 학습에 적극적이신 것 같아서, 앞으로 같이 공부해 갈 날들이 기대된다.
월요일은 항상 피곤하지만 오늘 나름 선방한 것 같다 !!
통계가 익숙했던 내용이라 그런지 넘 재미있어서 ㅋㅋ갑자기 아이패드 켜서 노트필기를 했을 정도니까....
머신러닝 살짝 겁나기는 하는데 ㅠㅠ내일 정욱튜터님의 소프트랜딩을 믿어야지 ㅠㅠㅎㅎ
.
늘어지지 말고 ! 이번주도 최선을 다하는 한 주로 만들어야겠다 !!
4월아 ~~ 어서와 ~~~
