
코드카타
102
103
104
어려움 없이 풀었다 !
.
105
처음에 작성한 풀이
select customer_id
from customer
group by 1
having count(customer_id) = (select count(distinct product_key)
from product
)수정ver
select customer_id
from customer
group by 1
having count(distinct product_key) = (select count(distinct product_key)
from product
)📍 what ?
having절에서 count(customer_id)를 사용했는지, count(distinct product_key) 사용했는지 !
📍 why? how?
동일한 제품의 반복 구매가 이루어졌으면, 답이 틀릴 수 있겠다.
예를 들어,
고객이 A를 3번, B를 1번 샀다면 count(customer_id) = 4,
count(distinct product_key) = 2
count(customer_id)는 고객의 등장 횟수를 세는 데 초점이 맞춰져 있었고, 문제에서 요구하는 "고객이 모든 제품을 다 샀는지"를 판단하는 데 적합하지 않다
group by customer_id로 고객별로 데이터를 묶고,
count(distinct product_key)로 그 고객이 연관된 서로 다른 제품의 개수를 계산한 뒤,
이를 product 테이블의 전체 고유 제품 수(select count(distinct product_key) from product)와 비교
.
106
너무 좋은 문제 !! 잊고있던 것 !!!!!!
select e.employee_id, e.name, count(m.reports_to) as reports_count
, round(avg(m.age),0) as average_age
from employees e
join employees m
on e.employee_id = m.reports_to
group by 1
order by 1테이블 하나여도 join할 수 있다 !
- 자가 조인 (Self-Join)
정의: 동일한 테이블을 두 번 이상 참조하여 조인하는 방식.
<조직도나 계층적 데이터를 다룰 때 자주 활용되는 패턴>
통계야 놀자 1회차
1. 데이터의 대표적 종류
수치형
- 연속형
- 이산형
범주형=명목형
- 이진형
- 순위형
2. 편차, 분산, 표준편차, 표준오차
'데이터의 분포를 보다 명확히 파악하기 위해'
- 편차 : x-평균 => 평균으로부터 얼마나 떨어져있는지
: 편차의 합은 0
편차만으로는 데이터의 분포를 정확히 알 수 없어서 분산 등장!!
-
분산 : 편차제곱합의 평균
: 실제 데이터가 어느정도로 차이가 있는지 직관적인 파악이 어려움 -
표준편차 : 분산에 제곱근 씌워주기
: 원래 단위로 되돌리기 !!
= standard deviation(σ)
-
표준오차:
표본의 표준편차=표본평균의 평균과 모평균의 차이
정규분포, 신뢰구간
- 정규분포는 평균과 분산(퍼진정도)에 따라 다른 형태를 가지기 때문에
비교가 어렵기 때문에 표준화하여 분석한다.
ex. 머신러닝 모델을 만들 때, 각 숫자가 가지는 의미가 다를 수 있다.
최근 일주일 접속일수 0~7
결제 금액 0~100,000,000,000(무한)
- 신뢰구간: 특정 범위 내에 값이 존재할것으로 예측되는 영역
- 신뢰수준: 실제 모수를 추정하는데 몇 퍼센트의 확률로 신뢰구간이 실제 모수를 포함하게 되는 확률. 주로 95%와 99% 를 이용
표준화(standard scaler) 공식
: 확률변수 X (값) 에서 평균 m을 빼고 표준편차로 나눈 값
표준정규분포는 평균 0, 분산 1을 가진다.
통계학 3주차
AB테스트
☑️ A/B 검정
-
A/B 검정은 두 버전(A와 B) 중 어느 것이 더 효과적인지 평가하기 위해 사용되는 검정 방법.
-> 두 그룹 간의 변화가 우연이 아니라 통계적으로 유의미한지를 확인. -
실전 예시 정리

- 가설: 대상 고객 정의를 적어두면 “이건 바로 나!”라고 생각하고 다운로드율이 증가할 것이다.
- 결과는 기존대비 +0.6% ~ + 20.1% 개선!
- 여러 번의 대상 고객 정의를 테스트 결과 : 알라미에 맞는 대상 고객은 ‘기존 알람으로 잘 일어나지 못하는 사람’
무작정 A/B 테스팅을 하기보다는 좋은 가설을 세우고 A/B 테스팅의 파급력을 고려하여 진행하길 추천
당근마켓
"경험의 피크"
- 정량적인 경험: 거래내역
- 정성적인 경험: 거래후기
귀무가설: 거래 후기를 주고 받는 것은 더 좋은 서비스 경험에 영향을 미치지 않는다.
대립가설: 거래 후기를 주고 받는 것은 더 좋은 서비스 경험에 영향을 미친다.
인건가....??
.
[거래 후기를 잘 작성하도록 유도하는 실험 설계]
가설: 거래 완료한 게시글의 채팅 시스템 메시지로 거래 후기 작성을 유도하면, 거래 후기 작성률이 높아질 것이다
핵심지표: “구매자 중 거래 완료 게시글에 후기를 작성한 비율”
결과
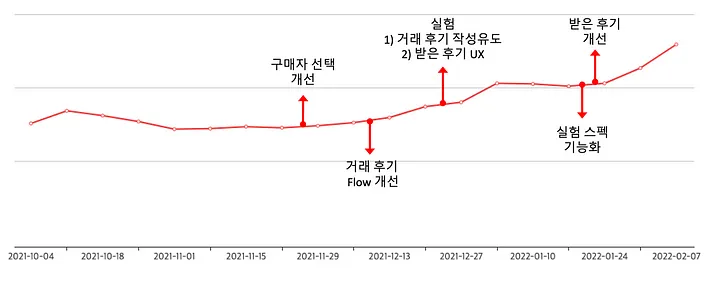
.
.
이후 내용들은 필기+코드실습하면서 들었다.

연습문제
2 / 2 / 1 / 3 / 2 / 1 ⭕⭕⭕⭕⭕⭕
이후 학습 내용
내일 수준별 세션에서 고급 테이블 결합을 배우게 될 예정이라,
판다스 세션 2회차 내용을 vscode 로 코드리뷰 하면서 공부했다.
느낀점&회고
수요일인데 벌써 체력이.. 바닥나려한다.. 밥을 잘 먹어야겠다.. (저녁 안먹고 잠깐 잤더니...)
진짜 이제 세션이 몰아쳐서 !!! 예복습만 하다가 하루가 슈슝 지나갈 것 같다 ㅠㅠ 효율적으로 시간을 쓸 수 있도록 노력해야겠다 !!
목요일 , 금요일 이틀만 더 버티자!! 아자아자 !! 💨💨💨
