코드카타
107
select employee_id
, case when count(employee_id) > 1 then (case when primary_flag = 'Y' then department_id end)
else department_id
end as department_id
from employee
group by 1이렇게 하면 employee_id가 4인 경우에서 department_id가 null로 나온다.
then 이후 쿼리를 더 건들였더니 Subquery returns more than 1 row라고 계속 런타임 에러가 났다.
구글링 결과, 나랑 비슷했는데 max를 사용했음을 알 수 있었다.
.
.
CASE 문만으로는 다중 행에서 단일 값을 보장 못 함 → 집계 함수 필요.
MAX는 NULL을 무시하므로 이런 상황에서 유용.
select employee_id
, case when count(employee_id) > 1 then max(case when primary_flag = 'Y' then department_id end)
else department_id
end as department_id
from employee
group by 1max만 써주면 된다 !
select e.employee_id
, coalesce(
(select department_id
from employee e2
where e2.employee_id = e.employee_id
and e2.primary_flag = 'Y'),
e.department_id
) as department_id
from employee e
group by e.employee_id이게 조금 더 느림
.
.
108
select x,y,z,
case when x>=y and x>=z and x < y+z then 'Yes'
when y>=x and y>=z and y < x+z then 'Yes'
when z>=x and z>=y and z < y+x then 'Yes'
else 'No'
end as triangle
from Triangle109
select num as ConsecutiveNums
from(select num,
lead(num,1) over (order by num) as ol,
lead(num,2) over (order by num) as tl
from logs) a
where num=a.ol=a.tl
group by num오잉,,
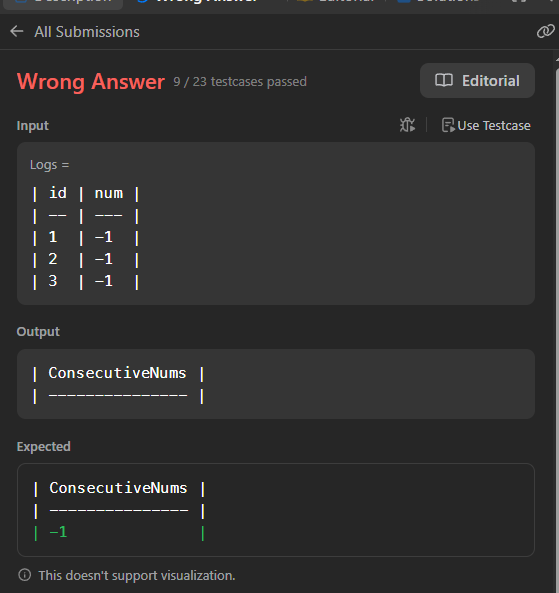
일단 이 오류는 where 문을 분할해서 고쳤고
다음 오류를 또 만났다.
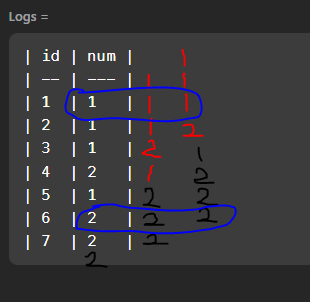
| id | num |
| -- | --- |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
| id | num |
| -- | --- |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 | 이유는 (order by num)때문!!!
지금 생각해보면 당연히 안된다 ㅋㅋ ID별로 정렬해야 기존 순서가 무시되지 않을 것이다 !!
(처음에 id는 쓸일도 없는데 왜줬나...오만한 생각을 했다)
select num as ConsecutiveNums
from
(select num,
lead(num,1) over (order by id) as ol,
lead(num,2) over (order by id) as tl
from logs
) a
where num=a.ol and a.ol=a.tl
group by numgroup by 안쓰고 distinct를 쓰는게 더 좋았을 수도 있을 것 같다
헤맨 이유🤯🤯
- lead를 1행할까 2행할까 고민만 했을 뿐, 1개 땡긴 거랑 2개 땡긴거 모두 select절에 넣어줄 생각을 못했음!
.- order by
id
.- where
A=B=C보다,A=B and B=C로 쓰자!
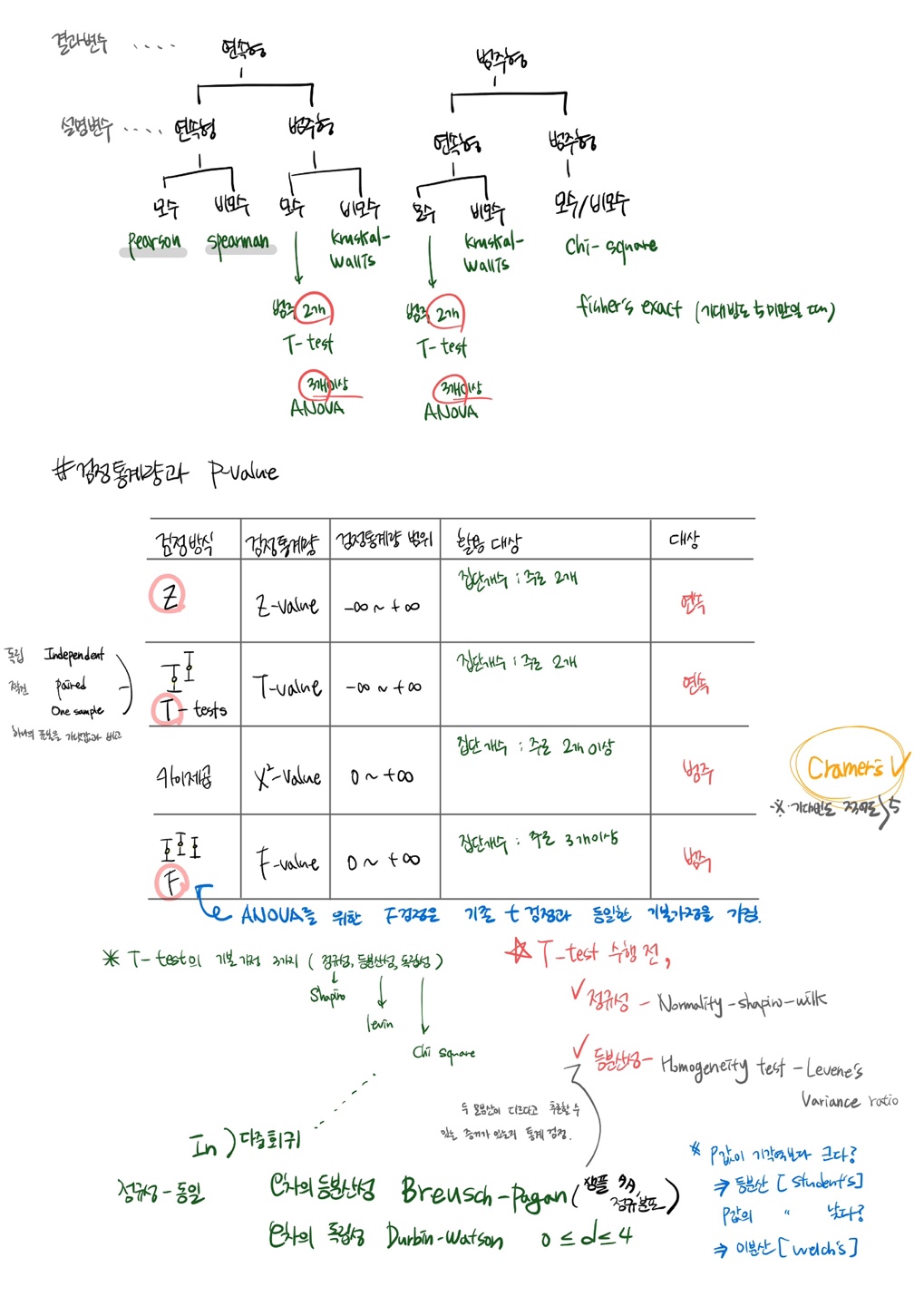
통계야 놀자 2회차 복습
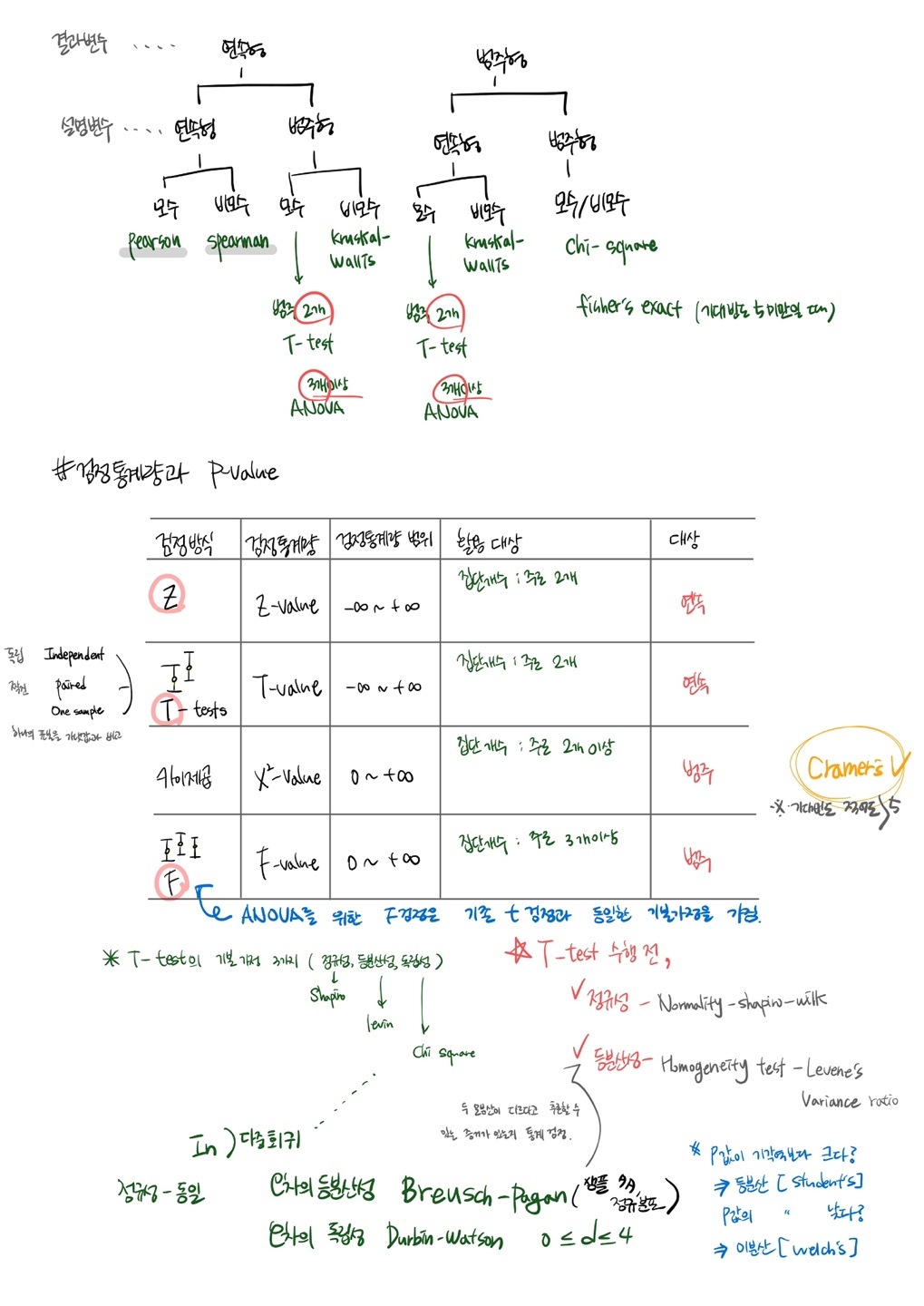
A/B Test 관련해서도 정리했는데, 기초통계 관련해서 정리한 내용을 올리는게 깔끔할 것 같아서 !
아티클 스터디
.
1.전체인 <모집단>에서 일부인 <표본>을 추출하여 설계/실험 진행
2.‘일부’일지라도 이 숫자가 충분하면, 일부를 통해 전체에 대해서 추측, 추론, 추정 가능
3.귀무가설-대립가설 , 양측검정-단측검정
귀무가설 ) 평소의 상태 = 결과에 차이 x
대립가설 ) 특정 조치 후 평소와 다른, 반대되는 상황이 발생할 것이라 가정 = 차이가 생긴다
.
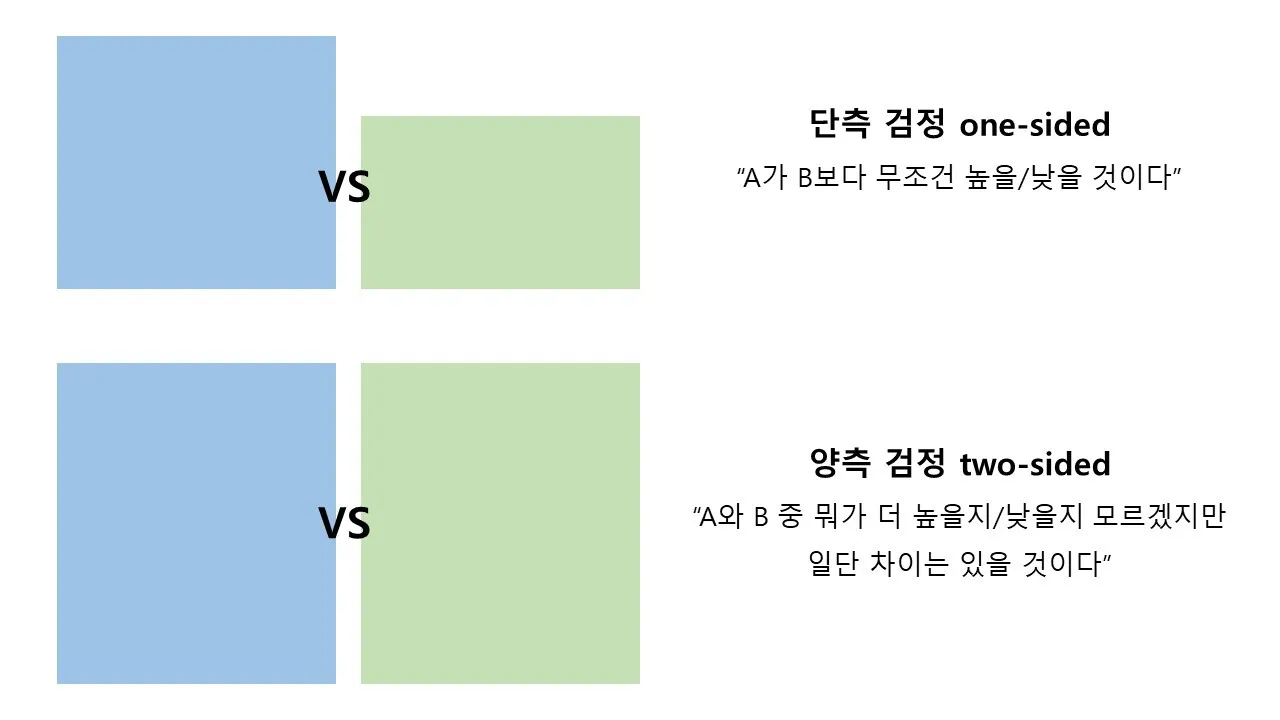
단측검정 ) ‘ 정말 더 나은 결과인지 ‘ One-sided
양측검정 ) ‘ 차이가 있긴 있되 어느 쪽이 더 나을지 미리 가정 어려워 ’ two-sided
4.실험결과도 결국 ‘추측’이다
우리 추측이 어느 정도로 신뢰할 수 있는가 ? ⇒ 신뢰수준
5.실험결과와 함께 표기되는 P-value
유의수준 5 %가 p-value 판단 기준이 된다.
6.A/B테스트에서 기초통계가 중요한 이유
가설을 통한 실험은 우연히 발생할 수 밖에 없기 때문에 적절한 기초 통계를 활용해 우리가 원하는 답을 찾기 위해 노력해야한다.
💡개인 인사이트
마침, 오늘 오전에 배운 세션 내용이 포함되어있는 아티클이라 복습차원에서 술술 읽을 수 있었다. 단순히 분석 수치+시각화 자료를 제공하기 보다, 통계적 값을 함께 제공하는 것이 전문성과 신뢰성을 더 높힐 수 있는 것 같다. (통계적 결과에만 의존할 수 있는 것은 아니지만! )
단측검정과 양측검정의 구체적인 사례와 예시를 알아보고싶은 생각이 들었고, 데이터 유형과 활용형태에 따라 어떤 통계검정방식을 사용해야하는지 구분해서 공부해둬야겠다.
. . #### 실무 적용 - 실무 적용 : 상품 구매 페이지 A/B 테스트 - 관련 사례 : 원본A는 배송비가 별도 표기 됨, 대안 B는 배송비가 상품가에 포함되어 배송비는 별도로 표기되지 않음  - 결론: 원본 A와 대안 B 사이에 유의미한 차이가 없다고 가정했을 때, 대안 B 의 구매율 35%가 관측도리 확률이 매우 희박하기 때문에, 원본 A 와 대안 B는 통계적으로 유의미한 차이를 가지고 있다.- 다른 팀원분이 소개해주신 추가 아티클도 재밌었다 :)
기업에게 중요한 AB 테스트란? AB 테스트 사례로 알아보기
standard_1회차 이론&실습
vscode 적응기; 겪은 오류
colab에서 갈아탔다..혼자 이것저것 해보는.. 타입인데.. 매번 임포트가 너무 번거롭+귀찮+ 파일 새로 다운받으면 일일이 경로복사..💫💫(kizul)
filenotfounderror: [errno 2] no such file or directory: 이 오류였었는데,
파일 불러오는 과정에서 생긴문제이다.
import os
currentPath=os.getcwd()
print(currentPath)결과: c:\Users\사용자\Downloads
이렇게 경로 확인해서 해당 경로로 파일을 옮겨줬더니 바로 해결됐다 !
고급 데이터 프레임 변경
wide=>long
melt
stack
.long=>wide
(pivot;구현 가능한다는 것, 무조건임은 X)
unstack
.
-행<->열
transpose
.
transpose
데이터 많을 때는, head로 작업하자
.
pivot&melt
멋대로 만들어도 보고! 이거를 melt로 녹이는 실습을 했다.
처음에는 이거보고 파라미터를 이해했고, 최종적으로 내가 이해가게 .. 필기해놓은게 있는데 노트필기라 옮기지를 못하겠다...아쉬운맘에 이거라도..ㅠ(그림판으로라도 그려야하나)
.
stack & unstack
stack: 컬럼을 인덱스 하위로 // 멀티 인덱스 처리 가능
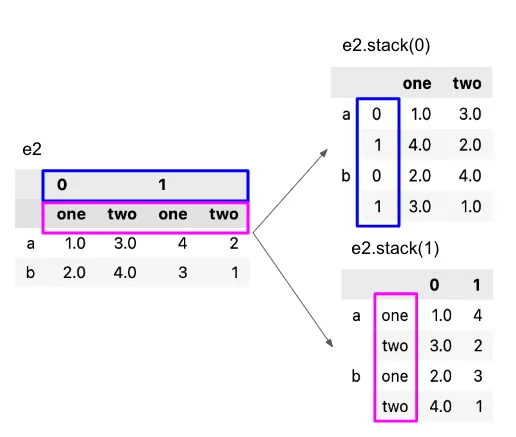
unstack: 인덱스레벨을 컬럼으로 변환
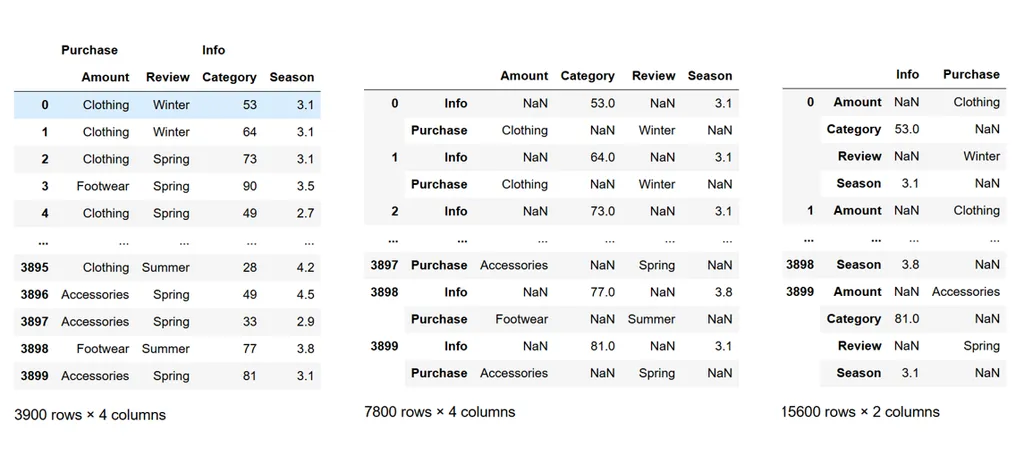
아니 내가 TIL을 대충쓰고 싶은게 아니라, 정말 이 사진이 최고다.(이해직빵)
튜플로 인위생성해서 실습
# stack
df2 = pd.read_csv("customer_details.csv") # customer_details.csv
# 필요한 컬럼 선택
df22 = df2[['Purchase Amount (USD)', 'Review Rating','Category', 'Season']].copy()
# pd.MultiIndex from tuples 를 통해, 멀티인덱스 설정
df22.columns = pd.MultiIndex.from_tuples([('Purchase', 'Amount'), ('Purchase', 'Review'),
('Info', 'Category'), ('Info', 'Season')])📍컬럼순서 바뀌지 않게 주의 **
#stack
df_stacked_0 = df22.stack(level=0)
#unstack
df_unstacked_0 = df_stacked_0.unstack(-1).reset_index()긍데 이렇게 unstack하면 df22랑 컬럼레벨이 달라져서
df_unstacked_0 = df_unstacked_0.swaplevel(axis=1).sort_index(axis=1)
df_unstacked_0 = df_unstacked_0.reset_index()뒤집어서 reset_index()사용하여, 컬럼 레벨까지 수정할 수 있었다.
다시한 번 display의 유용성을 알 수 있었다.
.
💥melt vs stack
melt, stack 둘다 long frame이지만 살짝 다르다.
melt는 특정 컬럼을 행으로, stack은 컬럼을 인덱스로 이동시킨다.
따라서 전자는 기존 인덱스 유지, 후자는 인덱스에 변화가 생긴다.
결과적으로, 전자는 시각화나 머신러닝, 분석 등을 위해 컬럼을 정리할 때 유용(컬럼을 하나의 카테고리 변수로 변환) 하고
후자는 인덱스로 계층적 구조를 생성할 수 있게 된다.
느낀점&회고
이제부터 배우는게 점점많아지고 어려워져서 당일 복습은 필수다 !!!!!
.
standard 1회차 강의자료 보고.. 맨첨에 절대 이해 못할 것 같았고.. 내가 이걸 하루만에 이해할 수 있을까..? 싶었는데.. 튜터님이 정말 잘 가르쳐주신 것 같아서.. 이해되는게 신기했다. ⭐⭐
.
velog 예쁘게 쓰고 싶었는데.. 오늘 세션 3개들었더니 뇌 녹는중...껄껄.. 🤯🤯
낼 qcc이후 또 세션 2개..~!!!!! 진짜 짜릿..!🔥🔥
.
통계강의 주말 이용해서라도 이번주 내로 끝내는게 목표다.
머신러닝까지 시작해버리면 진짜 답 없을 것 같기 때문..!!
.
.
멋쟁이 데이터 분석가가 되는 그 날 까지... KEEP GOING,,, 💨💨💨

명서님 필체는 언제봐도 느좋이요 👀👀🤩