
Database
Database란 간단하게 말하면 데이터의 한 집합으로 볼 수 있습니다. Database는 데이터들을 엑세스하고 조작하는 기능들을 포함하고 있습니다.
DBMS(Database Management System)은 앞서 설명한 Database가 포함하고 있는 데이터들을 엑세스하고 조작하기 위한 시스템입니다. PostgreSQL, MySQL, Oracle Database, SQLite와 같은 것들이 존재합니다. 즉, 실질적인 Database가 아닌 Database와 상호작용하여 관리하기 위한 시스템으로 볼 수 있습니다.
MySQL vs SQL
SQL은 구조화 쿼리 언어(Structured Query Langage)를 뜻하며 Database와 상호작용하기 위한 언어입니다. 데이터와 상호작용하고 접근하며, 업데이트하고 삭제하는 등 기본적으로 Database에서 데이터를 조작하기 위한 언어입니다.
MySQL은 앞서 설명했듯이 Database 관리 시스템으로 SQL을 사용하여 데이터와 상호작용 합니다. 즉, SQL은 고유한 언어이며 DBMS들은 SQL을 사용하여 상호작용합니다.
Install MySQL (for Mac)
- MySQL 설치
https://dev.mysql.com/downloads/mysql/ 해당 링크에서 사용중인 OS와 옵션에 맞는 것을 다운로드 받습니다.
- root 비밀번호 설정
설치 도중 root@localhost에 대한 비밀번호를 설정하는 화면이 아래와 같이 표시됩니다.
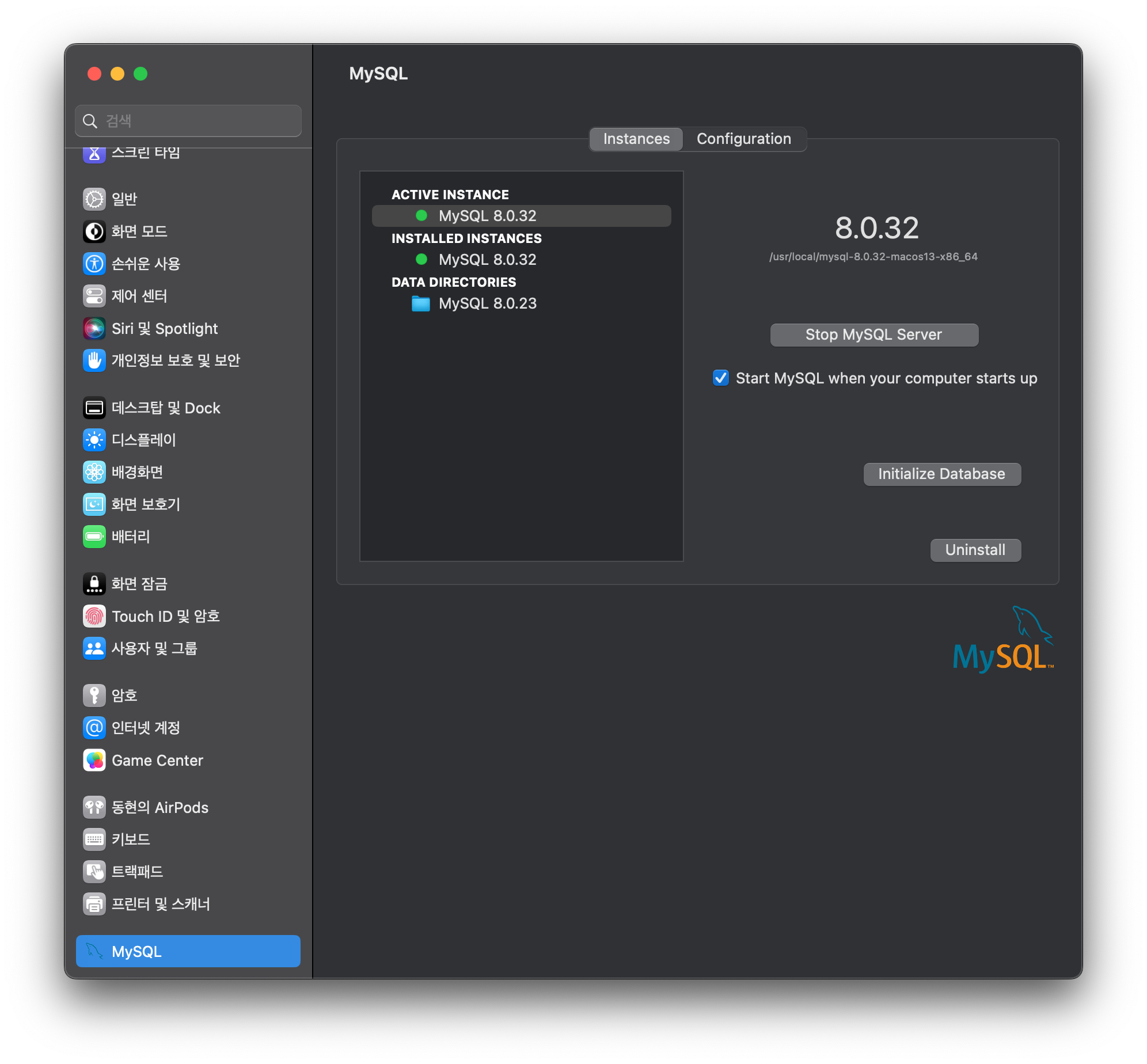
- 설치 확인
시스템 설정에서 아래와 그림과 같이 MySQL이 설치된 것을 확인할 수 있습니다. 여기서 MySQL Server Status를 비롯하여 다양한 정보들을 확인할 수 있습니다.
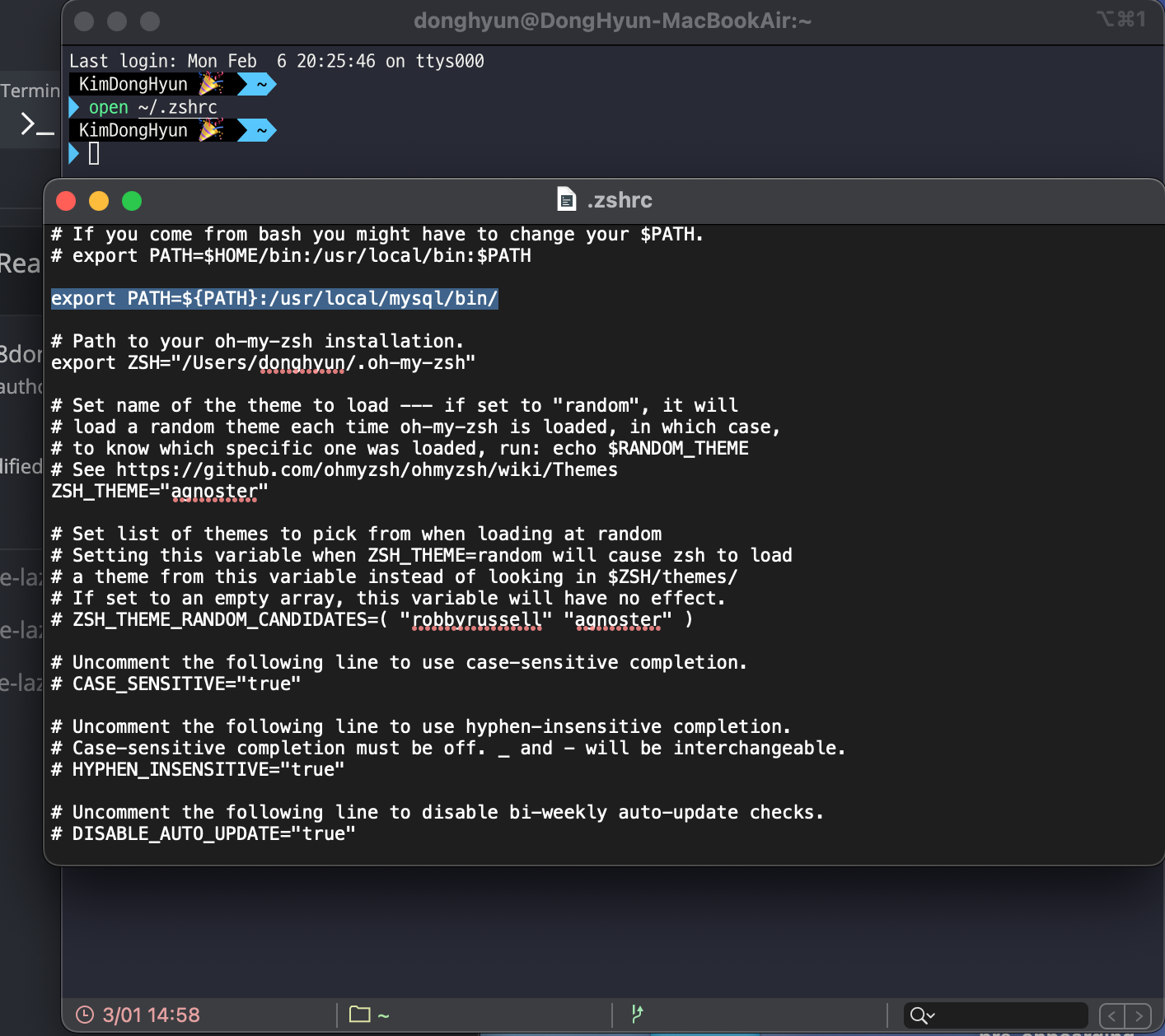
- 터미널 명령어 사용하기
터미널에서 mysql을 입력하면 명령어를 찾을 수 없다는 메세지가 출력됩니다. 이는 해당 경로에 MySQL 명령어가 없기 때문입니다.
open ~/.zshrc 명령어로 파일을 연 뒤 아래와 같은 문장을 추가하고, 터미널을 종료한 뒤 열면 mysql 명령어가 실행되는 것을 확인할 수 있습니다.
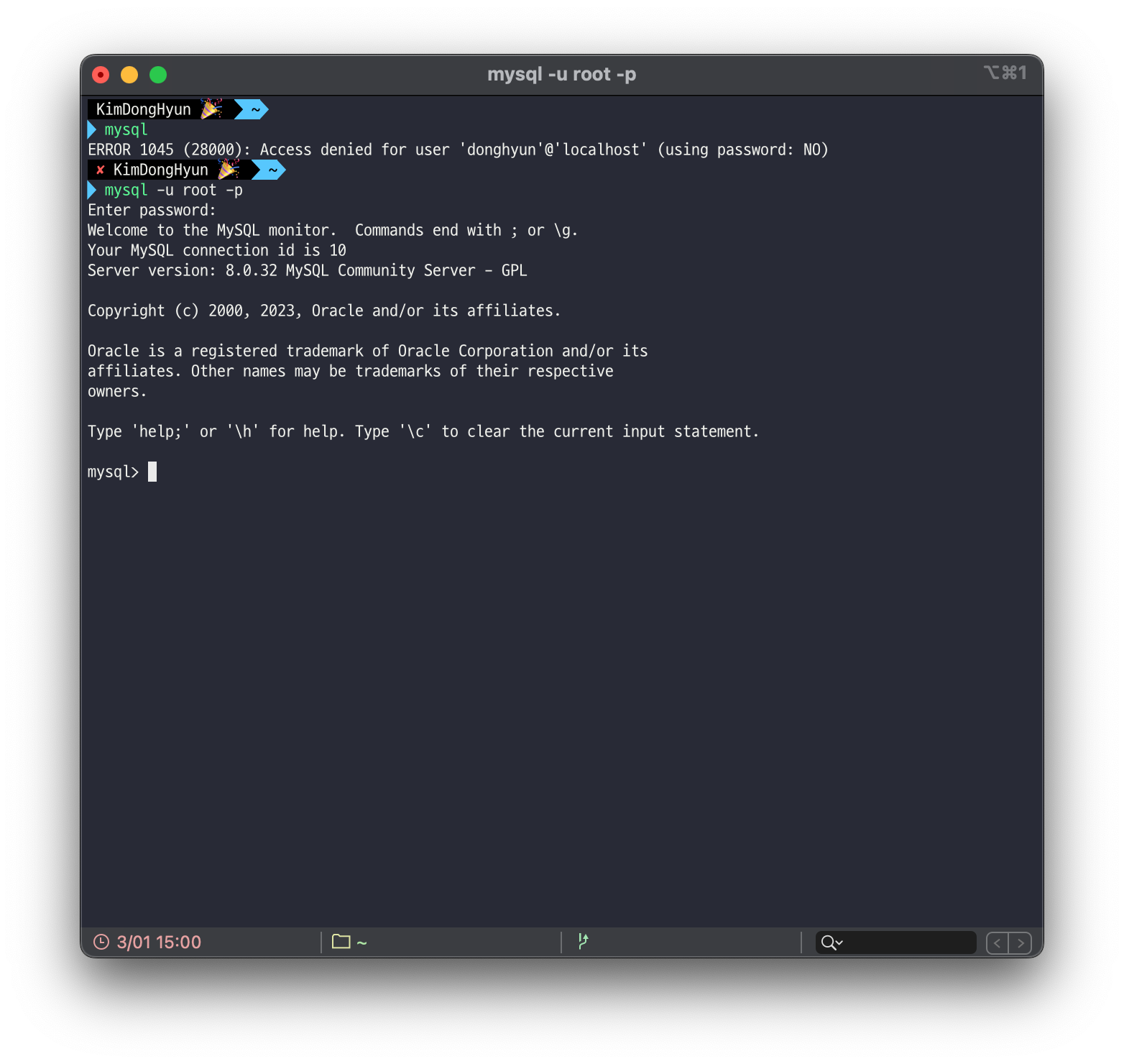
- root 권한으로 접근하기
mysql명령어 입력시 root 권한에 접근할 수 없다는 메세지가 출력됩니다.mysql -u root -p명령어를 입력하고 앞서 설정한 비밀번호를 입력합니다.
Database
SHOW DATABASES;
MySQL 데이터베이스 서버 안에서는 독립적인 데이터베이스를 생성할 수 있습니다. 즉, 같은 서버 내 여러 독립적인 데이터베이스가 존재할 수 있습니다.
터미널에서 mysql> SHOW DATABASES; 명령어를 입력하면 MySQL 서버에 현재 존재하는 데이터베이스들을 나열합니다.
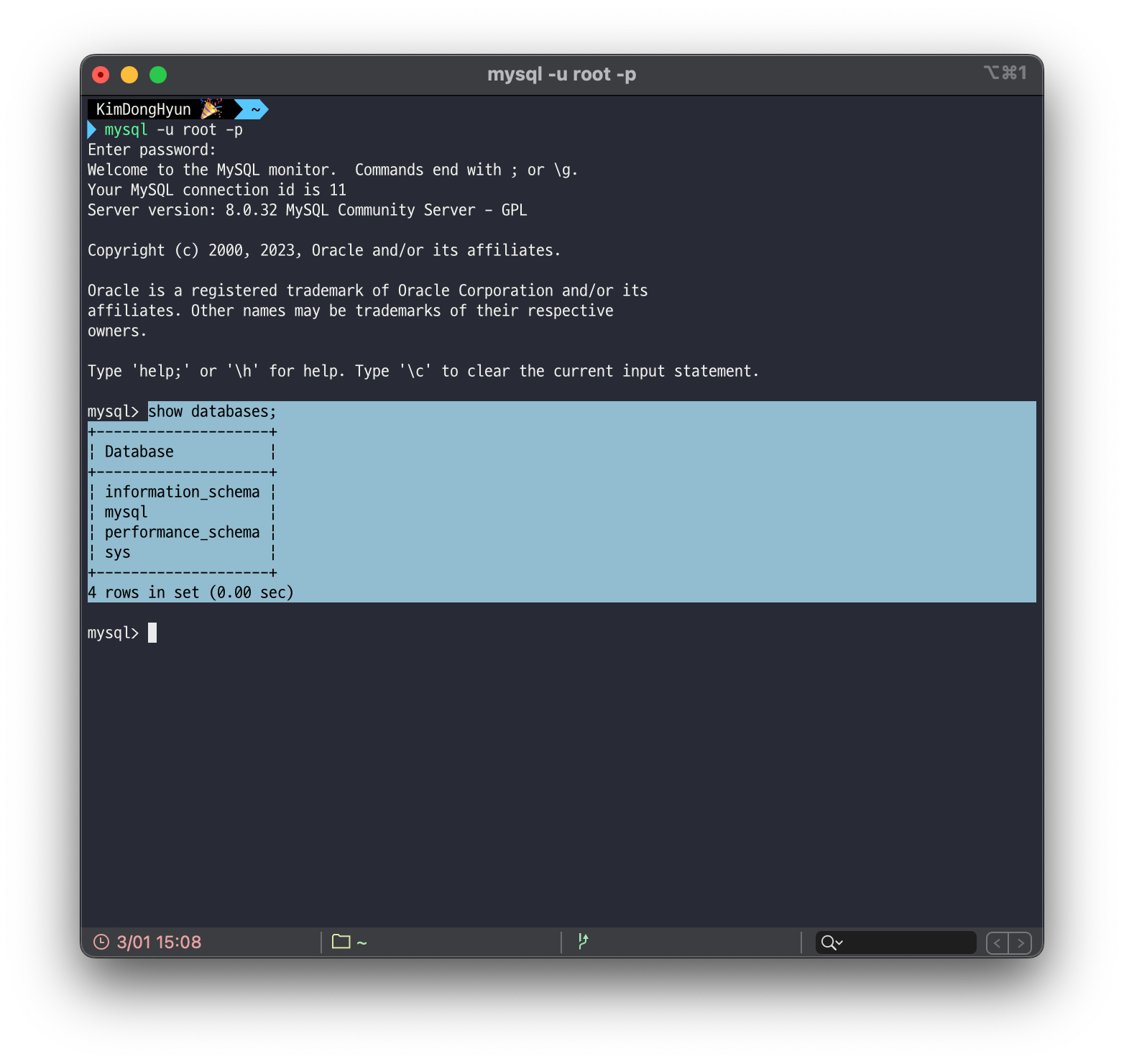
위 그림처럼 현재 서버 내에는 4개의 데이터베이스가 존재하는 것을 확인할 수 있습니다.
SELECT DATABASE();
mysql> SELECT DATABASE(); 명령어는 현재 사용중인 데이터베이스를 출력합니다.
USE <database_name>
mysql> USE <database_name>; 명령어는 사용할 데이터베이스를 변경하는 명령어입니다.
CREATE DATABASE <database_name>
mysql> CREATE DATABASE <database_name>; 명령어를 통해 새로운 데이터베이스를 생성할 수 있습니다.
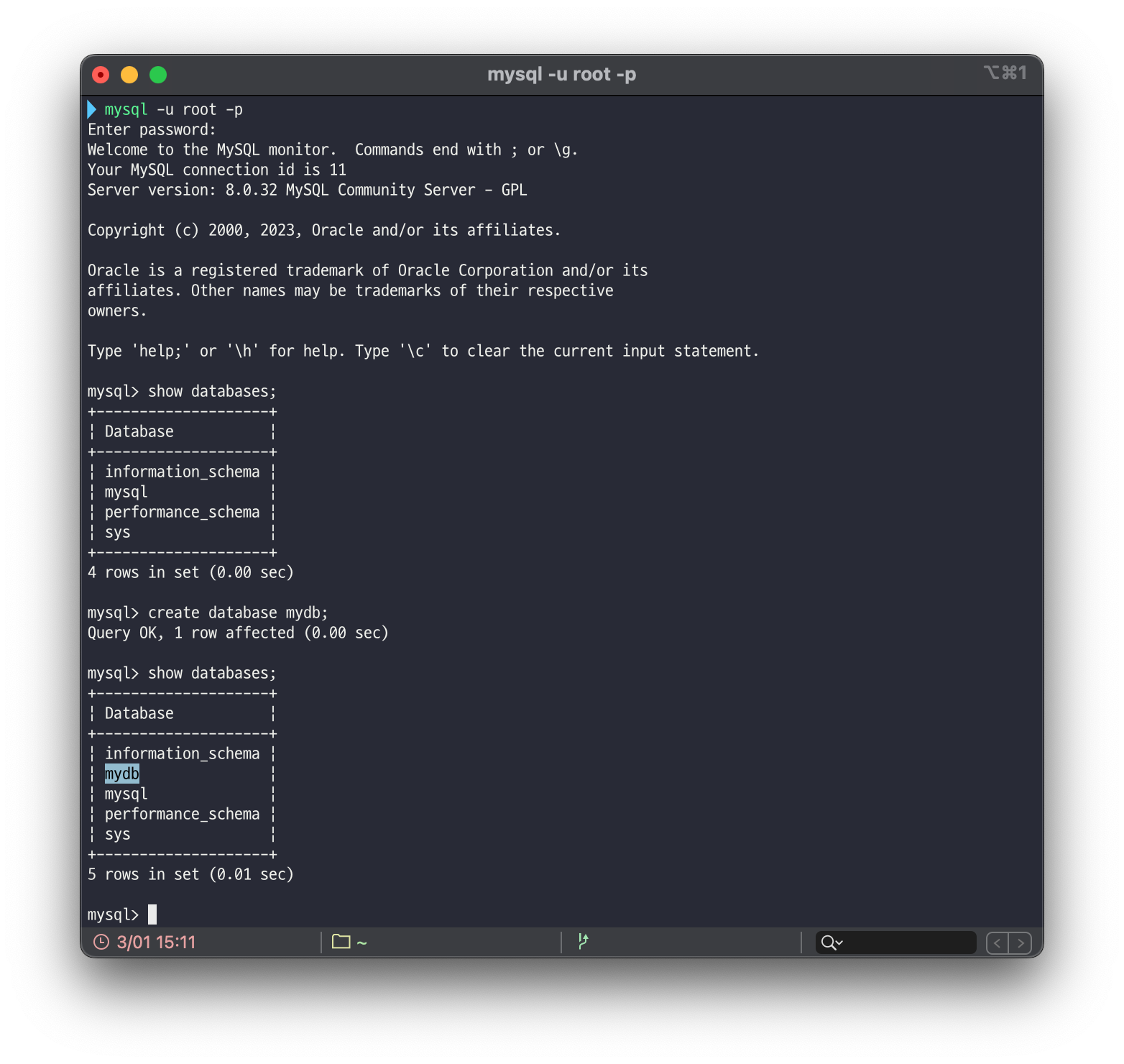
위 그림처럼 mysql> CREATE DATABASE mydb; 명령어 실행시 mydb라는 새로운 데이터베이스가 생성된 것을 확인할 수 있습니다.
DROP DATABASE <database_name>
데이터베이스를 삭제하기 위해서는 mysql> DROP DATABASE <database_name>; 명령어를 사용합니다.
Tables
데이터베이스는 단지 수많은 테이블로 구성되어 있습니다. 즉, 테이블 내에 관련된 데이터들이 저장되어 있습니다.
테이블의 Columns(열)은 테이블의 헤더를 가리킵니다. Rows(행)은 테이블이 갖고 있는 실제 데이터를 가리킵니다.
CREATE TABLE <table_name>
mysql> CREATE TABLE <table_name> (
-> <column_name> <date_type>,
-> ,,,
-> );CREATE TABLE 명령어를 사용하여 새로운 테이블을 생성할 수 있습니다. 테이블을 생성할 때 각 칼럼명과 칼럼에 포함될 데이터 타입을 설정해주어야 합니다.
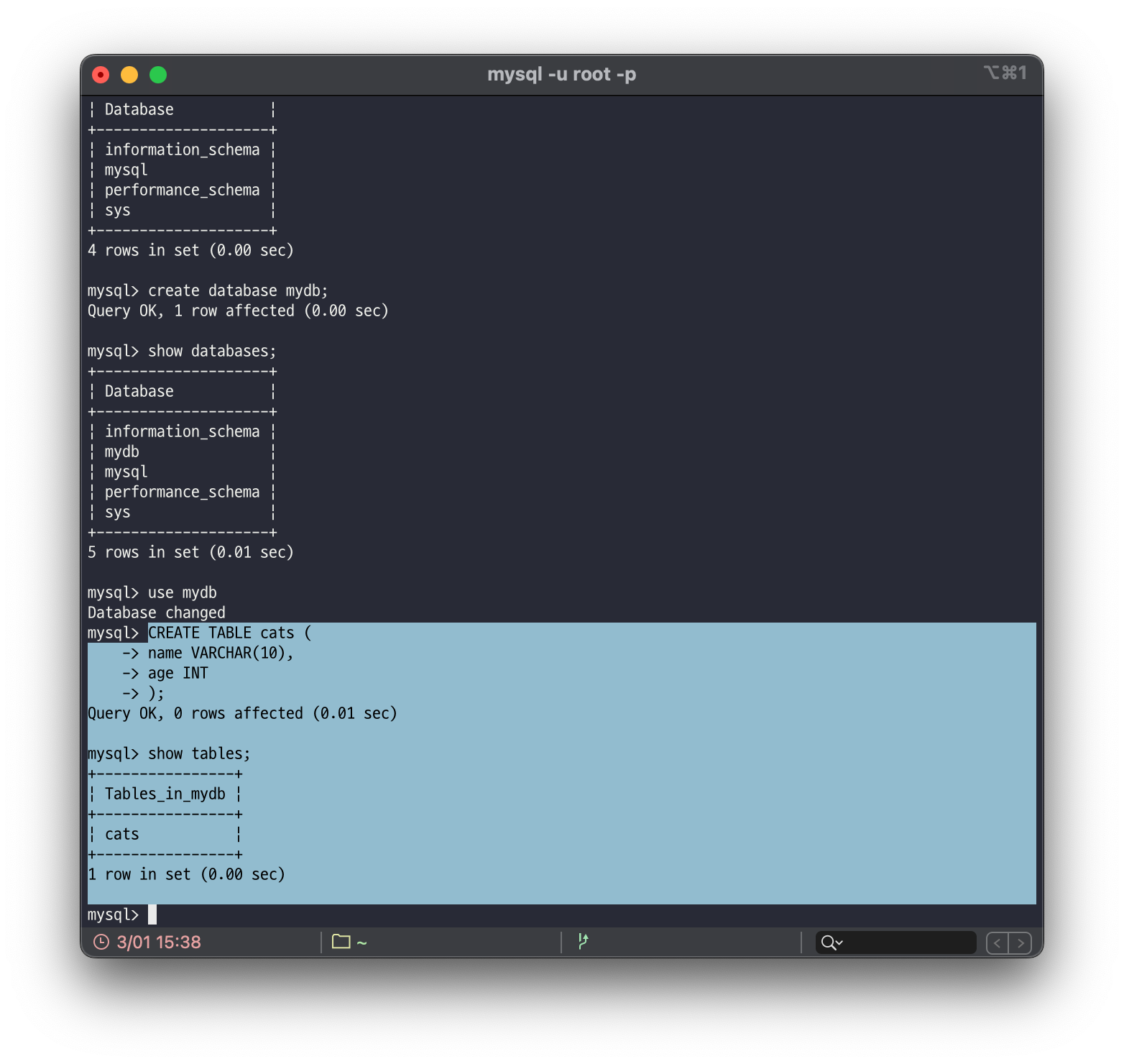
위 그림처럼 cats 라는 테이블을 생성하고, 테이블 내 name과 age 칼럼을 갖도록 생성했습니다.
SHOW TABLES
mysql> SHOW TABLES; 명령어를 사용하면 현재 데이터베이스 내 존재하는 테이블들을 확인할 수 있습니다.
SHOW COLUMNS FROM <table_name>
mysql> SHOW COLUMNS FROM <table_name>; 명령어를 통해 테이블의 구체적인 정보를 확인할 수 있습니다.
DROP TABLE <table_name>
생성된 테이블을 제거하기 위해서는 아래와 같은 명령어를 사용합니다.
mysql> DROP TABLES <table_name>,,,;Data Types
각 칼럼에 포함되는 데이터들은 일관된 데이터 타입을 갖습니다. 테이블을 생성할 때 각 칼럼에 포함될 데이터의 타입을 설정합니다.
String Types
-
VARCHAR(N): 가변 길이를 갖는 문자열 타입(N은 차지할 바이트 작성, 0 ~ 65,525), 또한 문자열의 길이를 위해 255이하인 경우 1바이트, 이상인 경우 2바이트를 추가적으로 갖습니다.
그러므로 차지할 바이트는 실제로 차지되는 바이트가 아닌 문자열의 길이를 나타내기 위한 바이트 크기를 위해 작성해주어야 합니다. -
CHAR(N): 고정된 길이를 갖는 문자열 타입(N은 차지할 바이트 작성, 0 ~255)
Numeric Types
-
INT: –2,147,483,648 ~ 2,147,483,647 -
SMALLINT: –32,768 ~ 32,767 -
TINYINT: 0 ~ 255 -
BIGINT: –9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 -
DECIMAL(최대 숫자 길이, 소수점 이하 자리수): 고정 소수점을 나타내기 위한 타입입니다. 만약DECIMAL(5, 2)타입의 최대 값은 999.99입니다. 숫자 값의 전체 길이는 5이며, 소수점 이하 2자리만 표시합니다.
Date Types
-
DATE: 시각 없이 날짜만을 저장하기 위한 타입입니다. 형식은 "YYYY-MM-DD" 입니다. -
TIME: 날짜 없이 시각만을 저장하기 위한 타입입니다. 형식은 "HH:MM:SS" 입니다. -
DATETIME: 날짜와 시각을 저장하기 위한 타입입니다. 형식은 "YYY-MM-DD HH:MM:DD" 입니다. -
TIMESTAMP: 날짜와 시각을 저장하기 위한 타입입니다. 기본적으로 NOT NULL로 설정되어 있으며, Timezone에 의존하고 있습니다.
Contrains
NOT NULL
Null은 기본적으로 값이 무엇인지 알지 못하거자 지정된 값이 없다는 것을 의미합니다. 주의할 점으로 NULL은 0을 의미하지 않습니다.
기본적으로 각 칼럼에 대해서 NULL 값을 허용할 지에 대한 제약조건을 설정할 수 있습니다. NOT NULL이라는 제약조건을 설정한다면 해당 칼럼의 경우 NULl값, 즉 빈 값을 허용하지 않게 됩니다.
mysql> CREATE TABLE <table_name> (
-> <column_name> <data_type> NOT NULL,
-> ,,,
-> );위 명령어처럼 테이블을 생성할 때 칼럼을 정의할 때 NOT NULL을 작성한다면 해당 칼럼은 NULL을 허용하지 않도록 설정됩니다.
DEFAULT
칼럼에 대한 데이터의 기본값을 설정할 수 있습니다. 만약 데이터를 추가할 때 특정 칼럼에 데이터를 추가하지 않았다면 기본값으로 설정한 데이터가 추가되도록 할 수 있습니다.
mysql> CREATE TABLE <table_name> (
-> <column_name> <data_type> DEFAULT <value>,
-> ,,,
-> );칼럼을 정의할 때 DEFAULT <value>을 작성한다면 해당 칼럼에 데이터가 추가되지 않는 경우에 설정한 기본값으로 설정됩니다.
PRIMARY KEY
기본키(Primary Key)는 테이블의 각 행을 고유하게 구분하기 위해 사용되는 데이터입니다. 즉, 기본키로 설정되는 칼럼의 경우 모든 행을 고유하게 구분할 수 있어야 하므로 중복된 데이터를 가질 수 없으며 빈 값을 허용하지 않습니다.
mysql> CREATE TABLE <table_name> (
-> <column_name> <data_type>,
-> ,,,
-> PRIMARY KEY (<column_name>)
-> );위 명령어처럼 테이블 생성시 PRIMARY KEY (<column_name>)을 통해 특정 컬럼을 기본키로 설정할 수 있습니다.
혹은 칼럼명 뒤에 공백으로 구분하여 PRIMARY KEY를 작성하여 설정할 수도 있습니다.
mysql> CREATE TABLE <table_name> (
-> <column_name> <data_type> PRIMARY KEY,
-> ,,,
-> );AUTO_INCREMENT
AUTO_INCREMENT의 경우에는 해당 칼럼에 데이터를 추가하지 않더라도 자동적으로 1씩 증가된 숫자값이 설정됩니다.
mysql> CREATE TABLE <table_name> (
-> <column_name> <data_type> AUTO_INCREMENT,
-> ,,,
-> );FOREIGN KEY
외래키를 설정하기 위해서는 아래와 같이 설정합니다.
myslq> CREATE TABLE <table_name> (
-> ,,,
-> FOREIGN KEY (column_name) REFERENCES <table_name> (column_name)FOREIGN KEY (column_name)에는 외래키가 될 칼럼명을 작성하고, REFERENCES <table_name> (column_name)에는 관계를 갖는 외부 테이블명과 칼럼명을 작성해줍니다.
CRUD
INSERT INTO
INSERT INTO 명령어는 특정 칼럼에 데이터를 추가하는 명령어입니다.
mysql> INSERT INTO <table_name> (<column_name>, ,,,)
-> VALUES (value , ,,,);INSERT INTO 문 뒤에는 테이블 명을 작성하고, 괄호 안에 데이터를 추가할 칼럼명을 ,(콤마)로 나열합니다.
그리고 VALUES 문 뒤 괄호 안에 칼럼에 추가할 데이터를 ,(콤마)로 구분하여 순서대로 작성해줍니다.
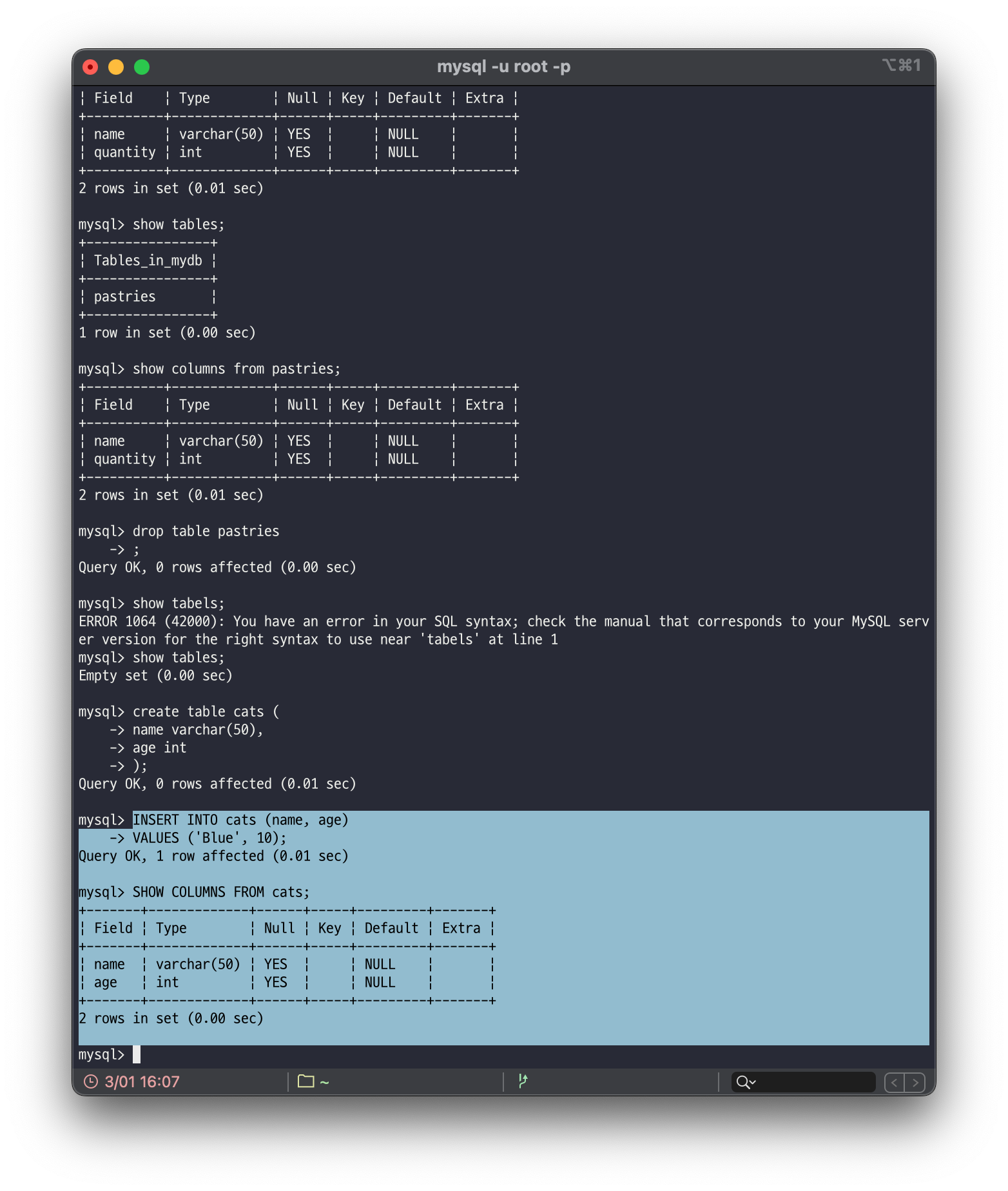
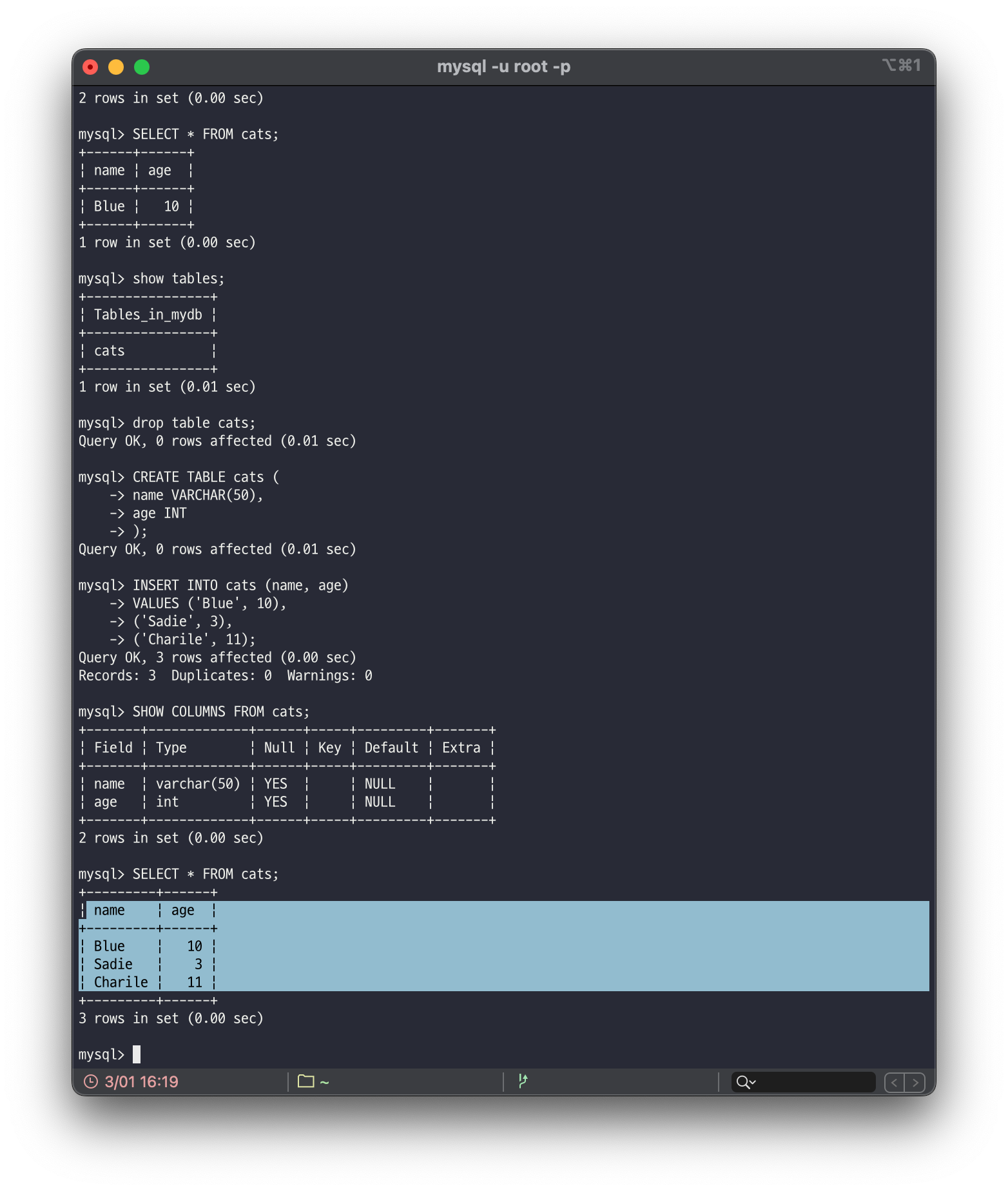
위 그림에서는 cats라는 테이블의 name과 age 칼럼에 'Blue'와 10을 순서대로 추가했습니다. 즉, 첫 번째 행에는 'Blue'와 10의 데이터가 존재합니다.
mysql> INSERT INTO cats (name, age)
-> VALUES ('Blue', 10),
-> ('Sadie', 3),
-> ('Charlie', 11);위 명령어처럼 VALUES 문 뒤 괄호로 구분하여 여러 행에 대한 데이터를 추가할 수도 있습니다.
첫 번째 행은 'Blue' 10, 두 번재 행은 'Sadie' 3, 세 번째 행에는 'Charile' 11이 존재하게 됩니다.
SELECT <column_name> FROM <table_name>
SELECT 명령어는 원하는 데이터를 가져오기 위한 명령어 입니다.
mysql> SELECT <columne_name>, ,,, FROM <table_name>;SELECT 문 뒤에는 조회할 특정 칼럼명을 작성합니다. 여러 칼럼에 대한 데이터를 조회하고자 한다면 ,(콤마)를 사용하여 조회할 칼럼명들을 나열하고, 모든 칼럼에 대해서 조회하고자 한다면 *(애스터리스크)를 작성합니다.
그리고 FROM 뒤에는 조회할 테이블명을 작성합니다.
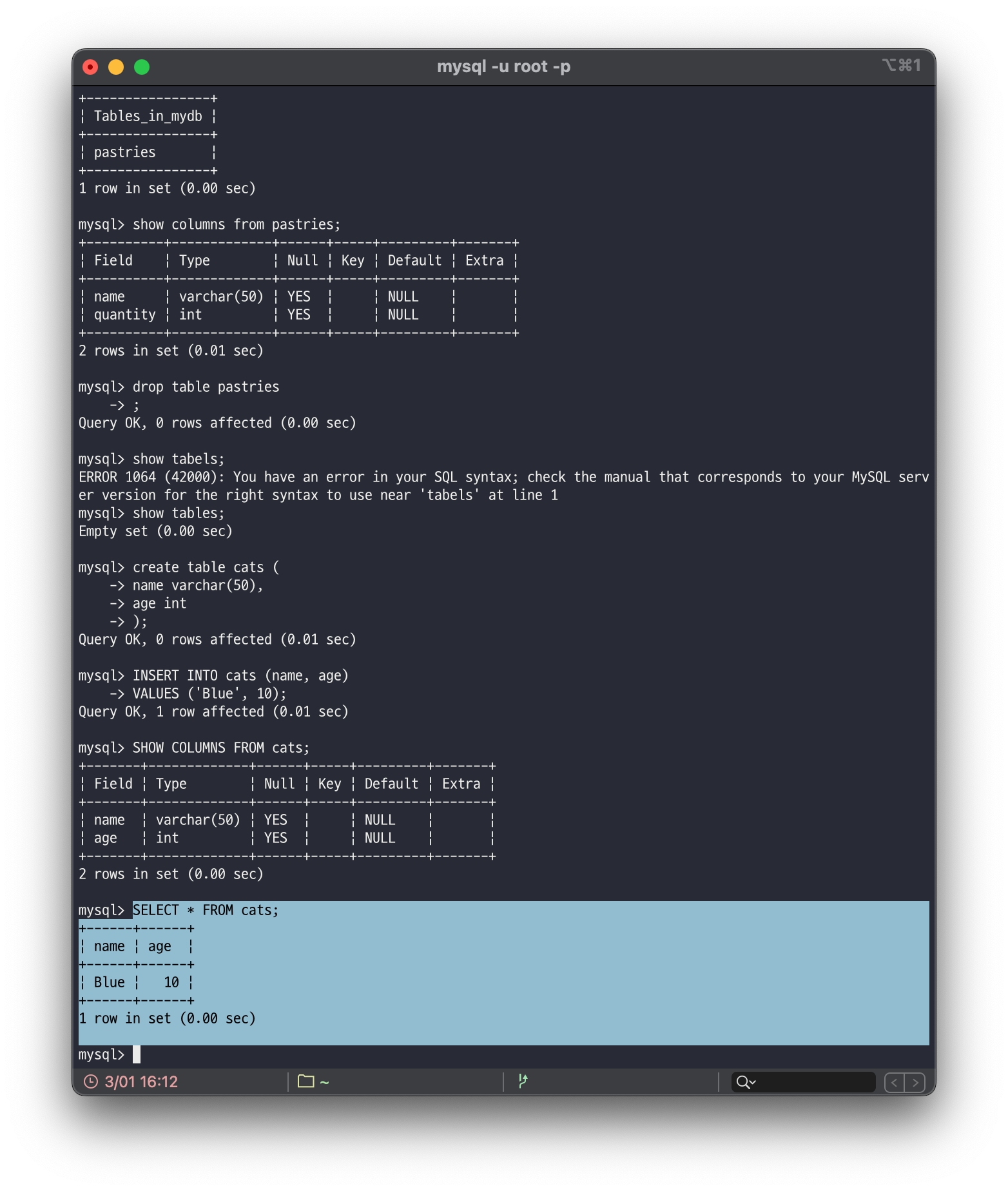
위 그림에서는 cats라는 테이블의 모든 칼럼에 대한 데이터를 조회하는 명령어를 사용한 결과입니다.
주의할 점으로 여러 컬럼을 조회하기 위해 ,(콤마)로 구분한다면 각 칼럼들은 독립적이며 다른 컬럼을 조회할 때 영향을 주지 않습니다. 각 칼럼에 작성된 순서대로 조회될 뿐입니다.
Aliases
AS를 통해 표시될 칼럼명을 변경할 수 있습니다. 실제 칼럼명을 변경하는 것은 아니며 출력될 때의 칼럼명을 지정할 수 있습니다.
mysql> SELECT <column_name> AS <aliases>
-> FROM <table_name>;WHERE <Condition>
WHERE 명령어는 조건문와 유사한 명령어입니다. 조회나 업데이트, 삭제와 같은 동작과 함께 사용되며 행을 특정하기 위해서 사용합니다.
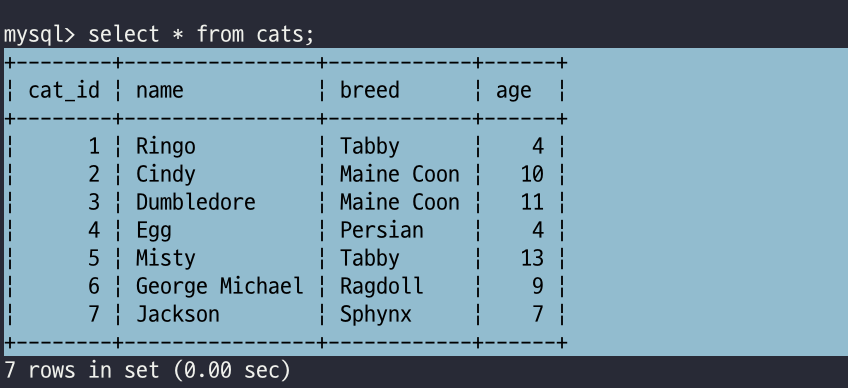
아래와 같은 테이블을 기준으로 설명하겠습니다.
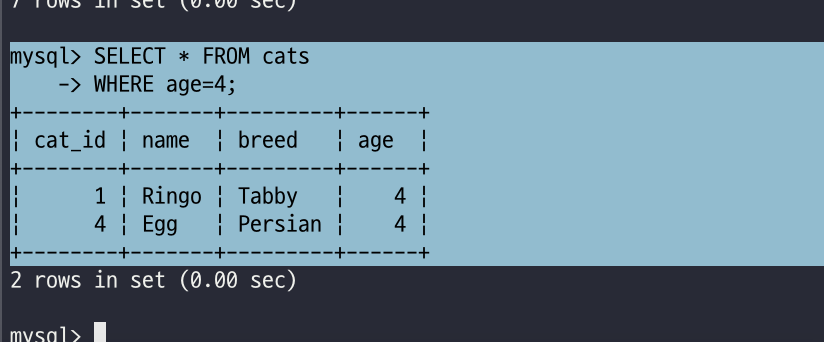
mysql> SELECT * FROM cats
-> WHERE age=4;위와 같은 명령어는 cats 테이블의 모든 행에 대해서 age 칼럼의 값이 4인 행을 조회하는 명령어입니다.
UPDATE <table_name> SET <column_name>=value
UPDATE SET 명령어를 통해 데이터를 변경할 수 있습니다.
mysql> UPDATE <table_name> SET <column_name>=value
-> WEHERE 조건;아래와 같은 테이블을 기준으로 설명하겠습니다.
mysql> UPDATE cats SET breed='Shorthair'
-> WHERE breed='Tabby';위와 같은 명령어는 cats 테이블에서 breed 칼럼값이 Tabby인 행들의 breed 칼럼값을 Shorthair로 변경합니다.
WHERE을 통해 행들을 특정하고, UPDATE SET을 통해 특정한 행들의 특정 칼럼값을 변경하는 명령어입니다.
DELETE FROM <table_name>
DELETE 명령어를 통해서 행을 제거할 수 있습니다.
mysql> DELETE FROM <table_name>
-> WHERE 조건;아래와 같은 테이블을 기준으로 설명하겠습니다.
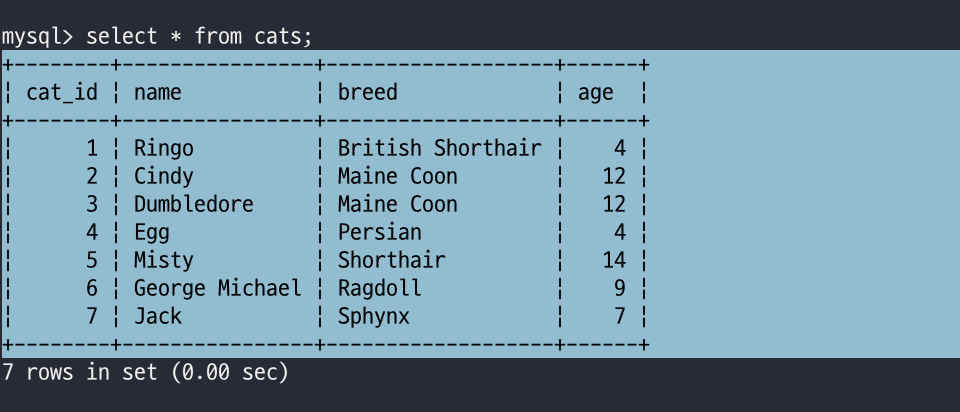
mysql> DELETE FROM cats
-> WHERE name='Egg';위와 같은 명령어는 cats 테이블에서 name 칼럼값이 Egg인 행을 제거하는 명령어입니다.
String Functions
CONCAT()
CONCAT() 함수는 데이터 조각, 즉 문자열을 결합하는 동작을 수행합니다. 함수를 실행할 때는 SELECT FROM 명령어를 통해 테이블을 선택해야 합니다.
CONCAT() 함수의 인수로는 컬럼명 혹은 문자열을 전달할 수 있으며, 문자열들을 연결한 하나의 문자열을 출력하기 위해서 사용합니다.
mysql> SELECT CONCAT(column_name, columns_name,,,)
-> FROM <table_name>;이때 출력되는 컬럼명은 CONCAT 함수 호출문으로 설정되며 이는 AS를 사용하여 변경할 수 있습니다.
mysql> SELECT CONCAT(column_name, columns_name,,,) as alias
-> FROM <table_name>;CONCAT_WS()
CONCAT_WS() 함수는 문자열을 연결할 때 구분자를 전달할 수 있습니다. 첫 번째 인수로 구분자를 전달하고, 두 번째 인수 이후부터 연결될 데이터를 나타내는 칼럼명이나 문자열을 전달합니다.
mysql> SELECT CONCAT_WS(separator, column_name, columns_name,,,)
-> FROM <table_name>;SUBSTRING()
SUBSTRING() 함수는 문자열의 부분 문자열을 추출할 수 있습니다. 첫 번째 인수로는 작업할 문자열 혹은 칼럼명을 전달하고, 두 번째 인수로 추출할 시작 인덱스, 두 번째로는 마지막 인덱스를 전달합니다.
만약 세 번째 인수를 전달하지 않는다면 두 번째 인수를 시작으로 끝까지 부분 문자열로 추출하게 됩니다.
음수를 전달하는 경우 끝에서부터의 인덱스를 의미합니다. 즉, 가장 끝 인덱스의 경우 -1을 의미합니다.
참고로 MySQL의 인덱스는 1부터 시작합니다.
mysql> SELECT SUBSTRING(column_name, start, end)
-> FROM <table_name>;REPLACE()
REPLACE() 함수는 문자열 일부를 치환하기 위한 함수입니다. 첫 번째 인수로 대상이될 문자열 혹은 칼럼명을 전달하고, 두 번째 인수로는 치환될 대상 문자열, 세 번째 인수로는 치환할 문자열을 전달합니다.
mysql> SELECT REPLACE(column_name, old_str, new_str)
-> FROM <table_name>;REVERSE()
REVERSE() 함수는 문자열의 순서를 뒤집기위해서 사용하는 함수입니다. 인수로 대상이되는 데이터의 칼럼명을 전달합니다.
mysql> SELECT REVERSE(column_name)
-> FROM <table_name>CHAR_LENGTH()
CHAR_LENGTH() 함수는 문자열의 길이를 출력하기 위해 사용하는 함수입니다. 인수로 대상이되는 데이터의 칼럼명을 전달합니다.
mysql> SELECT CHAR_LENGTH(column_name)
-> FROM <table_name>UPPER(), LOWER()
UPPER() 함수는 문자열을 모두 대문자, LOWER() 함수는 모두 소문자로 출력하기 위해 사용합니다. 인수로 대상이 되는 데이터의 칼럼명을 전달합니다.
mysql> SELECT UPPER(column_name), LOWER(column_name)
-> FROM <table_name>;Refining Selections
DISTINGT
DISTINGT는 SELECT에 결합하여 사용합니다. 데이터를 조회하여 나온 결과에서 중복을 제거시켜줍니다.
mysql> SELECT DISTINGT <column_name>
-> FROME <table_name>;위 쿼리문처럼 DISTINGT 뒤에 중복을 제거할 컬럼명을 나열해 줍니다.
ORDER BY
ORDER BY는 결과를 정렬하기 위해서 사용합니다.
mysql> SELECT <column_name>,,,
-> FROME <table_name>
-> ORDER BY <column_name>;쿼리문 마지막에 위와 같이 작성해 줍니다. 기본적으로 오름차순으로 정렬하며, 내림차순으로 정렬하려면 DESC를 추가적으로 작성해줍니다.
즉, 기본적으로는 ASC가 작성된 것과 동일합니다.
mysql> SELECT <column_name>,,,
-> FROME <table_name>
-> ORDER BY <column_name> DESC;LIMIT
LIMIT은 조회할 데이터의 개수를 제한할 수 있습니다. 쿼리문 마지막에 작성해줍니다.
mysql> SELECT <column_name>,,,
-> FROME <table_name>
-> LIMIT <count>;쿼리문 마지막에 LIMIT을 작성하고 조회할 데이터의 개수를 작성해줍니다.
LIMIT <start>, <count> 형식으로 시작될 데이터와 조회할 데이터의 개수를 명시할 수도 있습니다. 이때 시작 인덱스는 0부터 시작합니다.
Aggregate Functions
GROUP BY
GROUP BY는 여러 데이터 중 중복되는 데이터를 하나의 데이터로 표시해줍니다.
mysql> SELECT <column_name>,,
-> FROM <table_name>
-> GROUP BY <column_name>;위 쿼리문처럼 마지막에 GROUP BY를 작성하고 그룹핑될 칼럼을 작성해줍니다. 그러면 기준이된 칼럼의 중복되는 데이터들을 하나의 그룹으로 조회합니다.
COUNT()
COUNT() 함수는 조회된 데이터의 개수를 조회할 수 있습니다. 인수로 조회할 데이터의 칼럼명을 전달합니다.
mysql> SELECT COUNT(*)
-> FROME <table_name>;mysql> SELECT column_name, COUNT(*)
-> FROM <table_name>
-> GROUP BY <column_name>;GROUP BY를 사용한 경우 COUNT(*)를 통해서 각 그룹의 데이터 개수를 조회할 수 있습니다.
MIN(), MAX()
MIN()과 MAX() 함수는 조회된 데이터의 최소, 최대값을 조회할 때 사용하는 함수입니다. 인수로 조회할 데이터를 나타내는 컬럼명을 전달합니다.
mysql> SELECT MIN(column_name,,,)
-> FROM <table_name>GROUP BY와 함께 사용한다면 그룹핑된 데이터의 최소, 최대값을 구할 수 있습니다.
myslq> SELECT MAX(column_name)
-> FROM <table_name>
-> GROUP BY <column_name>SUM()
SUM()은 조회된 데이터의 합을 조회하기 위해 사용합니다. 인수로 조회될 데이터를 나타내는 컬럼명을 전달합니다.
mysql> SELECT SUM(column_name)
-> FROM <table_name>;GROUP BY와 함께 사용하여 그룹 내 특정 데이터의 합을 조회할 수 있습니다.
mysql> SELECT column_name, SUM(column_name)
-> FROM <table_name>
-> GROUP BY <column_name>;AVG()
AVG() 함수는 조회된 데이터의 평균을 조회하기 위해 사용합니다. 인수로 대상이되는 데이터를 나타내는 칼럼명을 전달합니다.
mysql> SELECT AVG(column_name)
-> FROM <table_name>;GROUP BY와 함께 사용하여 그룹 내 특정 데이터의 평균을 조회할 수 있습니다.
mysql> SELECT column_name, AVG(column_name)
-> FROM <table_name>
-> GROUP BY <column_name>;DATE Funtions
CRUDATE()
CRUDATE() 함수는 현재 날짜 값을 제공합니다(DATE).
CURTIME()
CURTIME() 함수는 현재 시각 값을 제공합니다(TIME).
NOW()
NOW() 함수는 현재 날짜와 시각 값을 제공합니다(DATETIME).
DAY(DATE | DATETIME)
DAY(DATE | DATETIME) 함수에 인수로 날짜가 포함된 값을 전달하면 요일(DAY) 값을 출력합니다.
DAYNAME(DATE | DATETIME)
DAYNAME(DATE | DATETIME) 함수에 인수로 날짜가 포함된 값을 전달하면 요일의 이름(Monday,,,)을 출력합니다.
DAYOFWEEK(DATE | DATETIME)
DAYOFWEEK(DATE | DATETIME) 함수에 인수로 날짜가 포함된 값을 전달하면 요일의 이름을 숫자로 반환합니다(Sunday의 경우 1, Saturday의 경우 7).
DAYOFYEAR(DATE | DATETIME)
DAYOFYEAR(DATE | DATETIME) 함수에 인수로 날짜가 포함된 값을 전달하면 해당 해의 첫 날부터 인수로 전달한 날짜까 지난 일의 수를 숫자값으로 반환합니다.
DATE_FORMAT(DATE | DATETIME, format)
DATE_FORMAT(DATE | DATETIME, format) : 날짜를 원하는 형식의 포맷으로 반환해줍니다. format은 format에서 확인할 수 있습니다.
DATEDIFF(DATE | DATETIME, DATE | DATETIME)
DATEDIFF(DATE | DATETIME, DATE | DATETIME) 함수는 두 날짜의 차이를 일의 수로 반환합니다.
(DATE | DATETIME) + | - (INTERVAL expr UNIT)
(DATE | DATETIME) + | - (INTERVAL expr UNIT) : 특정 날짜에서 원하는 날을 구할 수 있습니다.
예를 들어, DATE + INTERVAL 3 MONTH는 특정 날짜에서 3달이 지난 값을, DATETIME - INTERVAL 1 MONTH + 10 HOURS는 특정 날짜에서 1달 이전 날짜에서 10시간 더한 값을 반환합니다.
Comparison & Logical Operators
WHERE 절에서 조회할 특정 데이터에 대한 조건을 작성할 수 있습니다. 이때 작성되는 조건은 아래와 같은 연산자들을 사용합니다.
Equal & Not Equal
=와 != 논리 연산자를 사용하여 값을 비교할 수 있습니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE <column_name> != value;LIKE & Not LIKE
LIKE는 특정 문자열을 포함하는 데이터를 찾고자할 때 사용합니다.
mysql> SELECT <column_name>,,,
-> FROM <table_name>
-> WHERE <column_name> LIKE value;포함되어야 하는 문자열 값에 "%"으로 와일드카드를 사용할 수 있고, "_"을 통해 하나의 문자를 나타낼 수도 있습니다.
반대로 NOT LIKE는 반대로 특정 문자열 값이 포함되지 않은 값을 조회할 수 있습니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE <column_name> NOT LIKE value;Comparison
>, <, >=, <= 비교 연산자를 사용하여 특정 값과 비교하여 일치되는 데이터만을 조회할 수 있습니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE <column_name> >= value;MySQL에서 소문자와 대문자 모두 동일하게 처리합니다.
AND
&& 논리 연산자는 AND와 동일한 연산자입니다. 즉, 피연산자의 평가 결과가 모두 true인 경우에만 true이며 하나라도 false인 경우 false로 평가됩니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE <columna_name> = value && <column_name> > value;위 쿼리문은 && 연산자 앞 뒤 평가 결과가 모두 true인 데이터를 조회하게 됩니다.
OR
||연산자는 OR와 동일한 연산자입니다. 즉, 피연산자의 평가 결과가 하나라도 true인 경우 true이며 하나라도 false라면 false로 평가됩니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE <columna_name> = value || <column_name> > value;위 쿼리문은 || 연산자 앞 혹은 뒤의 평가 결과가 하나라도 true인 데이터를 조회하게 됩니다.
BETWEEN AND && NOT BETWEEN AND
BETWEEN을 통해 두 값 사이에 있는 데이터를 조회할 수 있습니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE <column_name> BETWEEN value AND value;위 쿼리문은 아래와 동일한 쿼리문입니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE column_name >= value &&
column_name <= value;NOT BETWEEN AND는 반대로 동작합니다. 즉, 두 값 사이에 있는 데이터를 제외한 데이터들을 조회합니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE <column_name> NOT BETWEEN value AND value;위 쿼리문은 아래 쿼리문과 동일합니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE column_name < value &&
column_name > value;CAST()
CAST() 함수는 원하는 데이터 타입으로 값을 변경시켜주는 함수입니다. 즉, DATE 타입을 DATETIME으로 변환하거나 CHAR을 VARCHAR로 변환할 때 사용합니다.
myslq> SELECT CAST(value AS TYPE);IN & NOT IN
IN 연산자는 특정 값이 포함된 데이터를 조회할 때 사용합니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE IN (value, ,,,);괄호 안에 작성된 값을 중 하나와 매칭되는 데이터들을 조회하게 됩니다.
NOT IN은 NOT과는 반대로 동작하며 특정 값이 포함되지 않은 데이터를 조회할 때 사용합니다.
mysql> SELECT <column_name>
-> FROM <table_name>
-> WHERE NOT IN (value, ,,,);CASE Statements
CASE 구문을 통해 특정 조건에 따른 값을 생성할 수 있습니다.
mysql> SELECT <column_name>,
-> CASE
WHEN <column_name> > value THEN value
WHEN ,,, THEN ,,,
ELSE value
END
FROM <table_name>;위 쿼리문의 CASE 구문에서 WHEN 절이 조건에 해당되며 THEN 절은 해당 조건에 만족할 때의 값을 나타냅니다. 그리고 마지막에 ELSE 절은 통해 모든 조건에 만족하지 않을 때의 값을 나타냅니다.
CASE 구문 마지막에는 END를 작성하여 CASE 구문의 마지막임을 나타냅니다.
JOIN
CROSS JOIN
기준 테이블과 조인되는 테이블의 각 데이터들을 모두 합치게 됩니다.
mysql> SELECT *
-> FROM <table_name>, <table_name>;두 테이블의 각 데이터들을 모두 합친, 모든 경우의 수를 나타냅니다.
INNER JOIN
기준이 되는 테이블과 조인이 되는 테이블의 데이터들을 합치는데 결합 조건에 만족하도록 데이터들을 합쳐줍니다.
mysql> SELECT <column_name>,,,
-> FROM <table_name>
-> INNER JOIN <table_name> ON <Condition>;INNER JOIN 문 뒤에는 조인될 테이블명을 작성하고, ON 뒤에는 결합 조건을 작성해줍니다. 즉, 작성한 결합 조건을 만족하는 두 테이블의 데이터를 합쳐줍니다.
LEFT JOIN
기준 테이블에 모든 데이터를 취한 다음 결합 조건에 맞게 오른쪽 테이블의 데이터를 합치게 됩니다. 기준 테이블에서 조인 테이블과 합쳐지지 못한 데이터들은 NULL 값으로 합쳐지게 됩니다.
mysql> SELECT <column_name>,,,
-> FROM <table_name>
-> LEFT JOIN <table_name> ON <Condition>;만약 NULL 값이 아닌 다른 값으로 채워지기를 원한다면 IFNULL() 함수를 사용할 수 있습니다. 첫 번쨰 인수로는 대상이 될 칼럼, 두 번째 인수로는 변환될 값을 전달합니다.
RIGHT JOIN
조인될 테이블의 모든 데이터를 취하고 기준 테이블의 데이터를 결합 조건에 맞게 합치는데 조인될 테이블의 데이터 중 결합되지 못한 데이터들은 NULL 값으로 합쳐지게 됩니다.
mysql> SELECT <column_name>,,,
-> FROM <table_name>
-> RIGHT JOIN <table_name> ON <Condition>;