아래는 약 1년( 2010년 12월 ~ 2011년 12월 ) 의 기간 동안 A회사 오픈마켓 플랫폼에서 발생한 데이터를 수집 및 RFM 분석을 진행한 프로젝트이다.
데이터셋은 2010년 12월 1일부터 2011년 12월 9일까지 영국에 기반을 둔 등록된 무매장 온라인 소매업체에서 발생한 모든 거래를 포함하는 국제적 데이터 세트이다. 이 회사는 주로 독특한 모든 행사용 선물을 판매합니다. 이 회사의 많은 고객은 도매업체이다. 우리는 이 회사를 A 회사라고
지칭하겠다.
A회사는 오픈마켓 플랫폼을 운영 중으로 런칭 이후 사용자들이 빠르게 상승하였지만, 현재는 정체기에 빠져있다. 현재 서비스 이용 수준이 어떻게 되고 있으며 런칭 이후 어떻게 변해왔는지를 파악하기 위해 데이터 전처리, 데이터 EDA, RFM 분석을 수행할 것이다.
⛳ 문제 정의
- 서비스 정체기로 인한 영업 이익과 사용자 수의 감소
⛳ 기대효과
- 정체 원인 파악 및 대응책 수립 및 실행을 통한 영업이익, 사용 고객수 증가
⛳ 해결방안
- 구매 데이터 활용 서비스 이용 현황 파악
- 분석을 통한 데이터 현황 파악이 가능한 지표 기획 및 개발
⛳ 성과측정
- 지표를 활용한 서비스 사용 현황 파악
⛳ 운영
- 지표 활용 데이터 인사이트 리포트 발행
- 개발된 지표 활용 대시보드(*BI tool 활용) 개발 후 모니터링 및 이슈 확인
RFM 분석이란?
RFM 분석은 RECENCY 최근성, FREQUENCY 구매빈도, MONETARY 구매금액 별로 계산을 해서
일부 점수 구간에 따라 서비스 등급(Grade)를 부여하는 것이다.RECENCY 최근성은 최근 구매 시기를 말하며 가장 최근에 구매한 고객일수록 점수가 높다.
FREQUENCY 구매 및 거래 빈도를 말하며 구매빈도는 많이 구매한 고객일수록 점수가 높다.
MONETARY 구매의 규모 또는 구매 금액을 말하며 구매금액은 많은 금액을 구매한 고객일수록 점수가 높다.점수를 계산한 후 내부에서 정한 점수별 등급으로 고객별 RFM 점수에 대한 등급을 정의한다.
이후 월 별로 매월마다 중요한 그룹별 고객에 대한 비중이 떨어지는지 올라가는지 분석하는 것이
RFM 분석의 목적이다.
데이터셋 정의
# ▶ pd.set option
import numpy as np
import pandas as pd
pd.set_option('display.max_columns',100)
pd.set_option('display.max_rows',100)
# ▶ Data read
df=pd.read_csv('S_PJT06_DATA.csv', encoding='ISO-8859-1')
df.head()
InvoiceNo 송장번호: 운송장 번호이다.
StockCode 재고코드: 제품의 재고 코드이다.
Description 상세설명: 제품에 대한 상세 설명이 적혀있다.
Quantity 수량: 주문한 제품의 수량 데이터가 있다.
InvoiceDate 송장날짜: 송장이 발부된 날짜로 주문을 한 날짜이다.
UnitPrice 개당가격: 각 제품 한 개의 가격이다.
CustomerID 고객ID: 구매한 고객의 id이다.
Country 나라: 구매한 고객의 나라이다.
확인 결과 한 고객이 여러 개의 주문을 하였고 같은 고객이 주문한 데이터는 송장번호와 고객id 열의 값이 같은 경우가 있다.
데이터 전처리
(1) Data shape(형태) 확인
# ▶ Data 형태 확인
# ▶ 541,909 row, 8 col로 구성됨
print('df', df.shape)
df (541909, 8)- 총 54만 개의 행으로 이루어진 데이터이다.
(2) Data type 확인
# ▶ Data type 확인
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 541909 entries, 0 to 541908
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 InvoiceNo 541909 non-null object
1 StockCode 541909 non-null object
2 Description 540455 non-null object
3 Quantity 541909 non-null int64
4 InvoiceDate 541909 non-null object
5 UnitPrice 541909 non-null float64
6 CustomerID 406829 non-null float64
7 Country 541909 non-null object
dtypes: float64(2), int64(1), object(5)
memory usage: 33.1+ MB- 총 8개의 열 데이터가 있으며 invoicedate가 날짜열 데이터가 아닌 object 타입으로 지정되어 있다. 아마 년월일 과 시간 데이터가 합쳐져 있는 것으로 보이며 이후 경우에 따라 날짜 데이터가 필요할 때 날짜형 데이터 타입으로 변경이 필요할 것이다. 나머지 데이터 타입은 이상이 없어 보인다.
(3) Null값 확인 (※ 빈 값의 Data)
# ▶ Null 값 확인
print(df.isnull().sum())
InvoiceNo 0
StockCode 0
Description 1454
Quantity 0
InvoiceDate 0
UnitPrice 0
CustomerID 135080
Country 0
dtype: int64-
꽤 많은 양의 null 값을 가지고 있어서 분석을 했을 때 부정확한 결과가 나올 확률이 높다. 따라서 null 값을 이후 제거해야 한다.
-
customer id가 없다는 것은 고객을 특정지을 수 없고 누가 샀는지 알 수 없어 의미가 없는 데이터이다.
(4) Outlier 확인 (이상치, 정상적인 범주를 벗어난 Data)
# ▶ Outlier 확인
df.describe()
index Quantity UnitPrice CustomerID
0 count 541909.000000 541909.000000 406829.000000
1 mean 9.552250 4.611114 15287.690570
2 std 218.081158 96.759853 1713.600303
3 min -80995.000000 -11062.060000 12346.000000
4 25% 1.000000 1.250000 13953.000000
5 50% 3.000000 2.080000 15152.000000
6 75% 10.000000 4.130000 16791.000000
7 max 80995.000000 38970.000000 18287.000000
``` ​:citation[oaicite:0]{index=0}​- quantity 수량, unitprice 개당 최소가격이 마이너스 값이 나와서는 안되는 값들이 outlier가 나왔으며 이를 제거해주어야 한다.
(5) 데이터 전처리 진행
- null 값 제거
# ▶ null value drop
# ▶ CustomerID 기준으로 Null value drop
df.dropna(subset=['CustomerID'], how='all', inplace=True)
df.isnull().sum()
InvoiceNo 0
StockCode 0
Description 0
Quantity 0
InvoiceDate 0
UnitPrice 0
CustomerID 0
Country 0
dtype: int64- cutomer id를 기준으로 null 값을 제거해서 그 행 안에 descreption이 null 값인 것들도 모두 삭제됨.
outlier(이상치) 제거
# ▶ distplot 활용 음수 데이터 분포 확인
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use(['dark_background'])
sns.distplot(df['Quantity'])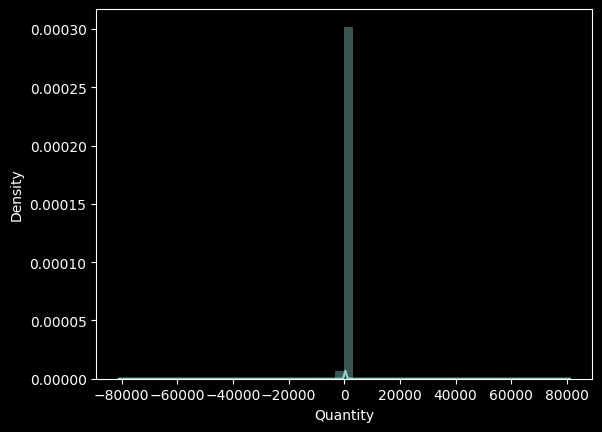
- quantity의 분포를 확인하니 0에 가까이 분포해야 할 quanity가 -8만까지 비정상적으로 분포해 있다.
# ▶ Quantity 음수값 제거
# 데이터 프레임에서 Quantity가 0보다 큰 행만 남기고 나머지를 제거하는 필터링 작업을 수행
df = df[df['Quantity']>0]
- 데이터 프레임에서 UnitPrice가 0보다 큰 행만 남기고 나머지를 제거하는 필터링 작업을 하여 아까 확인했던 이상치들을 제거해 준다.
# ▶ UniPrice 음수값 제거
df = df[df['UnitPrice']>0]
- 마찬가지로 개당 가격의 데이터 내 이상치도 같은 방법으로 제거해준다.
df.shape
(397884, 8)- 이상치 제거, null 값 제거 이후 최종적으로 남은 데이터셋은 397,884 개이다.
지표 기획 및 'RFM' 분석
- 고객별 등급을 나타낼 수 있게 고유한 고객 데이터인
customer id를 기준으로 최근성, 구매빈도, 구매금액 - customer id + Recency + Frequency + Monetary
(1) Recency(최근성)
# ▶ str.split을 사용해서 송장 데이터에 날짜 데이터만 추출하기
# 보통 시간별 데이터는 필요가 없다. 그래서 str.split 을 사용한다.
# 판다스 데이터프레임에서 인식하는 시간형태의 데이터 타입으로 인식
import pandas as pd
df['Date'] = pd.to_datetime(df['InvoiceDate'].str.split(' ').str[0])
df.head(5)
index InvoiceNo StockCode Description Quantity \
0 0 536365 85123A WHITE HANGING HEART T-LIGHT HOLDER 6
1 1 536365 71053 WHITE METAL LANTERN 6
2 2 536365 84406B CREAM CUPID HEARTS COAT HANGER 8
3 3 536365 84029G KNITTED UNION FLAG HOT WATER BOTTLE 6
4 4 536365 84029E RED WOOLLY HOTTIE WHITE HEART. 6
InvoiceDate UnitPrice CustomerID Country Date
0 12/1/2010 8:26 2.55 17850.0 United Kingdom 2010-12-01 00:00:00
1 12/1/2010 8:26 3.39 17850.0 United Kingdom 2010-12-01 00:00:00
2 12/1/2010 8:26 2.75 17850.0 United Kingdom 2010-12-01 00:00:00
3 12/1/2010 8:26 3.39 17850.0 United Kingdom 2010-12-01 00:00:00
4 12/1/2010 8:26 3.39 17850.0 United Kingdom 2010-12-01 00:00:00
``` ​:citation[oaicite:0]{index=0}​
str.split을 사용해서 송장 데이터에서 날짜 데이터만 추출하여Date열을 새롭게 만들어준다.Date열 데이터도 판다스 데이터프레임에서 인식하는 시간형태의 데이터 타입으로 인식하도록pd.to_datetime메서드를 사용한다.- 하지만 아래와 같은 방식으로도 날짜 부분 데이터만 추출할 수도 있다.
# InvoiceDate 열을 datetime 형식으로 변환
df['InvoiceDate'] = pd.to_datetime(df['InvoiceDate'])
# 날짜 부분만 추출
df['InvoiceDate'] = df['InvoiceDate'].dt.date분석해야 하는 최근성 데이터, 즉 날짜에 대한 range를 확인해본다.
df['Date'].min(), df['Date'].max()- 2010년 12월부터 2011년 12월까지의 1년 정도의 데이터를 분석한다.
이제 Recency를 구해보자
Recency는 마지막 구매일로부터 몇 일이 지났는지를 계산하면 알 수 있다.
따라서 데이터셋의 가장 최근 날짜에서 고객의 가장 마지막 구매일을 빼면 Recency를 구할 수 있다.
- 가장 최근 날짜 - 고객의 마지막 구매일
▶ 고객ID별 가장 마지막 구매일
# customer id를 기준으로 고객별로 `date` 열을 max로 게산해서 날짜 중 가장 큰 값
# 즉 고객별로 마지막 구매일자를 나타내는 값을 그룹화한다.
recency_df = df.groupby('CustomerID', as_index=False)['Date'].max()
recency_df.columns = ['CustomerID','LastPurchaseDate']
# 이후 고객의 가장 마지막 구매일로 부터 몇일이 지났는지를 계산한다.
recency_df['Recency'] = recency_df['LastPurchaseDate'].apply(lambda x : (df['Date'].max() - x).days)
recency_df.drop(columns=['LastPurchaseDate'],inplace=True)
recency_df.head(5)
CustomerID Recency
0 12346.0 325
1 12347.0 2
2 12348.0 75
3 12349.0 18
4 12350.0 310
- 첫번째 고객은 구매한지 325일이 됐기에 이 기간동안 접속을 하지 않은 것을 의미한다.
- 두 번째 고객은 이틀 전에 접속을 했으며 충성고객이라고 할 수 있다.
- lambda를 사용하지 않고도 아래와 같이 Recency를 계산할 수도 있다.
# Date 열의 최대값 구하기
max_date = df['Date'].max()
# Recency 계산
recency_df['Recency'] = (max_date - recency_df['LastPurchaseDate']).dt.days
recency_df.drop(columns=['LastPurchaseDate'],inplace=True)숫자로만 recency를 확인하기는 어려우니 시각화를 통해 분포를 확인해보자.
#recency에 대한 분포도 확인
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use(['dark_background'])
sns.displot(data = recency_df, x="Recency");
plt.gcf().set_size_inches(16.5, 3)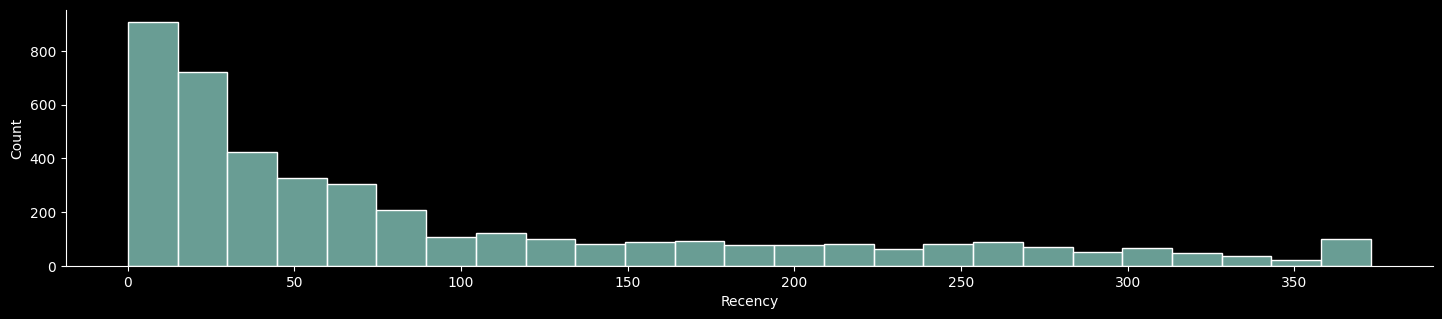
- 대부분의 고객들이 최근에 구매를 했지만 반면 오래된 고객들을 다시 참여시키기 위한 전략이 필요할 것으로 보인다.
(2) Frequency(최빈성 및 구매빈도)
해당 데이터는 한 구매자가 여러 개를 동시다발적으로 구매해 중복되는 데이터가 존재하고 구매횟수가 부풀려질 가능성이 있다. 따라서 Frequency(최빈성 및 구매빈도)을 구하기 위해서는 CustomerID와 InvoiceNo가 동일한 중복 행을 제거하여, 각 고객의 고유한 구매 기록만 데이터 프레임에서 남겨 송장번호가 같은 데이터들을 하나의 구매로 묶어 간주하도록 만든다.
이후 중복이 제거된 고유한 구매건들을 customer id 별로 계산한다.
# 데이터프레임 복사
frequency_df = df.copy()
# 원본 데이터프레임을 보호하고, 새로운 데이터프레임을 생성하기 위해 df를 복사
# 이후 frequency_df 데이터프레임을 생성
# 중복 행 제거
frequency_df.drop_duplicates(subset=['CustomerID', 'InvoiceNo'], keep='first', inplace=True)
# CustomerID와 InvoiceNo가 동일한 중복 행을 제거하여, 각 고객의 고유한 구매 기록만 남김
# 동일 고객이 동일한 인보이스로 여러 번 구매한 경우, 이를 하나의 구매로 간주하여
# 중복을 제거하기 위함.
# CustomerID 기준으로 그룹화하고 InvoiceNo의 개수를 계산
frequency_df = frequency_df.groupby('CustomerID', as_index=False)['InvoiceNo'].count()
# 각 CustomerID별로 InvoiceNo의 개수를 계산하여 구매 빈도(Frequency)를 구함
# as_index=False 옵션을 사용하여 CustomerID를 인덱스로 그룹화하지 않고
# 데이터프레임 형식을 유지하도록 함
# 컬럼 이름 변경
frequency_df.columns = ['CustomerID', 'Frequency']
# 결과 데이터프레임의 컬럼 이름을 CustomerID와 Frequency로 변경하여 의미를 명확히 함
frequency_df.head() # 결과 데이터프레임의 첫 몇 행을 출력하여 확인
CustomerID Frequency
0 12346.0 1
1 12347.0 7
2 12348.0 4
3 12349.0 1
4 12350.0 1- Customer ID당 유니크한 Invoice를 1개의 주문건으로 인식하여 얼마나 자주 구매하고 있는지를 파악할 수 있었다.
(3) Monetary(구매금액)
Monetary(금액)을 구하기 위해서는 개당 가격인 Unitprice와 구매 수량인 Quantity를 개산하여 Customer id 별로 분류하면 각 고객 당 총 구매금액을 구할 수 있다.
▶ 구매금액 = 구매개수 * 구매단가
# ▶ 구매금액 = 구매개수 * 구매단가
# 구매금액 계산하여 'Total_cost`라는 열이 생성된 새로운 데이터프레임 생성
df['Total_cost'] = df['UnitPrice'] * df['Quantity']
# 고객 id를 기준으로 구매금액의 합계를 계산하여 그룹화
monetary_df=df.groupby('CustomerID',as_index=False)['Total_cost'].sum()
# 고객별로 구매금액의 합계를 계산해 Monetary를 계산하고 이를 monetary_df 데이터프레임에 생성
# 그룹화하여 결과를 나타낸 monetary_df의 column을 'CustomerID','Monetary'로
#변경하여 의미를 명확히 함.
monetary_df.columns = ['CustomerID','Monetary']
# 결과 데이터프레임 출력 (예시용), 첫 5개의 데이터 확인.
monetary_df.head()
CustomerID Monetary
0 12346.0 77183.60
1 12347.0 4310.00
2 12348.0 1797.24
3 12349.0 1757.55
4 12350.0 334.40- Customer ID당 총 구매금액을 알 수 있었다.
(4) RFM DATA 병합 (MERGE)
RFM 분석은 각 데이터를 계산하는 것에서 끝나는 것이 아니라 이제 계산 결과를 분석해 점수를 매기고 등급을 나누는 것이 목적이다.
따라서 이제까지 구했던 Recency, Frequency, Monetary 데이터를 병합해 하나의 데이터프레임으로 모아야 한다.
# ▶ Data merge
# ▶ recency and frequency
rf = recency_df.merge(frequency_df,how='left',on='CustomerID')
# 최근성 데이터에 구매 빈도 데이터를 `CustomerID`를 기준으로 왼쪽 조인(left join) 통해merge(병합)한다.
# 왼쪽 조인을 사용한 이유는 recency_df에 있는 모든 CustomerID가 포함되도록 하기 위함이다.
# ▶ monetary
# 위에서 생성한 rf 데이터프레임과 monetary_df 데이터를 Customer ID를 기준으로 왼쪽 조인하여 병합
# 이렇게 RFM 데이터 프레임을 생성한다.
# 왼쪽 조인은 RECENCY_DF에 있는 모든 고객 정보를 유지하기 위함이다.
rfm = rf.merge(monetary_df,how='left',on='CustomerID')
rfm.head(5)
# 첫 5개의 행을 출력하여 데이터 병합 결과를 확인함
rfm.head(5)
CustomerID Recency Frequency Monetary
0 12346.0 325 1 77183.60
1 12347.0 2 7 4310.00
2 12348.0 75 4 1797.24
3 12349.0 18 1 1757.55
4 12350.0 310 1 334.40RFM 활용 서비스 이용 수준 측정
(1) 스케일링
RFM 은 점수를 매겨 고객을 그룹핑하고 그룹핑한 고객에 대한 비중 변화를 점검 및 모니터링하기 위해 만드는 것이다.
위의 rfm 데이터 프레임의 숫자 단위의 수준 차이가 많이 나서 비교하고 점수화하기가 까다롭다.
이렇게 숫자 또는 점수의 수준이 차이가 나는 것을 Scail 이 차이가 난다고 한다.
Scail 차이가 나는 값들을 점수화 하고 계산하기 위해 데이터를 변형시키는 것이 스케일링 작업이라고 한다. 스케일링 방법에는 여러가지가 있지만 해당 프로젝트에서는 Min max scale 을 사용하였다.
Min max scale은 최대값을 1, 최소값을 0으로 표준화하여 데이터의 scail을 조정하는 기법이다. 그래서 Rececny, Frequency, Monetary 데이터의 값에 따라 각 최대 최소 값을 1과 0의 구간으로 통일 시키는 것이다.
# ▶ Min max scale = 최대값을 1, 최소값을 0으로 표준화하여 데이터의 scail을 조정
from sklearn.preprocessing import minmax_scale
# ▶ 최근성은 숫자가 작을수록, 즉 최근 구매일이 얼마 지나지 않은 고객이 더 점수가 높음
rfm['Recency'] = minmax_scale(rfm['Recency'], axis=0, copy=True)
rfm['Recency'] = 1-rfm['Recency']
# 그래서 예를 들어 325일 동안 구매를 하지 않은 사람의 Recency 최대 값은
# 1과 가깝게로 스케일링이 된다. 따라서 이를 다시 1로 빼주어 낮은 점수를 부여할 수 있도록 한다.
# Frequency 열을 기준으로 최대값을 1, 최소값을 0으로 표준화하여 데이터의 scail 진행
rfm['Frequency'] = minmax_scale(rfm['Frequency'], axis=0, copy=True)
# Monetary 열을 기준으로 최대값을 1, 최소값을 0으로 표준화하여 데이터의 scail 진행
rfm['Monetary'] = minmax_scale(rfm['Monetary'], axis=0, copy=True)
# ▶ Score
rfm['Score']=rfm['Recency']+rfm['Frequency']+rfm['Monetary']
# recency, frequency, monetary 세 개의 스케일링 점수를 모두 더해서 'score` 데이터가 추가된
# 데이터프레임을 만들어준다.
# ▶ 100점을 곱해서 100점 만점으로 scaling
rfm['Score']=minmax_scale(rfm['Score'], axis=0, copy=True)*100
#copy=True는 minmax_scale 함수에서 사용해, 원본 데이터를 복사할지 여부를 결정
#copy=True로 설정하면 원본 데이터를 유지하면서 정규화된 데이터를 새로운 배열에 저장한다.
# 'Score' 열의 값을 소수점 첫째 자리에서 반올림하여 정수 값으로 변환함.
# round 함수는 소수점 자리를 반올림하기 위해 사용됨.
rfm['Score']=round(rfm['Score'],0)
index CustomerID Recency Frequency Monetary Score
0 0 12346.0 0.128686 0.000000 0.275443 16.0
1 1 12347.0 0.994638 0.028846 0.015368 42.0
2 2 12348.0 0.798928 0.014423 0.006401 33.0
3 3 12349.0 0.951743 0.000000 0.006259 39.0
4 4 12350.0 0.168901 0.000000 0.001180 7.0
-
데이터 스케일링 이후 rfm 데이터에 대한 점수화를 진행한 값들을
Score열에 생성해주었다. -
하지만
score의 스케일 점수가 보기 어려운 상태로 보기 쉬운 점수로 표준화 작업이 필요하다. -
그래서 Min-Max 스케일링을 통해 0에서 1 사이의 값으로 변환한 Score의 값들을 100을 곱해 100점 만점의 점수로 표준화해주어 점수화하기 쉬운 형태로
Score의 값들을 변환해주었다.
(2) Grade(등급) 점수 구간화
score의 점수가 90점일 수도 있고 60점 일수도 있는 상황이기에 분포를 확인해 가장 적게 분포해 있는 점수를 최고점으로 지정하고 그 아래로 아랫 등급들을 지정해주어야 한다.
sns.displot(rfm['Score']);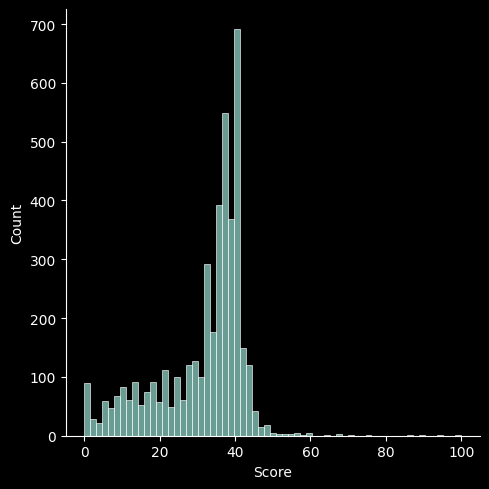
- score의 분포를 확인한 결과 대부분의 고객이 30~50 점의 분포를 띄고 있으며 60점에 해당하는 고객들도 일부 분포하는 것으로 보인다. 이를 바탕으로 등급화할 고객 점수를 설정한다.
- 그래서 60점 이상은 Very storong 등급 고객, 40~60점 Storng 등급 고객 20~40점 Normal 등급 고객 , 10~20점 Weak 등급 고객, 0~10점 Very Weak 등급 고객으로 설정하였다.
# ▶ 점수별로 고객의 등급을 부여
# 60점 이상 Very storong
# 40~60점 Storng
# 20~40점 Normal
# 10~20점 Weak
# 0~10점 Very Weak
# rfm 데이터프레임의 'Score' 열 값을 기준으로 등급을 매기기 위해 apply와 lambda 함수, if 조건문을 사용하고 각 점수 구간에 대해 특정 점수 및 조건을 만족하는 값들에 대해 등급을 할당함.
rfm['Grade'] = rfm['Score'].apply(lambda x : '01.Very Strong' if x>=60 else
('02.Strong' if x>=40 else
('03.Normal' if x>=20 else
('04.Weak' if x>=10 else '05.Very Weak'))))
rfm.head()
index CustomerID Recency Frequency Monetary Score Grade
0 0 12346.0 0.128686 0.000000 0.275443 16.0 04.Weak
1 1 12347.0 0.994638 0.028846 0.015368 42.0 02.Strong
2 2 12348.0 0.798928 0.014423 0.006401 33.0 03.Normal
3 3 12349.0 0.951743 0.000000 0.006259 39.0 03.Normal
4 4 12350.0 0.168901 0.000000 0.001180 7.0 05.Very Weak
5 5 12352.0 0.903485 0.033654 0.008930 38.0 03.Normal지표 기획
이제 전체적인 데이터 EDA를 완료했으니 A회사가 어떻게 변해왔는지를 파악하기 위해 데이터 현황 파악이 가능한 지표를 기획 및 개발하여 현재 서비스 이용 수준이 어떻게 되고 있으며 런칭 이후 어떻게 변해왔는지를 파악하도록 하자.
보통 매출 데이터 분석 및 RFM 분석에서는 월별 이용 건수, 월별 이용 고객과 지역 및 국가, 월별 고객 이용률에 대한 지표를 개발한다.
지표 개발에 앞서서 RFM 데이터와 기존 Df 데이터 프레임을 병합하여 지표 개발을 수월하게 할 수 있도록 했다.
▶ 기존 Data에 고객의 등급(Grade) Data를 left join
#rf = recency_df.merge(frequency_df,how='left',on='CustomerID')
# 기존 df 데이터프레임과 rfm 데이터프레임을 CustomerID를 기준으로 왼쪽 조인(left join)을 통해 병합함
# 이를 통해 df 데이터프레임에 RFM 데이터를 추가함
df = pd.merge(df, rfm, how='left', on='CustomerID')
# ▶ 지표 기획에 앞서, 년월만 새로운 col로 정의 (월별 이용 분석을 하기위한 준비과정)
df['Date_1'] = df["Date"].dt.strftime("%Y-%m")
df.head(5)
index | InvoiceNo | StockCode | Description | Quantity | InvoiceDate | UnitPrice | CustomerID | Country | Date | Total_cost | Recency_x | Frequency_x | Monetary_x | Score_x | Date_1 | Recency_y | Frequency_y | Monetary_y | Score_y | Grade
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
0 | 536365 | 85123A | WHITE HANGING HEART T-LIGHT HOLDER | 6 | 12/1/2010 8:26 | 2.55 | 17850.0 | United Kingdom | 2010-12-01 00:00:00 | 15.30 | 0.002681 | 0.158654| 0.019227 | 7.0 | 2010-12 | 0.002681| 0.158654 | 0.019227 | 7.0 | 05.Very Weak
1 | 536365 | 71053 | WHITE METAL LANTERN | 6 | 12/1/2010 8:26 | 3.39 | 17850.0 | United Kingdom | 2010-12-01 00:00:00 | 20.34 | 0.002681 | 0.158654| 0.019227 | 7.0 | 2010-12 | 0.002681| 0.158654 | 0.019227 | 7.0 | 05.Very Weak
2 | 536365 | 84406B | CREAM CUPID HEARTS COAT HANGER | 8 | 12/1/2010 8:26 | 2.75 | 17850.0 | United Kingdom | 2010-12-01 00:00:00 | 22.00 | 0.002681 | 0.158654| 0.019227 | 7.0 | 2010-12 | 0.002681| 0.158654 | 0.019227 | 7.0 | 05.Very Weak
3 | 536365 | 84029G | KNITTED UNION FLAG HOT WATER BOTTLE | 6 | 12/1/2010 8:26 | 3.39 | 17850.0 | United Kingdom | 2010-12-01 00:00:00 | 20.34 | 0.002681 | 0.158654| 0.019227 | 7.0 | 2010-12 | 0.002681| 0.158654 | 0.019227 | 7.0 | 05.Very Weak
4 | 536365 | 84029E | RED WOOLLY HOTTIE WHITE HEART. | 6 | 12/1/2010 8:26 | 3.39 | 17850.0 | United Kingdom | 2010-12-01 00:00:00 | 20.34 | 0.002681 | 0.158654| 0.019227 | 7.0 | 2010-12 | 0.002681| 0.158654 | 0.019227 | 7.0 | 05.Very Weak
``` ​:citation[oaicite:0]{index=0}​(1) 월 별 고객 현황 및 이용 건수
월별 고객 현황 및 이용 건수를 통해 특정 기간 동안 고객 활동의 증가 또는 감소를 확인할 수 있다. 이는 이용자 수의 비수기와 성수기를 파악하고거나 시즌별 트렌드를 파악하고, 마케팅 전략을 조정하는 데 유용하며 비수기에는 프로모션을 통해 이용을 증가시키는 전략을 마련할 수 있게 만들어주며 의사결정에 도움을 줄 수 있다. 이를 MAU라고도 한다.
월 별 고객 현황
# ▶ MAU 월별 고객 현황
df_cus = df.groupby('Date_1',as_index=False)['CustomerID'].nunique()
plt.plot(df_cus['Date_1'], df_cus['CustomerID'], label='Customer');
plt.legend();
plt.gcf().set_size_inches(25, 5)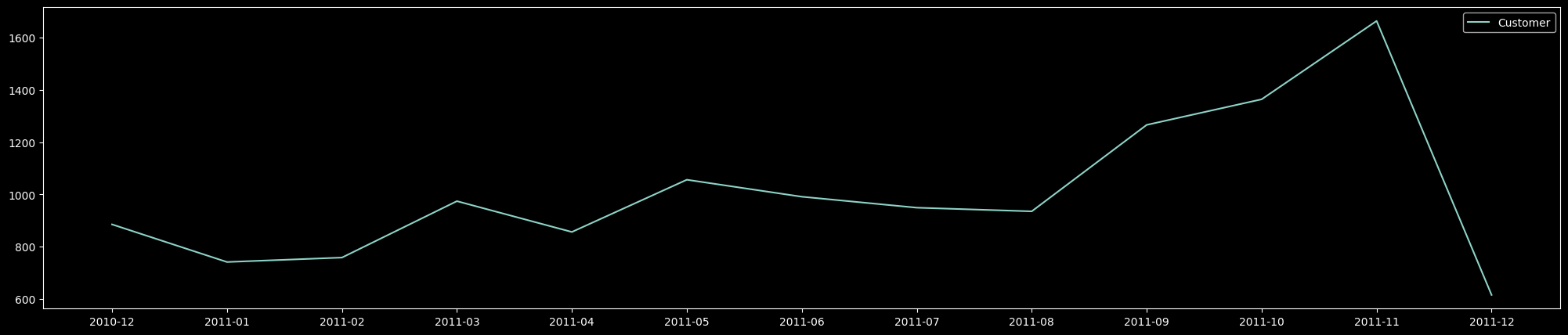
- MAU 확인 결과 2010.12 런칭이후 사용자 수가 증가하고 2011.11월 Peak를 달성했으나, 12월에 갑자기 하락한 모습을 보였다.
- 하지만 12월은 9일까지 데이터가 수집 됐기에 데이터가 부족한 현상으로 급하락한 것으로 보이며, 서비스 이용고객수는 나쁘지 않다.
월별 이용 건수
# ▶ 월별 이용 건수, 송장번호 한 개당 한 개의 이용 건수라고 생각하면 된다.
df_cnt = df.groupby('Date_1',as_index=False)['InvoiceNo'].nunique()
df_cnt.head(5)
plt.plot(df_cnt['Date_1'], df_cnt['InvoiceNo'], label='Customer_cnt');
plt.legend();
plt.gcf().set_size_inches(25, 5)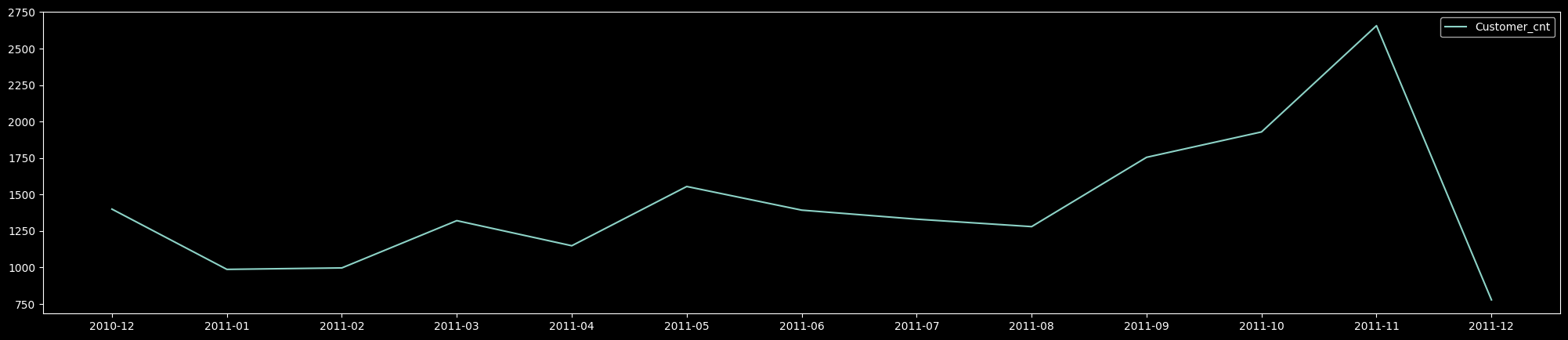
- 송장번호 한 개당 한 개의 이용 건수라고 생각하여 이를 월별 이용 건수로 가정하였다.
- MAU 월별 이용 고객수와 비슷한 양상을 보이며 마찬가지로 12월은 9일까지 데이터가 수집 됐기에 데이터가 부족한 현상으로 급하락 하였다. 서비스 이용 건수도 계속해서 성장하는 모습을 보인다.
(2)월 별 이용 국가
월별 이용 지역 및 국가 지표를 통해서는 어떤 지역 또는 국가에서 서비스가 많이 이용되는지를 파악하여, 시장을 세분화하여 주요 시장을 식별할 수 있다. 이는 각 국가의 고객 특성에 맞춘 맞춤형 마케팅 전략을 세우는 데 도움을 준다. 특정 지역에서의 이용률이 높다면, 해당 국가에 대한 추가적인 마케팅 및 서비스 확장 등의 의사결정에 도움을 줄 수 있다.
# 총 이용 국가는 37개국
df['Country'].nunique()
> 37
# ▶ 월별 이용 국가 데이터 프레임 생성
df_country = df.groupby('Date_1',as_index=False)['Country'].nunique()
plt.plot(df_country['Date_1'], df_country['Country'], label='Country');
plt.legend();
plt.gcf().set_size_inches(25, 3)
-
A회사의 서비스를 이용하는 국가는 총 37개국으로 이용국가 수는 1월을 시작으로 감소했다가 5월, 9월, 11월에 감소하거나 나머지 달에는 다시 상승하는 모습을 보여주고 있다.
-
이후 어느 지역의 국가가 특히 감소하는지 확인할 필요가 있어 보인다.
충성도가 높은 나라 와 충성도가 작은 나라
# 가장 충성도가 높은 이용 나라, 국가별 충성고객을 이용 건수 개수를 세서 순위를 매긴다.
pd.DataFrame(df.groupby(['Country'])['InvoiceNo'].nunique().sort_values(ascending=False)).head(10)
InvoiceNo
Country
United Kingdom 16646
Germany 457
France 389
EIRE 260
Belgium 98
Netherlands 94
Spain 90
Australia 57
Portugal 57
Switzerland 51
# 가장 충성도가 낮은 이용 나라, 국가별 충성고객을 이용 건수 개수를 세서 순위를 매긴다.
pd.DataFrame(df.groupby(['Country'])['InvoiceNo'].nunique().sort_values(ascending=True)).head(10)
InvoiceNo
Country
Brazil 1
RSA 1
Lebanon 1
Saudi Arabia 2
United Arab Emirates 3
Bahrain 4
Lithuania 4
Czech Republic 5
European Community 5
Canada 6- 영국의 이커머스 회사이다 보니 주로 유럽 국가들의 이용 고객 수가 많은 것으로 보이며 충성도가 낮은 국가들은 유럽 국가가 아닌 남미, 중동 국가 들로 주로 이루어져 있으며 자연스러운 현상으로 보인다.
(3) 월 별 Grade 이용률 비중
월별 고객 이용률을 통해서는 예를 들어 RFM 분석에서 Grade(등급)별 이용 비중을 통해, 고객의 만족도 및 충성도를 평가할 수 있다. 높은 등급(Strong, Very Strong)의 비중이 높다면, 이는 서비스에 만족하는 고객이 많다는 의미이다. 이때는 현재 잘하고 있는 것이 무엇인지 찾아 그것을 더 고도화시키는 전략이 필요할 것이다. 반대로 낮은 등급(Weak, Very Weak) 고객의 비중이 높다면, 서비스의 문제점을 식별하고 개선할 필요가 있다. 이를 통해 전반적인 고객 경험을 향상시킬 수 있도록 전략을 마련할 수 있게 도와줄 수 있겠다.
df_grade = df.groupby(['Date_1', 'Grade'],as_index=False)['CustomerID'].nunique()
df_grade.head(5)
Date_1 Grade CustomerID
0 2010-12 01.Very Strong 11
1 2010-12 02.Strong 397
2 2010-12 03.Normal 291
3 2010-12 04.Weak 42
4 2010-12 05.Very Weak 144
# 데이터프레임에서 피벗 테이블을 생성
df_pivot = pd.pivot_table(df_grade, # 피벗할 데이터프레임을 지정
index='Date_1', # 행 위치에 들어갈 열을 'Date_1'로 설정
columns='Grade', # 열 위치에 들어갈 열을 'Grade'로 설정
values='CustomerID') # 데이터로 사용할 열을 'CustomerID'로 설정
# NaN 값을 0으로 채움
df_pivot.fillna(0, inplace=True) # 피벗 테이블의 NaN 값을 0으로 대체
# 새로운 열 'total'을 생성하여 각 등급의 월 별 고객 수 총합을 계산
df_pivot['total'] = df_pivot['01.Very Strong'] + df_pivot['02.Strong'] + df_pivot['03.Normal'] + df_pivot['04.Weak'] + df_pivot['05.Very Weak']
# 각 등급의 고객 수의 값을 'total' 값으로 나누어 비율을 계산
df_pivot.iloc[:, 0] = (df_pivot.iloc[:, 0] / df_pivot['total']) # '01.Very Strong'의 비율 계산
df_pivot.iloc[:, 1] = (df_pivot.iloc[:, 1] / df_pivot['total']) # '02.Strong'의 비율 계산
df_pivot.iloc[:, 2] = (df_pivot.iloc[:, 2] / df_pivot['total']) # '03.Normal'의 비율 계산
df_pivot.iloc[:, 3] = (df_pivot.iloc[:, 3] / df_pivot['total']) # '04.Weak'의 비율 계산
df_pivot.iloc[:, 4] = (df_pivot.iloc[:, 4] / df_pivot['total']) # '05.Very Weak'의 비율 계산
# 'total' 열을 삭제
df_pivot.drop(['total'], axis=1, inplace=True) # 'total' 열을 데이터프레임에서 삭제
# 최종 피벗 테이블 출력
df_pivot
Grade 01.Very Strong 02.Strong 03.Normal 04.Weak 05.Very Weak
Date_1
2010-12 0.012429 0.448588 0.328814 0.047458 0.162712
2011-01 0.014845 0.450742 0.349528 0.045884 0.139001
2011-02 0.014512 0.419525 0.377309 0.056728 0.131926
2011-03 0.012320 0.401437 0.388090 0.198152 0.000000
2011-04 0.014019 0.420561 0.394860 0.170561 0.000000
2011-05 0.012311 0.425189 0.428977 0.133523 0.000000
- 월 별 이용 비율 계산을 위해서 각 등급별로 등급에 해당하는 고객(customer id)의 수를 계산하고 이를 바탕으로
pivot테이블을 생성했다. - 생성한
pivot테이블 내의 각 등급의 월 별 고객 수 총합을 계산하고 이를 다시 각 행의 월 별 고객 수로 나누어 각 등급의 월 별 고객 수의 비율을 계산하였다.
import warnings
warnings.filterwarnings('ignore')
plt.style.use(['dark_background'])
# 데이터프레임 df_pivot을 수평 막대 그래프(horizontally stacked bar chart)로 시각화
ax = df_pivot.plot(kind='barh', stacked=True, title="years amt", rot=0)
# kind='barh': 수평 막대 그래프를 의미
# stacked=True: 막대들을 쌓아서 누적형으로 표현
# title: 그래프의 제목 설정
# rot=0: x축 라벨의 회전 각도 설정 (0도)
# 각 막대의 패치를 순회하며 값(너비)을 그래프에 표시
for p in ax.patches:
left, bottom, width, height = p.get_bbox().bounds
# left: 경계 상자의 왼쪽(x 좌표). 패치의 시작 지점의 x 좌표를 의미한다. 만약 left+width/3 을 설정한다면 수치를 나타내는 숫자를 왼쪽 x 좌표로부터 3만큼 늘어난다.
# bottom: 경계 상자의 아래쪽(y 좌표). 패치의 시작 지점의 y 좌표를 의미한다. 만약 bottom+height/3 을 설정한다면 수치를 나타내는 숫자를 아래쪽 y 좌표로부터 아래로 3만큼 위치가 내려가게 된다.
# width: 경계 상자의 너비. 패치의 가로 길이를 의미한다.
# height: 경계 상자의 높이. 패치의 세로 길이를 의미한다.
ax.annotate("%.1f"%(width*100), xy=(left+width/2, bottom+height/2), ha='center', va='center', color='black')
# annotate: 텍스트를 그래프 상에 표시
# "%.1f"%(width*100): 막대의 너비를 백분율로 변환하여 소수점 한 자리까지 표시
# xy: 텍스트를 표시할 좌표 (막대의 중앙)
# ha='center', va='center': 텍스트 정렬을 중앙으로 설정
# color='black': 텍스트 색상을 검은색으로 설정
# 그래프의 가독성을 위해 테두리 제거
plt.box(False)
# 그래프의 크기를 설정 (가로 25인치, 세로 15인치)
plt.gcf().set_size_inches(25, 15)
# 그래프를 화면에 출력
plt.show()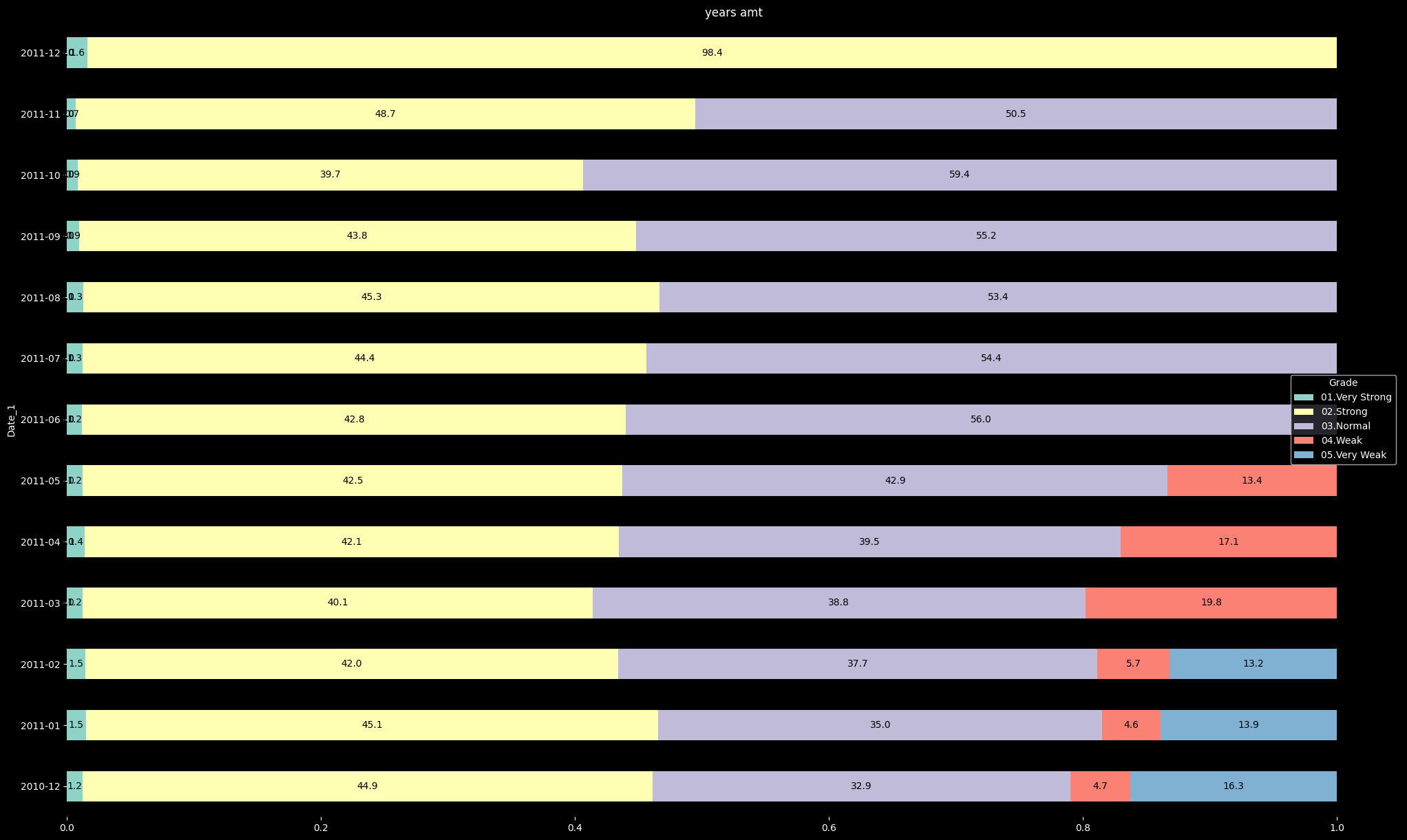
- 월 별 Grade 이용률 비중 확인 결과 2011년 12월달을 기준으로 very weak 등급 고객이 점점 줄어들다 3월달 부터 weak고객이 증가한 것을 알 수 있었다.
- 그리고 2011년 6월달을 기점으로 weak 고객들도 normal 등급의 고객으로 상향 돼 normal 등급의 고객이 증가했지만 strong과 very strong 고객의 비중은 12월달에 비해서 크게 변화가 없거나
오히려 하락하는 달도 있었다.
결론
-
월별 고객 현황, 서비스 이용건수는 지속적으로 상승하고 있다가 12월 12월에 갑자기 하락한 모습을 보였다. 하지만 12월은 9일까지 데이터가 수집 됐기에 데이터가 부족한 현상으로 급하락한 것으로 보이며 따라서 사용 고객수의 감소에는 문제가 없는 것으로 보인다.
-
하지만 A회사의 서비스 이용국가 수는 1월을 시작으로 감소했다가 5월, 9월, 11월에 감소하거나 나머지 달에는 다시 상승하는 모습을 보여주고 있다. 해당 달에 이용국가 수를 감소시킬만한 어떠한 이벤트가 있었는지 확인할 필요가 있다.
-
영국의 이커머스 회사이다 보니 주로 유럽 국가들의 이용 고객 수가 많은 것으로 보이며 충성도가 낮은 국가들은 유럽 국가가 아닌 남미, 중동 국가 들로 주로 이루어져 있으며 자연스러운 현상으로 보인다. 하지만 유럽 국가를 제외한 타 국가들의 서비스 이용자들을 확보함으로써 사용 고객수를 어떻게 증가시킬 것인가에 대핵 고민해보아야 할 것이다.
-
그리고
very weak,weak고객 등급의 수는 줄어normal등급의 고객 수가 늘어났지만 앞으로는normal고객들을 실질적인 영업이익을 늘려줄 수 있는strong과very strong고객으로 어떻게 상향시켜 이용률을 높일 건지 고민해보아야 할 거 같다.
