
JPA에서의 N + 1 문제란
N + 1 문제는 JPA와 같은 ORM(Object-Relational Mapping)에서 자주 발생하는 성능 문제로, 주로 데이터베이스에서 여러 개의 연관된 엔티티를 조회할 때 발생한다.
특정 엔티티와 연관 관계가 설정된 다른 엔티티를 조회할 경우에 조회된 데이터 갯수(n) 만큼 연관관계의 조회 쿼리가 추가로 n개 발생하여 1개의 조회 메서드를 실행하였지만 실제로는 최악의 경우 n + 1개의 조회 쿼리가 발생할 수 있으면 만약 막대한 양의 데이터가 존재한다면 이러한 N + 1 문제는 프로그램에 심각한 성능 저하를 유발할 수 있다.

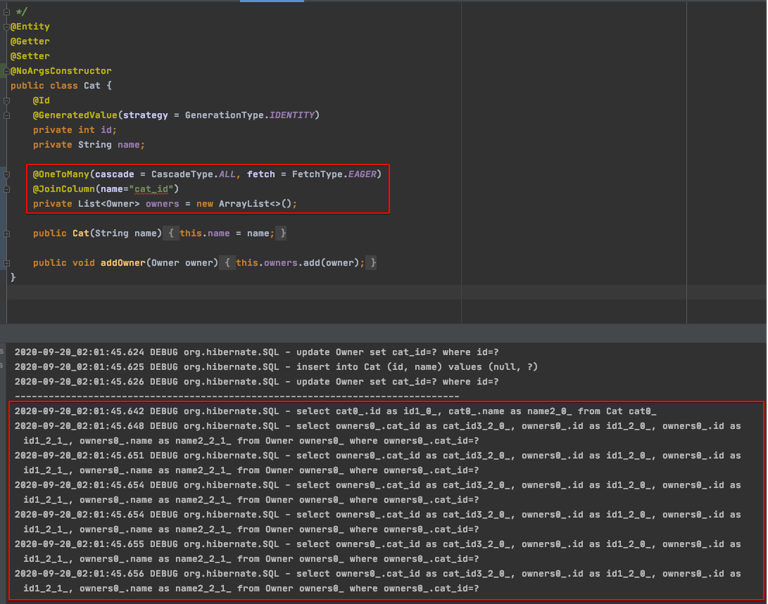
(이미지 출처 : https://incheol-jung.gitbook.io/docs/q-and-a/spring/n+1)
예시를 통해 살펴보자.
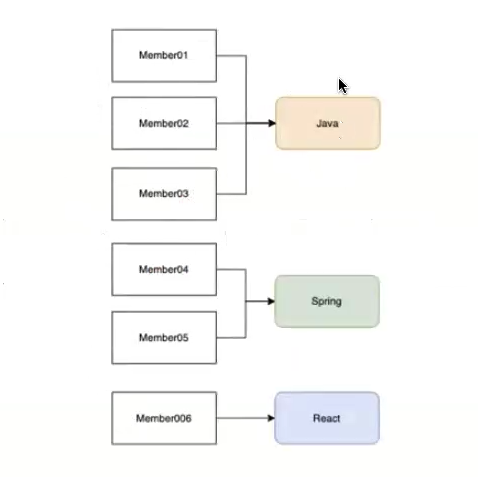
예를 들어 수업 목록을 조회하는 서비스 메서드를 작성한다고 가정해보자.
현재 DB에는 Java, Spring, React 3개의 수업이 저장되어 있고 각각의 수강생은 위의 이미지와 같은 상황이다.
[수업 목록 조회 코드]
// 조회: 수업 엔티티 목록 조회
log.info("::: 수업 목록 조회 :::");
List<Course> foundCourseList = courseRepository.findAll();
// DTO 변환: 수업 엔티티 -> CourseDto
log.info("::: DTO 변환 - Course -> CourseDto :::");
List<CourseDto> courseDtoList = foundCourseList.stream().map(course -> new CourseDto(
course.getId(),
course.getName(),
course.getMembers().size()
)).toList();
위와 같이 수업 목록을 조회하는 서비스의 코드를 실행하면 총 몇 번의 쿼리가 발생할까???
정답은 바로 4번이다.
courseRepository.findAll();
우선 첫번째로 findAll() 메서드로 전체 수업의 목록을 가져오는 select ~ from course 조회 쿼리가 1개 발생하고
course.getMembers().size()getMembers().size()로 각 수업에서 수강생들을 숫자를 세기 위해 select ~ from member ~ where course_id = ~ 쿼리를 수업(Course)의 수만큼 각각 발생시켜 쿼리가 총 3번 더 나간다.
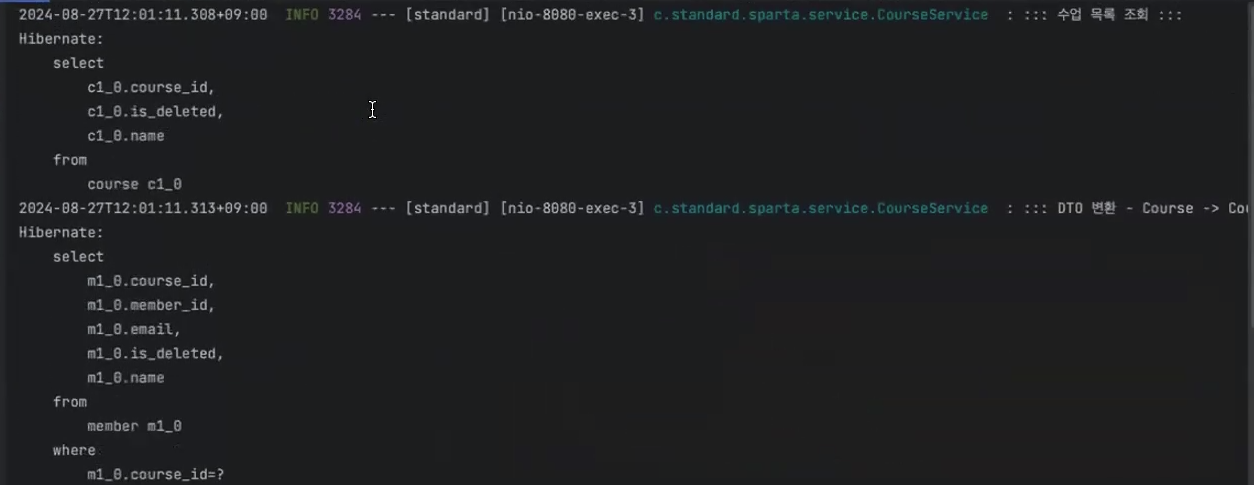
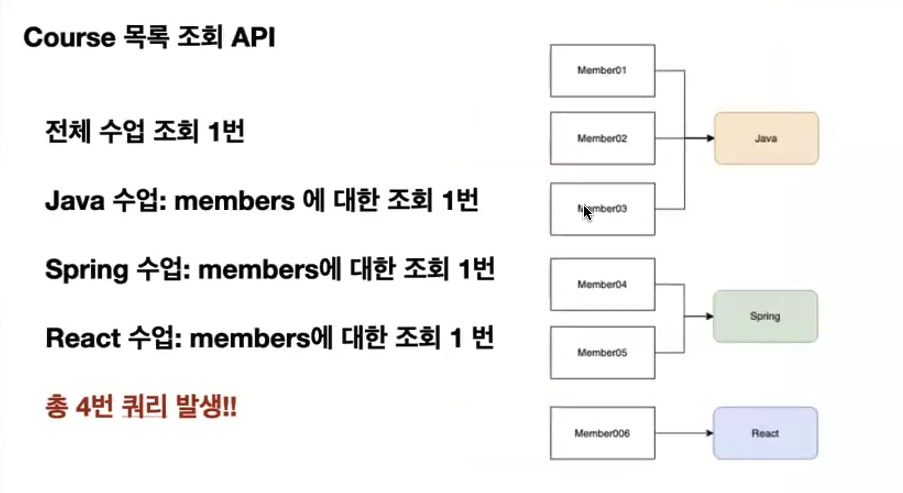
여기까지는 누구나 쉽게 예측할 수 있었을 것이다.
그렇다면 위의 데이터 예시 이미지를 다시 상기하면서 이번에는 회원 목록을 조회하는 서비스를 개발한다고 생각해보자.
[회원 목록 조회 서비스]
// 조회: 회원 엔티티 목록 조회
log.info("::: 멤버 목록 조회 :::");
List<Member> foundMemberList = memberRepository.findAll();
log.info("::: 멤버 DTO 변환 :::");
// DTO 변환: 회원 엔티티 목록 -> List<MemberDto> memberListDto
List<MemberDto> memberDtoList = foundMemberList.stream().map(member -> new MemberDto(
member.getId(),
member.getName(),
member.getCourse().getName()
)).toList();
그렇다면 해당 회원 목록 조회 서비스는 모두 총 몇 번의 조회 쿼리를 만들어낼 것인가???
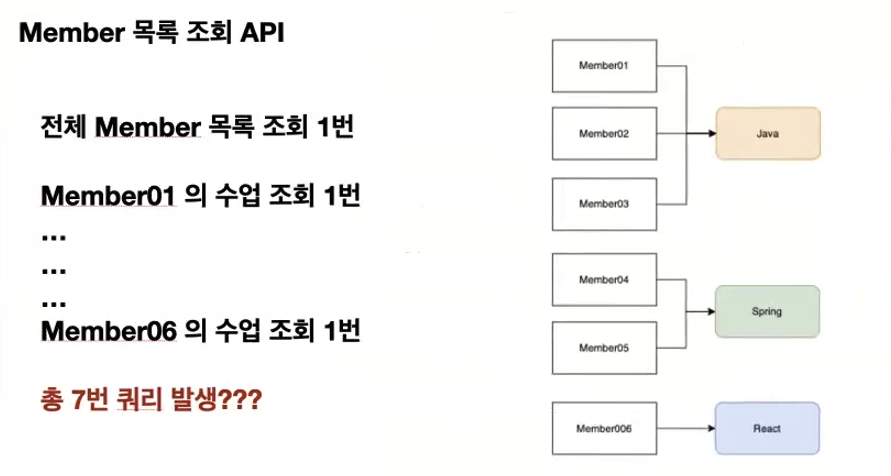
앞에서 수업의 개수만큼 탐색했던 것을 떠올리면 자연스럽게 7번의 쿼리가 나갈 것이라고 생각하기 쉽지만 조회 쿼리는 실제로는 모두 4번 나간다.
memberRepository.findAll();finaAll()로 멤버 전체를 조회하는 메서드로 조회 쿼리가 1개 발생하고
member.getCourse().getName()이후에 member.getCourse()로 해당 멤버의 수업(Course)을 조회하는 데에 만약에 현재 아직 한 번도 나오지 않은 수업이라면 DB에서 직접 꺼내와야 하기 때문에 조회 쿼리가 한 번씩 더 발생된다.
그렇다면 이미 있던 수업이라면, 쉽게 말해 Java를 듣는 Member01의 수업을 조회하고 직후 마찬가지로 Java를 듣는 Member02의 수업을 조회하려고 할 때에는 왜 조회 쿼리가 발생하지 않는 것일까???
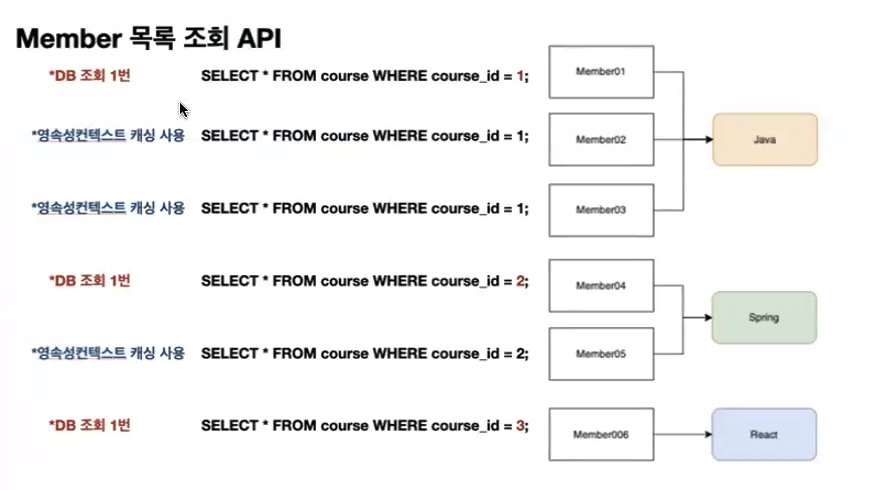
정답은 바로 영속성 컨텍스트의 캐싱 기능 덕분이다.
해당 트랜잭션을 수행해주는 엔티티 매니저(Entity Manager) 내부에는 1차 캐시라고 영속 상태의 엔티티 객체들을 저장하는 메모리가 존재한다.
엔티티 매니저를 통해 persist()로 엔티티 객체를 영속 상태로 저장하거나 find()로 아직 1차 캐시에 존재하지 않는 객체를 DB에서 꺼내오면 트랜잭션이 종료되어 엔티티 매니저가 사라질 때까지 엔티티 매니저 내부의 1차 캐시에 해당 객체들을 저장하고 이후 find()가 사용될 때마다 DB를 확인하기 전에 우선 1차 캐시를 확인하고 해당 객체가 저장되어 있으면 DB를 확인하지 않고 해당 객체를 꺼내어 오는 방식을 사용한다.
따라서 해당 경우는 member.getCourse()로 각 수업을 처음 조회할 때마다 엔티티 매니저가 내부의 1차 캐시를 확인하여 없다는 것을 확인한 후 쿼리문을 발생시켜 DB에서 데이터를 가져온 후 1차 캐시에 저장하고 이후 같은 수업을 꺼낼 때에는 1차 캐시에서 데이터를 가져오기 때문에 조회 쿼리가 7번이 아니라 4번 발생하는 원리이다.

N + 1 문제 발생 원인
Eager Loading(즉시 로딩)일 때의 N + 1 발생 원인
즉시 로딩(Eager Loading)은 연관된 엔티티를 기본적으로 즉시 함께 조회하지만, 이 전략은 다음과 같은 경우 N + 1 문제를 유발할 수 있다.
1. 연관된 엔티티의 조회 방식: 즉시 로딩을 사용하면, JPA는 기본적으로 연관된 엔티티들을 LEFT JOIN이나 OUTER JOIN을 사용하여 한 번에 가져오려고 시도하는데, 이런 JOIN 전략은 복잡한 연관 관계가 많아질수록 더 많은 조인과 데이터 중복을 유발할 수 있다.
예를 들어, 한 엔티티가 여러 연관 엔티티와 연결된 경우, 각각에 대해 불필요한 추가 쿼리가 발생할 수 있다.
2. 컬렉션 연관 관계에서의 문제: 즉시 로딩은 @OneToMany 또는 @ManyToMany와 같은 컬렉션 관계에서 특히 위험하다. 연관된 데이터를 즉시 로딩할 때 각 엔티티마다 추가 쿼리가 발생하여 N + 1 문제를 초래할 수 있다.
예를 들어, Team과 Member가 즉시 로딩 관계로 설정되어 있다면, 여러 개의 Team을 조회할 때 각각의 팀에 대한 멤버 데이터를 조회하기 위해 여러 추가 쿼리가 실행되는 N + 1 문제가 발생할 수 있다.
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(fetch = FetchType.EAGER)
private List<Member> members;
}
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String userName;
@ManyToOne(fetch = FetchType.EAGER)
private Team team;
}
위와 같은 설정에서 Team 엔티티를 조회할 때, 각 팀에 속한 멤버도 즉시 로딩되므로, 만약 Team 엔티티가 여러 개 조회되면 각각에 대해 추가적인 쿼리가 발생하게 된다.
List<Team> teams = em.createQuery("select t from Team t", Team.class).getResultList();
이 코드에서 팀 리스트를 가져오면, 각 팀마다 멤버를 조회하기 위한 추가 쿼리(N번)가 발생할 수 있다.
참고로 모두 알고 있겠지만 Eager Loading은 필요없는 경우에도 연관된 모든 엔티티를 끌고 오는 방식이기 때문에 성능 악화 측면에서 N + 1 문제하고는 비교할 수도 없이 더 큰 문제이기 때문에 사용을 기본적으로 배제하자.
Lazy Loading(지연 로딩)일 때의 N + 1 발생 원인
지연 로딩(Lazy Loading)에서 N + 1 문제가 발생하는 원인은 지연 로딩으로 설정하면 엔티티를 가져올 때 연관된 엔티티를 처음에는 로딩하지 않고 대신 null이나 다름없는 해당 엔티티를 상속받아 id값만 들고 있는 가짜 객체인 프록시 객체를 대신 가져오고, 실제 엔티티를 사용할 때마다 별도의 쿼리를 통해 DB에서 가져오는 방식을 사용하기 때문이다.

프록시 객체는 실제 객체의 참조를 보관하며 프록시 객체를 호출하면 해당 참조값을 통해 실제 객체의 메서드를 호출한다.
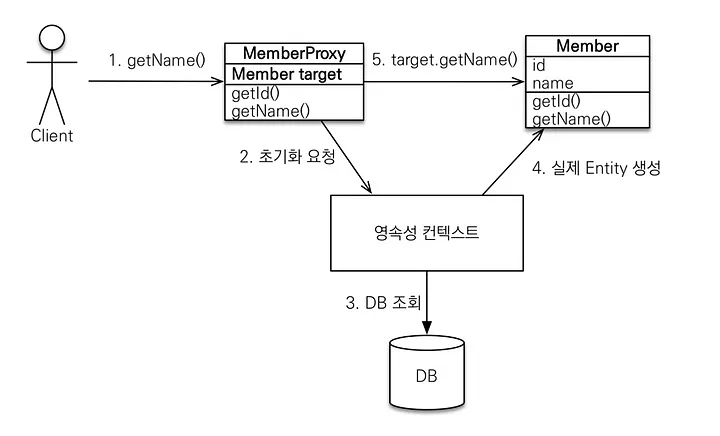
해당 예시에서 Member 프록시 객체의 target 값은 null인데 사용해야 될 경우에는 JPA가 영속성 컨텍스트에 진짜 객체를 가져오라 명령하여 DB에서 정보를 조회하여 실제 객체가 생성된다.
이후 기존 프록시 객체와 진짜 객체가 연결되어 프록시 객체의 getName() 메서드를 호출하면 진짜 객체의 getName()이 호출되는 방식이다.
이런 방식으로 최악의 경우에 연관 엔티티의 필드 값을 get() 메서드로 얻어오기 위해 매번 DB에 직접 select 쿼리 문을 날려야 할 수도 있기 때문에 추가로 N번의 쿼리가 발생하여 지연 로딩에서 N + 1 문제가 발생한다.
N + 1 문제 해결법
1. Fecth Join(페치 조인)
페치 조인(Fetch Join)은 JPA에서 성능 최적화를 위해 사용하는 기법으로, N+1 문제를 해결하기 위해 연관된 엔티티들을 한 번의 쿼리로 미리 로딩하는 방식이다.
기존에 미리 Spring Data JPA에 정의되어 있는 findAll() 대신 Fetch Join을 적용한 새로운 메서드를 만들어 적용해보자.
[JPQL로 Fetch Join 적용 예시]
public interface CourseRepository extends JpaRepository<Course, Long> {
@Query("SELECT c FROM Course c JOIN FETCH c.members")
List<Course> findAllWithFetchJoin();
}
JOIN 뒤에 FETCH 붙여주면 Fetch Join이 적용된다.
[Querydsl로 Fetch Join 적용 예시]
@Configuration
class QueryDslConfig {
@PersistenceContext
private EntityManager em;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(JPQLTemplates.DEFAULT, em);
}
}@Repository
public class CourseRepository {
public List<Course> findAllWithFetchJoin() {
QCourse course = QCourse.course;
QMember member = QMember.member;
return queryFactory
.selectFrom(course)
.leftJoin(course.members, member).fetchJoin()
.fetch();
}
}join(), leftJoin(), rightJoin() 등 join() 메서드 뒤에 적용하면 Fetch Join이 적용된다.
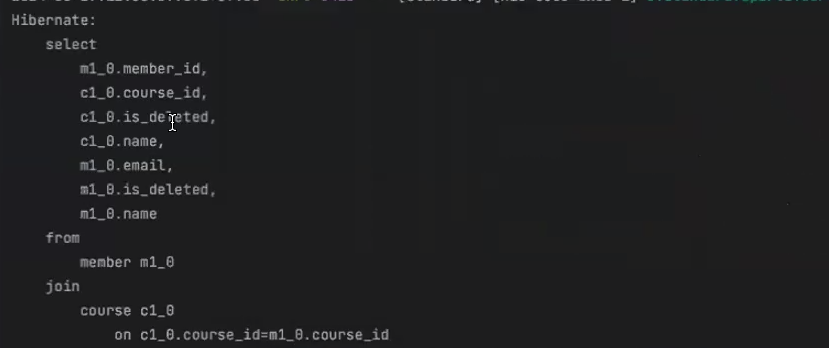
Fetch Join을 적용하면 마치 SQL에서 테이블간 Join을 한 것처럼 작동해서 한 번의 쿼리에 두 엔티티를 모두 가져오는 것을 확인할 수 있다.
현업에서는 Fetch Join을 주로 사용하고 대부분의 N + 1 문제는 Fetch Join만으로도 해결이 가능하다.
하지만 ToOne은 한 번에 몇 개든 Fetch Join 가능하지만 ToMany를 한 번에 여러 개 Fetch Join 하려고 하는 경우, 즉 두 개의 이상의 컬렉션을 페치 조인(Fetch Join)하려고 하는 경우에는 카테시안 곱이 발생하여 데이터의 개수가 매우 증가하고 데이터도 변형될 염려가 있어서 여러 개의 컬렉션을 Fetch Join하려고 하면 MultiBagException이 발생하게 설정되어 있기 때문에 Collection Fetch Join은 딱 1개만 가능하다.
또한 Fetch Join에서 페이징을 하면 limit, offset을 통한 쿼리가 아닌 인메모리에 모든 데이터를 가져와 application에서 페이징 처리하기 때문에 데이터가 좀만 많아져도 OutOfMemoryError가 발생하기 때문에
~ToMany(Collection Fetch Join)와 페이징을 같이 사용해서는 안 된다는 단점이 있다.
(※ 이전에는 DISTINCT를 쿼리 문에 넣어주지 않으면 데이터가 중복되었지만 Hibernate 6부터는 DISTINCT가 자동으로 기본값으로 적용되어 데이터가 중복되지 않는다.)
2. Batch Size
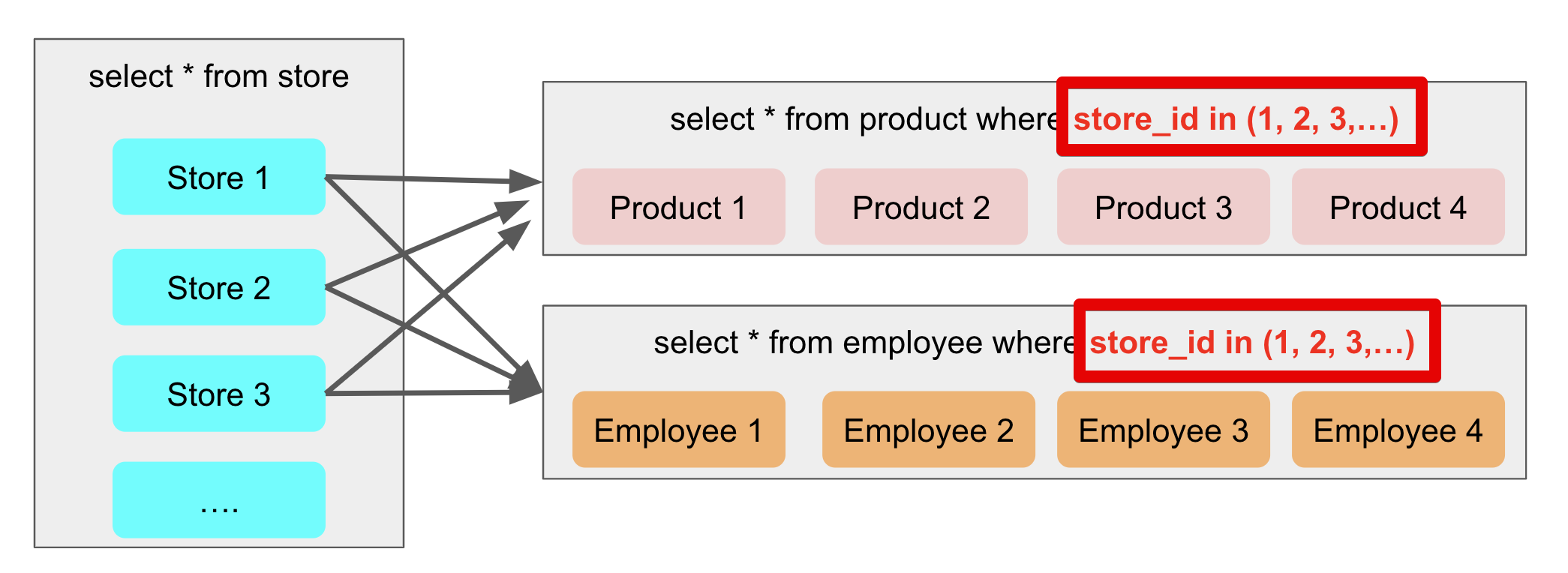
데이터베이스에서 한 번에 처리할 데이터의 개수를 나타내는 Batch Size를 설정함으로써 N + 1 문제와 다중 컬렉션 Fetch Join으로 인한 MultiBagException 문제를 해결할 수 있다.
연관 엔티티 조회를 조회할 때 엔티티 간의 관계에서, 예를 들어 부모 엔티티를 조회할 때 자식 엔티티도 함께 조회해야 하는 상황이 있다면 이 때 자식 엔티티들을 하나씩 개별 쿼리로 조회하는 대신, Batch Size를 설정함으로써 한 번의 쿼리로 설정한 개수만큼의 여러 자식 엔티티를 가져오는 방법이다.
[application.yml을 통한 글로벌 설정]
spring:
properties:
hibernate:
default_batch_fetch_size: 100
application.yml에 추가하면 프로젝트 전역에 Batch Size를 적용할 수 있다.
[@BatchSize를 통한 개별 설정]
@OneToMany(mappedBy = "parent")
@BatchSize(size = 10) // 연관된 엔티티를 10개씩 가져옴
private List<Child> children;개별 엔티티 또는 연관 관계에 대해서는 @BatchSize 애노테이션을 사용하면 Batch Size를 설정할 수 있다.
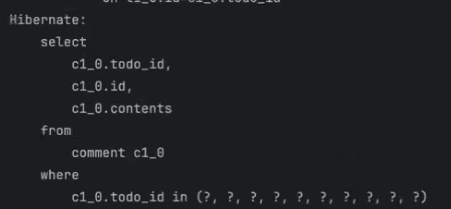
Batch Size를 설정하면 in 쿼리가 발생하면서 설정한 사이즈만큼 엔티티 개수를 가져온다.
(※ 스프링 부트 3.1 - Hibernate 6.2부터 Batch Size 설정하면 where ~ in ~ 쿼리가 아니라 성능 최적화를 위해 where array_contains(~)로 바뀌었지만 결과는 기존과 동일하다.)
