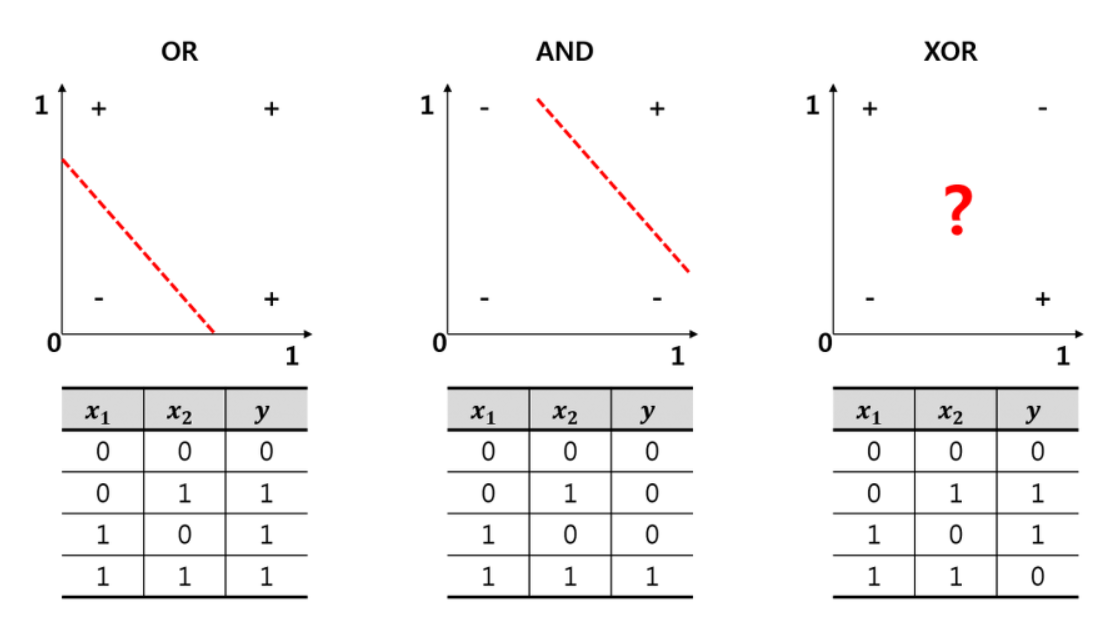
XOR을 해결하기 위해 하는 것이 딥러닝의 기초라고 생각하면 된다.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline텐서플로우를 활용하여 XOR 문제에 대해서 알아보도록 하자
x = np.array([
[0,0],
[1,0],
[0,1],
[1,1]
])
y = np.array([[0],[1],[1],[0]])model = tf.keras.Sequential([
tf.keras.layers.Dense(2,activation='sigmoid', input_shape=(2,)),
tf.keras.layers.Dense(1,activation='sigmoid')
])layers를 두번 사용해서 해결책을 찾도록 했다.
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.1),loss='mse')기존 lr을 사용했는데,,오류가 떴다. 대신에 learning_rate로 대체되었다고 파이썬에 명시된 것을 확인할 수 있었다.
hist = model.fit(x,y,epochs=5000,batch_size=1)총 5천개의 epochs를 학습시킨 것을 확인할 수 있다.
epochs는 지정된 횟수만큼 학습을 하는것
batch_size는 한번의 학습에 사용될 데이터의 수를 지정
model.predict(x)
plt.plot(hist.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.show()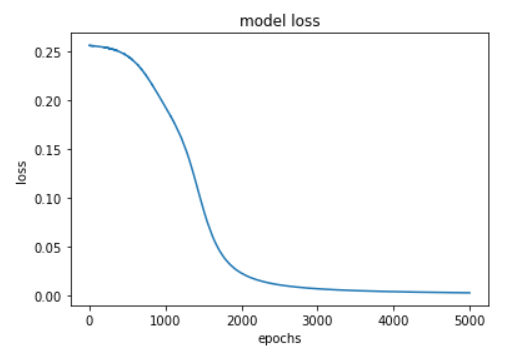
다음과 같은 loss 값을 얻었다.
학습에서 찾은 가중치
for w in model.weights:
print('---')
print(w)<tf.Variable 'dense/kernel:0' shape=(2, 2) dtype=float32, numpy=
array([[5.820788 , 3.8238754],
[5.8267474, 3.8252182]], dtype=float32)>
<tf.Variable 'dense/bias:0' shape=(2,) dtype=float32, numpy=array([-2.470183, -5.868636], dtype=float32)>
<tf.Variable 'dense_1/kernel:0' shape=(2, 1) dtype=float32, numpy=
array([[ 7.703268],
[-8.375878]], dtype=float32)>
<tf.Variable 'dense_1/bias:0' shape=(1,) dtype=float32, numpy=array([-3.4755566], dtype=float
분류
iris 데이터를 활용할 것이당.
우선 필요한 모듈을 import 해준다.
from sklearn.datasets import load_iris
iris = load_iris()
x = iris.data
y = iris.targetsklearn의 one hot encoding
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(sparse = False, handle_unknown='ignore')
enc.fit(y.reshape(len(y),1))enc.categories_를 확인해보면 [array([0, 1, 2])]를 확인할 수 있다.
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y_onehot, test_size=0.2,random_state=13)train과 test를 만들어서 학습시키고 결과를 확인해보자
우선!!!
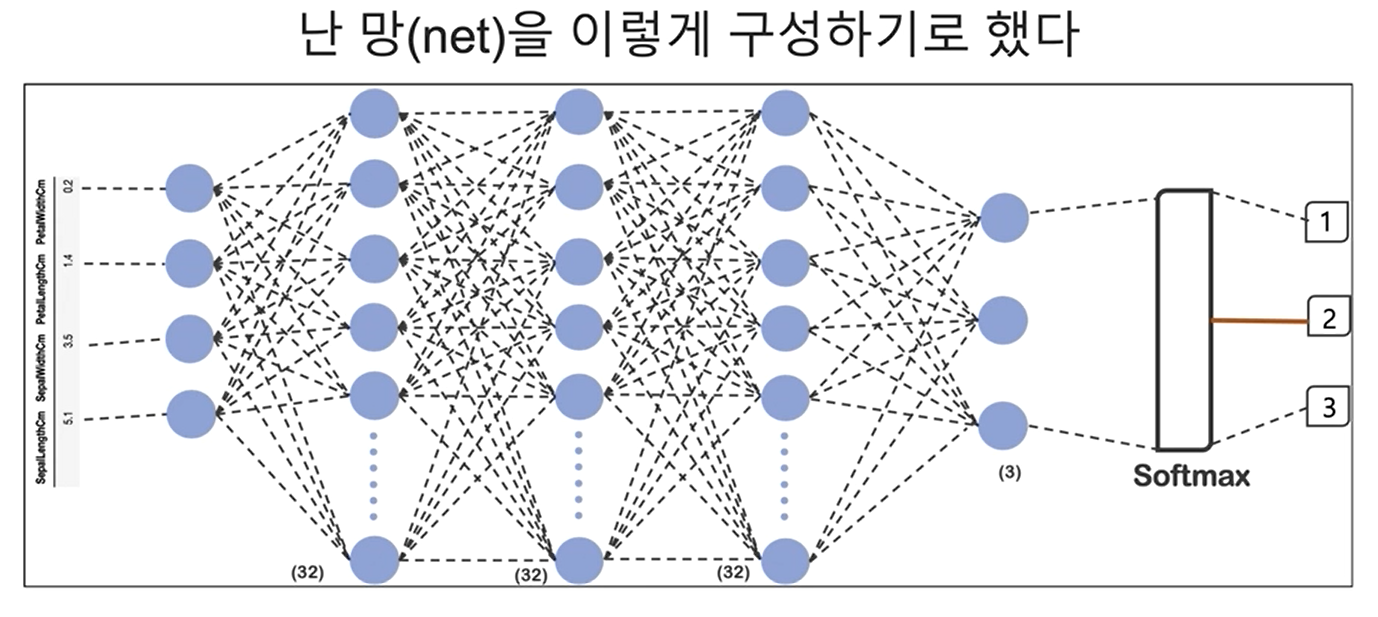
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(32, input_shape=(4,), activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])구성한대로 32,32,3의 layers로 계산했다.
위 코드에서 activation이란?
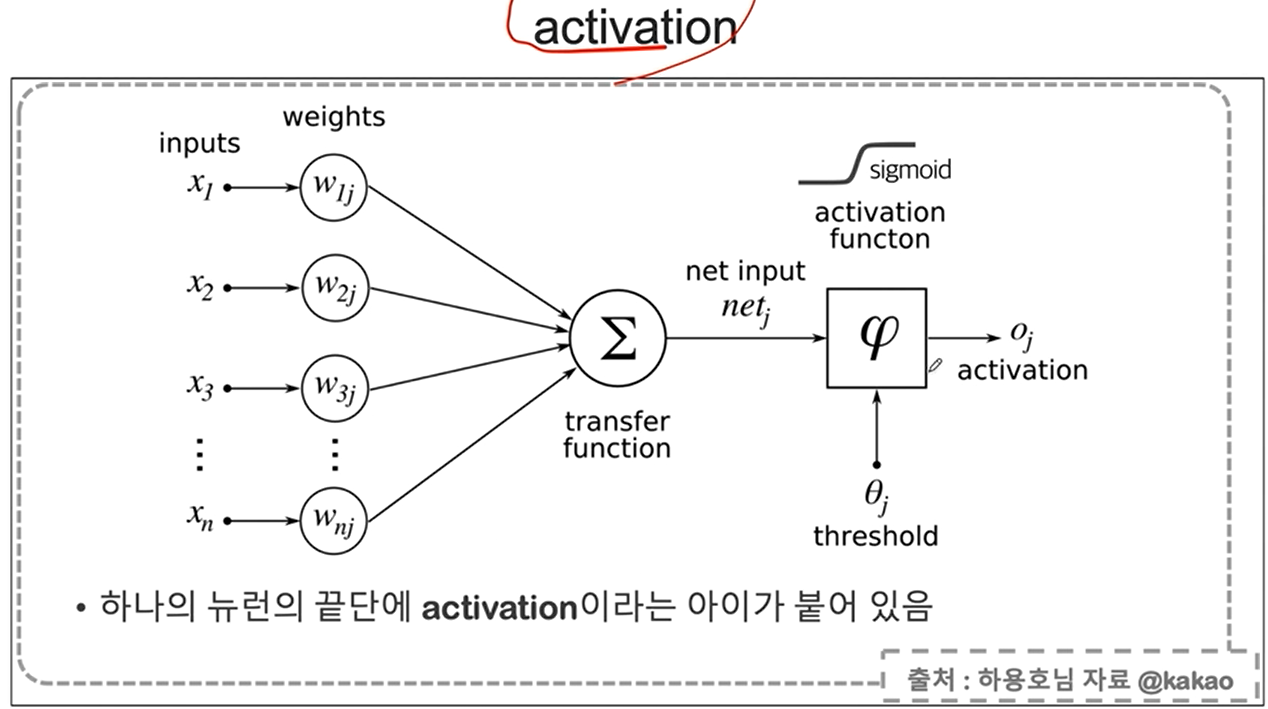
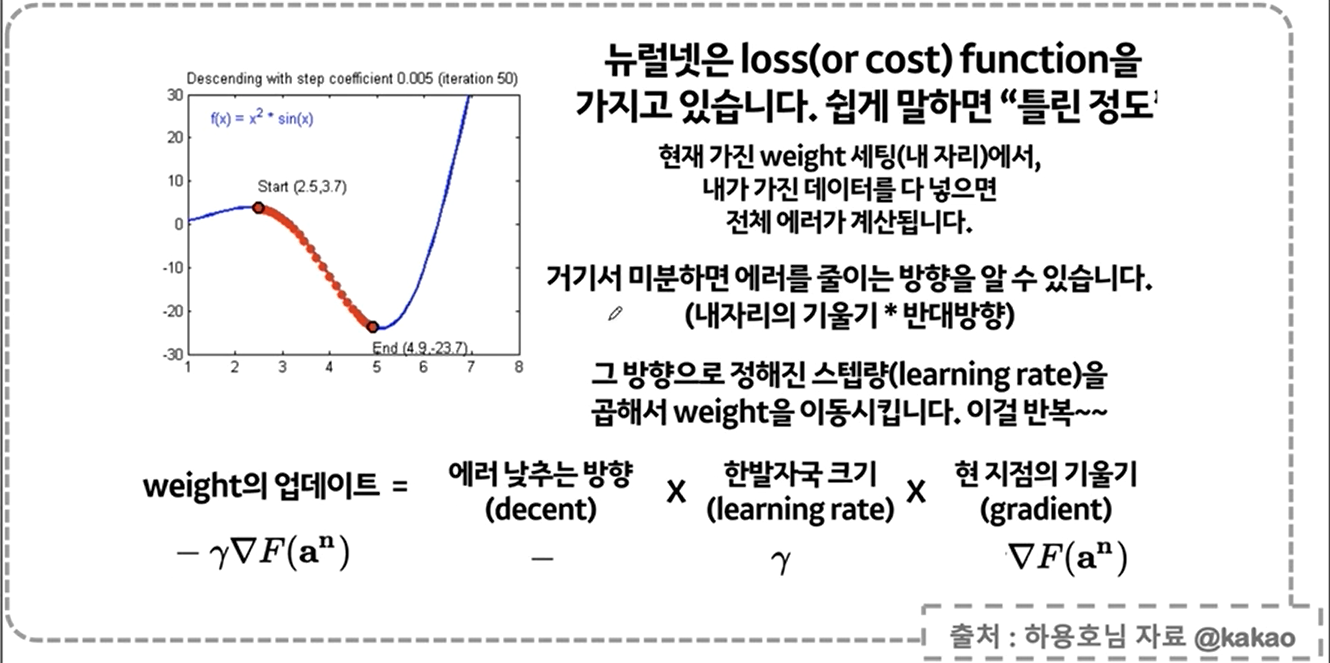
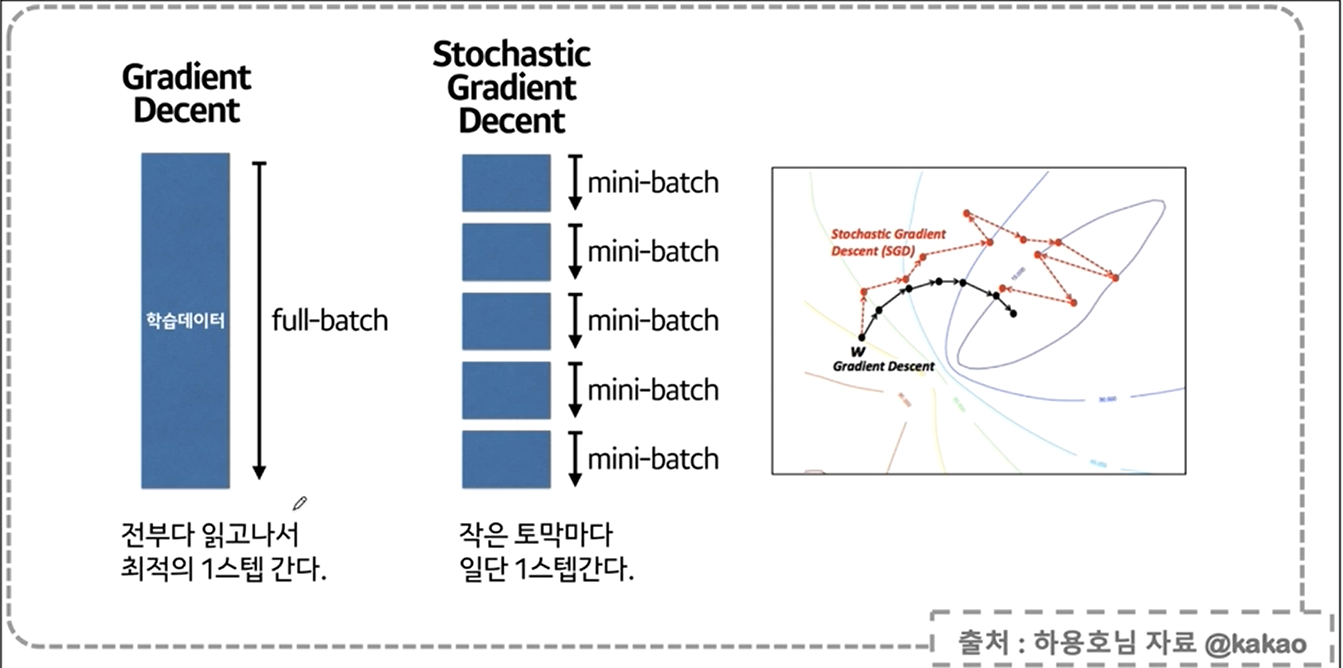
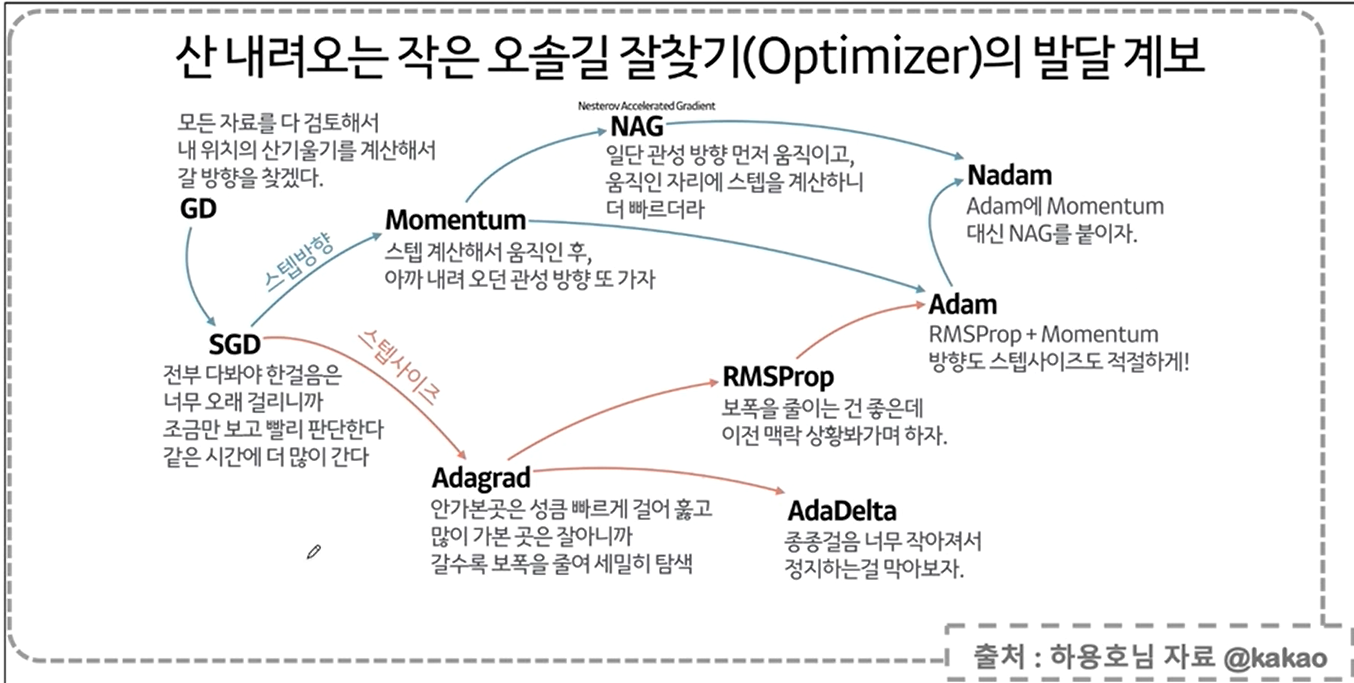
역전파에 대한 설명
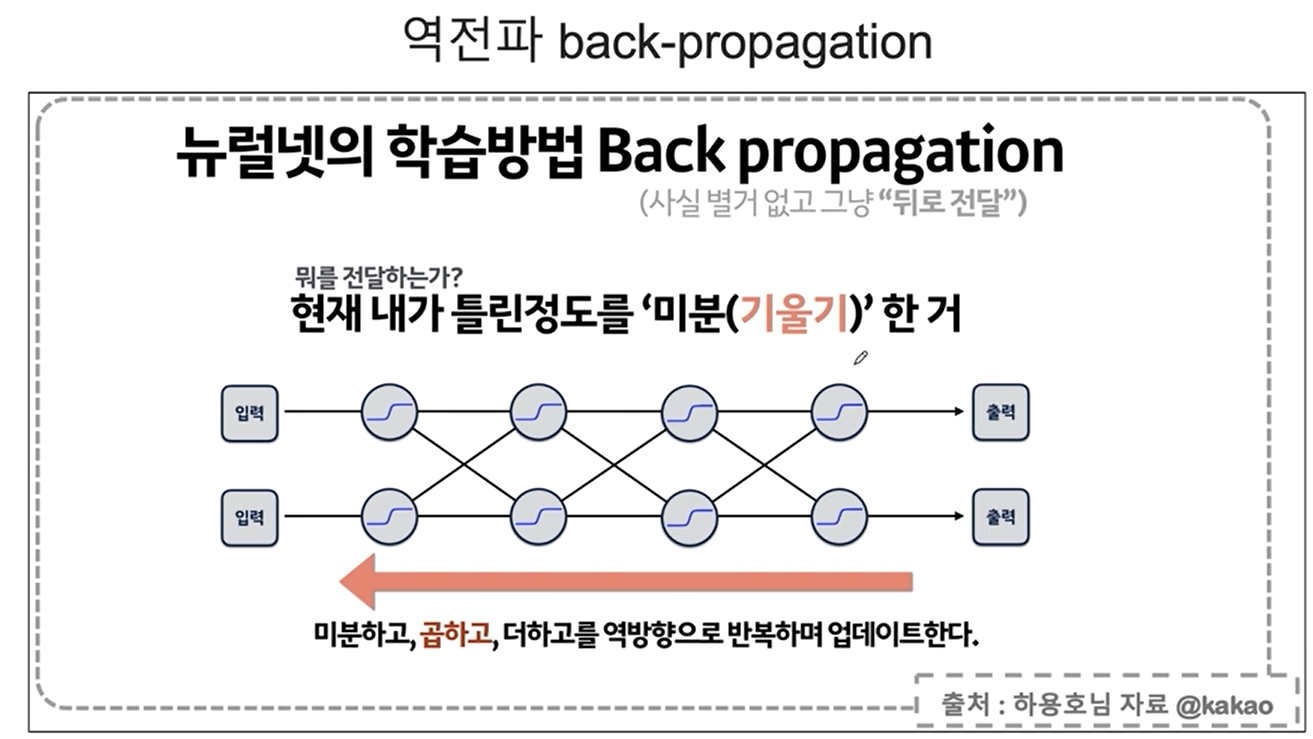
역전파 역시 문제점이 있다,,
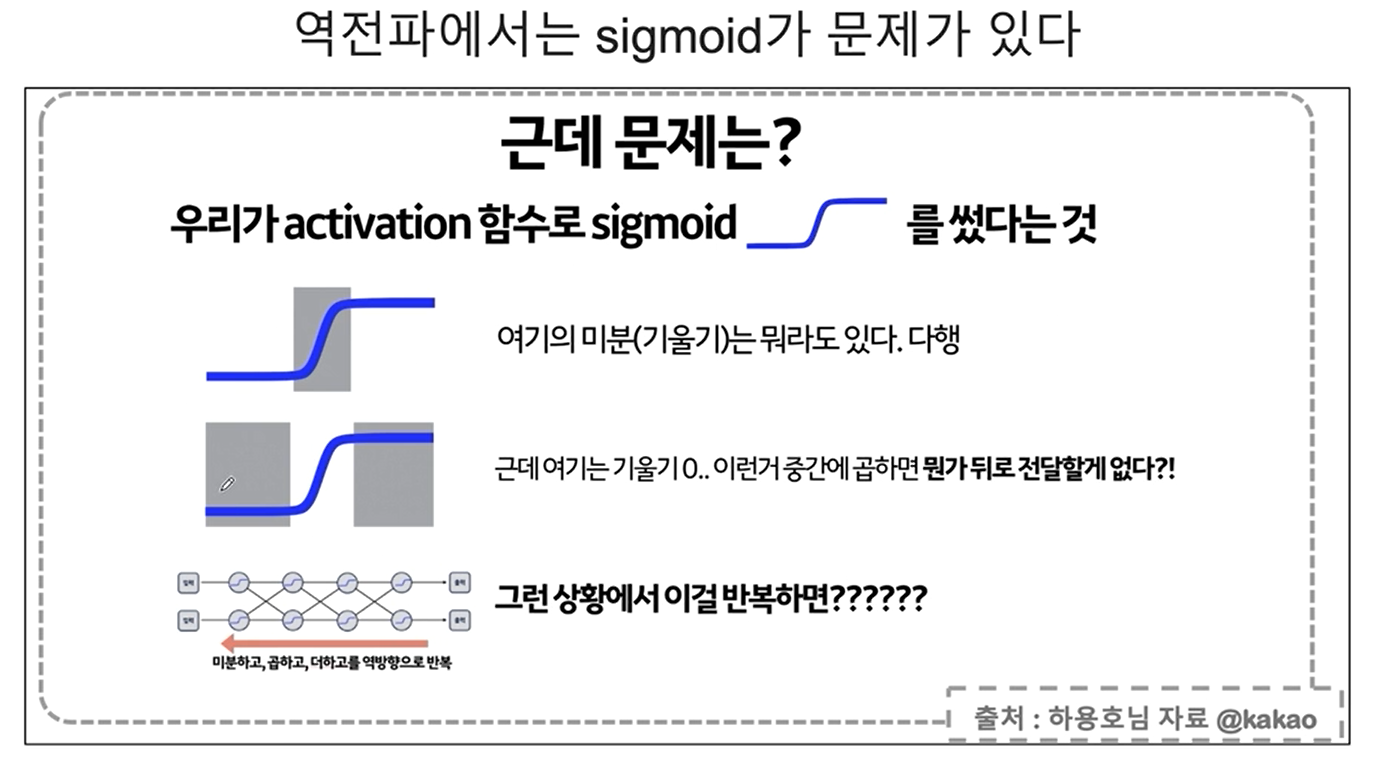
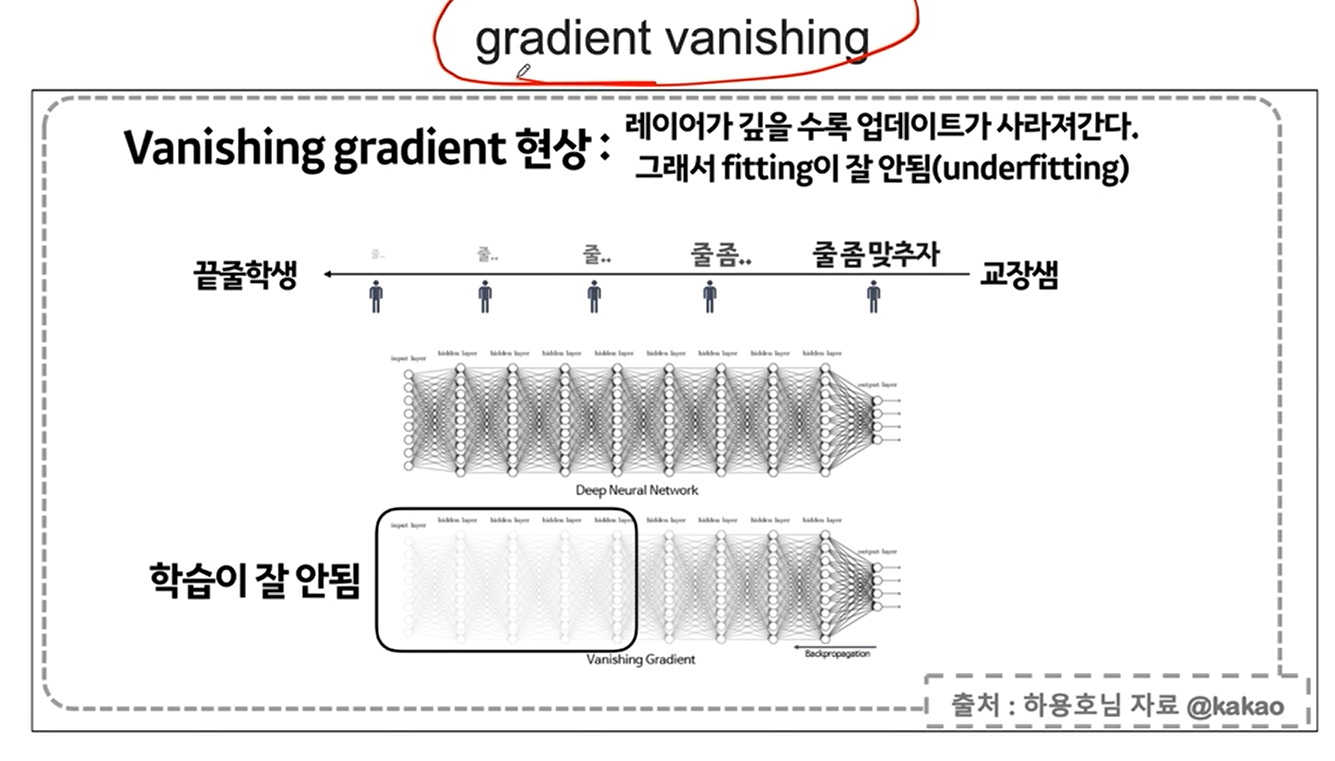
이를 개선하는 방법이
gradient vanishing
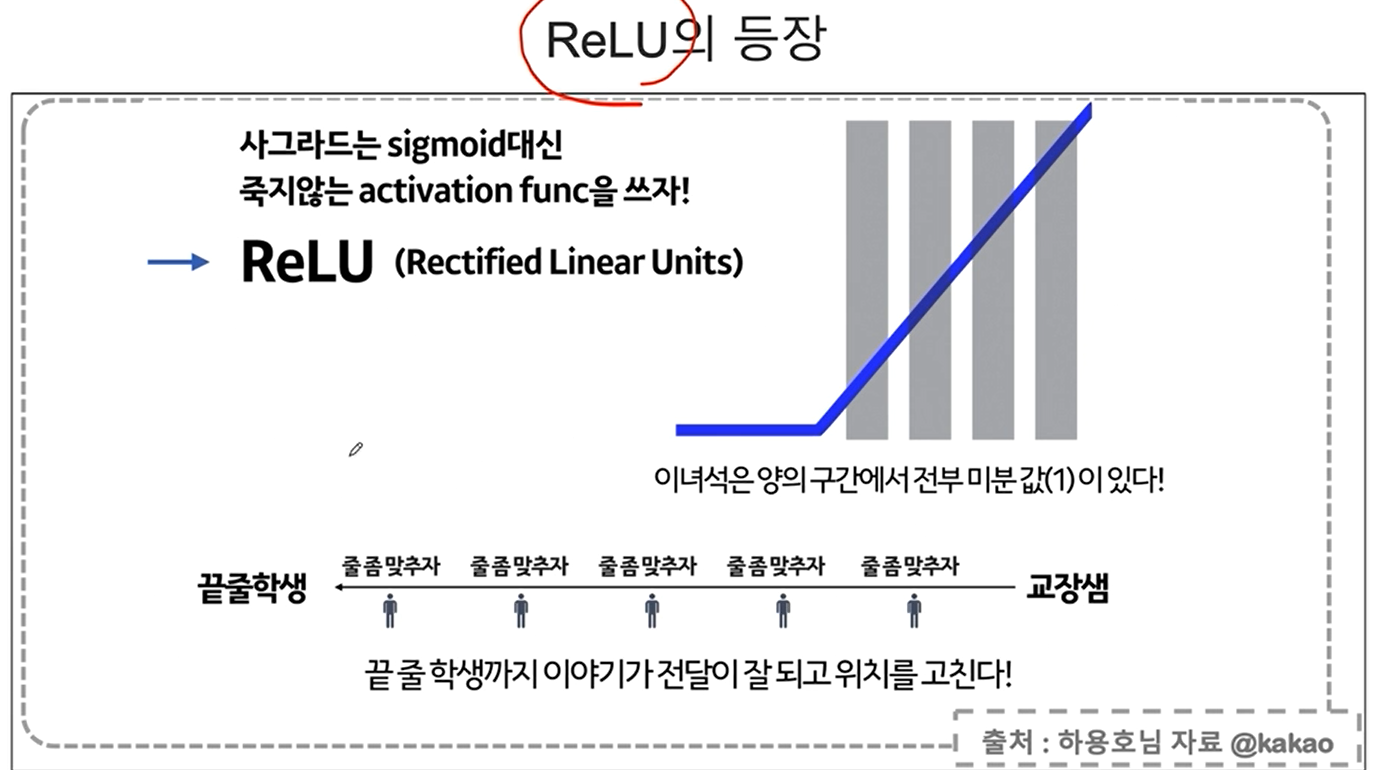
ReLU란?
softmax

gradient encent

model.compile(optimizer='adam',loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()모델을 fit해주자!
hist = model.fit(x_train,y_train,epochs=100)
model.evaluate(x_test,y_test,verbose=2)[0.0858207568526268, 1.0]
plt로 확인해보면
plt.plot(hist.history['loss'])
plt.plot(hist.history['accuracy'])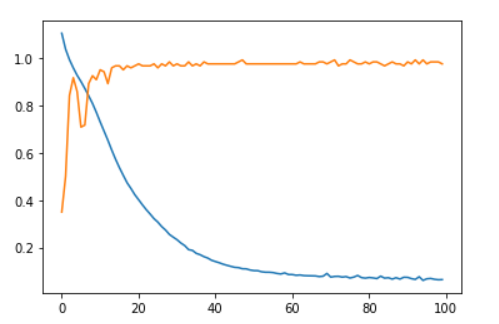
오 성적이 좋은 것을 볼 수 있다!
