이디야는 스타벅스 매장 옆에 존재하는가 데이터 분석 + 시각화
이다야는 과연 스타벅스 매장 옆에 존재하는가에 대한 데이터 분석 및 시각화
필요한 import 및 from 작업
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
import numpy as np
import pandas as pd
import time
from selenium import webdriver
import requests
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
plt.rcParams["axes.unicode_minus"]=False
rc("font",family = "Malgun Gothic")
%matplotlib inline
import re
from bs4 import BeautifulSoup
from urllib.request import urlopen
from bs4 import BeautifulSoup
from tqdm import tqdm_notebook
import folium스타벅스
우선 스타벅스 홈페이지를 URL 변수에 담고 driver를 이용하여 chromedriver로 연다.
url ="https://www.starbucks.co.kr/store/store_map.do"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.implicitly_wait(5)
driver.get(url)이후 지역 버튼 클릭
driver.find_element_by_css_selector("#container > div > form > fieldset > div > section > article.find_store_cont > article > header.loca_search").click()시도 정보와 서울 선택
driver.find_element_by_css_selector("#container > div > form > fieldset > div > section > article.find_store_cont > article > article:nth-child(4) > div.loca_step1 > div.loca_step1_cont > ul > li:nth-child(1) > a").click()
time.sleep(3)
driver.find_element_by_css_selector("#mCSB_2_container > ul > li:nth-child(1) > a").click()BeautifulSoup을 이용해서 html에 담는다.
req = driver.page_source
soup = BeautifulSoup(req, "html.parser")서울시 내 스타벅스 매장의 정보를 받고 인덱스 0을 찾아 매장의 이름과 위치, 경도, 위도, 구 이름을 확인할 수 있다.
content = soup.find("div", id = "mCSB_3_container")
contents = content.find_all("li")
contents[0]
스타벅스 매장을 리스트에 담고 for문을 이용해서 서울시 모든 스타벅스 매장의 정보를 알아낸다. 그 중 필요한 정보인 매장이름, 주소, 구, 브랜드는 스타벅스로 하여 append()에 추가하는 분석화
starbucksList = []
for li in contents:
name = li.find("strong").text.strip()
address = li.find("p").text.strip().replace("1522-3232","")
gu =address.split(" ")[1]
print(name, address, gu)
each ={
"매장이름": name,
"주소" : address,
"구" : gu,
"브랜드": "스타벅스"
}
starbucksList.append(each)strip()을 통해 띄어쓰기 부분은 삭제하였고, replace를 통해 필요없는 가게 번호 정보는 삭제 시켜줬다.
스타벅스 매장이 총 몇개인지 알아보기 위해 len()함수 이용
len(starbucksList)총 574개라고 나왔다. 이것을 DateFrame으로 담아주자.
df_starbucks = pd.DataFrame(starbucksList)
df_starbucks.head(10)
이디야
스타벅스와 동일하게 URL 변수에 홈페이지 주소를 담는다.
ei_url = "https://www.ediya.com/contents/find_store.html"
driver = webdriver.Chrome("../driver/chromedriver.exe")
driver.implicitly_wait(5)
driver.get(ei_url)이후 스타벅스 데이터에서 얻은 구별 정보로 for문을 이용해서 이디야였는 구별 매장 갯수와 정보를 수집한다.
gu_list = list(df_starbucks["구"].unique())
len(gu_list)
eidiyaList =[]
for gu in tqdm_notebook(gu_list):
driver.find_element_by_css_selector("#keyword")
# 검색 초기화
driver.find_element_by_css_selector("#keyword").clear()
# 입력
driver.find_element_by_css_selector("#keyword").send_keys(f"서울 {gu}")
# 검색 버튼 클릭
driver.find_element_by_css_selector("#keyword_div > form > button").click()
# 이디야 구별 매장 정보 수집
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
ul_tag = soup.find("ul",id ="placesList")
dl_all = ul_tag.find_all("dl")
for dl in dl_all:
name = dl.find("dt").text.strip()
address = dl.find("dd").text.strip()
gu = address.split(" ")[1]
each ={
"매장이름": name,
"주소" : address,
"구" : gu,
"브랜드" : "이디야"
}
eidiyaList.append(each)len()함수를 이용해서 얻은 결과 739개 데이터가 나온다.
이후 이디야역시 DataFrame에 담은 후 스타벅스와 이디야 DataFrame을 병합한다.
df_sumData = pd.concat([df_starbucks, df_eidiya])
df_sumData.reset_index(drop=True, inplace=True)
df_sumData.tail()구글 지도를 이용한 매장의 위치 좌표 반환
import googlemaps
gmaps_key ="AIzaSyARJecTYacbReyN9i7zLH3Y-JOiDVHNYvs"
gmaps = googlemaps.Client(key= gmaps_key)
gmaps위도, 경도를 np.nan데이터로 표현한다.
df_sumData["위도"] = np.nan
df_sumData["경도"] = np.nan각 매장의 위도와 경도를 이미 알 수 있기에 주소,위도,경도를 for문을 이용해서 추가시킨다.
for idx, rows in tqdm_notebook(df_sumData.iterrows()):
rows["주소"]
tmp = gmaps.geocode(rows["주소"], language="ko")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
df_sumData.loc[idx, "위도"] = lat
df_sumData.loc[idx, "경도"] = lng
Mapping 작업
mapping = folium.Map(location = [37.535855, 126.991558],zoom_start=11)
for idx, rows in df_sumData_csv.iterrows():
# 브랜드별 마커 설정
if rows["브랜드"] =="스타벅스":
mk_color="black",
elif rows["브랜드"] == "이디야":
mk_color = "blue"
# 지도마커 생성
folium.Marker(
location=[rows["위도"],rows["경도"]],
popup=rows["주소"],
tooltip = rows["매장이름"],
icon =folium.Icon(
icon ="coffee",
prefix="fa",
color = mk_color)
).add_to(mapping)
mapping브랜드별 마커 설정 및 지도 마커를 생성해준다.
각 구 별 스타벅스와 이디야의 개수를 파악한다.
df_sumCount = df_sumData_csv.pivot_table(index="구", columns ="브랜드",values ="값", aggfunc= np.sum)
df_sumCountdf_sumCount.plot.bar(rot = 0, figsize = (15,10), color=["black","blue"])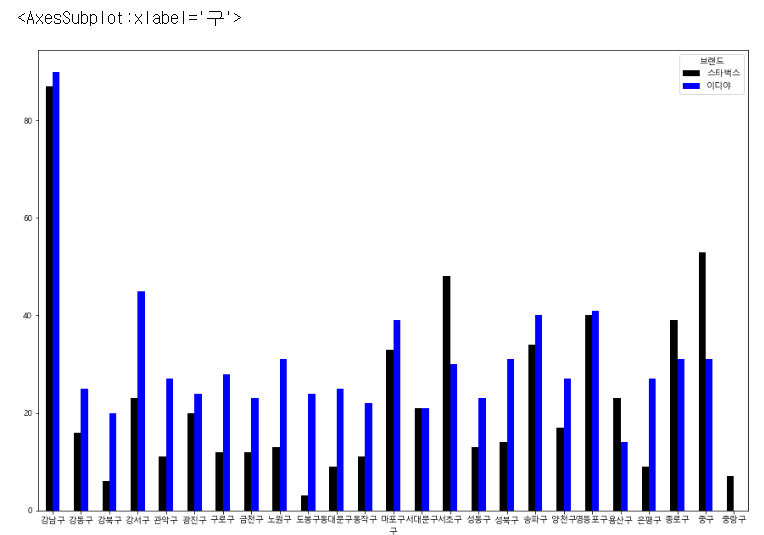

이렇게 해서 제로베이스 첫번째 과제를 나름 성공적으로 해결했다,,
