
TIL
최종프로젝트 3일차
- 최종프로젝트 3일차. 오늘은 내가 담당한 상품 도메인에 조회속도를 향상시키고자 캐시를 적용하였다.
- 지난 게시글에서 Redis를 이용한 캐싱에 대해 잠깐 다뤘었는데, 이번에는 직접 적용하면서 겪은 내용과 함께 조금 더 자세하게 다뤄보려고 한다.
캐싱이란?
- 일반적으로 모든 데이터는 DB에 저장이 되고, CRUD를 수행할때 DB를 거쳐서 수행하게 된다.
이것이 일반적인 구조이지만, DB에는 치명적인 단점이 있다. DB는 HDD라는점.
HDD의 특성상 SSD보다 느리기에, 속도적인 단점이 있다. 메모리의 속도와 용량은 반비례하는법- 이를 보완하기위해 등장한것이 바로 캐싱이다.
- 사실, SSD로 DB를 구성하는것이 제일 좋겠지만, 그렇게되면 가격이 엄청나게 비쌀것이다.
그래서 캐싱이 등장했다.- 캐싱은 원본 데이터와는 별개로 자주 쓰이는 데이터(Hot Data)들을 복사해둘 캐시 공간을 마련한다. 캐시 공간은 상수 시간 등 낮은 시간 복잡도로 접근 가능한 곳
즉, 접근 시간이 원본 데이터에 접근하는 속도보다 훨씬 빠르게 접근 가능한 곳을 주로 사용한다.
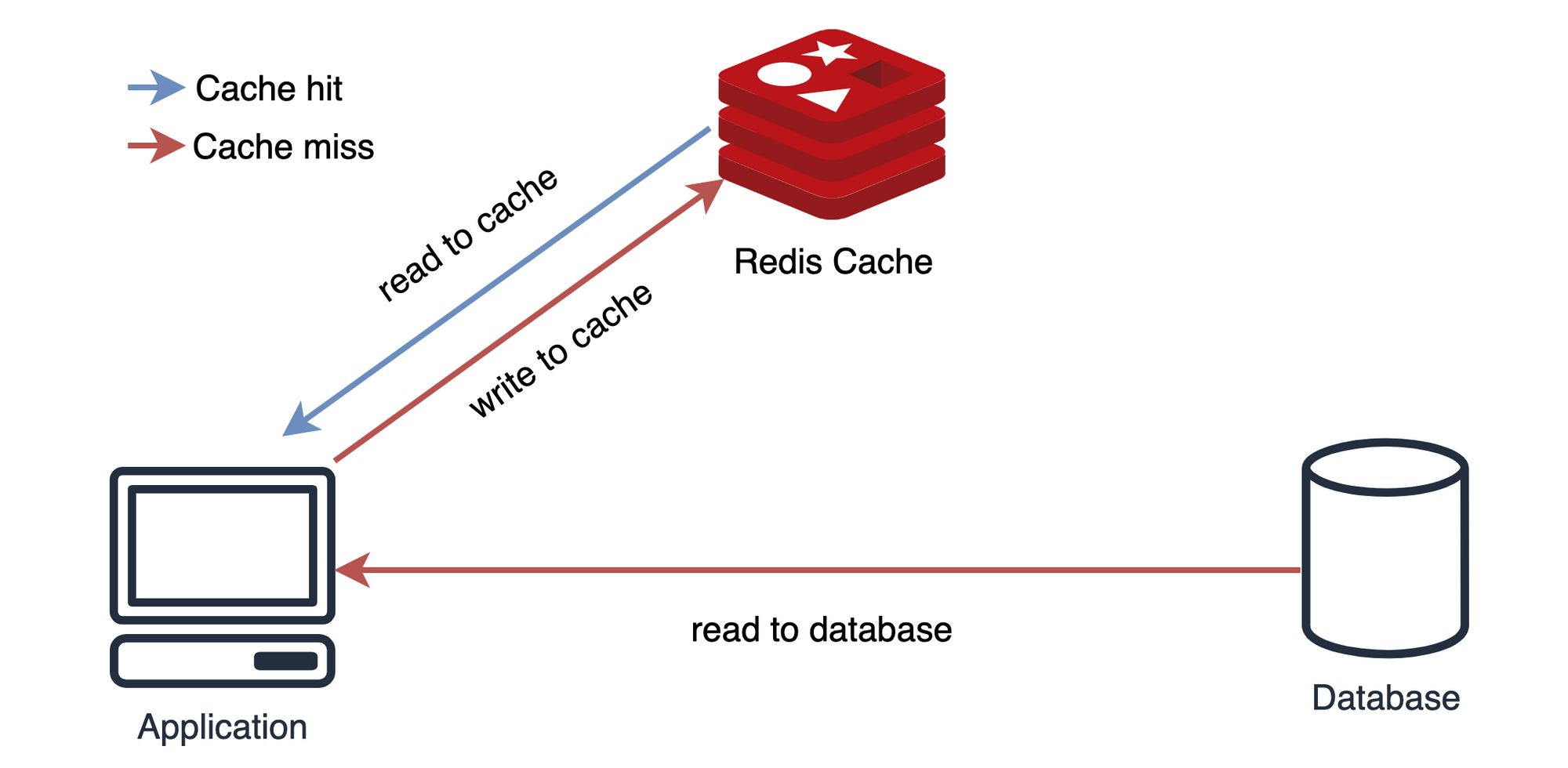
캐시 작동 방식
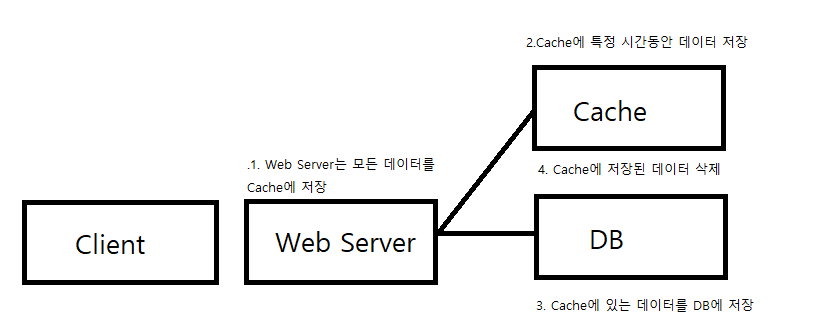
- 데이터를 달라는 요청이 들어오면, 원본 데이터가 담긴 곳에 접근하기 전에 먼저 캐시 내부부터 찾는다.
- 캐시에 원하는 데이터가 없거나(Cache), 너무 오래되어 최신성을 잃었으면(Expiration) 그때서야 원본 데이터가 있는 곳에 접근하여 데이터를 가져온다. 이때 데이터를 가져오면서 캐시에도 해당 데이터를 복사하거나 혹은 갱신한다.
- 캐시에 원하는 데이터가 있으면 원본 데이터가 있는 공간에 접근하지 않고 캐시에서 바로 해당 데이터를 제공한다. (Cache hit)
- 캐시 공간은 작으므로, 공간이 모자라게 되면 안 쓰는 데이터부터 삭제하여 공간을 확보한다.
캐싱 전략
캐싱전략은 크게
Look aside Cache와Write Back2가지 방식이 있다.
또한 Write에는 Cache 데이터 저장 여부에 따라Write-Around,Write-Through2가지가 있다.
1. Look aside Cache(Lazy Loading)
- Lazy Loading의 장점은, Cache에 데이터가 저장되어 있다면,
DB에 접근하는 대신 Cache에서 호출함으로써 부하를 줄일 수 있다.
Redis가 다운되더라도 바로 장애로 이어지지 않고 DB에서 데이터를 가지고 올 수 있다.
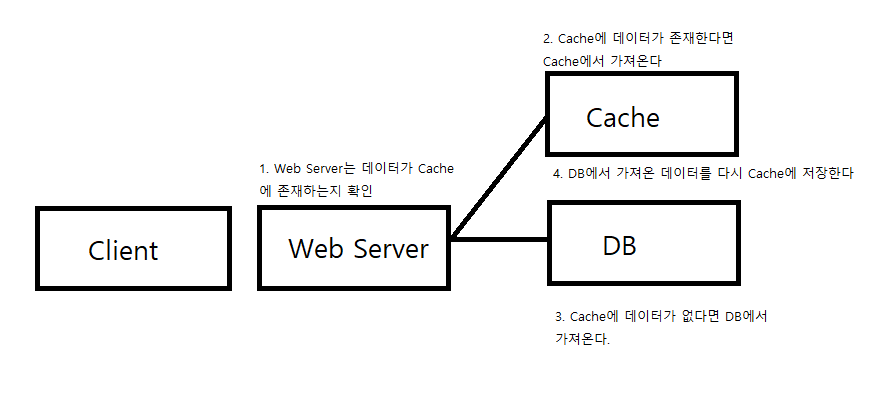
2. Write Back
- Write Back은, 쓰기가 굉장히 빈번할 때 사용한다.
DB(Disk)에 바로 저장하지 않고 Cache에 먼저 저장한다.
그리고 특정 시점에 Cache 데이터를 DB에 저장한다.
DB에 바로바로 저장하는 방식에 비해 DB부하가 줄어든다.
지금 진행하는 최종 프로젝트도 경매 시스템이기에 쓰기가 굉장히 빈번하여 나쁘지 않아보인다.
Write하는 방법에도Write-Around,Write-Through방식이 있다.
- 1. Write-Around
- Write-Around는 Cache를 거치지 않고 무조건 DB에 저장을 한다.
- 그리고 조회 시, cache miss의 경우에만 DB에서 데이터를 가지고 와서 조회한다.
- DB에 발생한 변화가 조회에는 적용이 안될 수 있다. 아마도 특수한 상황에서 쓸 수 있을것 같다.
- 2. Write-Through
- Write-Through는 DB에 데이터를 저장할 때, Cache에도 같이 저장하는 것이다.
- 장점으로 Cache는 항상 최신의 데이터를 가지고 있지만,
저장을 2번 한다는 점이라는 단점이 존재한다.

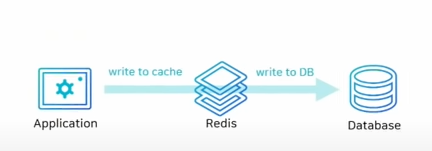
Redis
- 이전에 동시성 제어 게시글에서 언급됬던 Redis가 캐싱을 해준다.
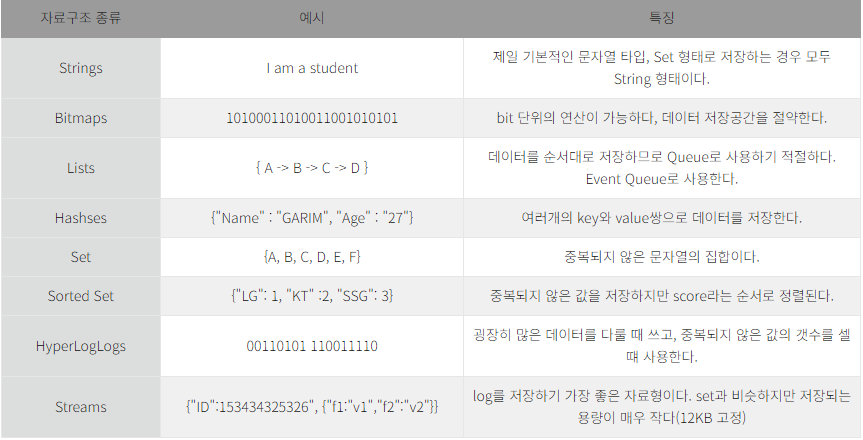
사실 동시성 제어도 Redis가 싱글쓰레드인 점을 이용하여 하나씩 DB에 넘겨주는것.Redis의 경우Memcached와는 달리 다양한 컬렉션(Collection)을 사용한다.- Redis의 컬렉션은 원자성(Atomic)을 보장하기 때문에 자원 경쟁을 피할 수 있어
트랜잭션 경합의 영향을 덜 받는다.- Redis의 자료구조는 다음과 같다.
Redis를 이용한 캐싱 적용
- Spring에서 다음과 같은 어노테이션으로 캐싱을 적용할 수 있다.
1. @Cacheable(캐시 채우기)
@Cacheable(value = "캐시 이름", key = "키")라고 생각하면 된다.
(Redis는 key-value로 데이터가 이루어져 있다.)- 뒷 부분의
cacheManager는 어떤 cacheManager를 사용할 지 명시해준다.
(별도로 지정하지 않으면 default로 설정된 cacheManager를 사용하게 된다.)- 마지막으로
unless = "#result == null"은 null값은 저장하지 않겠다는 의미이다.- 해당 코드는
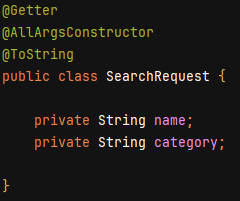
searchRequest라는 DTO를 통해 key를 구성하는데, DTO를 key로 넣기위해서는
@ToString어노테이션을 붙여주면 된다.
- 그러면 이런식으로 저장이 된다.


2. @CacheEvict(캐시 제거)
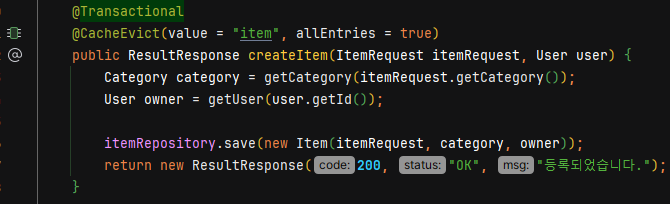
- @CacheEvict(value = "삭제할 캐시 이름", allEntries = true(모든걸 지우겠다는 뜻))
- 해당 코드는 상품이 생성될때마다 캐시를 제거하도록 구현하였다.(캐시에 생성되는 상품이 없기에)
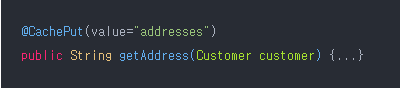
3. @CachePut(캐시 업데이트)
- @CachePut 어노테이션을 사용하면 캐시를 업데이트 할 수 있다.
- 하지만 내가 @CacheEvict를 사용한 이유는, 검색어 기반으로 key가 만들어지기에
선택적으로 업데이트 하기보단 삭제 후 조회 시 캐시 저장으로 최신화를 구현하였다.
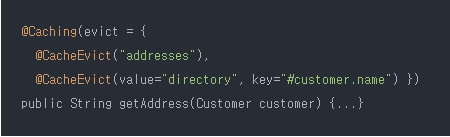
4. @Caching(캐시 그룹화)
- @Caching 어노테이션을 사용하면 같은 종류의 캐시 메서드를 여러개 그룹화 할 수 있다.
직렬화 & 역직렬화
- Redis를 사용하면서 문제를 하나 마주했다.
- 조회를 처음 할때는 조회가 되었는데, 그 다음부터는 조회가 되지 않았다.
- 이러한 문제가 왜 발생했나 찾아보다가,
직렬화/역직렬화가 이유였음을 깨닫고 찾아보았다.
직렬화(Serialization)와 역직렬화(Deserialization)
- 직렬화 : 객체들의 데이터를 연속적인 데이터(스트림)로 변형하여 전송 가능한 형태로 만드는 것
- 역직렬화 : 직렬화된 데이터를 다시 객체의 형태로 만드는 것
- 객체 데이터를 통신하기 쉬운 포멧(Byte,CSV,Json..) 형태로 만들어주는 작업을 직렬화라고 볼 수 있고, 역으로, 포멧(Byte,CSV,Json..) 형태에서 객체로 변환하는 과정을 역직렬화라고 할 수 있겠다.
왜 직렬화/역직렬화가 필요할까?
- 자바에는 원시타입(Primitive Type)이 byte,short,int,long,float,double,boolean,char 총 8가지가 있다.
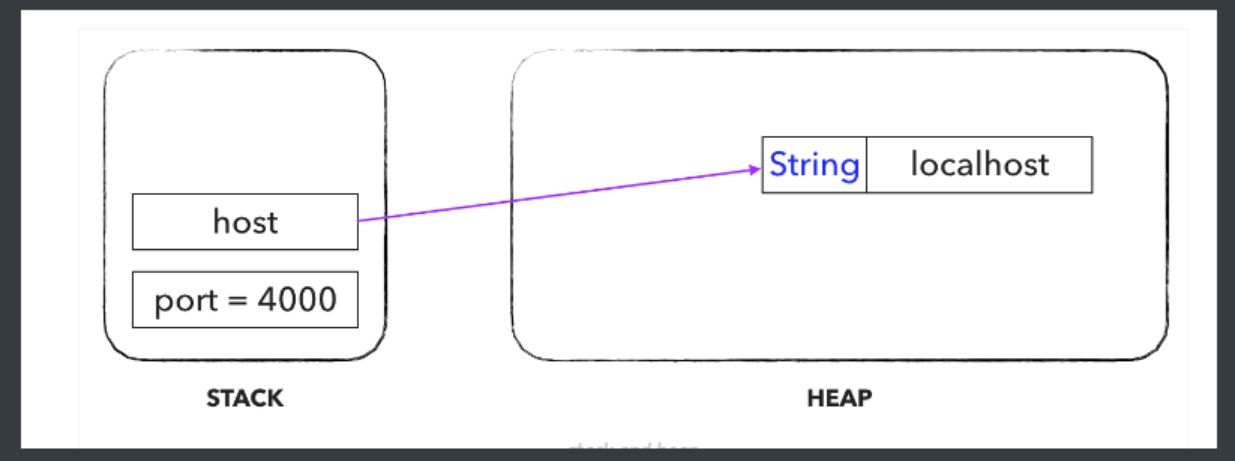
그리고 그 외 객체들은 주소값을 갖는 참조형 타입이다.- 원시타입은 stack에서 값 그 자체로 갖고있다
외부로 데이터를 전달할때, 값을 일정한 형식의 raw byte 형태로 변경하여 전달할 수 있다.- 하지만 객체의 경우 실제로 Heap 영역에 존재하고 스택에서는 Heap 영역에 존재하는 객체의 주소(메모리 주소)를 갖고 있다.
- 프로그램이 종료되거나 객체가 쓸모없다고 판단되면 Heap 영역에 있던 데이터는 제거된다.
따라서 본인 메모리에서도 데이터가 사라진다.- 따라서 이 주소값의 데이터(실체)를 Primitive 한 값 형식 데이터로 변환하는 작업을 거친 후, 전달해야한다.
왜 Redis 캐시를 사용하는데 전송이 필요할까?
- 둘다 같은 PC에서 작동중이지만, Redis와 Spring서버는 엄연히 다른 서버이다.
따라서 데이터에대한 작업을 위해 직렬화/역직렬화가 필요한것이다!- 그렇다면 직렬화/역직렬화를 어떻게 구현할까?
JdkSerializationRedisSerializer
- JdkSerializationRedisSerializer 는 Default로 적용되는 Serializer로 기본 자바 직렬화 방식을 사용한다.
- 자바에서는 Serializable 인터페이스만 구현하면 별도의 작업 없이 사용가능하다.
하지만 여러가지 단점이 있다.
- SerialVersionUID 설정을 하지 않으면 클래스의 기본 해시값을 SerialVersionUID 로 사용한다. 따라서 클래스 구조가 조금이라도 변경시 SerialVersionUID 가 달라서 역직렬화에 실패할 수 있다.
- 만약 개발자가 주의를 가지고 SerialVersionUID 를 설정한다고 하여도, 클래스 내부 필드 타입이 변경되면 역시 역직렬화가 실패할 수 있다.
- 기본적으로 타입에 대한 정보 등 클래스 메타 정보들을 가지고 있기 때문에 직렬화시 용량이 비대해진다.
GenericJackson2JsonRedisSerializer
- GenericJackon2JsonSerializer 는 Class Type 을 지정할 필요 없이 자동으로 객체를 Json 형식으로 직렬화해주는 장점이 있다.
하지만 직렬화된 데이터가 Class Type 을 포함한다는 단점이 있다.
Jackson2JsonRedisSerializer
- Jackson2JsonRedisSerializer 은 @class 필드를 포함하지 않고 Json 으로 저장해준다.
하지만 항상 Class Type 정보를 Serializer 에 함께 지정해주어야한다.
이는 앞서 살펴보았던 GenericJackson2JsonRedisSerializer와 반대 특징을 가진다.
StringRedisSerializer
- 결론부터 말하자면 StringRedisSerialier 를 직렬화 구현체로 선택하는 것이 가장 단점을 최소화할 수 있는 방법이다.
- StringRedisSerializer 는 String 값을 그대로 저장하는 Serializer 이다.
그렇기에 Json 타입으로 별도로 변환하는 과정이 필요하지만,
앞서 살펴본 직렬화 구현체들의 단점을 보완할 수 있다.
조회가 한번만 되었던 문제의 이유와 해결
- 조회가 한번만 되었던 이유를 알게 되었다.
- 처음 조회를 할때는 DB에서 조회를 하여 조회가 가능했지만,
- 2. 두번째 조회부터는 캐시에서 값을 가져와야하는데, 이부분이 되지 않았던 것이다.
- 왜 안되었을까 생각해보았고, 결과를 찾았다.
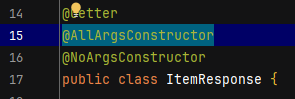
- 역직렬화를 하기위해서 다시 객체를 생성해야하는데, 생성자가 구현되어있지 않았기 때문이다.
- @AllArgsConstructor 어노테이션을 추가하여 해결하였다.
캐싱 부하 테스트
- 25개의 상품을 만들고, 1000명의 유저가 각각 10번씩 조회와 수정하는 상황을 테스트 해보았다.
캐싱을 적용하지않았을때(조회만 했을경우)
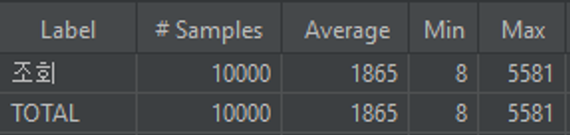
캐싱을 적용했을때(조회만 했을경우)
- 약 30%정도 실행시간이 단축되었다.
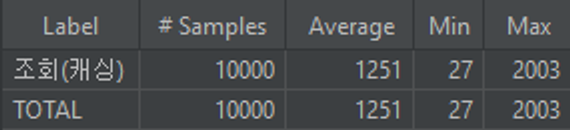
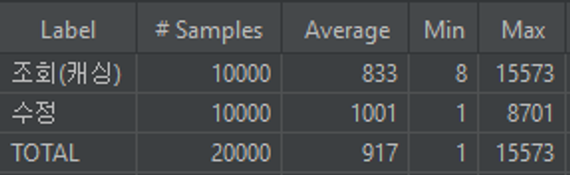
캐싱을 적용하지않았을때(조회+수정)
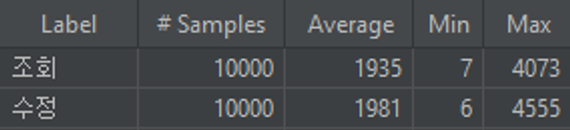
캐싱을 적용했을때(조회만 했을경우)
- 약 50%정도 실행시간이 단축되었다.
오늘의 회고
오늘은 Redis를 이용한 캐싱 적용을 하면서, 우연치 않게 문제를 만나서 해결하는 과정에서
상당한 수확을 얻은것 같다.
문제의 원인을 파악하기 위해 개념적으로 접근하였고,
개념을 공부하다 보니 문제의 해결법까지 도달했다.
또 성장한것 같아서 기분이 좋다.
그리고 사실 수정할때마다 캐시를 삭제하기에, 캐싱을 적용해도 성능이 그렇게 다르지 않을것이라 예상했는데, 이정도로 성능이 다르게 나올지는 몰랐다.
캐싱이 DB에 비해서 비용이 굉장히 비싼데, 값어치를 톡톡히 하는것 같다.
내일은 개인적인 사정으로 프로젝트에 참여하지 못하게 되었다.
참여하지 못하는 만큼, 주말을 통해 꾸준히 성장해보려고 한다.

개발하는 기록자