논문 제목:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
저자 : JasonWei, Xuezhi Wang, Dale Schuurmans Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi Quoc V. Le, Denny Zhou
Abstract
연결된 사고(chain of thought)를 생성하는 것이, 즉 일련의 중간 추론 단계를 생성하는 것이 대형 언어 모델이 복잡한 추론을 수행하는 능력을 크게 향상시킨다는 점을 탐구를 통해서 이러한 추론 능력이 충분히 큰 언어 모델에서 자연스럽게 등장한다는 것을 보여줍니다.연결된 사고 프롬프트(chain-of-thought prompting)라는 간단한 방법을 이 방법에서는 몇 가지 연결된 사고 예제를 프롬프트에 제공하여 모델이 이를 학습함 이를 통해 세 가지 대형 언어 모델에 대한 실험 결과, 연결된 사고 프롬프트가 산술, 상식, 상징적 추론 작업에서 모델의 성능을 향상시키는 것을 확인함
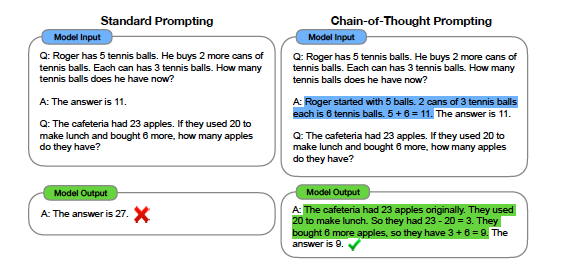
- 설명: 문제의 답을 단답형으로 구성한 기존의 프롬프트는 좌측처럼 오답을 내었지만 우측처럼 문제를 풀이하는 과정을 예제로 넣었더니, 정답으로 귀결함
💡대규모 언어 모델의 등장으로 프롬프트 엔지니어링이라는 새로운 학문이 탄생했으며, 이는 프롬프트를 정교하게 설계해 언어 모델로부터 더 나은 답변을 이끌어내는 방법을 연구하는 분야
Introduction
논문은 언어 모델은 규모가 커짐에 따라서 더욱 뛰어난 성능을 보이지만 수리 연산, 상식 추론, 기호 추론과 같이 난이도가 높은 과제에 대한 해결 능력은 단순히 모델 규모를 키우는 것만으로는 부족으로 대형 언어 모델이 수리 연산, 상식 추론, 기호 추론과 같은 난이도 높은 문제를 해결하기 위해 연결된 사고 프롬프팅(chain-of-thought prompting) 기법을 제안했으며, 기존 파인튜닝과 소수 샷 프롬프팅의 한계를 보완하여, 프롬프트에 입력, 사고 과정, 출력을 포함시켜 언어 모델의 추론 능력을 향상시키는 접근법입니다. 이 방법은 중간 논리 과정을 자연어로 전개하여 더 높은 성능을 끌어냄.
Chain-of-Thought Prompting
논문의 목표는 언어 모델이 이와 유사한 연결된 사고(chain of thought)를 생성하는 능력을 갖추게 하는 것. 즉, 문제의 최종 답에 도달하기 위한 일관된 중간 추론 단계를 생성
목표
연결된 사고는 모델이 여러 단계의 문제를 중간 단계로 분해하여 추가 계산을 가능하게 하고, 모델의 추론 과정을 해석하고 디버그할 수 있는 기회를 제공합니다. 이는 수학 문제, 상식 추론, 기호 조작 등 다양한 환경 작업에 활용될 수 있으며, few-shot prompting을 통해 충분히 큰 언어 모델에서 쉽게 이끌어낼 수 있음
Arithmetic Reasoning
실험설정
- 연결된 사고 프롬프팅을 다양한 언어 모델(GPT-3, LaMDA, PaLM, UL2, Codex)에 대해 수학 문제 벤치마크(GSM8K, SVAMP, ASDiv, AQuA, MAWPS)에서 실험
- 표준 프롬프팅과 비교해, 연결된 사고 프롬프팅은 각 예시에 중간 추론 과정을 추가함으로써 언어 모델의 추론 성능을 향상시키는 방법

-
수학 문제와 상식 추론을 포함한 논문 전체에서 수행한 실험에 대한 예시
-
결과
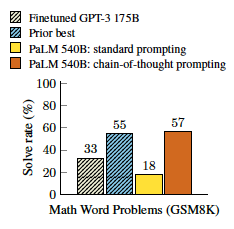
결과
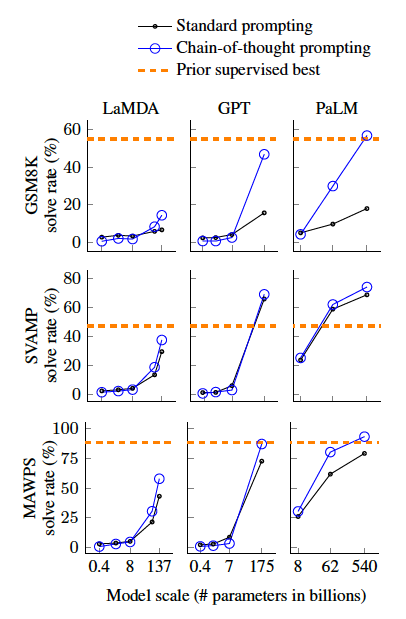
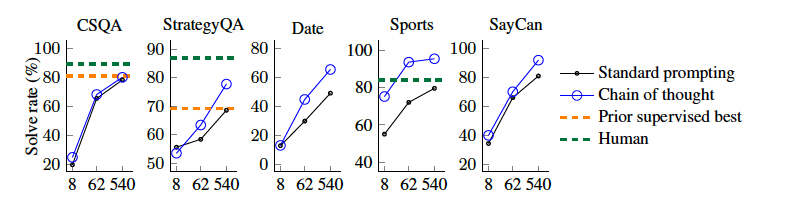
CoT는 대형 언어 모델의 성능을 크게 향상시키는 것을 보여주며, 모델 규모가 커질수록(100B 이상의 매개변수) 효과가 나타나며, 복잡한 문제일수록 더 큰 성능 향상을 보임
CoT는 작은 모델에서는 성능이 뛰어나지 않았으며, 일반적인 프롬프팅보다 낮은 경우도 있었습니다. 그러나 난이도가 높은 GSM8K에서는 CoT가 뛰어난 성능을 보였지만, MAWPS의 가장 쉬운 SingleOp에서는 성능 향상이 거의 없음. GPT-3 175B와 PaLM 540B 모델에서는 CoT를 사용했을 때, fine-tuning한 SOTA 모델보다 더 우수한 결과를 나타남
Discussion
첫째, 연결된 사고가 인간의 사고 과정을 모방하지만, 신경망이 실제로 "추론"을 하고 있는지에 대한 답을 제공하지 못함
둘째, few-shot prompting 설정에서 예시에 연결된 사고를 추가하는 비용은 적지만, fine-tuning에는 부담이 될 수 있음
셋째, 올바른 추론 경로가 보장되지 않아, 올바른 답변과 잘못된 답변이 모두 생성될 수 있음
프롬프팅 기법
https://thebasics.tistory.com/298
자동화 CoT 프로프트
https://ar5iv.labs.arxiv.org/html/2210.03493
참고 자료
https://basicdl.tistory.com/entry/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-Chain-of-Thought-Prompting-Elicits-Reasoning-in-Large-Language-Models
https://thebasics.tistory.com/298
https://www.ncloud-forums.com/topic/63/
https://ar5iv.labs.arxiv.org/html/2210.03493
