논문 제목:LoRA: Low-Rank Adaptation of Large Language Models
저자 : Edward Hu, Yelong Shen ,Microsoft Corporation그밖에 팀원들
Abstract
대형 언어 모델(LLM)의 미세 조정에는 막대한 GPU 메모리가 필요하며, 이로 인해 더 큰 모델을 사용하는 데 제약이 생깁니다. 로우랭크 적응(Low-Rank Adaptation) 기법의 양자화된 버전인 QLoRA는 이러한 문제를 상당 부분 완화하지만, 효율적인 LoRA 랭크(rank)를 찾는 것은 여전히 어려운 과제이며,QLoRA는 미리 정의된 랭크에서 학습되기 때문에, 더 낮은 랭크로 재구성하려면 추가적인 미세 조정 단계를 요구함
INTRODUCTION
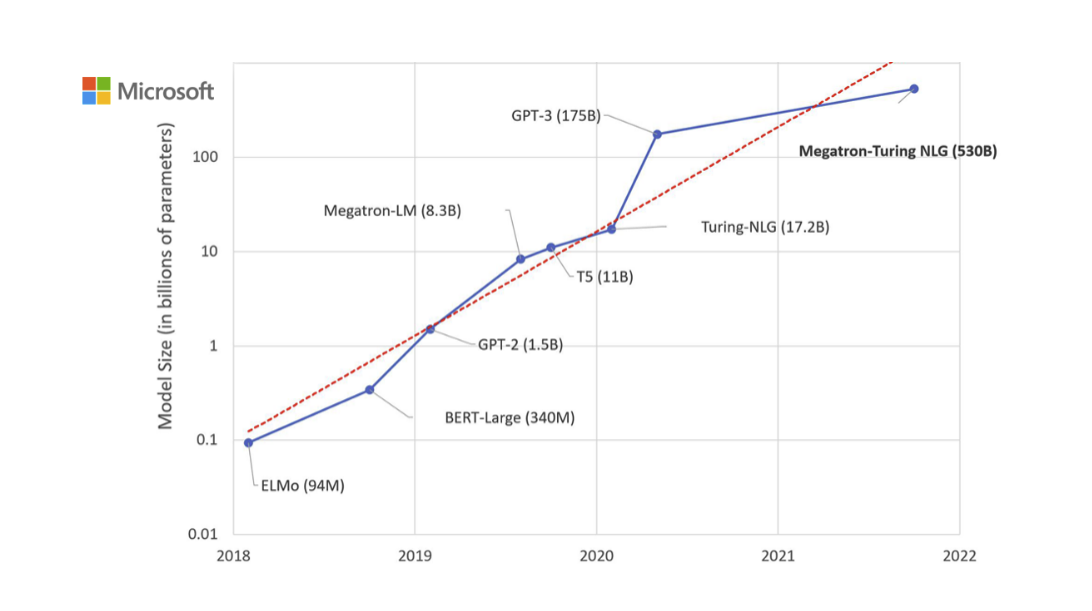
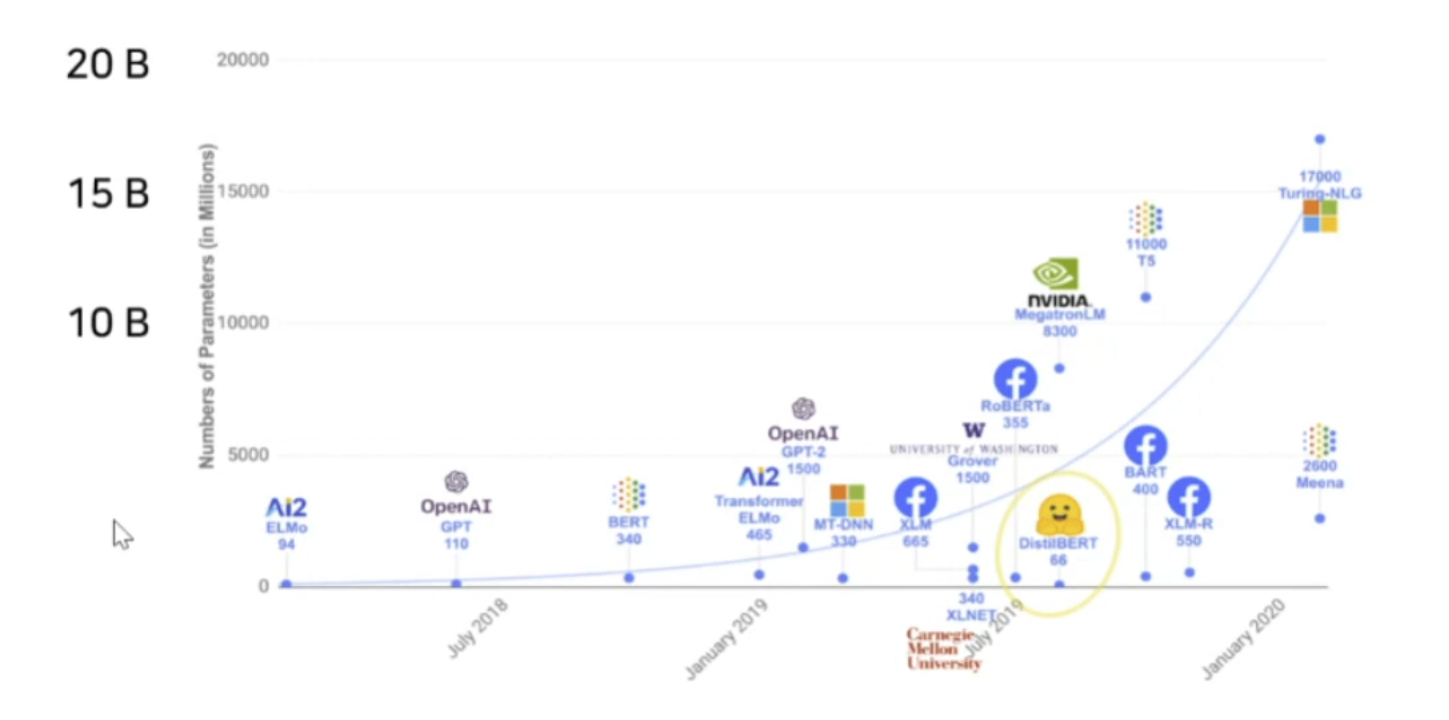
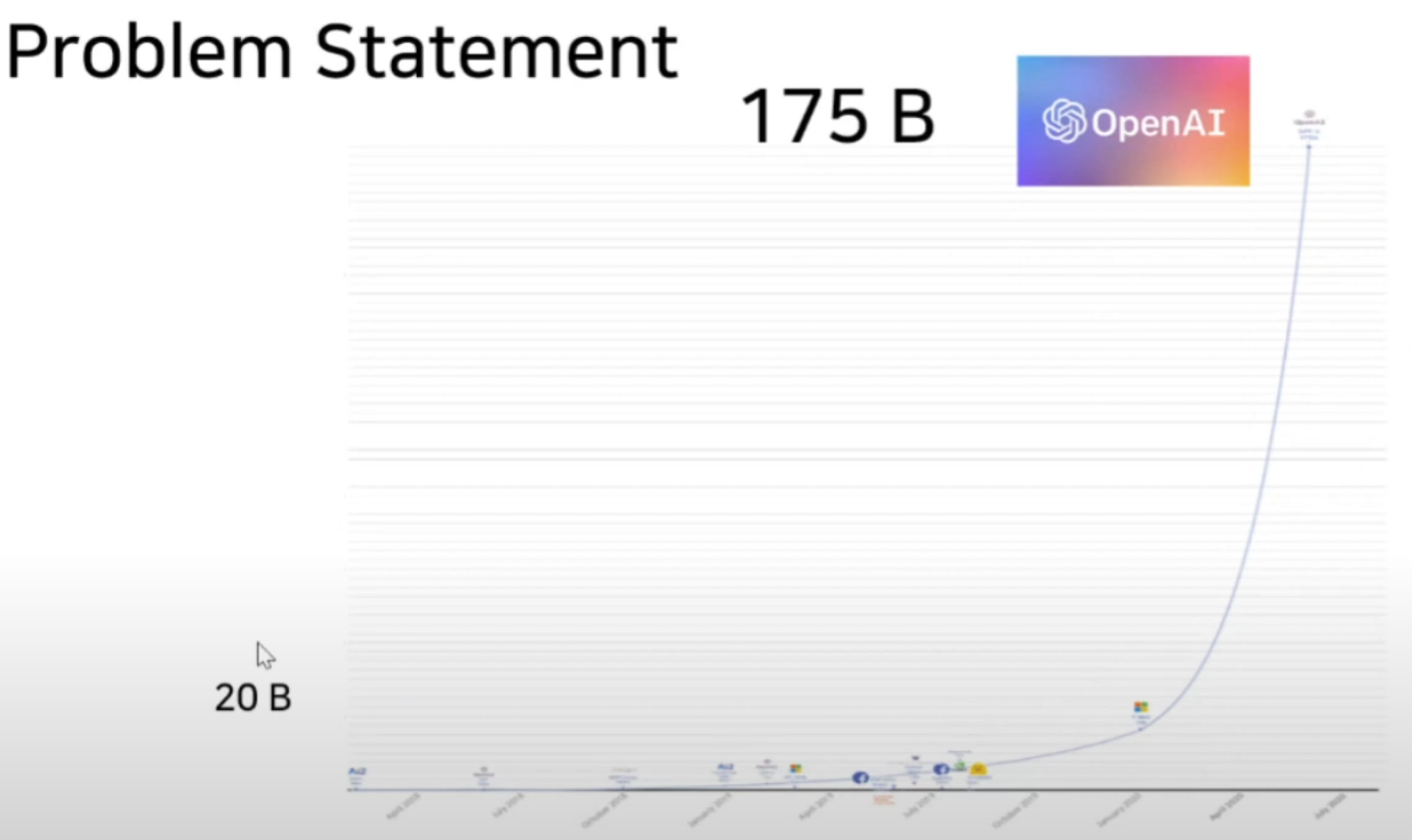
자연어 처리의 많은 애플리케이션에서는 하나의 대규모 사전 학습 언어 모델을 여러 다운스트림 애플리케이션에 맞게 적응시키는 것이 필요합니다. 이러한 적응은 보통 fine-tuning을 통해 이루어지며, 이는 사전 학습된 모델의 모든 파라미터를 업데이트합니다. 그러나 fine-tuning의 주요 단점은 새로운 모델이 원래 모델과 동일한 수의 파라미터를 포함하게 된다는 점입니다. 많은 파라미터를 학습시는것은 시간도 오래 걸릴 뿐더러 비효율이 발생한다. 이를 해결하기 위해 많은 사람들이 일부 파라미터만 적응시키거나 새로운 작업을 위해 외부 모듈을 학습시키는 방법을 모색했습니다. 이렇게 하면 각 작업에 대해 사전 학습된 모델 외에 작업별 파라미터만 저장하고 로드하면 되므로, 배포 시 운영 효율성이 크게 향상됩니다. 하지만 기존 기법들은 모델 깊이를 확장하여 추론 지연 시간을 유발하거나,모델의 사용 가능한 시퀀스 길이를 줄이는 문제를 발생시킵니다. 더 중요한 것은, 이러한 방법들이 종종 파인튜닝 기준치에 미치지 못해 효율성과 모델 품질 사이의 트레이드오프가 발생한다는 점입니다. 그래서 저자들은 저차원 적응(LoRA, Low-Rank Adaptation) 접근 방식을 제안합니다. LoRA는 사전 학습된 가중치를 고정한 채, 모델 적응 동안 변화하는 밀집 계층의 랭크 분해 행렬을 최적화하여, 밀집 계층의 일부를 간접적으로 학습할 수 있게 합니다.
LoRA의 장점 :
- 사전 학습된 모델을 공유하여 다양한 작업에 맞춘 작은 LoRA 모듈을 만들 수 있습니다.
- LoRA는 훈련 효율을 높이고, 적응형 최적화 기법을 사용할 때 최대 3배까지 하드웨어 진입 장벽을 낮춥니다.
- LoRA의 간단한 선형 설계는 배포 시 학습 가능한 행렬을 고정된 가중치와 합칠 수 있어, 완전히 파인튜닝된 모델과 비교할 때 추론 지연이 발생하지 않습니다.
- LoRA는 기존의 여러 방법과 독립적으로 적용될 수 있으며, 다양한 방법과 결합이 가능합니다.
용어
- dmodel: Transformer 레이어의 입력 및 출력 차원 크기를 나타냄
- Wq, Wk, Wv, Wo: 자기-어텐션 모듈의 쿼리, 키, 값, 출력 프로젝션 행렬을 나타냄
- W 또는 W0: 사전 학습된 가중치 행렬을 나타내며, W는 적응 과정에서 누적된 그래디언트 업데이트를 의미함
- r: LoRA 모듈의 랭크(차원 순위)를 나타냄
PROBLEM STATEMENT
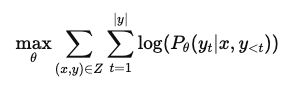
- 기존의 finetuning 방식인 모델의 모든 파라미터를 업데이트하는 최대우도법 목적식
- 각 downstream task마다 다른 LoRA layer를 사용해 효율적으로 파라미터를 업데이트 할 수 있도록 하는 것
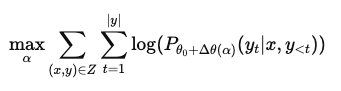
- LoRA를 사용하여 더 작은 rank representation을 제안하여 메모리 및 연산 효율성을 극대화
AREN’T EXISTING SOLUTIONS GOOD ENOUGH?
Transfer learning이 시작된 이래 수십 개의 연구들이 모델 adaptation을 보다 파라미터 및 계산 효율적으로 만들기 위해 노력했다. 예를 들어 언어 모델링을 사용하면 효율적인 adaptation과 관련하여 두 가지 주요 전략이 있다.
- Adapter layer 추가
- 입력 레이어 activation의 일부 형식 최적화
- 문제는 현재의 해결책이 충분하지 않다는 점
- 효율적인 Adaptation을 위한 두 가지 주요 전략
- Adapter layer는 inference latency를 유발
- 다양한 adapter variation이 존재
- 원래 디자인은 각 Transformer 블록에 두 개의 adapter layer가 있음
- 최근 디자인은 블록당 하나의 layer와 추가 LayerNorm이 있음
- Adapter layer를 사용할 때 latency가 증가
- Prompt 최적화의 어려움
- Prompt tuning은 최적화가 어려움
- 학습 가능한 parameter 수가 변할 때 성능이 비선형적으로 변화함
OUR METHOD
LOW-RANK-PARAMETRIZED UPDATE MATRICES
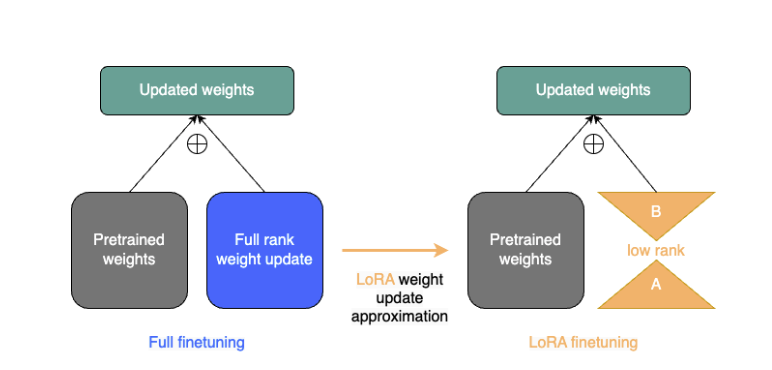
- 특정 task에 adaptation 할 때, 연구에 영감을 받아 parameter 업데이트를 낮은 rank로 제약함
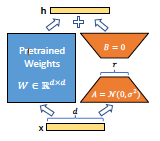
- Pre-trained weight W0를 W0+ΔW로 업데이트하는데, ΔW=BA로 분해
- ΔW=B⋅A이며, B와 A는 학습 가능한 parameter
-
위 수식은 pre-trained 모델의 weight W0에 low-rank matix B와 A로 표현된 변화량 ΔW를 더하여 입력 x에 대한 출력을 계산
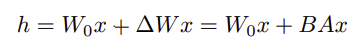
APPLYING LoRA TO TRANSFORMER
-
Transformer 아키텍처에서 LoRA를 사용하여 학습 가능한 parameter 수를 줄임
-
연구는 attention weights에만 적용
-
메모리와 저장 공간 사용이 크게 줄어듦
Empirical Experiments
1. Baseline
- FT: Fine-Tuning
- FTTop2: 마지막 두 레이어만 튜닝
- BitFit
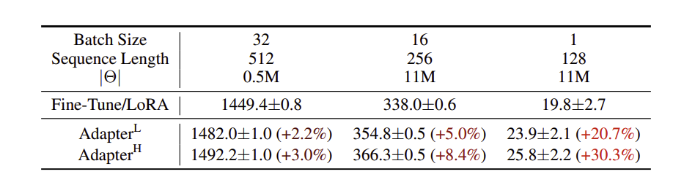
- AdapH: 오리지널 adapter tuning
- AdapL: MLP 모듈 뒤와 LayerNorm 뒤에만 adapter layer 적용
- AdapP: AdapterFusion (Adap과 유사)
- AdapD: AdapterDrop (몇몇 adapter layer를 drop)
2. Result
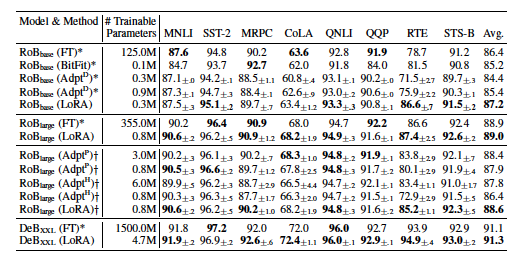
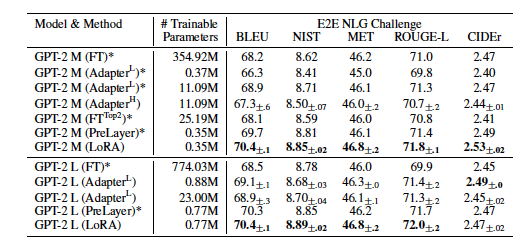
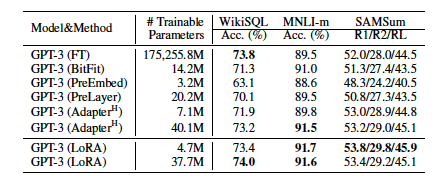
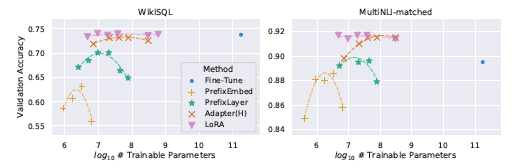
CONCLUSION AND FUTURE WORK
대한 언어 모델의 파인튜닝은 필요한 하드웨어와, 서로 다른 작업에 대해 독립적인 인스턴스를 호스팅하는 데 필요한 저장 및 전환 비용 측면에서 지나치게 비쌉니다. 저자들은 LoRA라는 효율적인 적응 전략을 제안하며, 이는 모델 품질을 유지하면서도 추론 지연 시간을 초래하지 않고 입력 시퀀스 길이를 줄이지 않습니다. 특히, 대부분의 모델 파라미터를 공유함으로써 서비스로 배포 시 빠른 작업 전환을 가능하게 합니다. 우리는 Transformer 언어 모델에 집중했지만, 제안된 원칙은 밀집 계층이 있는 모든 신경망에 일반적으로 적용할 수 있습니다.
참고 자료
https://kyujinpy.tistory.com/83
https://velog.io/@kameleon43/논문리뷰-LORA-LOW-RANK-ADAPTATION-OF-LARGE-LANGUAGE-MODELS
https://jeongwooyeol0106.tistory.com/106
https://velog.io/@bluein/paper-22
https://taeyuplab.tistory.com/12
https://velog.io/@quasar529/논문리뷰-LoRA-Low-Rank-Adaptation-of-Large-Language-Models
