논문 제목:RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVA
저자 : Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, Christopher D. Manning
Abstract
-
검색 증강 언어 모델(Retrieval-augmented language models)은 세상의 상태 변화에 더 잘 적응하고, 드문(long-tail) 지식을 더 효과적으로 통합할 수 있음
-
텍스트 조각을 재귀적으로 임베딩, 클러스터링, 요약하여, 하위 레벨에서 상위 레벨로 요약 수준이 다른 트리를 구성하는 방법
Introduction
재귀적으로 텍스트 청크를 임베딩, 클러스터링, 요약하는 방식으로, 하단에서부터 상단으로 요약 레벨이 다른 트리 구축
Inference 시에는 구축된 트리에서 검색함으로써, 긴 문서에 대해 다양한 요약 레벨에서 정보를 얻어 통합
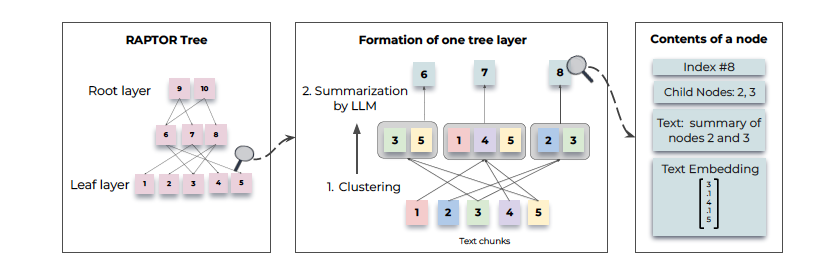
METHODS
RAPTOR는 긴 텍스트의 주제와 계층적 구조를 반영하는 재귀적 트리 구조를 통해 의미적 깊이와 연결성을 개선한 검색 시스템
RAPTOR의 주요 특징
재귀적 트리 구조
텍스트를 짧은 청크(100 토큰)로 분할하며, 문장이 잘리지 않도록 처리해 문맥적 일관성을 유지
각 텍스트 청크를 SBERT 기반 임베딩으로 변환하여 트리의 리프 노드로 사용
클러스터링과 요약을 반복하여 상위 레벨로 통합, 최종적으로 계층적 다층 트리를 생성
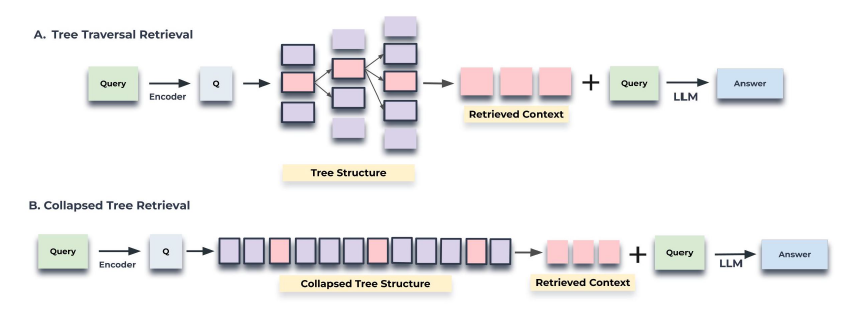
정보 검색 전략
트리 탐색(tree traversal): 트리를 레이어별로 탐색하며, 각 단계에서 관련성 높은 노드 선택.
압축 트리(collapsed tree): 트리의 모든 레이어에서 관련성을 평가하여 가장 중요한 노드를 검색.
클러스터링
소프트 클러스터링을 사용하여 텍스트 청크가 여러 클러스터에 속할 수 있도록 유연성을 제공.
Gaussian Mixture Models(GMMs)를 활용해 요약을 통해 검색된 대량의 정보를 관리 가능한 크기로 압축
Querying
사용자 질문에 대해 RAPTOR 트리에서 정보를 검색하기 위해 두 가지 전략을 사용
Tree Traversal
루트에서 시작해, 각 계층에서 코사인 유사도가 높은 노드를 선택하며 하위 계층으로 탐색.
트리의 상위 계층(전반적인 맥락)부터 하위 계층(세부 정보)까지 정보를 활용 가능.
깊이 d와 노드 수 k로 검색 범위 조정 가능.
Collapsed Tree
트리 계층을 무시하고 모든 노드를 단일 계층으로 간주해 한 번에 검색.
LLM의 토큰 한도 내에서 가장 유사한 노드들을 추가.
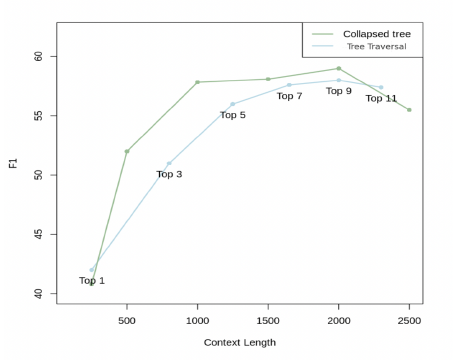
성능이 더 우수해 기본 방식으로 사용.
성능평가
- 다양한 추상화 수준에서 컨테스트 정보를 보강하여 대형언어 모델의 파라메트릭 지식을 향상시키는 새로운 트리 기반 검색 시스템
참고자료
https://muni-dev.tistory.com/entry/RAPTOR-RECURSIVE-ABSTRACTIVE-PROCESSINGFOR-TREE-ORGANIZED-RETRIEVAL
https://aiforeveryone.tistory.com/47
https://muni-dev.tistory.com/entry/RAPTOR-RECURSIVE-ABSTRACTIVE-PROCESSINGFOR-TREE-ORGANIZED-RETRIEVAL
