논문 제목:Self-critiquing models for assisting human evaluators
저자 : OpenAI일행
Abstract
행동 클로닝을 통해 대규모 언어 모델이 자연어 비평을 작성하도록 미세 조정하는 방법
모델이 작성한 비평은 인간이 놓친 요약의 결함을 발견하는 데 도움을 주며, 자연적으로 발생하는 결함과 고의로 삽입된 결함 모두를 식별할 수 있음
Introduction
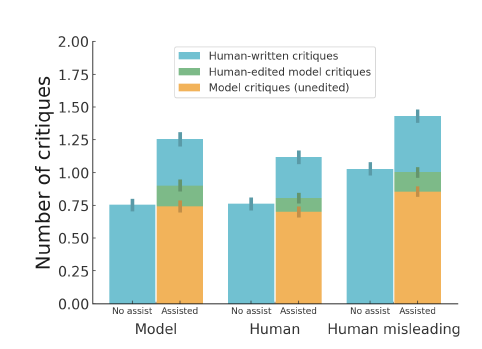
언어 모델을 개발하기 위해 자연어 비평을 활용하는 방법
모델 비평 지원의 효과
모델 크기와 비평 능력의 상관관계
비평을 활용한 자체 개선
생성, 구별, 비평 능력 비교
데이터셋 공개
Generator-discriminator-critique
G: 생성(Generation)
질문에 대한 답변 생성.
D: 구별(Discrimination)
생성된 답변의 품질을 평가(즉, 비평 가능 여부를 판단).
C: 비평(Critique)
생성된 답변의 결함을 인간이 이해할 수 있도록 지적.
이 작업 간의 격차를 비교합니다:
G와 C 간의 격차(GC gap): 모델이 스스로 생성한 답변에서 결함을 지적할 수 있는 정도.
G와 D 간의 격차(GD gap): 모델이 생성한 답변의 품질을 스스로 인지할 수 있는 정도.
D와 C 간의 격차(CD gap): 모델이 결함을 알고 있다고 판단되었을 때, 이를 인간이 이해할 수 있는 방식으로 지적할 수 있는 정도.
GC 및 GD 격차는 항상 양수(positive)입니다.
CD 격차는 작업에 따라 달라집니다.
추가 자료가 있으면 좋겠다.
참고자료

개발자를 위한 첫시작