논문 제목:STaR: Self-Taught Reasoner Bootstrapping ReasoningWith Reasoning
저자 : Eric Zelikman, Yuhuai Wu, Jesse Mu, Noah D. Goodman
Abstract
STaR(Self-Taught Reasoner)은 소수의 논리 예제와 논리가 없는 대규모 데이터세트를 활용해 언어 모델의 복잡한 추론 능력을 점진적으로 향상시키는 기술
특징
- 소수의 논리 예제를 기반으로 질문에 대한 논리를 생성.
- 생성된 답변이 틀리면 정답을 참고하여 새로운 논리를 생성.
- 최종적으로 정답을 도출한 논리를 기반으로 모델을 미세 조정.
- 이 과정을 반복해 성능을 개선.
Introduction
문제점
기존 논리 데이터세트 구축 방식은 비용이 많이 들고 제한적
맥락 학습 기반 방법은 성능 개선 효과가 있지만 최적화된 대규모 데이터 학습에는 부족함
STaR 접근법
논리 생성: 소수의 사례를 통해 LLM이 스스로 논리를 생성하게 유도.
반복 학습: 올바른 답변을 도출한 논리를 활용해 모델을 미세 조정.
역추론: 모델이 문제를 해결하지 못하면 정답을 제공해 새로운 논리를 생성하여 데이터세트를 보완.
효과
논리 생성과 데이터 품질 향상이 상호 작용하여 성능을 점진적으로 향상.
실패한 문제도 역추론을 통해 학습 데이터로 활용.
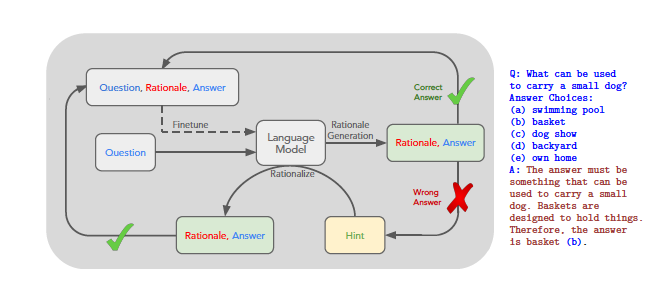
1.외부 루프
대시 라인은 STaR의 반복 학습 과정(모델 미세 조정)을 나타냅니다.
2.데이터세트 구성
질문과 정답은 데이터세트에 존재.
논리는 STaR이 생성하여 학습에 활용.
3.논리 생성 과정
모델이 질문에 대해 논리를 생성하고 답을 도출.
정답과 비교 후, 필요 시 정답 기반으로 새로운 논리를 생성.
결과적 학습 강화
그림설명
입력 데이터 (Question, Rationale, Answer)
모델은 질문(Question)을 입력으로 받고, 논리(Rationale)와 답변(Answer)을 생성
언어 모델의 역할
Rationale Generation: 질문에 대한 논리를 생성하고 답변을 도출
Fine-tuning: 생성된 논리와 답변을 바탕으로 모델을 반복적으로 학습
정답 도출 (Correct Answer)
생성된 답변이 정답과 일치하면 학습 데이터로 추가하여 모델 성능을 향상
오답 처리 (Wrong Answer)
생성된 답변이 정답과 일치하지 않으면 힌트(Hint)를 제공
힌트를 바탕으로 모델이 새로운 논리와 답변을 생성하는 Rationalize 단계를 수행
반복적 학습 과정
올바른 논리와 답변이 생성될 때까지 위 과정을 반복하며, 학습 데이터를 점진적으로 보완
예시 질문과 답변
질문: "What can be used to carry a small dog?"
정답 논리: "Baskets are designed to hold things. Therefore, the answer is basket (b)."
Method
역추론(Rationalization) 기법
문제점
모델이 학습 세트에서 새로운 문제를 해결하지 못하면 학습이 정체
이는 실패한 문제에서 직접적인 학습 신호를 얻을 수 없음
해결책: 역추론
정답 제공: 모델이 문제를 해결하지 못한 경우, 정답(ground truth)을 제공
새로운 논리 생성: 모델이 정답을 바탕으로 새로운 논리를 생성
학습 데이터 보완: 생성된 논리를 학습 데이터로 추가하여 모델의 성능을 개선
효과
실패한 문제도 학습 데이터로 활용 가능.
더 유용한 논리를 생성하여 학습 데이터의 품질과 다양성을 향상.
Experiments
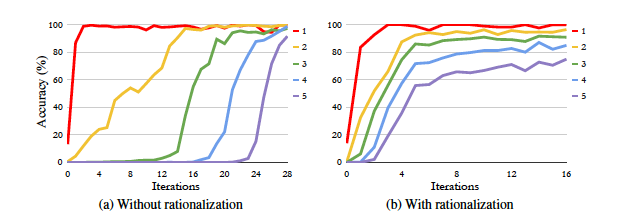
STaR은 논리화를 통해 산술 문제와 상식적 질문 응답에서 성능을 크게 향상시켰으며, 초등 수학 문제에서도 소폭의 개선
Conclusion
-
STaR(Self-Taught Reasoner)은 모델이 스스로 논리를 만들어 문제를 해결하도록 돕는 방법
간단한 문제를 먼저 풀게 하고, 틀린 문제는 정답을 바탕으로 새로운 논리를 만들어 학습합니다. 이 과정을 반복하면서 모델의 능력을 점점 더 향상 -
이 방법은 복잡한 문제에서도 모델의 성능을 크게 높일 수 있으며, 데이터를 활용해 논리를 학습하는 새로운 접근법으로 다양한 분야에 활용될 수 있음
-
하지만 처음부터 모델이 어느 정도 추론 능력을 가지고 있어야 하고, 틀린 논리를 걸러내는 문제는 추가 개선이 필요함
