논문 제목:STaR:FINETUNED LANGUAGE MODELS ARE ZERO-SHOT LEARNERS
저자 : JasonWei , Maarten Bosma , Vincent Y. Zhao , Kelvin Guu , Adams Wei Yu,Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le
Abstract
대규모 언어 모델에 자연어 지침을 활용해 파인튜닝하는 방식이 제로샷 성능을 크게 개선할 수 있음을 입증했습니다. FLAN은 기존의 GPT-3보다 더 나은 성과를 보였으며, 지침 튜닝에서 데이터셋 수, 모델 크기, 그리고 자연어 템플릿이 성공의 주요 요인임을 강조함.

- 다양한 작업을 지침으로 변환해 언어 모델을 학습시키는 방법으로, 이전에 본 적 없는 작업에서도 제로샷 성능을 향상시킴.
Introduction
대규모 언어 모델(GPT-3 등)의 제로샷 학습 성능을 개선하기 위해 instruction tuning이라는 간단한 방법을 제안합니다. 기존 언어 모델은 소수샷 학습(few-shot)에서는 우수한 성능을 보이지만, 제로샷 학습(zero-shot)에서는 사전 학습 데이터와 다른 형식의 프롬프트를 처리하기 어려워 성능이 떨어지는 문제가 있습니다.instruction tuning, 이를 통해 FLAN(Finetuned Language Net)이라는 모델을 개발했습니다.
- 모델의 크기가 클수록 instruction tuning의 효과가 더 뚜렷하게 나타나는 것으로 확인되었음.
- instruction tuning은 사전 학습–파인튜닝과 프롬프트 방식을 결합한 간단한 방법으로,FLAN은 대규모 언어 모델의 제로샷 학습 가능성을 넓히는 데 기여하며, 언어 모델의 활용 가능성을 크게 확장시킨 사례로 평가됨.
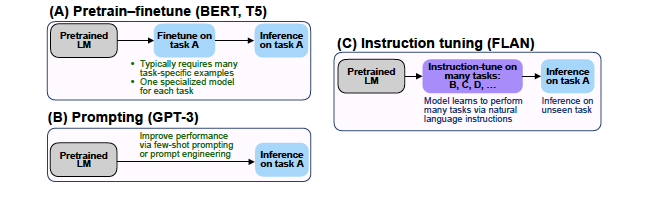
- 위 그림은 pretrain-finetune, prompting, 그리고 instruction tuning을 간단하게 나타낸것.
FLAN: INSTRUCTION TUNING IMPROVES ZERO-SHOT LEARNING
- FLAN의 목표는 언어 모델이 NLP 지침에 따라 작업을 수행하는 능력을 향상시키는 것
이를 위해 감독 학습을 통해 지침으로 설명된 작업을 학습시키고, 보지 못한 작업(unseen tasks)에서도 지침을 따를 수 있도록 함.
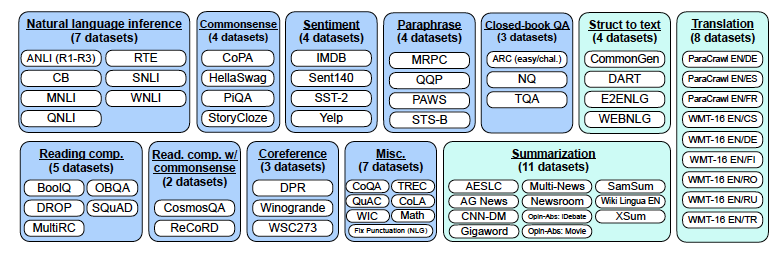
- 연구 커뮤니티의 데이터를 instructional format으로 변형해서 사용
Results
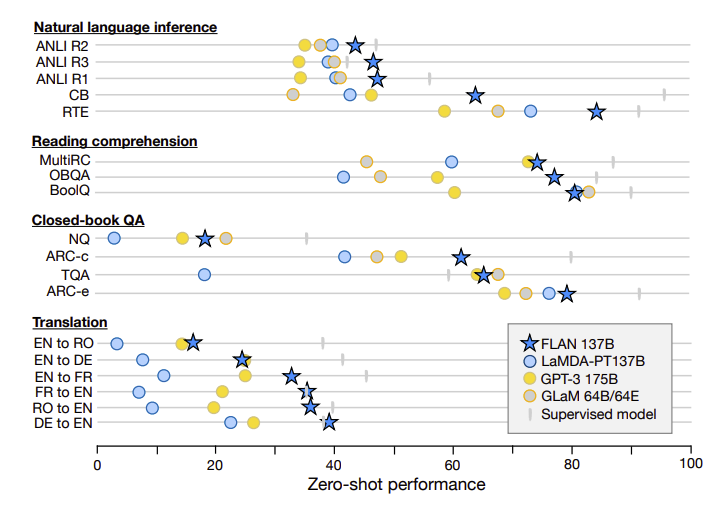
- FLAN은 제로샷 평가에서 같은 크기의 LaMDA-PT 모델을 큰 폭으로 능가했으며, GPT-3 모델과 비교해서도 한 개의 데이터셋을 제외한 모든 데이터셋에서 더 나은 성능을 보임.
- FLAN은 제로샷 평가에서 LaMDA-PT를 능가하며, LaMDA-PT와 비슷한 성능을 보이는 강력한 모델로 평가.
Ablation Studies & Further Analysis
- 저자들은 instruction tuning에 사용되는 cluster(같은 task로 묶인 dataset들의 집합)의 개수가 unseen task에서의 성능에 어떠한 영향을 미치는지를 측정
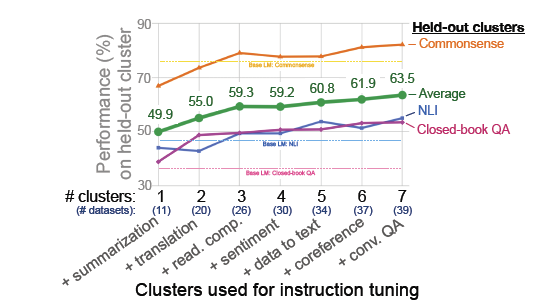
- Instruction tuning에 사용되는 cluster의 수가 많아질수록, unseen taskdptjdml 성능이 증가하는 것
- 저자들은 instruction tuning을 진행하는 base model의 크기가 tuning이 주는 성능 향상에 영향을 미치는지를 측정
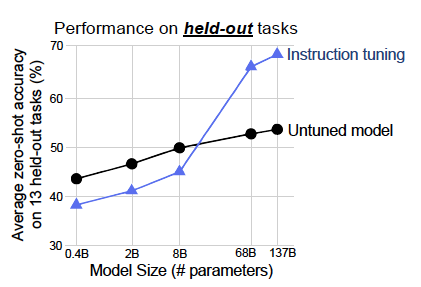
- instruction tuning의 효과를 얻기 위해서는 일정 수준 이상의 크기를 가진 model에 적용
- FLAN의 성능 향상이 과연 fine-tuning으로부터 오는 것인지, instruction으로부터 오는 것인지에 대한 측정
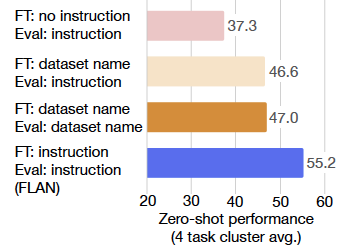
- unseen task의 zero-shot 성능은 단순한 fine-tuning이 아닌, instruction과 함께하는 fine-tuning이 중요하다는 것
참고자료
https://learn-ai.tistory.com/entry/Paper-Review-FLAN-Finetuned-Language-Models-Are-Zero-Shot-Learners
https://cartinoe5930.tistory.com/entry/FLAN-Fine-tuned-Language-Models-are-Zero-shot-Learners-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
https://velog.io/@justinshin/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-Finetuned-Language-Models-Are-Zero-Shot-Learners-2022-1
