논문 제목: Sequence Transduction with Recurrent Neural Networks
저자 : Alex Graves
Abstract
- 입력 시퀀스를 출력 시퀀스로 변환하는 ML 문제에 대해서 논의 함.
- RNN은 입력과 출력 간의 정렬이 필요해 시퀀스 변환에 제약이 있었지만, 저자들은 정렬 없이도 입력을 변환할 수 있는 end- to-end로 학습할 수 있는 확률적 sequence transduction을 제안함, 이를 통해 시퀀스 변환 문제를 효과적으로 해결할 수 있음
Introduction
-
시퀀스를 변환하고 조작하는 능력은 매우 중요함
-
왜곡에도 불구하고 식별할 수 있어야 하며, 언어 모델이 출력 시퀀스에 대한 사전 지식을 주입하는 경우, 누락된 단어나 잘못된 발음, 비어휘적 발화 등에 대해서도 강인해야 함
-
RNN은 입력과 출력 시퀀스 간의 왜곡에 강인한 표현을 학습할 수 있는 강력한 도구이나 RNN은 입력 시퀀스와 출력 시퀀스 간의 정렬이 사전에 알려진 문제로 제한됨
-
연결주의 시계열 분류(CTC)는 RNN 출력 레이어로, 입력 시퀀보다 길지 않은 모든 출력 시퀀스와 모든 정렬에 대한 분포를 정의해야하나, CTC는 출력 시퀀스가 입력보다 긴 작업을 처리하지 못하고, 출력 간의 상호 의존성을 모델링하지 않음
-
논문에서 설명하는 변환기는 모든 길이의 출력 시퀀스에 대한 분포를 정의하고, 입력-출력 및 출력-출력 간의 상호 의존성을 공동으로 모델링함으로써 CTC를 확장함
Recurrent Neural Network Transducer



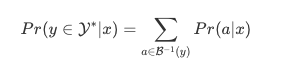


Prediction Network
- 예측 네트워크 𝐺에 대해 설명하고 있으며, 예측 네트워크 𝐺는 입력층, 출력층, 단일 은닉층으로 구성된 RNN

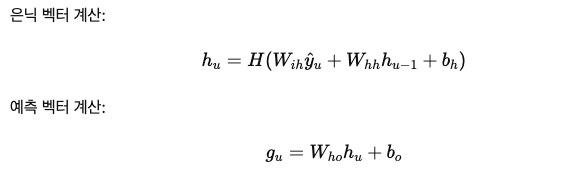

예측 네트워크는 주어진 이전 요소를 기반으로 각 출력 시퀀스의 요소를 모델링하려고 시도하므로 일반적인 다음 단계 예측 RNN과 유사하지만, "null" 예측을 수행할 수 있는 옵션이 추가됨
Transcription Network
- Transcription 네트워크 ℱF는 Bi-RNN과 2 hidden layer로 구성
- 양방향 RNN은 입력 시퀀스 𝑥를 순방향과 역방향으로 각각 스캔하여 두 개의 은닉층을 사용하고, 이 은닉층들이 하나의 출력층으로 피드 포워드가 됨
- Transcription 네트워크의 출력 차원은 K+1로 prediction 네트워크와 동일함
Output Distribution
- 1≤t≤T를 만족하는 transcription 벡터 ft와 0≤u≤U를 만족하는 prediction 벡터 gu, 그리고 레이블 k∈𝒴가 주어졌을 때, 출력의 확률을 정의
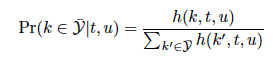
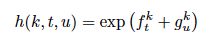
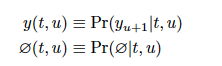
- 확률은 입력-출력 정렬을 나타내는 격자에서 사용되며, 모든 가능한 정렬에 대해 확률을 할당하며, 이를 통해 입력 시퀀스에 대한 출력 시퀀스의 전체 확률을 계산할 수 있으며, 단순 계산은 복잡하지만 효율적인 Forward-Backward Algorithm으로 해결할 수있음
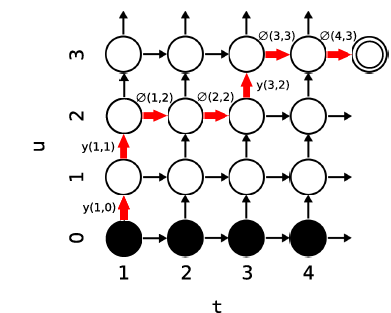
Forward-Backward Algorithm
- 전방 변수 𝛼(𝑡,𝑢)α(t,u)는 전사 시퀀스 𝑓[1:𝑡]동안 출력 시퀀스 𝑦[1:𝑢]를 출력할 확률을 나타냄
- 로그 손실 𝐿=−ln𝑃𝑟(𝑦′∣𝑥)L=−lnPr(y ′∣x)을 최소화하는 것

Training
주어진 입력 시퀀스 𝑥와 목표 시퀀스 y에 대해 모델을 훈련하는 방법
- 로그 손실 𝐿=−ln𝑃𝑟(𝑦′∣𝑥)L=−lnPr(y ′∣x)을 최소화하는 것이 목표

Testing
transducer를 테스트 데이터에서 평가할 때 출력 시퀀스 분포의 모드를 찾기 위해 고정 폭 빔 탐색(beam search)을 사용하는 방법을 설명
Experimental Results
Task and Data
- TIMIT 데이터셋사용. 훈련 세트에서 일부를 검증 세트로 사용해 총 3696개의 훈련 샘플과 192개의 테스트 샘플로 실험
- 표준 음성 전처리 기법을 사용해 특징 시퀀스를 만들었으며, 음소 오류율을 성능 측정 지표로 사용
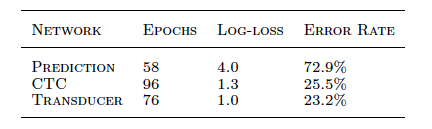
- 예측 네트워크의 오분류율과 로그 손실을 평가했으며, 로그 손실은 평균 비트 수로 변환하여 제시
Network Parameters
- prediction network는 128 크기의 LSTM 은닉층, 39개의 입력 유닛, 40개의 출력 유닛으로 구성
- transcription network는 두 개의 128 크기 LSTM 은닉층, 26개의 입력, 40개의 출력으로 구성
- 모든 네트워크는 온라인 경사 하강법(online steepest descent)으로 학습했으며, 가우시안 가중치 노이즈(Gaussian weight noise)를 사용해 과적합을 방지
- transduction network는 beam width을 4000에 설정했으며, beam search algorithm을 사용해 테스트 데이터를 처리했음
- CTC network는 pre x search decod- ing을 사용하여 테스트 세트를 transcribe함
Conclusions and Future Work
- 두 개의 RNN 네트워크로 구성된 일반적인 Transducer를 개발
- 이 구조는 음성학적인 정보와 언어학적인 정보를 모두 고려하여 추론
- Transducer를 음성인식 외에도 손글씨 인식이나 번역 등 다양한 transduction problem에 적용해볼 예정
참고: https://cosmoquester.github.io/sequence-transduction-with-recurrent-neural-networks/
