논문 제목: Sequence Transduction with Recurrent Neural Networks
저자 : Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar,Sahaj Agarwal, Hamid Palangi, Ahmed Awadallah
Abstract
소형 모델의 능력 향상을 위해서 모방학습을 통해 대형 기초 모델(LFM)이 생성한 출력을 활용하는 방법에 연구를 위해서 Orca라는 130억개의 매개변수를 가진 모델을 개발하였으며, GPT-4로 부터 설명, 단계별 사고과정, 복잡한 지시사항을 학습하였으며, ChatGPT의 지도를 받아서 더 깊은 추론능력을 학습을 하였음. 기존 최첨단 지시 기반 튜닝 모델인 Vicuna-13B보다 BBH에서 100%, AGIEval에서 42% 높은 성능을 보였고, ChatGPT와 동등한 수준에 도달함.
Introduction
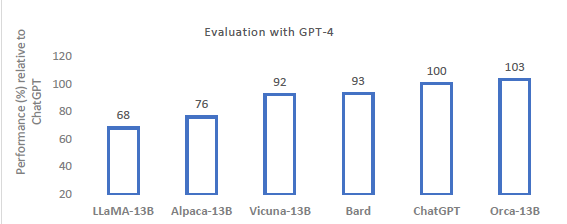
- Orca는 Vicuna 평가 세트에서 GPT-4에 의해 평가되었을 때 ChatGPT를 포함하는 다양한 foundation model을 능가하는 성능을 보여 줌

- Explanation tuning을 사용한 Orca는 다양한 전문적 및 학문적 시험에서 LFM과의 갭을 줄였음.
- Explanation Tuning이란 모델을 훈련할 때 설명(explanation)을 학습 데이터로 제공하여 모델이 더 나은 추론 능력을 갖추도록 하는 방법
대형 기초 모델(LFMs)인 ChatGPT와 GPT-4는 다양한 작업과 전문 시험에서 인간 수준의 성능을 보여주며, 모델과 데이터셋의 확장, 그리고 사용자 의도에 맞춘 학습(지도 학습과 강화 학습)에 의해 발전했음. 최근 연구들은 모델 자체가 행동을 감독하거나 다른 모델을 훈련하는 가능성을 탐구하고 있으며, ChatGPT와 GPT-4 같은 LFMs를 교사로 활용해 소형 모델(Alpaca, WizardLM, Vicuna 등)을 훈련하는 시도가 증가하고 있으나, 이러한 소형 모델들은 학습 스타일은 모방할 수 있으나, 추론 능력과 이해력 측면에서는 아직 부족한 점이 있다고 밝힘.
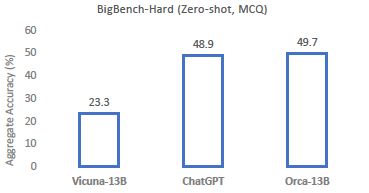
- BigBench-Hard에서 복잡한 zero-shot 추론 task에 대해 Orca는 ChatGPT와 동등한 성능을 달성했다고 보여줌.
Challenges with Existing Methods
ChatGPT와 같은 대형 기초 모델(LFMs)의 출력을 모방하는 지시 조정 연구는 작업 다양성, 쿼리 복잡성, 데이터 확장성에서 한계를 가지고 있다고 말하고 있음.
저자들은 Gudibande 등의 연구는 광범위한 모방이 방대한 데이터셋과 더 다양한 고품질 데이터가 필요하다고 주장하지만, 우리는 이러한 조건이 달성 가능하며 복잡한 제로샷 벤치마크에서 격차를 줄일 수 있음을 보여주며, Self-Instruct와 이를 변형한 Alpaca, WizardLM 같은 모델들은 지시의 다양성에 한계가 있지만, Vicuna와 Koala는 ShareGPT와 같은 커뮤니티 대화를 통해 더 인간적인 성능을 보여줌.
Simple instructions with limited diversity
Self-Instruct 과정은 초기 프롬프트로 LFM이 새로운 지시를 생성하게 하지만, 생성된 질문들이 다양성이나 복잡성 면에서 부족한 경우가 많아. Alpaca랑 WizardLM은 Self-Instruct의 변형을 쓰는데, WizardLM은 지시를 점점 더 복잡하게 만드는 Evol-Instruct 개념을 도입해서 이런 한계를 극복하려고 하고있으나, 반면에 Vicuna랑 Koala는 ShareGPT 같은 커뮤니티 대화를 통해 더 인간적인 대화와 자연스러운 지시를 제공해서 훨씬 뛰어난 성능을 보여주고 있음.
Task diversity and data scaling
ShareGPT의 인간 대화 데이터는 중요한 소스이지만, 주로 창의적 콘텐츠 생성과 정보 탐색에 치우쳐 있으며, 추론 과정을 제대로 학습하지 못하고 스타일만 모방하는 문제가 있고데이터 수집의 규모도 제한적임.
Limited imitation signals
기존 method는 teacher 모델에 의해 생성된 <query, response> 쌍으로부터의 imitation learning에 의존하며, 이것은 teacher의 추론 프로세스 추적에 너무 제한된 영향을 주게 된다.
Evaluation
평가 프로토콜이 부족하며, 그나마 많이 사용되고 인정되는 metric인 Vicuna Evaluation도 문제가 많다. auto-evaluation은 LFM과 비교해서 smaller model의 능력을 과대평가하고, 이전의 metric은 요약 및 추론 스킬이 약하다는 단점을 가지고 있다.
Key Contributions
Explanation Tuning
GPT-4의 상세한 설명을 포함한 ⟨질문, 응답⟩ 쌍을 사용해서 모델이 더 많은 학습 신호를 얻도록 했음. 그리고 시스템 지시를 통해 학습의 추론 과정을 설명하게 해서 일반적인 지시 조정보다 더 나은 학습을 유도했음.
Scaling tasks and instructions
Flan 2022 Collection을 활용해 다양한 작업과 지시를 포함하고, FLANv2를 사용해 복잡한 프롬프트를 생성해서 ChatGPT와 GPT-4에 쿼리하여 훈련 세트를 만들었음.
Evaluation
Orca의 생성, 추론, 이해 능력을 다양한 환경에서 평가했으며, GPT-4 자동 평가, 학술적 벤치마크, 전문 시험, 안전성 평가 등을 사용했으며, 마지막으로 Orca와 ChatGPT, GPT-4, 그리고 소형 모델 Vicuna의 성능을 비교한 사례 연구도 제공했음.
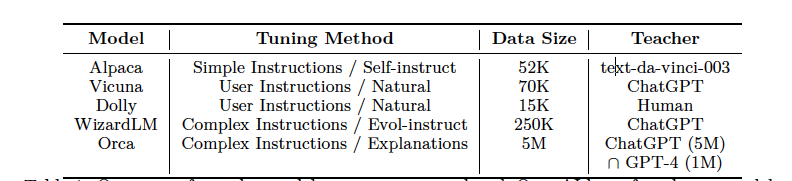
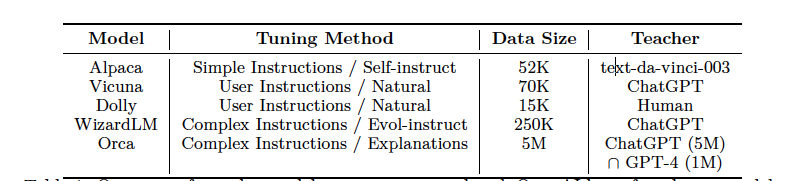
- LFM과 함께 instruction tune된 유명한 모델의 개요
Preliminaries
Instruction Tuning
Instruction tuning은 사전 학습된 언어 모델이 작업에 대한 자연어 설명과 응답 쌍으로부터 학습하도록 하는 기법이다. 예를 들어, {"instruction": "주어진 문장의 단어들을 배열하여 문법적으로 올바른 문장을 만드세요.", "input": "the quickly brown fox jumped", "output": "the brown fox jumped quickly"}와 같은 형태로 학습이 이루어집니다. 이 방법은 언어 전용 및 다중 모달 작업 모두에 적용되어 왔으며, 언어 전용 작업의 경우 FLAN과 InstructGPT 같은 모델의 zero-shot 과 few-shot 성능을 향상시켰습니다.
Role of System Instructions
기본 지시 조정(vanilla instruction-tuning)은 짧고 간결한 응답으로 구성된 입력-응답 쌍을 사용하는데, 이는 소형 모델의 훈련에 사용될 때 LFM의 추론 과정을 제대로 학습하지 못하게 한다. 하지만 최근 GPT-4와 같은 LFM에서는 시스템 지시를 사용해 모델의 행동과 응답을 안내할 수 있습니다. 시스템 지시는 자연어로 작성되며 JSON 요청에서 "system" 역할을 통해 사용자 메시지와 분리되며, 모델의 응답의 어조, 작업, 형식, 제한 사항을 지정할 수 있으며, 안전성도 개선할 수 있음.
Explanation Tuning
기존 연구의 한계를 해결하기 위해, 우리는 복잡한 지시와 풍부한 신호로 확장된 대규모의 다양한 작업 데이터를 활용
Dataset Construction
<System message, User query, LFM response>
System message
System message는 프롬프트의 시작에 위치하며, LFM에게 필수적인 맥락, 지침 등을 제공하며, 이를 통해 응답 길이, 어시스턴트의 성격, LFM의 허용 및 비허용 행동, 응답 구조 등을 조정
User query
사용자 질문은 LFM이 수행할 실제 작업을 정의하며, 다양한 사용자 질문을 위해 FLAN-v2 컬렉션을 활용함
LFM response
FLAN-v2의 5M 개의 user query는 ChatGPT의 응답을 활용하고, 그중 1M 개는 GPT-4의 응답을 수집하였음
총 16개의 시스템 메시지를 수작업으로 만들어 LFM으로부터 다양한 종류의 응답을 유도

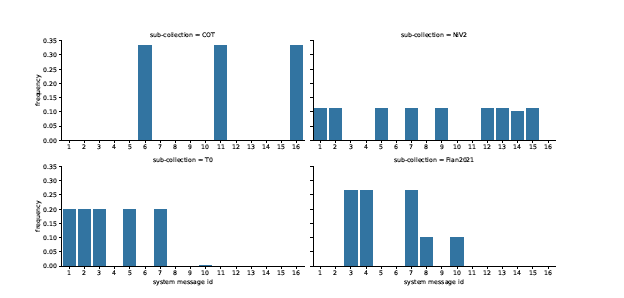
- training data의 서로 다른 모음에서 system message의 상대적 빈도
- training data의 구성
Zero-Shot CoT: 제로샷 Chain-Of-Thought (CoT) 컬렉션은 수학 문제 해결, 자연어 추론, 상식적 추론, 과학 질문 응답, 홀수 찾기 추론 등 총 18개 작업으로 구성되어 있으며, 약 15만 개의 쿼리를 포함됨. 모든 쿼리는 연쇄 추론 응답을 목표. ChatGPT와 GPT-4는 시스템 지시가 추가된 경우 인간이 작성한 응답보다 더 상세한 응답을 생성.
NiV2: 총 1560개 작업과 약 500만 개의 쿼리로 구성되어 있습니다. 각 작업에서 300개의 쿼리를 무작위로 샘플링하고, 쿼리 수가 적은 작업은 전체 데이터를 포함하여 총 44만 개의 쿼리를 얻음.
Flan 2021: 142개 작업과 62개의 데이터셋으로 구성되어 있으며, 전체 컬렉션은 매우 방대하여 추가 작업이 비용이 크고, 100만 개의 쿼리를 최대치로 각 작업에서 샘플링해 총 2,890만 개의 쿼리를 생성했으며, 이 중 250만 개의 쿼리를 샘플링함.
Orca는 먼저 ChatGPT로부터 수집한 FLAN-5M 데이터로 학습하고, 이후 GPT-4 응답이 포함된 FLAN-1M 데이터로 추가 학습였음. ChatGPT를 중간 교사로 사용한 이유는 능력 차이를 줄여 소형 모델의 모방 학습 성능을 개선하고, 비용과 시간 측면에서 ChatGPT가 GPT-4보다 빠르고 저렴하기 때문. GPT-4의 응답은 ChatGPT보다 길어서 Orca가 점진적으로 복잡한 내용을 학습하도록 도움.
Tokenization: LLaMA BPE Tokenization를 사용해 입력 예제를 처리하며, 숫자는 개별 숫자로 분리하고, 모르는 UTF-8 문자는 바이트로 분해하고, 가변 길이 시퀀스를 처리하기 위해 "PAD" 토큰을 추가했고, 최종 어휘집에는 32,001개 토큰이 포함됨.
Packing: 훈련 최적화를 위해 여러 입력 예제를 최대 2048 토큰 길이의 단일 시퀀스로 패킹하여 훈련에 사용하고, 2.7개의 예제를 한 시퀀스에 포함시켜 일관된 시퀀스 길이를 유지하도록 패딩 토큰을 추가.
Loss: 교사 모델이 생성한 토큰에 대해서만 손실을 계산하여, 시스템 메시지와 작업 지시에 따라 응답을 생성하도록 훈련
Compute: 20개의 NVIDIA A100 GPU(80GB 메모리)를 사용해 훈련했으며, FLAN-5M에서 4번의 에포크 동안 160시간, FLAN-1M에서는 40시간, ChatGPT와 GPT-4 데이터를 수집하는 데 각각 2주와 3주가 소요되었습니다.
Experiment Setup
Orca를 다양한 능력 평가를 위해 Text-Davinci-003, ChatGPT, GPT-4, Vicuna와 비교함.
Text-Davinci-003과 ChatGPT(GPT-3.5-turbo) 는 텍스트 생성 및 대화에 최적화된 모델들이며, GPT-4는 더 복잡한 작업에서 인간 수준의 성능을 보였으며, Vicuna는 LLaMA를 기반으로 사용자가 공유한 대화를 통해 훈련된 오픈소스 챗봇임.
- Orca 평가 벤치마크
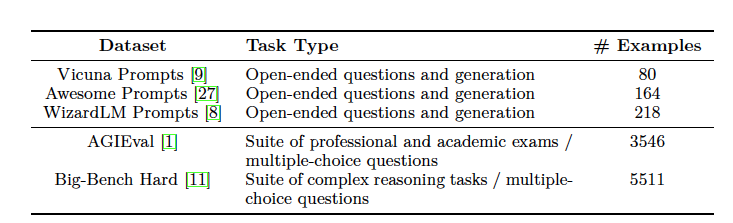
- Orca의 개방형 생성 능력과 복잡한 추론 작업을 이해하고 추론하는 능력을 평가하기 위해 사용된 작업들을 상세히 설명
Vicuna Prompts: Vicuna에서 제안된 원래 프롬프트들로, 80개의 프롬프트가 일반, 지식, 롤플레이, 상식,반사실적 상황, 코딩, 수학, 글쓰기 능력을 포함한 9개의 기술로 나누어져 있음
Awesome Prompts:주로 ChatGPT 모델의 참고로 사용되는 프롬프트 예제 모음으로, 번역, 요약, 분석 등 다양한 작업을 포함. 이 Prompt는 라이프 코치, 스타트업 기술 변호사, 점성가, 체스 플레이어, 통계학자, 메모 작성 보조자 등 164개의 역할을 기반으로 함
WizardLM Prompt: 실제 작업을 기반으로 한 Prompts 예제 모음이며, 이 프롬프트들은 오픈소스 프로젝트, 플랫폼, 포럼에서 수집되었습니다. 이들은 29개의 독특한 기술과 각 프롬프트의 난이도로 나누어져 있으며, 수학, 학술적 글쓰기, 디버깅, 코드 생성, 추론 능력 등 인간 수준의 지능의 주요 요구 사항을 고려.
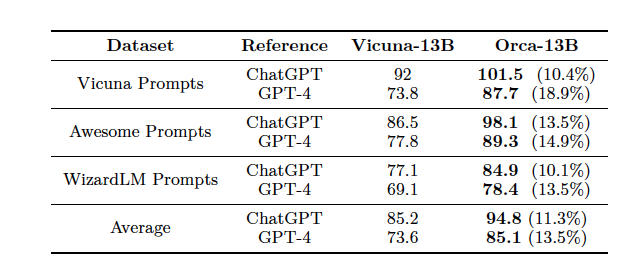
- 추론 능력 평가에서는 AGIEval과 Big-Bench Hard (BBH)를 사용하여 객관식 질문에 대한 모델의 성능을 평가
- AGIEval은 인간 중심의 입학 및 자격 시험에서 파생된 벤치마크이며, BBH는 대형 언어 모델의 능력과 한계를 측정하기 위한 어려운 작업들로 구성. 제로샷 설정에서 CoT 없이 평가를 진행하며, 객관식 질문에 대해 AGIEval의 prompt 형식과 동일한 파싱 논리를 사용해 모델의 응답을 일관되게 처리함.
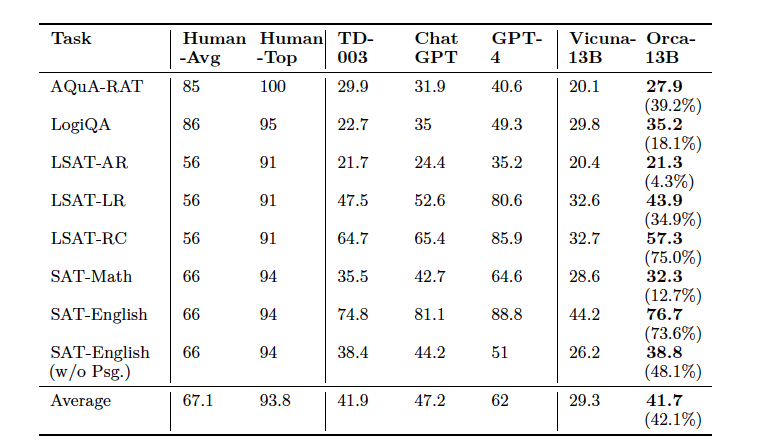
- text-davinci-003, ChatGPT, GPT-4, Vicuna, Orca의 AGIEval benchmark의 zero-shot 성능 비교
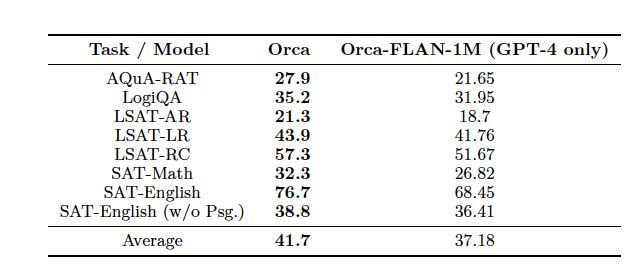
- AGIEval 벤치마크에서 서로 다른 system message를 사용한 Orca의 zero-shot 성능 비교
100개의 랜덤 ChatGPT-beats-Orca & Orac-beats-ChatGPT 샘플의 분석
Domain Knowledge: Tesla의 배터리 문제 같은 전문적인 도메인에 대한 문제 해결은 전문적인 지식을 필요로 하기에 둘 다 떨어지는 성능을 보여줌.
Complex Reasoning: 복잡한 추론에 대해서 둘 다 떨어지는 모습을 보여줌.
Long Context: ChatGPT는 Orca보다 long context를 모델링하는데 더 우수함.
Geometric Reasoning: 기하학적 추론에 대해 각각은 살짝씩 떨어지는 성능을 보여줬다. 이것은 두 모델 간의 기하학적 추론 성능 갭을 가리킴.
LaTeX Reasoning: LaTeX 유형의 추론에서 떨어지는 모습을 보여줌.
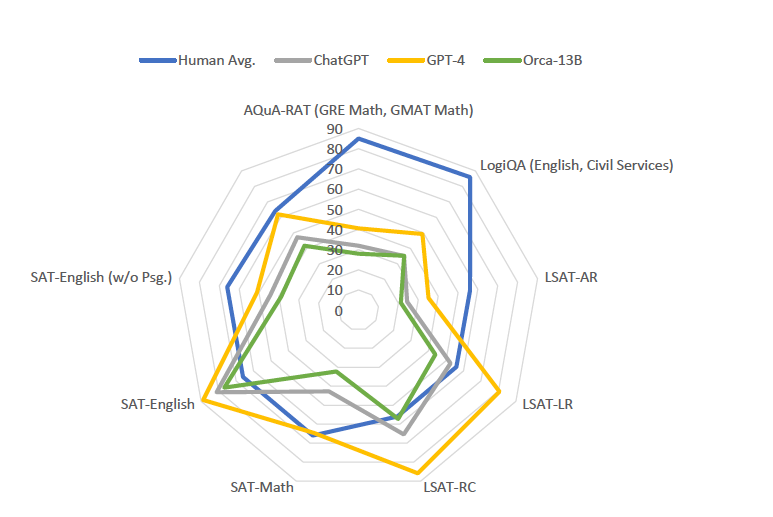
- AGIEval 벤치마크에서 Orca, ChatGPT, GPT-4의 성능
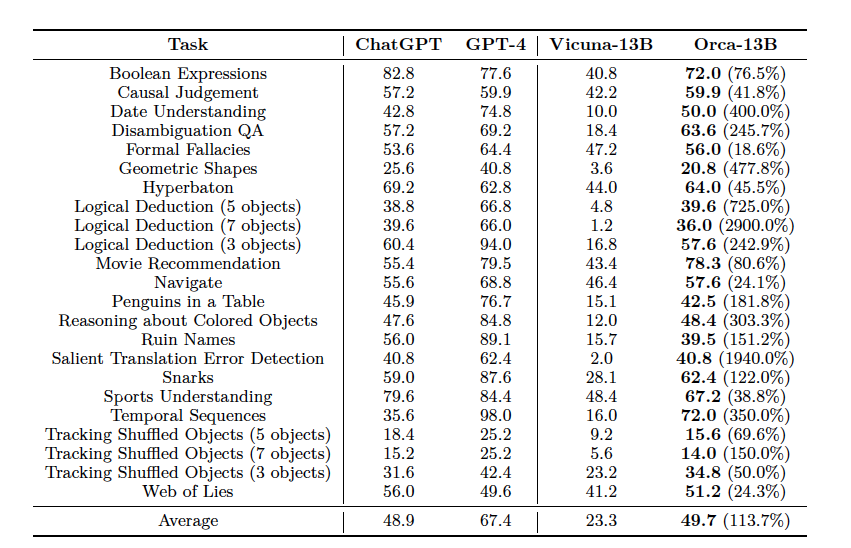
- Big-Bench Hard (BBH) 벤치마크에서 Orca의 제로샷 성능 비교
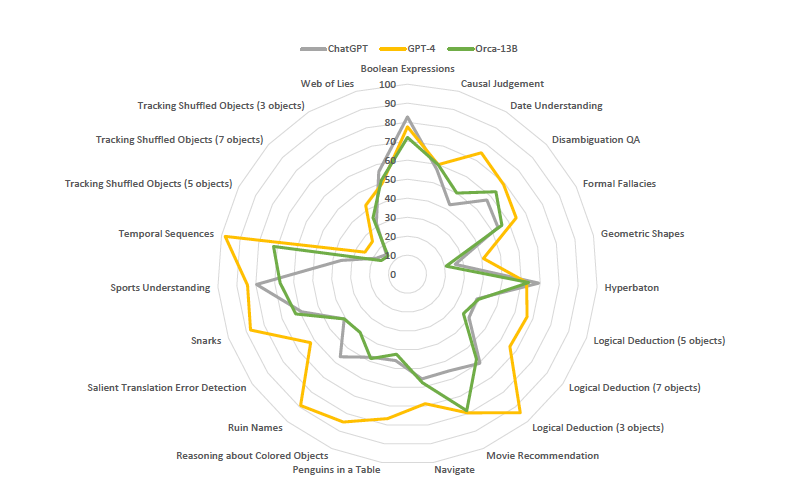
- Big-Bench에서 서로 다른 task에 대한 GPT-4, ChatGPT, Orca의 성능
Limitations
Orca는 LLaMA 모델 계열을 기반으로 구축되어, 다음과 같은 대형 언어 모델의 일반적인 한계를 가지고 있음:
데이터 편향: 대규모 데이터로 훈련된 언어 모델은 원본 데이터에 존재하는 편향을 그대로 가질 수 있어, 편향적이거나 공정하지 않은 출력을 생성할 가능성이 있음.
맥락 이해 부족: 언어 이해와 생성에서 뛰어난 성능을 보이지만, 현실 세계 이해 능력은 제한적이어서 부정확하거나 비논리적인 응답이 발생할 수 있음
투명성 부족: 모델의 복잡성과 크기로 인해 내부의 작동 원리나 특정 응답의 이유를 이해하기 어려워, 블랙박스처럼 작동함.
유해 콘텐츠: 언어 모델은 여러 유형의 유해 콘텐츠를 생성할 수 있으며, 이를 예방하기 위해 다양한 콘텐츠 검열 서비스를 사용하는 것이 권장됩니다. AI 기술의 콘텐츠 피해를 줄이기 위한 규제와 표준이 필요하며, 연구와 오픈소스 커뮤니티의 역할이 중요함
환각 현상: 모델이 잘못된 정보를 생성하는 환각 현상을 방지하기 어려우므로, 중요한 결정에 모델을 전적으로 의존하는 것은 주의해야 합니다. 특히 작은 모델은 기억 용량 부족으로 인해 더 환각에 취약할 수 있음.
악용 가능성: 적절한 안전 장치가 없으면, 이 모델들은 허위 정보나 유해 콘텐츠를 생성하는 데 악용될 위험이 있음.
Orca의 설명 조정 데이터의 한계:
제로샷 설정: Orca는 제로샷 설정을 시뮬레이션하는 데이터로 훈련되었으며, 다중 회차 대화, 인컨텍스트 학습, 퓨샷 학습 등 다른 환경에서의 성능은 테스트되지 않았음.
데이터 분포: Orca의 성능은 튜닝 데이터의 분포와 강하게 상관될 가능성이 있어, 훈련 데이터에 적게 포함된 수학, 코딩, 추론 등의 분야에서는 정확도가 제한될 수 있음.
시스템 메시지: 다양한 시스템 지시로 훈련된 Orca는 모델 크기에 따른 확률적 특성으로 인해 비결정적인 응답을 생성할 수 있음.
GPT-4 행동: Orca는 GPT-4를 모방하여 훈련되었기 때문에, 교사 모델의 장단점을 모두 상속할 수 으며, GPT-4 훈련 과정의 안전 조치 덕분에 Orca도 그 이점을 얻을 수 있지만, 위험에 대한 더 나은 정량화가 필요함.
Conclusions
소형 언어 모델을 GPT-4와 같은 대형 기초 모델에 맞추기 위한 훈련 과정과 현재 상태를 다루며, 연구에 따르면 소형 모델의 능력은 종종 과대평가되며, Explanation Tuning이 효과적인 방법이지만 더 정교한 방법 개발이 필요. 데이터 크기와 품질이 성능에 중요한 역할을 하며, Orca는 다른 소형 모델보다 우수하지만 GPT-4와의 격차는 여전히 크다. 단계별 설명을 통한 학습은 모델 품질을 크게 향상시킬 수 있으며, 이러한 통찰이 향후 더 강력한 평가 방법, 정렬 및 후처리 기법 개발에 기여하기를 기대하고 있음.
