논문 제목:ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
저자 : Samyam Rajbhandari, Je Rasley,Olatunji Ruwase,Yuxiong He
Abstract
대규모 딥러닝 모델은 높은 정확도를 제공하지만, 수십억에서 수조 개의 매개변수를 학습하는 것은 한계가 있습니다. 이를 해결하기 위해, 저자들은 메모리를 최적화하여 학습 속도를 대폭 개선하고 더 큰 모델을 효율적으로 학습할 수 있게 하는 Zero Redundancy Optimizer (ZeRO)라는 새로운 솔루션을 개발했습니다. ZeRO는 데이터 병렬 및 모델 병렬 학습에서 메모리 중복을 제거하면서도 낮은 통신 볼륨과 높은 계산 세분성을 유지하여, 장치 수에 비례해 모델 크기를 효율적으로 확장할 수 있습니다.
Extended Introduction
딥러닝(DL) 모델이 점점 커지면서 모델 크기의 증가가 정확도 향상에 크게 기여하고 있습니다. 자연어 처리(NLP) 분야에서는 BERT-large(3억 개 파라미터), GPT-2(15억 개), Megatron-LM(83억 개), T5(110억 개)와 같은 대규모 모델들이 등장했습니다. 모델 크기가 수십억에서 수조 개의 파라미터로 계속 확장될 수 있도록 하려면, 이러한 모델을 학습하는 과정에서의 한계에 직면하고 있습니다. 대규모 모델은 단일 장치(예: GPU나 TPU)의 메모리에 담을 수 없고, 단순히 장치를 더 추가하는 것만으로는 학습을 효과적으로 확장할 수 없습니다.기본적인 데이터 병렬성(DP)은 장치별 메모리 사용량을 줄이지 않으며, 32GB 메모리를 가진 현재 세대 GPU에서는 14억 개 이상의 파라미터를 가진 모델에서 메모리가 부족해집니다.
저자들은 이 두가지 기준에서 생각하였음
1. 대규모 모델에서 대부분의 메모리는 옵티마이저 상태(Adam의 모멘텀 및 분산 등), 그라디언트, 파라미터와 같은 모델 상태가 차지합니다.
2. 나머지 메모리는 활성화, 임시 버퍼, 사용 불가능한 조각 메모리 등, 우리가 잔여 상태(residual states)라고 부르는 것이 소비합니다.
-
DP는 계산과 통신 효율이 높지만 메모리 효율이 낮고, MP는 메모리 효율이 높지만 계산과 통신 효율이 떨어집니다. DP는 모든 프로세스에 모델 상태를 복제하여 메모리를 낭비하고, MP는 상태를 분할해 메모리를 절약하지만 통신 비용이 증가하여 확장성이 낮아집니다.
-
저자들은 ZeRO-DP는 DP의 계산/통신 효율성을 유지하면서도 MP의 메모리 효율성을 달성합니다. ZeRO-DP는 모델 상태를 복제하는 대신 분할하여 데이터 병렬 프로세스 간의 메모리 상태 중복을 제거하고, 학습 중 동적인 통신 일정을 사용하여 DP의 계산 세분성과 통신량을 유지합니다.
1) Optimizer State Partitioning(옵티마이저 상태 분할) (Pos): 메모리가 4배 줄어들며, DP와 동일한 통신량을 유지
as DP;
2) Add Gradient Partitioning(그라디언트 분할 추가) (Pos+g): 메모리가 8배 줄어들며, DP와 동일한 통신량을 유지
as DP;
3) Add Parameter Partitioning(파라미터 분할 추가) (Pos+g+p):DP 정도(Nd)에 따라 메모리 감소가 선형으로 증가
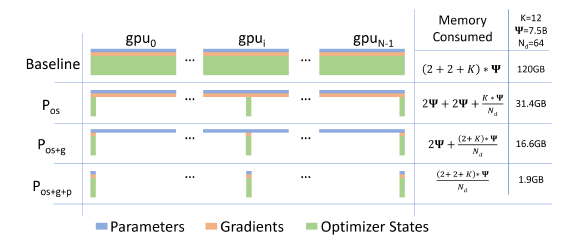
모델 상태의 장치당 메모리 소비를 세 가지 ZeRO-DP 최적화 단계와 비교한 내용
- ZeRO-DP가 모델 상태의 메모리 효율을 높인 후, 활성화, 임시 버퍼, 사용 불가한 메모리 조각이 메모리의 또 다른 병목이 될 수 있습니다. 이를 해결하기 위해, 우리는 ZeRO-R을 개발하여 이 세 가지 요소로 인해 소모되는 메모리를 각각 최적화
1) 활성화 메모리 최적화: (역전파 수행을 위해 순전파에서 저장되는 활성화 메모리) 체크포인팅이 일부 도움이 되지만, 대규모 모델에는 충분하지 않음을 발견했습니다. ZeRO-R은 활성화 분할을 통해 기존 MP 접근법에서의 활성화 복제를 제거하고, 필요할 때 활성화 메모리를 CPU로 오프로드합니다.
2)임시 버퍼 크기 최적화: ZeRO-R은 메모리와 계산 효율성 간 균형을 맞추기 위해 임시 버퍼의 적절한 크기를 정의합니다.
3) 메모리 조각화 방지: 학습 중 다양한 텐서의 수명이 달라짐에 따라 조각화된 메모리가 발생하며, 조각화로 인해 충분한 여유 메모리가 있어도 메모리 할당 실패가 발생할 수 있습니다. ZeRO-R은 텐서의 수명에 따라 메모리를 적극적으로 관리하여 메모리 조각화를 방지합니다.
ZeRO가 DP의 메모리 비효율을 제거하면서, 이제 MP가 여전히 필요한가?
1) ZeRO-R과 함께 사용하면, MP는 매우 큰 모델의 활성화 메모리 사용량을 줄일 수 있습니다.
2) 활성화 메모리가 문제가 되지 않는 작은 모델의 경우, 데이터 병렬만 사용하여 집계된 배치 크기가 너무 커져 좋은 수렴을 얻기 어려울 때 MP가 도움이 될 수 있습니다. 이 경우, ZeRO와 MP를 결합하여 적절한 집계 배치 크기로 모델을 맞출 수 있습니다.
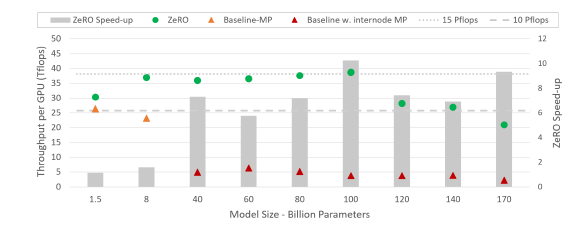
- ZeRO의 학습 처리량 및 속도 향상은 최신 기술(SOTA) 기준과 비교하여 다양한 모델 크기에 따라 변화
Related Work
Model Parallelism, Data Parallelism 설명부분
Where Did All the Memory Go?
 참고자료
참고자료
ZeRO: Insights and Overview
ZeRO는 두 가지 최적화 세트를 가지고 있습니다.
i) 모델 상태의 메모리 사용량을 줄이는 ZeRO-DP
ii) 잔여 메모리 소비를 줄이는 ZeRO-R
ZeRO가 효율성을 유지하면서 메모리 사용량을 줄일 수 있도록 하는 최적,여기서 효율성은 핵심 요소입니다. 이 제한이 없으면, 모든 파라미터 상태를 CPU 메모리로 이동시키거나 MP의 정도를 임의로 늘리는 것과 같은 단순한 방법으로도 메모리 사용량을 줄일 수 있기 때문입니다.
Insights and Overview: ZeRO-DP
a) DP는 MP보다 확장 효율성이 높습니다. MP는 계산의 세분성을 줄이고 통신 오버헤드를 증가시키기 때문에, 일정 수준을 넘어서면 낮은 계산 세분성이 GPU당 효율을 감소시키고, 증가한 통신 오버헤드가 GPU 간의 확장성을 저해합니다. 특히 노드 경계를 넘을 때 이러한 문제는 더욱 두드러집니다. 반대로, DP는 높은 계산 세분성과 낮은 통신량을 갖추고 있어 훨씬 높은 효율성을 제공합니다.
b) DP는 메모리 효율이 낮습니다. 모델 상태가 모든 데이터 병렬 프로세스에 중복되어 저장되기 때문입니다. 반면 MP는 모델 상태를 분할하여 메모리 효율을 얻습니다.
c) DP와 MP 모두 학습 과정 전체에 필요한 모델 상태를 항상 유지하지만, 모든 상태가 항상 필요한 것은 아닙니다. 예를 들어, 각 층의 파라미터는 해당 층의 순전파와 역전파 동안에만 필요합니다.
이러한 통찰에 기반하여 ZeRO-DP는 DP의 학습 효율성을 유지하면서 MP의 메모리 효율성을 달성합니다.
Insights and Overview: ZeRO-R
1) 활성화 메모리 감소: ZeRO-R은 GPU 간 활성화 체크포인트를 분할하여 MP에서 발생하는 활성화 메모리의 중복을 제거합니다. 필요한 경우에만 allgather로 활성화 데이터를 재구성하며, 매우 큰 모델에서는 활성화 데이터를 CPU 메모리로 이동하여 높은 효율성을 유지합니다.
2) 임시 버퍼 관리: 모델 크기가 커져도 메모리 소비가 폭발적으로 증가하지 않도록 상수 크기의 버퍼를 사용하여 임시 버퍼를 관리합니다.
3) 메모리 조각화 관리: 단기 및 장기 메모리 객체가 섞여 발생하는 메모리 조각화를 방지하기 위해, ZeRO는 활성화 체크포인트와 그라디언트를 연속 메모리 버퍼로 이동시켜 메모리를 효율적으로 사용하고 할당 시간을 줄입니다.
Deep Dive into ZeRO-DP
ZeRO-DP 목적: 기존 데이터 병렬(DP) 방식은 모델 상태(옵티마이저 상태, 그라디언트, 파라미터)를 장치마다 복제하여 메모리 소비가 크지만, ZeRO-DP는 이를 분할하여 메모리 사용량을 줄입니다.
세 가지 최적화 단계:
Pos (Optimizer State Partitioning): 옵티마이저 상태를 DP 프로세스에 따라 분할하여 메모리 소비를 최대 4배 절감합니다.
Pg (Gradient Partitioning): 각 파티션의 그라디언트를 DP 프로세스에 따라 축소하여 메모리 소비를 8배까지 줄입니다.
Pp (Parameter Partitioning): 파라미터도 각 파티션에 따라 분할해 저장하여, Nd배로 메모리 소비를 줄입니다.
메모리 절감 효과: 7.5억 개의 파라미터 모델의 경우, 64-way DP를 사용한 ZeRO-DP의 Pos+g+p 최적화로 메모리 요구량이 120GB에서 1.9GB로 감소합니다. ZeRO를 사용하면 DP만으로는 실행할 수 없는 대규모 모델을 충분한 장치 수로 실행할 수 있습니다.
😃모델 크기에 대한 영향: ZeRO-DP는 DP만으로 학습할 수 있는 모델 크기를 크게 확장하며, Nd = 1024일 때 1조 개 이상의 파라미터 모델도 학습할 수 있습니다.
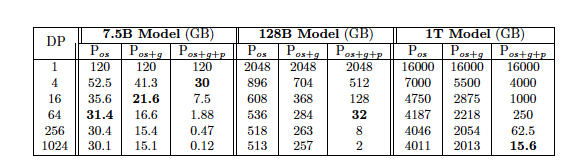
Deep Dive into ZeRO-R
Pa (분할된 활성화 체크포인팅)
활성화 메모리를 분할하여 복제된 활성화 중복을 제거합니다. 각 층의 활성화는 필요 시에만 all-gather로 재구성됩니다.
매우 큰 모델에서는 활성화 체크포인트를 CPU로 오프로드해 메모리 사용을 최소화할 수 있습니다.
CB (고정 크기 버퍼)
대규모 모델에서 모델 크기에 비례해 임시 버퍼 크기가 폭발적으로 증가하는 것을 방지하기 위해 성능 효율적인 고정 크기 버퍼를 사용합니다.모델 크기와 관계없이 일정한 크기의 버퍼로 메모리 효율을 유지하면서도 계산 효율성을 확보할 수 있습니다.
MD (메모리 조각화 방지)
활성화 체크포인팅과 그라디언트 계산 과정에서 발생하는 메모리 조각화를 방지합니다.
장기 및 단기 메모리 객체의 혼재로 인한 조각화를 방지하기 위해, 활성화 체크포인트와 그라디언트를 사전 할당된 연속 메모리로 이동시킵니다.이는 더 큰 모델과 배치 크기로 학습할 수 있게 하고, 메모리 할당 속도를 개선해 효율성을 높입니다.
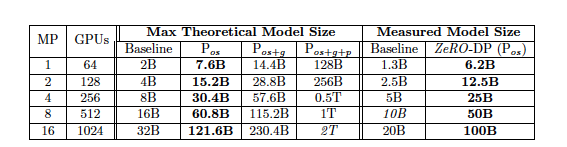
Communication Analysis of ZeRO-DP
ZeRO가 메모리 중복을 제거하여 모델 크기를 확장하는 만큼, 통신량을 메모리 효율성과 교환하는지 의문이 생길 수 있습니다. 즉, ZeRO 기반 DP 접근 방식의 통신량이 기본 DP와 비교해 어떤지를 묻는 것입니다. 답변은 두 가지로 나뉩니다.
i) ZeRO-DP는 Pos와 Pg를 사용할 때 최대 8배의 메모리 감소를 가능하게 하면서도 추가 통신이 발생하지 않습니다.
ii) ZeRO-DP는 Pos와 Pg에 더해 Pp를 사용할 때 최대 1.5배의 통신이 발생하지만, 메모리 사용량을 Nd배 더 줄입니다.
결론 : 이것을 사용해서 메모리를 줄여서 자원을 효과적으로 사용했다.
참고:https://coniverse.tistory.com/m/entry/DeepSpeed-%EB%85%BC%EB%AC%B8-ZeRO-Memory-Optimization-Towards-Training-A-Trillion-Parameter-Models-%EB%A6%AC%EB%B7%B0
논문링크:https://arxiv.org/abs/1910.02054
