논문 제목:PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
저자 : Yanli Zhao, Andrew Gu, Rohan Varma,그밖에.....
Abstract
본 논문은 PyTorch Fully Sharded Data Parallel (FSDP)를 대규모 모델 학습을 위한 산업 수준의 솔루션으로 소개를 위한 논문. FSDP는 PyTorch의 핵심 구성 요소들과 공동 설계되어 사용자 경험을 개선하고 학습 효율성을 높이며, 다양한 하드웨어에서 자원 활용을 최적화. 실험 결과, FSDP는 기존의 분산 데이터 병렬 처리와 비슷한 성능을 내면서도 더 큰 모델을 지원하고, TFLOPS 측면에서 거의 선형적인 확장성을 보여줌
Introduction
이 논문은 대규모 신경망 모델의 빠른 성장과 관련된 문제점을 다루고 있으며, 대규모 모델은 혁신을 촉진하지만, 이를 학습하기 위한 효율적이고 산업 수준의 도구가 필요하다. 파이프라인 병렬 처리, 텐서 병렬 처리, 제로 중복 병렬 처리 등 다양한 기술이 대규모 모델 학습에 기여해왔지만, 특정 모델에만 적용되거나 프레임워크 변화에 취약한 문제점이 있으며, 따라서 기계 학습 프레임워크와 공동 설계된 본질적이고 사용자 정의 가능한 솔루션이 필요하다고 여겨지고 있음
대규모 모델 학습을 가능하게 하는 PyTorch Fully Sharded Data Parallel (FSDP)을 소개함. FSDP는 모델 파라미터를 분할(sharding)하여 학습을 수행하는 방식으로, DeepSpeed ZeroRedundancyOptimizer 기법에서 영감을 받았지만 PyTorch의 다른 구성 요소와 조화롭게 재설계되었으며, FSDP는 모델을 더 작은 단위로 분할하고 각 단위 내의 모든 파라미터를 평탄화한 후 분할. 이러한 분할된 파라미터는 계산 전에 필요에 따라 통신되고 복구되며, 이후 즉시 폐기됨. 이 접근 방식 덕분에 FSDP는 한 번에 하나의 단위에서만 파라미터를 물리화할 필요가 있어 메모리 소비를 크게 줄일 수 있음.
BACKGROUND
PyTorch는 머신 러닝 프로젝트의 핵심 도구로 자리 잡았으며, Tensor 객체를 통해 데이터를 저장하고 조작. 각 모듈은 입력을 출력으로 변환하며, Linear 모듈은 가중치와 편향을 사용해 출력 값을 생성. 데이터 크기와 모델 복잡성이 커짐에 따라, PyTorch 기반 응용 프로그램에 산업 수준의 분산 학습 프레임워크가 필요해졌으며, 이 섹션에서는 PyTorch의 분산 학습 기능 발전을 설명하고 있음
대규모 모델 학습을 위한 세 가지 접근 방식인 Model Replication, Model Partitioning,Model Sharding
-
모델 복제(Model Replication):DistributedDataParallel(DDP)은 모델 복제를 통해 각 장치에 동일한 모델을 복제하고 그래디언트를 동기화하지만, 모든 파라미터가 GPU 메모리에 맞아야 하는 제한이 있어 대규모 모델에는 적합하지 않음.
-
모델 분할(Model Partitioning): 파이프라인 병렬 처리와 Tensor RPC는 모델을 작은 단위로 나누어 여러 장치에 분배하지만, 모델을 수정해야 하거나 특정 구조로 제한되는 단점이 있음.
-
모델 샤딩(Model Sharding): 모델 파라미터를 샤딩하여 메모리 사용을 줄이고 대규모 모델을 지원하며, FSDP는 필요할 때 파라미터를 통신하는 방식을 사용하며, 이 방식은 대다수의 대규모 모델 학습에 적합.
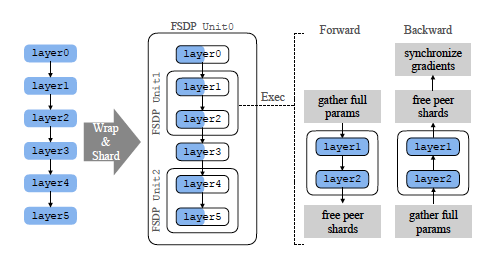
SYSTEM DESIGN
FSDP는 대규모 모델 학습을 위해 모델 파라미터를 샤딩하여 메모리 사용을 줄이며, 모델을 작은 단위로 나누고, 각 단위에 대해 비분할된 파라미터와 그래디언트만 계산할 때 필요로 하며, 나머지 단위는 샤딩된 상태로 유지합니다. 전방 및 역방향 계산 시, 필요한 파라미터를 수집하고 계산 후 샤드를 해제하여 메모리 부담을 줄이며, 이를 통해 FSDP는 대규모 모델을 단일 GPU에 맞지 않는 경우에도 효율적으로 학습할 수 있음.
-
모델 초기화(Model Initialization): FSDP는 연기된 초기화를 도입하여 초기화를 "가짜" 장치에서 먼저 수행하고, 이후 GPU에서 실제로 초기화 작업을 재실행을 통해 GPU 메모리 사용 없이 대규모 모델을 생성하고 초기화할 수 있음. 초기화 과정에서도 한 번에 하나의 단위만 물리화하고 샤딩하여 메모리 사용을 줄임.
-
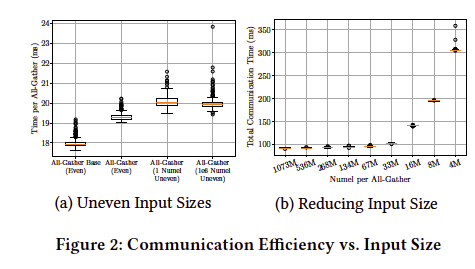
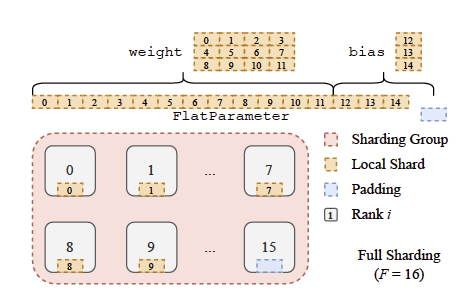
샤딩 전략(Sharding Strategies): FSDP는 완전 복제부터 완전 샤딩까지 다양한 샤딩 전략을 제공, 완전 샤딩은 메모리 사용량을 최소화하지만 통신 오버헤드가 높으며, FSDP는 이러한 통신을 효율적으로 수행하기 위해 큰 FlatParameter로 파라미터를 통합하고 이를 균등하게 샤딩함.
-
평탄화-연결-청크 알고리즘(flatten-concat-chunk algorithm): 각 파라미터를 샤딩하여 메모리 사용을 줄이면서도 통신 효율을 극대화하는 알고리즘입니다. 사용자는 메모리 사용량과 처리량 간의 트레이드오프를 조정할 수 있습니다.
-
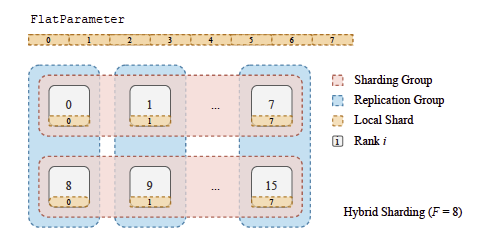
하이브리드 샤딩(Hybrid Sharding): 샤딩과 복제를 결합하여 메모리 사용과 통신 간의 균형을 맞추는 전략으로, 데이터센터 로컬리티를 활용해 크로스 호스트 트래픽을 줄입니다. 특히 중간 크기 모델에 적합하며, 메모리 부족 문제를 해결하면서도 메모리 낭비를 방지함.
올바른 그래디언트 전파: FSDP의 FlatParameter와 그 그래디언트는 원래 파라미터와 그 그래디언트의 기본 저장소를 소유함. 전방 계산 전에 FSDP는 torch.split()과 torch.view()를 사용하여 원래 파라미터가 비샤딩된 FlatParameter를 참조하도록 설정하여 올바른 그래디언트 전파를 보장
그래디언트 감소: FSDP는 FlatParameter의 그래디언트가 완료되면 실행되는 그래디언트 후크를 등록하여 그래디언트 감소를 포함한 후방 처리 논리를 수행
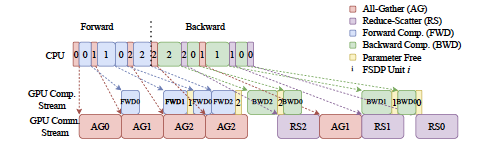
통신 최적화:
통신과 계산 중첩: 별도의 CUDA 스트림을 사용해 AllGather를 실행하여 계산과 통신을 겹칩
역방향 프리페칭: ReduceScatter 전에 AllGather를 미리 발행하여 통신 지연을 방지
전방 프리페칭: 반복 간 정적인 계산 그래프를 이용해 다음 AllGather를 미리 발행
그래디언트 누적: 통신 포함 또는 비포함 방식으로 그래디언트를 누적하여 처리량을 조절
메모리 관리:
PyTorch의 캐싱 할당기: 빈번한 메모리 할당과 해제를 줄이기 위해 캐싱 할당기를 사용하지만, 생성자와 소비자 스트림 간 메모리 재사용이 어려워 성능 저하가 발생할 수 있음
속도 제한기: CPU 스레드를 지연시켜 메모리 블록의 재사용을 보장하고 통신과 계산을 겹쳐 효율성을 높임
IMPLEMENTATION
사용자는 FSDP에 접근하기 위해 두 가지 API를 사용할 수 있습니다: FullyShardedDataParallel model wrapper 와 fully_shard module annotator입니다. 전자는 전체 모델을 FSDP 단위로 감싸고, 후자는 FSDP 로직을 후크로 설치하여 모델 구조와 파라미터 이름을 유지함.
초기화
FSDP는 대규모 모델의 효율적인 초기화를 위해 두 가지 추가 옵션을 제공합니다:
GPU에서 비샤딩 모델 초기화: GPU 메모리 내에서 전체 모델을 초기화한 후 FSDP로 넘깁니다. 이후 옵티마이저를 인스턴스화하여 메모리 사용량을 줄임.
CPU에서 비샤딩 모델 초기화: GPU 메모리 용량을 초과하는 모델은 CPU 메모리에서 전체적으로 초기화하고, GPU로 단계별로 전송하여 파라미터를 샤딩함. 이 방법은 큰 모델을 처리할 수 있지만 CPU의 메모리 대역폭과 병렬 처리 성능이 제한적이어서 속도 저하가 발생할 수 있습니다. 따라서 사용자들은 종종 지연된 초기화를 선호
평탄화 파라미터(Flat Parameters)
FlatParameter 클래스는 nn.Parameter에서 상속받으며, FSDP는 FlatParamHandle 클래스를 사용해 개별 FlatParameter 인스턴스를 관리합니다. FSDP는 모델의 정적 nn.Module 구조를 활용하여 FlatParameter를 구성하며, 모든 파라미터가 주석된 nn.Module에 할당됩니다. 또 다른 접근 방식은 실행 순서를 관찰하고 이를 바탕으로 FlatParameter를 동적으로 재구성하는 것
런타임
FSDP는 로컬 모델 인스턴스에 통신 작업을 추가하여 그래디언트를 줄이고 파라미터를 수집합니다. 통신 작업의 시점을 맞추는 것이 올바른 결과와 효율성을 위해 매우 중요. 통신 관련 코드를 모델의 전방 전달에 추가하기 위해, FullyShardedDataParallel nn.Module 래퍼는 전방 및 후방 로직을 추가하며, functional fully_shard는 nn.Module 후크를 등록하여 구현. 역방향 전달에서는 Tensor에 등록된 후크를 사용해 각 FSDP 단위의 전방 출력 텐서에 대해 그래디언트 계산 전에 통신을 추가
혼합 정밀도(Mixed Precision)
FSDP는 다양한 혼합 정밀도 메커니즘을 지원하며, 낮은 정밀도와 높은 정밀도 두 가지 버전을 유지합니다. 전방 및 역방향 계산에는 낮은 정밀도를 사용하고, 옵티마이저 단계에서는 높은 정밀도를 사용합니다. FSDP의 혼합 정밀도는 모든 집합 통신을 낮은 정밀도로 수행할 수 있어 통신 양을 줄이는 장점이 있습니다. FP16 또는 BF16을 낮은 정밀도로, FP32를 높은 정밀도로 자주 선택합니다. FP16의 경우 정밀도 부족으로 인해 수치적 오류가 발생할 수 있어, FSDP는 이를 위해 자체적인 샤딩된 그래디언트 스케일러를 제공
EVALUATION
실험 설정: Hugging Face T5, minGPT, DHEN 모델을 사용하여 FSDP의 성능을 평가
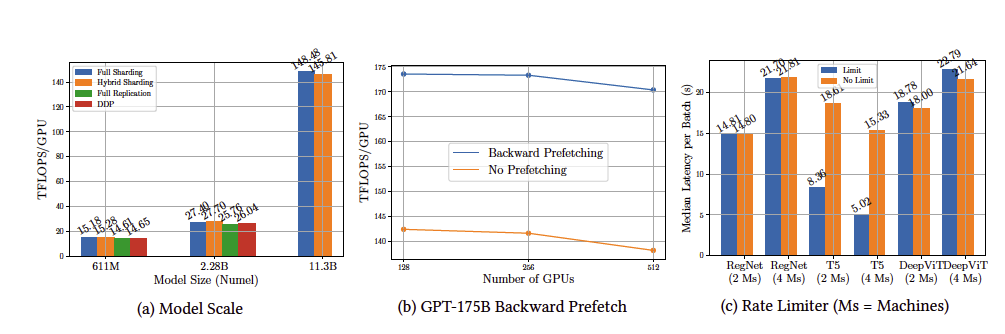
모델 크기 평가: FSDP는 2.28B 이상의 모델에서도 메모리 부족 없이 높은 성능을 보였으며, GPT-175B 모델에서 역방향 프리페칭을 통해 18% 속도 향상을 달성
통신 제한: 통신 제한은 특정 상황에서 최대 5배 속도 향상을 주었으나, 일부 모델에서는 오히려 성능 저하를 일으켰으며, 통신 제한 사용 시 메모리 단편화를 먼저 확인 필요.
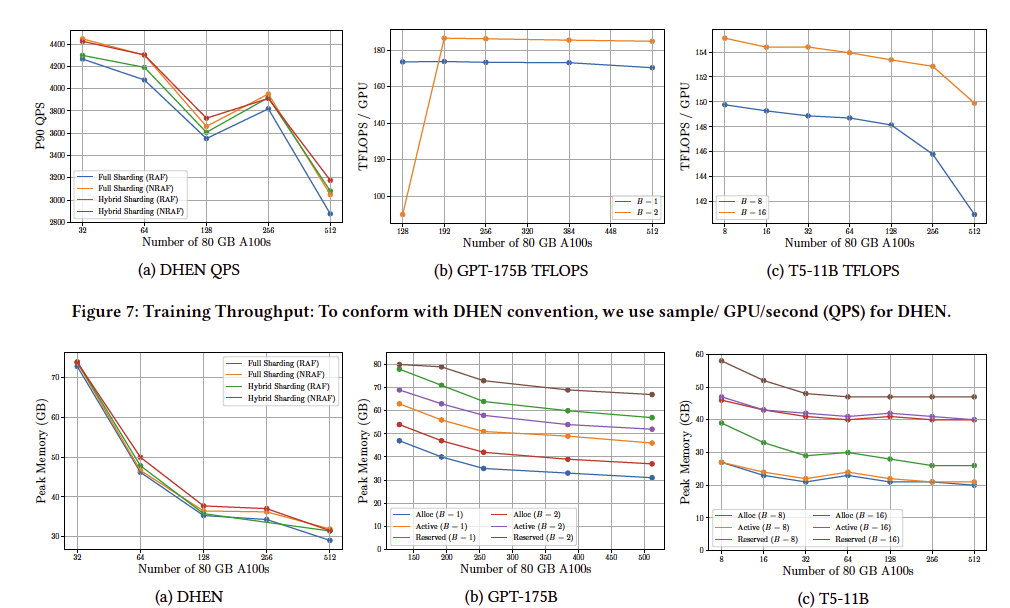
대규모 모델의 효율적 학습: DHEN, GPT-175B, T5-11B 모델에서 Full Sharding과 Hybrid Sharding을 사용한 실험을 진행했으며, FSDP는 높은 확장성과 효율을 보여주었으나, 대규모 클러스터에서는 통신이 계산을 압도하여 성능 저하가 발생할 수 있음.
CONCLUSION
PyTorch 2.0 릴리스 시점의 FullyShardedDataParallel (FSDP)의 기본 원리, 설계 철학, 구현에 대해 설명 FSDP는 지연 초기화(deferred initialization), 유연한 샤딩 전략(flexible sharding strategies), 통신 중첩 및 프리페칭(communication overlapping and prefetching), 통신 집합의 속도 제한(rate limiting communication collectives) 등 일련의 고급 기술을 통해 사용성 및 효율성을 달성. 이러한 모든 기술은 다른 주요 PyTorch 구성 요소와 긴밀하게 공동 설계되어 솔루션의 안정성과 견고함을 보장합니다. 평가 결과, FSDP는 대규모 언어 모델과 추천 모델을 거의 선형 확장성으로 지원할 수 있음을 보여줌
참고:
