
Search Process
검색은 어떻게 작동하는 걸까🤔 ???
큰 틀을 말해보자면
사용자가 브라우저에서 검색어를 입력하고 검색 버튼을 클릭하는 순간
검색어를 갖고 백엔드로 API요청이 들어간다.
API는 DB에서 검색어를 찾아
다시 API에 돌려주고 백엔드에서 브라우저로 결과 값을 보여줄 것이다.
빠른 검색을 위해
Redis
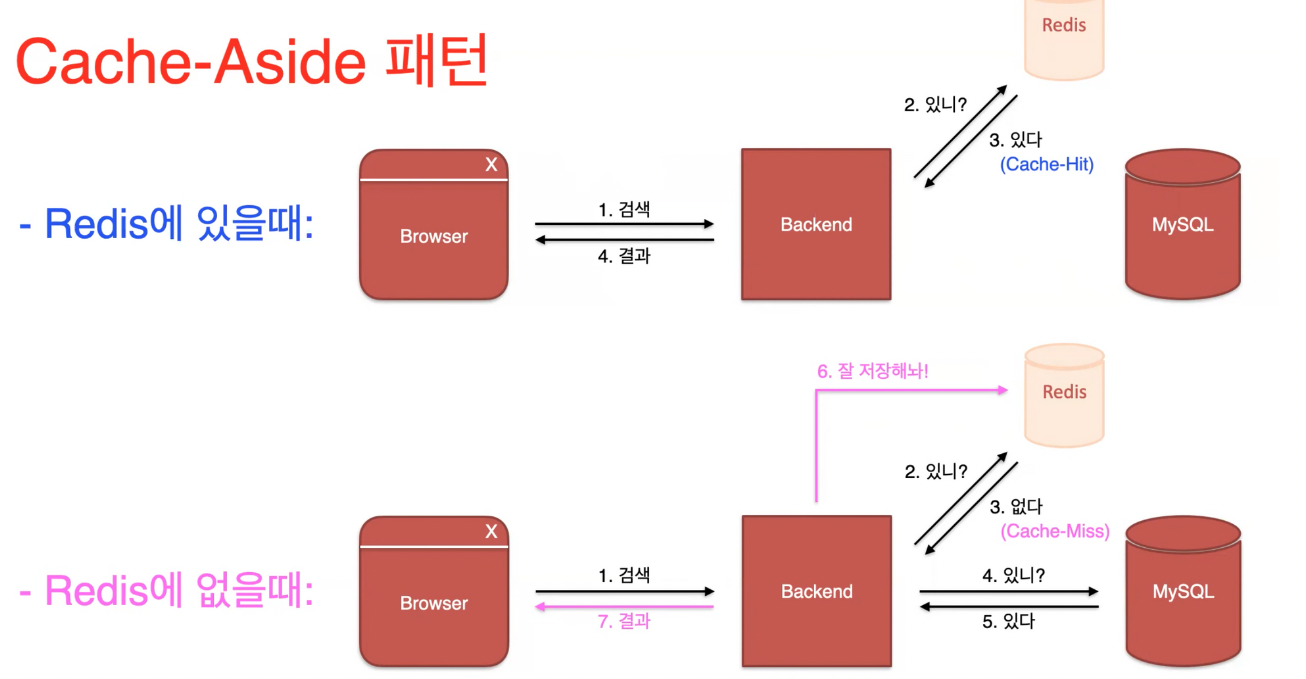
우리는 Redis라는 것을 도입했다.
Redis는 인메모리 데이터베이스로 메모리 기반으로 디스크에서 데이터를 저장하는 것과는 달리 서버의 주 메모리에 저장하여 디스크에 엑세스해야 할 필요를 없앰으로써 검색 시간으로 인한 지연을 방지하고 CPU 명령을 적게 사용한다.
cache-hit
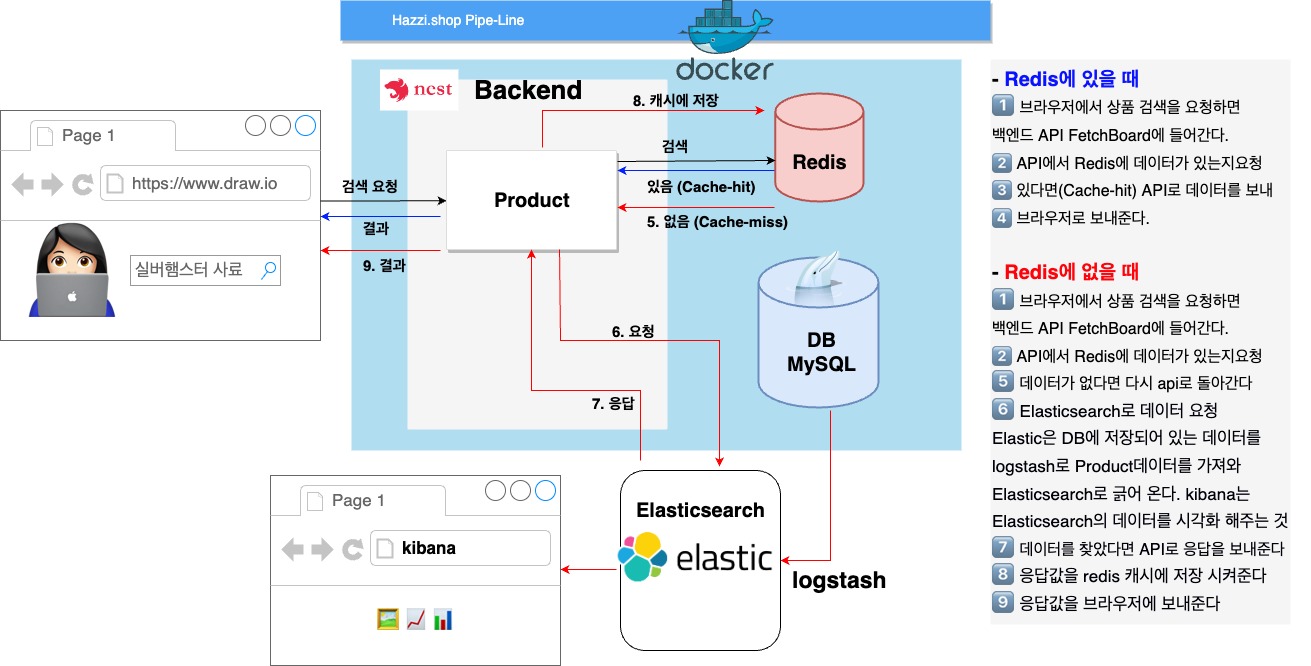
점심을 검색하면 -> Redis로 바로 간다.
있으면 바로 되돌려 준다. 아주 빠르게 사용가능하다
이것을 cache-hit라고 한다.
만약 없다면??
cache-miss면 mainDB or Elasticsearch에 간다.
Elasticsearch
브라우저
백엔드
프론트엔드
디비 - 인덱스를 걸었다. 게시판 테이블
브라우저에는 검색창
밑에는 게시글. 검색창의 검색을 누르면 FechBoard(word:'점심')
점심이 들어간 문장을 찾아달라고 API에 요청
DB Board 테이블에 점심 들어간 것을 찾아야한다.
where title = '%점심%'
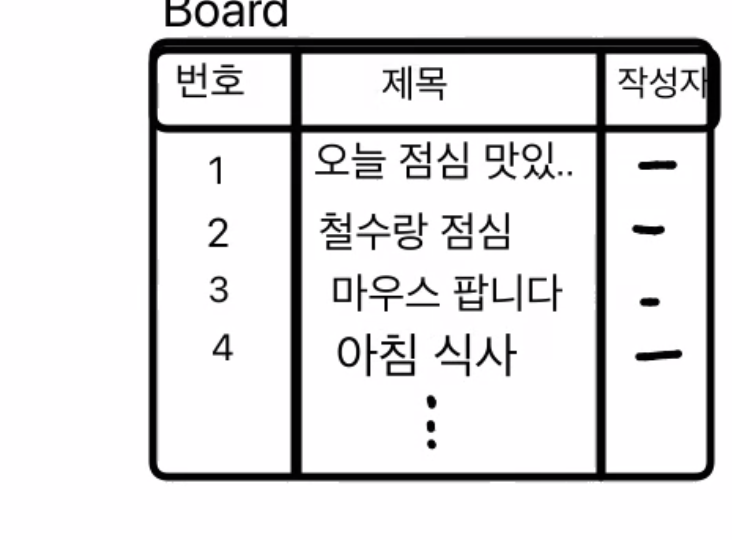
위에서부터 점심이 들어가있는지 찾는다.
한 페이지에 10개를 보여주면 (인덱스는 사용할 수 없다. 인덱스는 전체를 찾을때 가능)
만약 글이 100만개가 있는데 98만번째에도 점심이 들어가 있다면 ???
엄청 느리다!!!! 찾기가 쉽지 않다.
google 검색엔진 초창기
단어를 잘라서 (Token 이라고 부른다.) 저장해줬다.

Tokenizing : 단어를 자르는 작업
이걸 작업해주는 것은 없을까?
=> Elasticsearch
그래서 나온 것이 Elasticsearch다.
게시글 등록을 했을 때..
등록을 했을 때 DB에도 넣고, Elasticsearch에도 넣고
=> 좋지않은 방법. 갑자기 오류로 하나에는 안들어갈 수 있다.
Logstash
DB에 있는 데이터를 가져다가 Elasticsearch로 긁어 온다.
동기화도 시켜준다.
kibana
브라우저에서 접속하는 주소
DBeaver처럼 엘라스틱 서치의 데이터를 볼 수 있다.
Elasticsearch의 시각화 도구.
메모리 기반보다 빠른 순 없다. 디스크에서 꺼내기 때문에
트래픽이 더 많아지면 검색하는 사용자들의 검색 패턴(인기 검색어)
Redis에 key, value 형태로 저장해 놓는다
<틀릴 수 있음>
