수업 목표
1. 파이썬 기초 문법을 안다.
2. 원하는 페이지를 크롤링 할 수 있다.
3. pymongo를 통해 mongoDB를 제어할 수 있다.
1. Python
- 파이썬은 일종의 번역팩으로 이해하면 된다. 컴퓨터는 101010001 과 같은 언어만 알아듣기 때문에 파이썬 문법으로 된 것을 101010001로 변환해줄 수 있도록, 파이썬이 번역해준다 생각하면 된다.
1-1 Python 기초문법
1) 변수 & 기본연산
a = 3 # 3을 a에 넣는다
b = a # a를 b에 넣는다
a = a + 1 # a+1을 다시 a에 넣는다
num1 = a*b # a*b의 값을 num1이라는 변수에 넣는다
num2 = 99 # 99의 값을 num2이라는 변수에 넣는다
# 변수의 이름은 마음대로 지을 수 있음!
# 진짜 "마음대로" 짓는 게 좋을까? var1, var2 이렇게?2) 자료형
-
숫자, 문자형
name = 'bob' # 변수에는 문자열이 들어갈 수도 있고, num = 12 # 숫자가 들어갈 수도 있고, is_number = True # True 또는 False -> "Boolean"형이 들어갈 수도 있습니다. ######### # 그리고 List, Dictionary 도 들어갈 수도 있죠. 그게 뭔지는 아래에서! -
리스트 형 (Javascript의 배열형과 동일)
a_list = [] a_list.append(1) # 리스트에 값을 넣는다 a_list.append([2,3]) # 리스트에 [2,3]이라는 리스트를 다시 넣는다 # a_list의 값은? [1,[2,3]] # a_list[0]의 값은? 1 # a_list[1]의 값은? [2,3] # a_list[1][0]의 값은? 2 -
Dictionary 형 (Javascript의 dictionary형과 동일)
a_dict = {} a_dict = {'name':'bob','age':21} a_dict['height'] = 178 # a_dict의 값은? {'name':'bob','age':21, 'height':178} # a_dict['name']의 값은? 'bob' # a_dict['age']의 값은? 21 # a_dict['height']의 값은? 178 -
Dictionary 형과 List형의 조합
people = [{'name':'bob','age':20},{'name':'carry','age':38}] # people[0]['name']의 값은? 'bob' # people[1]['name']의 값은? 'carry' person = {'name':'john','age':7} people.append(person) # people의 값은? [{'name':'bob','age':20},{'name':'carry','age':38},{'name':'john','age':7}] # people[2]['name']의 값은? 'john'
3) 함수
- 함수의 정의 - 이름은 마음대로 정할 수 있음!
# 수학문제에서 f(x) = 2*x+3 y = f(2) y의 값은? 7 # 참고: 자바스크립트에서는 function f(x) { return 2*x+3 } # 파이썬에서 def f(x): return 2*x+3 y = f(2) y의 값은? 7 - 함수의 응용
def sum_all(a,b,c): return a+b+c def mul(a,b): return a*b result = sum_all(1,2,3) + mul(10,10) # result라는 변수의 값은?
4) 조건문
- if / else 로 구성!
def oddeven(num): # oddeven이라는 이름의 함수를 정의한다. num을 변수로 받는다. if num % 2 == 0: # num을 2로 나눈 나머지가 0이면 return True # True (참)을 반환한다. else: # 아니면, return False # False (거짓)을 반환한다. result = oddeven(20) # result의 값은 무엇일까요?def is_adult(age): if age > 20: print('성인입니다') # 조건이 참이면 성인입니다를 출력 else: print('청소년이에요') # 조건이 거짓이면 청소년이에요를 출력 is_adult(30) # 무엇이 출력될까요?
5) 반복문
파이썬에서의 반복문은, 리스트의 요소들을 하나씩 꺼내쓰는 형태입니다.
- 즉, 무조건 리스트와 함께 쓰입니다!
fruits = ['사과','배','감','귤'] for fruit in fruits: print(fruit) # 사과, 배, 감, 귤 하나씩 꺼내어 찍힙니다. - 리스트 예제
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
count = 0
for fruit in fruits:
if fruit == '사과':
count += 1
print(count)
# 사과의 개수를 세어 보여줍니다.- 딕셔너리 예제
people = [{'name': 'bob', 'age': 20},
{'name': 'carry', 'age': 38},
{'name': 'john', 'age': 7},
{'name': 'smith', 'age': 17},
{'name': 'ben', 'age': 27}]
# 모든 사람의 이름과 나이를 출력해봅시다.
for person in people:
print(person['name'], person['age'])
# person이라는 변수에 people의 속성을 순서대로 가져오는 것!!!
# 그래서 person['name'] == n번째 person의 'name'이 뭐니? 라는 뜻
# 이번엔, 반복문과 조건문을 응용한 함수를 만들어봅시다.
# 이름을 받으면, age를 리턴해주는 함수
def get_age(myname):
for person in people:
if person['name'] == myname:
return person['age']
return '해당하는 이름이 없습니다'
print(get_age('bob'))
print(get_age('kay'))1-2 Python 패키지(package)
- Python 에서 패키지는 모듈(일종의 기능들 묶음)을 모아 놓은 단위
- 이런 패키지의 묶음을 라이브러리라고 볼 수 있다.
- 이 강의에서 패키지 설치 = 외부 라이브러리 설치라고 보면 된다.!
1) 가상환경
- 가상환경(virtual environment)은 같은 시스템에서 실행되는 다른 파이썬 응용 프로그램들의 동작에 영향을 주지 않기 위해, 파이썬 배포 패키지들을 설치하거나 업그레이드하는 것을 가능하게 하는 격리된 실행 환경 입니다.
- 쉽게 말해 프로젝트 별로 패키지들을 담을 공구함
- 모든 공구를 다 담을 필요 없이 프로젝트 별로 필요한 패키지를 별도로 보관해서 사용하는 것
2) pip 사용 - requests 패키지 설치
- 앱을 설치할 때 앱스토어/플레이스토어를 가듯이, 새로운 프로젝트의 라이브러리를 가상환경(공구함)에 설치하려면 pip(python install package) 를 이용
- pycham에서 setting -> project interpreter에서 원하는 라이브러리 추가
3) requests 패키지 활용
- 모든 구의 IDEX_MVL 값
import requests # requests 라이브러리 설치 필요 r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99') rjson = r.json() gus = rjson['RealtimeCityAir']['row'] for gu in gus: print(gu['MSRSTE_NM'], gu['IDEX_MVL']) - IDEX_MVL 값이 60 미만인 구
import requests # requests 라이브러리 설치 필요 r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99') rjson = r.json() gus = rjson['RealtimeCityAir']['row'] for gu in gus: if gu['IDEX_MVL'] < 60: print (gu['MSRSTE_NM'], gu['IDEX_MVL'])
2. 크롤링
- 크롤링 : 포털 사이트 검색엔진이 내 사이트를 퍼가는 행위를 뜻하지만 반대로 포털사이트 데이터를 개인 사이트로 가져오는 행위(스크래핑)도 혼용한다.
- 크롤링이 가능한 이유 : 서버에 요청을 통해 받아온 데이터를 내 입맛에 맡게 솎아 내는 것이 크롤링이고 데이터를 정리하는 것은 컴퓨터가 하는 것
2-1 크롤링 기초 (beautifulsoup4)
- 크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 파싱(parsing) : 어떤 페이지(문서, html 등)에서 내가 원하는 데이터를 특정 패턴이나 순서로 추출해 가공하는 것
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
#############################
# (입맛에 맞게 코딩)
#############################-
select / select_one 사용법(영화 제목을 가져와보기)
- 태그 안의 텍스트를 찍고 싶을 땐 → 태그.text
- 태그 안의 속성을 찍고 싶을 땐 → 태그['속성']
import requests
from bs4 import BeautifulSoup
# URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print (a_tag.text)- beautifulsoup 내 select에 미리 정의된 다른 방법을 알아봅니다
# 선택자를 사용하는 방법 (copy selector) soup.select('태그명') soup.select('.클래스명') soup.select('#아이디명') soup.select('상위태그명 > 하위태그명 > 하위태그명') soup.select('상위태그명.클래스명 > 하위태그명.클래스명') # 태그와 속성값으로 찾는 방법 soup.select('태그명[속성="값"]') # 한 개만 가져오고 싶은 경우 soup.select_one('위와 동일') - 항상 정확하지는 않으나, 크롬 개발자도구를 참고 가능
- 원하는 부분에서 마우스 오른쪽 클릭 → 검사
- 원하는 태그에서 마우스 오른쪽 클릭
- Copy → Copy selector로 선택자를 복사할 수 있음
2-2 크롤링 연습
- 영화 순위, 제목, 평점 크롤링 해오기
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# select를 이용해서, tr들을 불러오기
trs = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for tr in trs :
ranks = tr.select_one('td:nth-child(1) > img') # img 태그까지 가져오기
titles = tr.select_one('td.title > div > a') # a 태그까지 가져오기
stars = tr.select_one('td.point') # tr 태그까지 가져오기
if titles is not None:
rank = ranks['alt'] # img 태그의 alt 속성값을 가져오기
title = titles.text # a 태그 사이의 텍스트를 가져오기
star = stars.text # td 태그 사이의 텍스트를 가져오기
print(rank, title, star) # 반복문이니까 one으로 돌때마다 하나씩 출력 3. mongoDB
-
mongoDB : NoSQL 방식의 데이터 베이스 저장공간
-
SQL : 행/열의 생김새가 정해진 엑셀에 데이터를 저장하는 것과 유사합니다. 데이터 50만 개가 적재된 상태에서, 갑자기 중간에 열을 하나 더하기는 어려울 것입니다. 그러나, 정형화되어 있는 만큼, 데이터의 일관성이나 / 분석에 용이할 수 있습니다. ex) MS-SQL , My-SQL
-
NoSQL : 딕셔너리 형태로 데이터를 저장해두는 DB입니다. 고로 데이터 하나 하나 마다 같은 값들을 가질 필요가 없게 됩니다. 자유로운 형태의 데이터 적재에 유리한 대신, 일관성이 부족할 수 있습니다. ex) MongoDB
-
-
Robo3T : 눈에 보이지 않게 작동하는 mongoDB의 내용을 시각화 해주는 프로그램
3-1 pymongo로 DB조작하기
1) pymongo 라이브러리 역할
- 예를 들어, MS Excel를 파이썬으로 조작하려면, 특별한 라이브러리가 필요
- 마찬가지로, mongoDB 라는 프로그램을 조작하려면, 특별한 라이브러리, pymongo가 필요
- DB또한 컴퓨터가 수행하는 하나의 프로그램!!!
2) pymongo 사용법,코드 요약
from pymongo import MongoClient # pymongo를 임포트 하기(패키지 인스톨 먼저 해야겠죠?)
client = MongoClient('localhost', 27017) # mongoDB는 27017 포트로 돌아갑니다.
db = client.dbsparta # 'dbsparta'라는 이름의 db를 만듭니다.
# 코딩 시작
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
same_ages = list(db.users.find({'age':21},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})3-2 웹 스크래핑 결과 활용
웹스크래핑 결과 저장(insert)
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# header : 브라우저에서 엔터를 눌러 요청한 것과 같은 효과를 내기 위해 사용, 대부분의 사이트는 크롤링하는 것을 막아두었기 때문에!!
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs :
ranks = tr.select_one('td:nth-child(1) > img')
titles = tr.select_one('td.title > div > a')
stars = tr.select_one('td.point')
if titles is not None:
rank = ranks['alt']
title = titles.text
star = stars.text
# 딕셔너리 생성
doc = {
'title' : title,
'rank' : rank,
'star' : star
}
db.movies.insert_one(doc) # 반복문이니까 one으로 돌때마다 하나씩 insert웹스크래핑 결과 이용(find, update, delete는 제외)
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
matrix = db.movies.find_one({'title':'매트릭스'}) # (1) 영화제목 '매트릭스'의 평점을 가져오기(find_one)
matrix_star = matrix['star']
print(matrix_star)
same_star = list(db.movies.find({'star':matrix_star},{'_id':False})) # (2) '매트릭스'의 평점과 같은 평점의 영화 제목들을 가져오기(find)
for same_star_list in same_star:
print(same_star_list['title'])
db.movies.update_one({'title':'매트릭스'},{'$set':{'star':'0'}}) # (3) 매트릭스 영화의 평점을 0으로 만들기(update)
# 문자열 통일을 위해 0 이 아닌 '0' 으로 값 입력
3주차 숙제
지니 뮤직 1~50위 곡 스크래핑 하기
1) 작동 결과

2) 사용코드
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=D&ymd=20200403&hh=23&rtm=N&pg=1',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs :
ranks = tr.select_one('td.number')
titles = tr.select_one('td.info > a.title.ellipsis')
singers = tr.select_one('td.info > a.artist.ellipsis')
rank = ranks.text.split('\n')[0]
title = titles.text.strip()
singer = singers.text
print(rank, title, singer)
# doc = {
# 'title' : title,
# 'rank' : rank,
# 'singer' : singer
# }
# db.genie.insert_one(doc) # mongoDB에 'genie'라는 이름으로 저장
3) 숙제간 마주친 문제점과 해결 방법
-
정확한 순위 값을 위해 split() 함수 활용
-
문제점 :
rank변수를 print하게 되면 순위를 나타내는 text가 포함된 태그의 하위태그에도 포함된 text(순위변동를 나타내는)가 함께 출력되어 이를 분리할 필요가 있었다.print(rank)의 결과값

<td class = "number">태그 의 하위 태그 인span태그들에 추가로 포함되어 있는 텍스트들
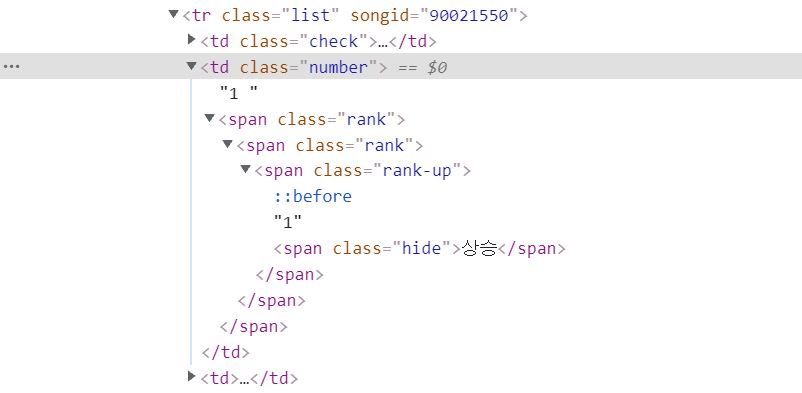
-
해결 방법 : 이를 해결하기 위해
.split을 활용하기로 결정했고,ranks.text.split(' ')print해보니 아래와 같이\n을 기준으로 순위 값이 구분되어 있는 것을 확인할 수 있었다.
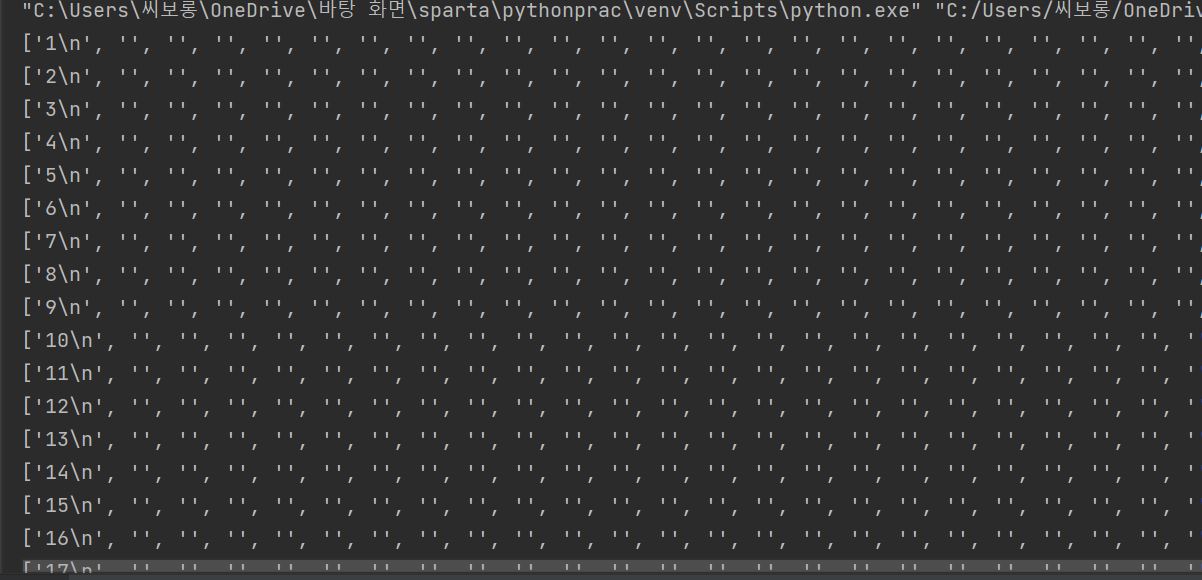
-
결국
rank = ranks.text.split('\n')[0]코드로 원하는 순위 텍스트만 뽑아 올 수 있었다.
-
-
strip() 함수 활용
- 문제점 :
title을 print 해보면 제목과 제목 사이에 공백이 많이 나오는 것을 확인 할 수 있다.- 제목 사이에 많은 공백

- 제목 사이에 많은 공백
- 해결 방법 :
.strip()을 활용하여 텍스트 사이의 공백을 모두 없애는 것으로 해결print(titles.text.strip())결과
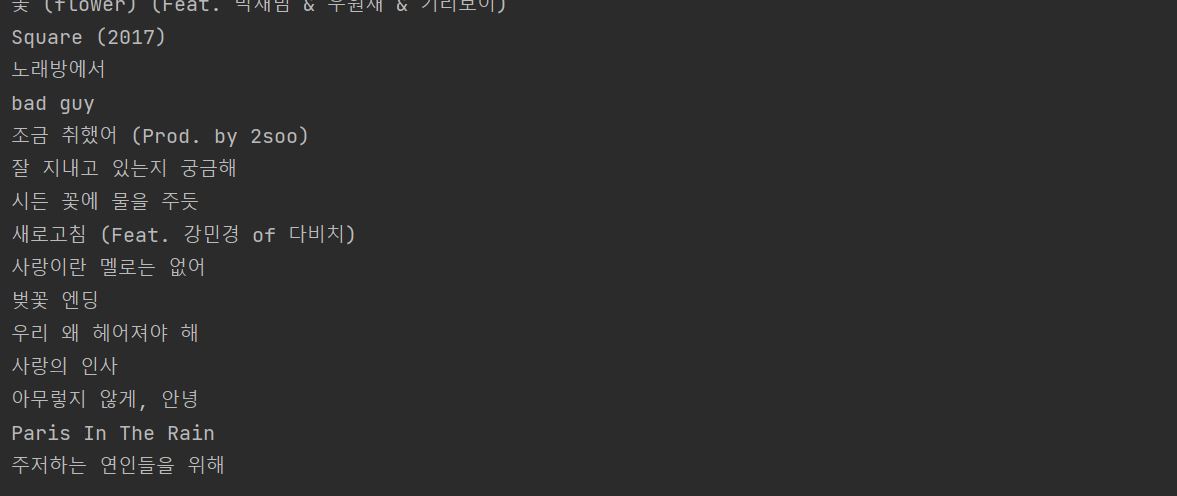
- 문제점 :
