Day1
🟢Bert에 대해서 이야기 해본다
🔵개념
https://arxiv.org/pdf/1810.04805
- transformer 구조를 활용하여 구조를 설계한 첫번째 자연어 처리 모델
어텐션 vs 셀프 어텐션
- 어텐션
- 디코더 기준 중요한 걸 인코더에서 체크
- 셀프 어텐션
- 문장 내에서 체크하는 것
- Query, Key, Value
예시 : ) 강아지가 침대 위에 올라갔다.
- 올라갔다와 강아지의 연관성 높음을 증명하는 것이 셀프 어텐션
🔵huggingface
- tensorflow, pytorch 라이브러리 없이 그냥 transformer 라이브러리 사용
관련 라이브러리 - accelerate. dataset. transformer
- kimi → 중국 모델
https://www.vellum.ai/llm-leaderboard?utm_source=google&utm_medium=organic
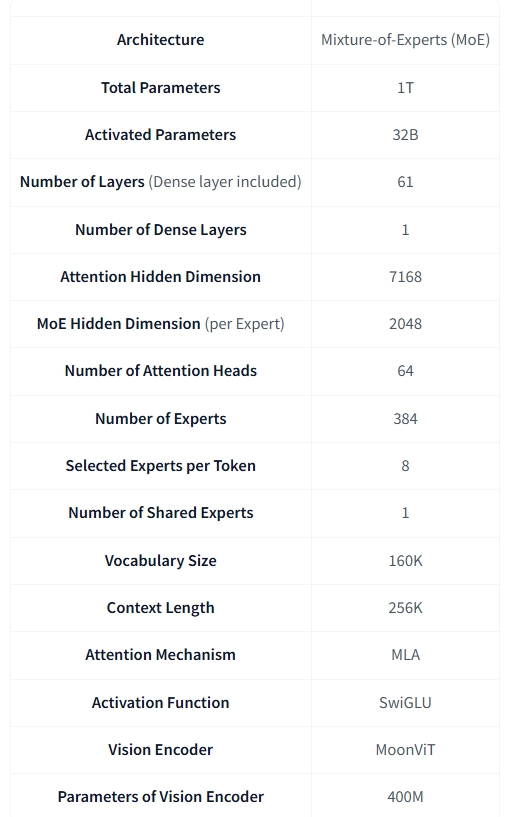
🔵문샷 모델. 가중치 공개일 경우 다 허깅페이스에 있음.
https://huggingface.co/moonshotai/Kimi-K2.5
🔵코드 구현을 해보자
환경 설정
pip install nlp
from nlp import list_datasets
datasets_list = list_datasets()
print(', '.join(dataset.id for dataset in datasets_list))
from transformers import BertModel, BertTokenizer
import torch
model = BertModel.from_pretrained("bert-base-uncased")
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
- uncased → 모두 소문자 처리한 것을 가져오겠다.
tokenizer.tokenize("Today is monday")['today', 'is', 'monday']
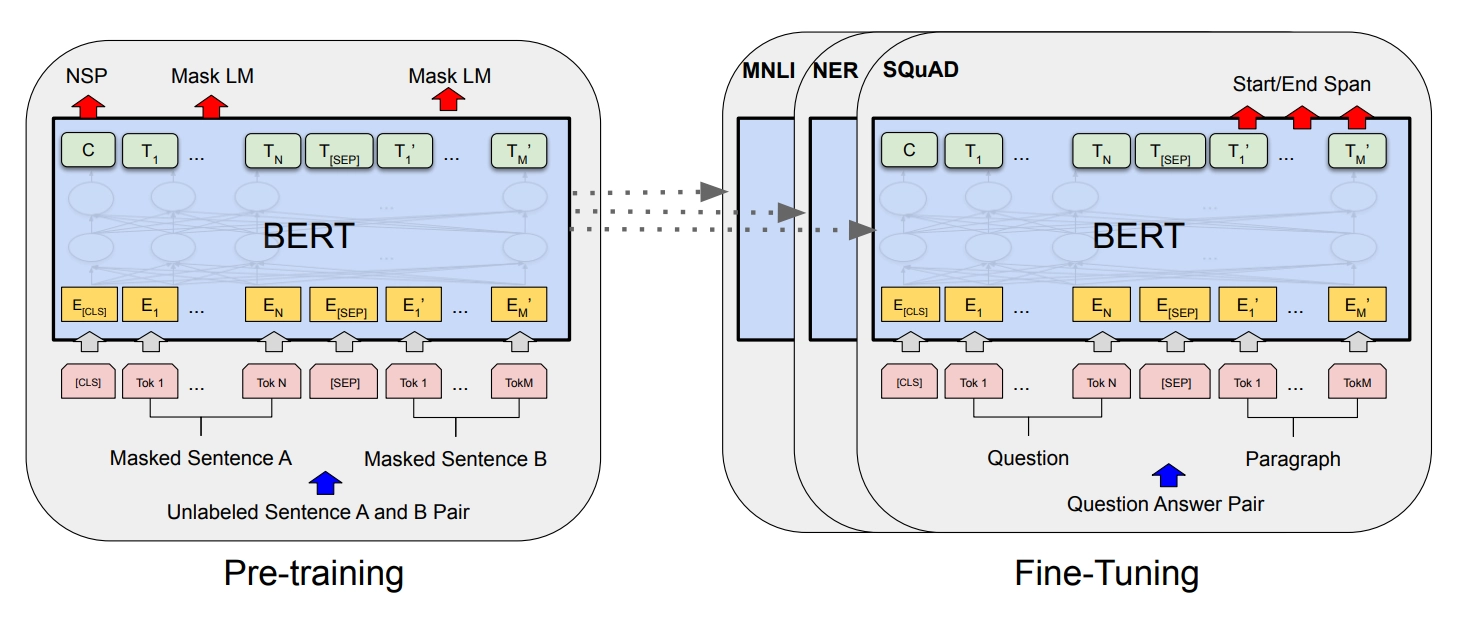
- CLS 토큰, 문장의 시작을 알림
- SEP 토큰 , 문장의 끝을 알림
token = tokenizer.tokenize("Today is monday")
tokens = [['CLS']] + token + [['SEP']]
tokens = tokens + [['PAD']] + [['PAD']]- 기본 설정값이 있으면 나머지는 패딩해야함
- 우선 기본 값이 7개로 가정하고, 2개 모자라서 2개를 패딩함
- 패딩은 학습할 필요가 없으므로 마스크를 씌운다.
attention_mask = [1 if i != ['PAD'] else 0 for i in tokens ]- 이를 통해 모델이 패딩은 보지 않게 처리할 수 있다.
[tokenizer.convert_tokens_to_ids(x) for x in tokens]
token_ids = tokenizer.convert_tokens_to_ids(tokens)[101, 2651, 2003, 6928, 102, 0, 0]
- 사전을 기반으로 인덱스가 설정되기 때문에 모델마다 다른 인덱스가 부여된다,.
token_ids = torch.tensor(token_ids).to('cuda')
attention_mask = torch.tensor(attention_mask).to('cuda')
model = model.to('cuda')
token_ids = token_ids.unsqueeze(0)
attention_mask = attention_mask.unsqueeze(0)- unsqueeze(0) → 차원 변경
hidden_rep, cls_head = model(token_ids, attention_mask=attention_mask)- hidden_rep ⇒ 은닉층에서 표현된 값
- cls_head ⇒ 마지막 인코더에서 출력된 값.
outputs =model(token_ids, attention_mask=attention_mask)
outputs.last_hidden_state
tensor([[[ 0.0197, 0.2196, 0.0938, ..., -0.1899, 0.4116, 0.2325],
[-0.5819, -0.1249, 0.3125, ..., -0.2005, 0.9950, -0.6527],
[-0.9762, -0.2775, 0.4668, ..., -0.1024, 0.5229, 0.6063],
...,
[ 0.5964, 0.2489, -0.1335, ..., 0.0682, -0.4352, -0.2907],
[-0.1634, 0.0760, 0.3225, ..., 0.1563, 0.4583, 0.2637],
[-0.1767, -0.0107, 0.2926, ..., 0.2592, 0.4495, 0.1880]]],
device='cuda:0', grad_fn=)
outputs.last_hidden_state.shapetorch.Size([1, 7, 768])
- 7개의 토큰. 768차원의 임베딩 값.
🔵마스크를 맞추게 한다. The capital of France is [MASK].
from transformers import BertTokenizer, BertForMaskedLM, BertForSequenceClassification
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
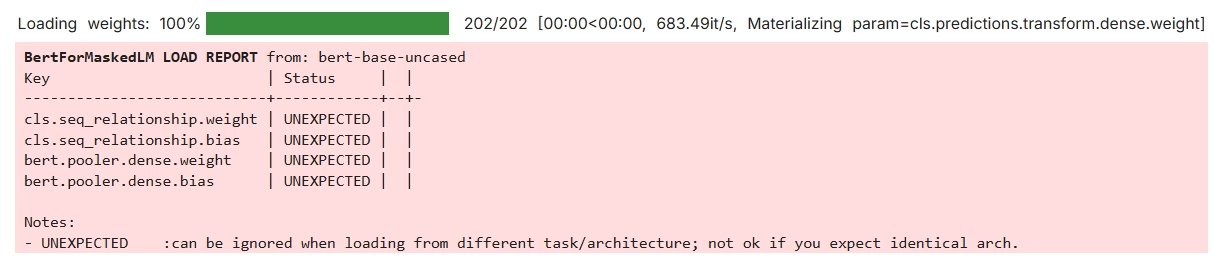
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors="pt")
print(inputs){'input_ids': tensor([[ 101, 1996, 3007, 1997, 2605, 2003, 103, 1012, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1]])}
- **로 매개변수 넣으면 json이 넘어감
with torch.no_grad():
outputs = model(**inputs)
predcitions = outputs.logitsmask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
print(mask_token_index)tensor([6])
predicted_token_id = predcitions[0, mask_token_index].argmax(dim=-1)
print(predicted_token_id)tensor([3000]
- 버트도 단어 예측에 있어 소프트맥스에 통과시켜 최대 확률로 가게 함.
predicted_word = tokenizer.decode(predicted_token_id)
print(predicted_word)paris
values , indices = torch.topk(predcitions[0, mask_token_index], k=2, dim=-1)
words = "The capital of France is {}."
for x in text.split():
print(words.format(x))
The capital of France is The.
The capital of France is capital.
The capital of France is of.
The capital of France is France.
The capital of France is is.
The capital of France is [MASK]..
🔵다중언어모델을 사용해보자
kmodel = BertForMaskedLM.from_pretrained('bert-base-multilingual-cased')
ktokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased")
text = "거먼은 해당 제품이 2026년 [MASK] 출시될 가능성이 크다고 내다봤다."🔵Downstream Task
- 기존에 만들어진모델을 가지고 새로운 테스크를 해결하고자 하는 것.
- 프리트레인(Pre-train, 사전 학습)된 AI 모델을 특정 목적(문서 분류, 질의응답 등)에 맞춰 파인튜닝(Fine-tuning)하여 활용
kmodel = BertForMaskedLM.from_pretrained('bert-base-multilingual-cased')
ktokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased")
text = "거먼은 해당 제품이 2026년 [MASK] 출시될 가능성이 크다고 내다봤다."
import torch
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch.nn.functional as F
model_name = "klue/bert-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForMaskedLM.from_pretrained(model_name)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
inputs = tokenizer(text, return_tensors="pt").to(device)
mask_token_index = torch.where(inputs["input_ids"] == tokenizer.mask_token_id)[1]
model.eval()
with torch.no_grad():
outputs = model(**inputs)
predictions = outputs.logits
mask_logits = predictions[0, mask_token_index]
probs = F.softmax(mask_logits, dim=-1)
print(probs.sum())
print(probs.shape)
top_values, top_indices = torch.topk(probs, k=10, dim=-1)
for i in range(10):
token_id = top_indices[0, i].item()
token_prob = top_values[0, i].item()
token_text = tokenizer.decode([token_id])
rank = i + 1
print(f"{rank}순위: {token_text} (ID: {token_id}, 확률: {token_prob:.4f})")

🔵진짜 다운스트림테스크 진행 - 감정분석 모델을 bert로 생성해본다.
from transformers import AutoTokenizer, AutoModelForSequenceClassification
model_name = "klue/roberta-large"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = model.to('cuda')
inputs = tokenizer(text, return_tensor='pt', truncation=True, max_length=128, padding=True)
def predict_sentiment(text):
model.eval()
inputs = tokenizer(
text,
return_tensors="pt",
truncation=True,
max_length=128,
padding=True
).to(device)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.softmax(logits, dim=-1)
prediction = torch.argmax(probs, dim=-1).item()
return prediction, probs[0]- 다운스트림테스크를 쉽게 진행시킬 수 있게 존재하는 라이브러리
print(predict_sentiment("신난다"))(1, tensor([0.4471, 0.5529], device='cuda:0'))
🟢Discord
https://discord.gg/SkNXtS5Y
https://discord.com/developers/applications
https://emojipedia.org/smiling-face-with-smiling-eyes🔵특정 채널과 연동
import requests
BOT_TOKEN = 'MTQ4MDQxMTMzMDczNjU1ODEyMA.G_JALf.bZXlmoWsyZXisLFrBMEaAe0F3lQEYXlSm__zz8'
CHANNEL_ID = '1480421375461163162'
headers = {
'Authorization': f'Bot {BOT_TOKEN}'
}
params = {
'limit': 100
}
url = f'https://discord.com/api/v10/channels/{CHANNEL_ID}/messages'
response = requests.get(url, headers=headers, params=params)
response.json() {'type': 7,
'content': '',
'mentions': [],
'mention_roles': [],
'attachments': [],
'embeds': [],
'timestamp': '2026-03-09T05:04:01.685000+00:00',
'edited_timestamp': None,
'flags': 0,
'components': [],
'id': '1480430942148366458',
'channel_id': '1480421375461163162',
'author': {'id': '688050459012759648',
'username': '.laptopdestroyer',
'avatar': 'c51315d4239ec119ad095f2a7d09c3a6',
'discriminator': '0',
'public_flags': 0,
'flags': 0,
'banner': None,
'accent_color': None,
'global_name': '김나연',
'avatar_decoration_data': None,
'collectibles': None,
'display_name_styles': None,
'banner_color': None,
'clan': None,
'primary_guild': None},
'pinned': False,
'mention_everyone': False,
'tts': False},
from urllib.parse import quote
quote('😊')'%F0%9F%98%8A'
🔵특정 메시지에 이모티콘 달기
from urllib.parse import quote
MESSAGE_ID = "1480433509310140416"
encoded_reaction = quote('🐱')
url = f'https://discord.com/api/v10/channels/{CHANNEL_ID}/messages/{MESSAGE_ID}/reactions/{encoded_reaction}/@me'
response = requests.put(url, headers=headers)
🔵디스코드 연동텍스트 보내기
response = requests.put(url, headers=headers)
msg_url = f'https://discord.com/api/v10/channels/{CHANNEL_ID}/messages'
data = {
'content' : "."
}
response = requests.post(msg_url, headers=headers, json=data)
🔵동기 비동기 처리
pip install discord
import nest_asyncio
import discord
nest_asyncio.apply()
intents = discord.Intents.default()
intents.message_content = True
client = discord.Client(intents=intents)
@client.event
async def on_ready():
print("실시간 채팅 받기....")
연결
import requests
BOT_TOKEN = 'MTQ4MDQxMTMzMDczNjU1ODEyMA.G_JALf.bZXlmoWsyZXisLFrBMEaAe0F3lQEYXlSm__zz8'
CHANNEL_ID = '1480421375461163162'
headers = {
'Authorization': f'Bot {BOT_TOKEN}'
}
params = {
'limit': 50
}
url = f'https://discord.com/api/v10/channels/{CHANNEL_ID}/messages'
response = requests.get(url, headers=headers, params=params)
data=response.json()
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model_name = "WhitePeak/bert-base-cased-Korean-sentiment"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)
model = model.to('cuda')
tokenizer = AutoTokenizer.from_pretrained(model_name)
device = 'cuda'
def predict_sentiment(text):
model.eval()
inputs = tokenizer(
text,
return_tensors="pt",
truncation=True,
max_length=128,
padding=True
).to(device)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
probs = torch.softmax(logits, dim=-1)
prediction = torch.argmax(probs, dim=-1).item()
return prediction
posi = "😽"
nega = "🙈"
from urllib.parse import quote
senti = 0
for x in response.json():
print(f"{x['author']['username']} - {x['content']} - {predict_sentiment(x['content'])}")
senti = predict_sentiment(x['content'])
encoded_reaction = quote(posi) if senti == 1 else quote(nega)
MESSAGE_ID = x['id']
url = f'https://discord.com/api/v10/channels/{CHANNEL_ID}/messages/{MESSAGE_ID}/reactions/{encoded_reaction}/@me'
response = requests.put(url, headers=headers)
MTQ4MDQ1MzMxNjI1MjE0MzcyNw.GGzlIJ.vj0FNMsFqttGI5KG56_aKDkwXbcr_ZGAfYvUiU
- oaut2 → 권한.
🔵내 api 받기
생성된 url 강사님께 전달하여 연결
🔵허깅페이스에서 토큰 연결
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
secret_value_0 = user_secrets.get_secret("api")
login(token=hf_token)
# Load model directly
from transformers import AutoProcessor, AutoModelForImageTextToText
processor = AutoProcessor.from_pretrained("google/gemma-3-4b-it")
model = AutoModelForImageTextToText.from_pretrained("google/gemma-3-4b-it")
messages = [
{
"role": "user",
"content": [
#{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "헤더 선언 새로 하셨나용?"}
]
},
]
model = model.to('cuda')
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(processor.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
outputs = model.generate(**inputs, max_new_tokens=1000)
input_len = inputs["input_ids"].shape[-1]
ai_response = processor.decode(outputs[0][input_len:], skip_special_tokens=True)
print(f"AI: {ai_response}")
messages.append({
"role": "assistant",
"content": [{"type": "text", "text": ai_response}]
})
while True:
user_text = input("사용자: ")
if user_text.lower() == 'quit':
break
messages.append({
"role": "user",
"content": [
{"type": "text", "text": user_text}
]
})
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to('cuda')
outputs = model.generate(**inputs, max_new_tokens=1000)
input_len = inputs["input_ids"].shape[-1]
ai_response = processor.decode(outputs[0][input_len:], skip_special_tokens=True)
print(f"AI: {ai_response}")
messages.append({
"role": "assistant",
"content": [
{"type": "text", "text": ai_response}
]
})
- 디스코드와 챗봇 연결 가능~
Day2
🟢어떤 주제를 물은건지 분류해보게 한다.
🔵전처리
import pandas as pd
food_store=pd.read_csv("./라벨링데이터_train/음식점_train.csv")
hospital=pd.read_csv("./라벨링데이터_train/병원_train.csv")
digit=pd.read_csv("./라벨링데이터_train/디지털가전_train.csv")
cloth=pd.read_csv("./라벨링데이터_train/의류_train.csv")
food_store.loc[food_store.발화자 =='c', ['발화문','카테고리']].to_csv("./data1.csv",index=False)
hospital.loc[hospital.발화자 =='c', ['발화문','카테고리']].to_csv("./data2.csv",index=False)
digit.loc[digit.발화자 =='c', ['발화문','카테고리']].to_csv("./data3.csv",index=False)
cloth.loc[digit.발화자 =='c', ['발화문','카테고리']].to_csv("./data4.csv",index=False)🔵캐글에 등록하기.
import pandas as pd
import os
data_dir = "/kaggle/input/datasets/nerffia/sentence-classification"
for file in os.listdir(data_dir):
print(data_dir+"/"+file)
df= pd.concat([pd.read_csv(data_dir + "/" + file) for file in os.listdir(data_dir)])
df.shape #(851687, 2)df.발화문.apply(lambda x : len(x)).mean()
df[df.발화문.apply(lambda x : len(x) >= 25)].shape
df2 = df[df.발화문.apply(lambda x : len(x) >= 25)].copy()🔵분류를 위해 head를 4개로 설정
- body는 이미 학습되어있다고 가정한다.
from transformers import BertTokenizerFast, BertForSequenceClassification
model_name = "klue/bert-base"
label2id = dict(zip(df2.카테고리.unique(), range(4)))
id2label = {v : k for k, v in label2id.items()}
num_labels = len(id2label)
print(label2id)
print(id2label)
print(num_labels){'의류': 0, '병원': 1, '디지털가전': 2, '음식점': 3}
{0: '의류', 1: '병원', 2: '디지털가전', 3: '음식점'}
4model = BertForSequenceClassification.from_pretrained(
model_name,
num_labels = num_labels,
id2label = id2label,
label2id = label2id
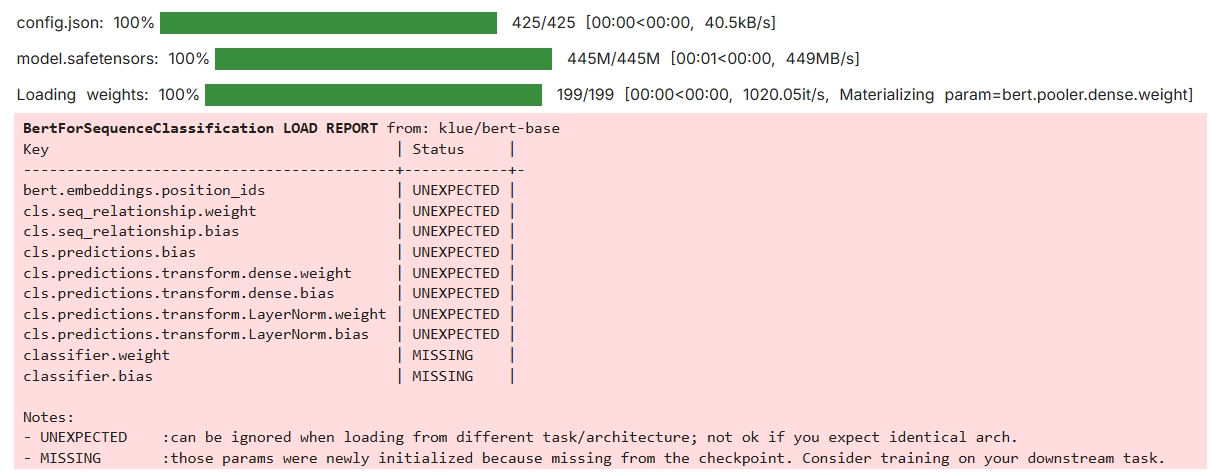
)
import torch
device =torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
tokenizer = BertTokenizerFast.from_pretrained(model_name)
tokenizer('오늘은 화요일입니다')
{'input_ids': [2, 3822, 2073, 14353, 12190, 3], 'token_type_ids': [0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1]}
- 시작이 2, 끝이 3
🔵데이터
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_length=64):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_length = max_length
self.encodings = self.tokenizer(
texts,
truncation=True, padding=True, max_length=max_length
)
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
item = {key : torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(label2id[self.labels[idx]])
return item
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df2['발화문'], df2['카테고리'], test_size=0.2, random_state=42, stratify=df2.카테고리)
train_dataset = MyDataset(X_train.tolist(), y_train.tolist(), tokenizer)
val_dataset = MyDataset(X_test.tolist(), y_test.tolist(), tokenizer)
a = next(iter(train_dataset))
print(a){'input_ids': tensor([ 2, 3662, 2205, 5209, 3686, 5228, 2170, 4198, 19521, 1335,
2073, 2147, 6578, 12262, 2069, 568, 2259, 5047, 18, 5542,
4140, 4215, 2052, 7567, 6301, 35, 3, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0]), 'token_type_ids': tensor([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]), 'attention_mask': tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]), 'labels': tensor(2)}🔵transformer 안에 TrainingArguments 함수 존재
- 평가지표 함수도 추가
from transformers import TrainingArguments, Trainer
import numpy as np
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=-1)
accuracy = (preds == labels).mean()
return {"accuracy": float(accuracy)}
training_args = TrainingArguments(
output_dir="./klue_bert_sentiment",
eval_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
save_total_limit = 1,
report_to="none")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
🔵여태까지 한 코드 → pytorch가 없음. transformer로 진행.
trainer.save_model("./my_model")
tokenizer.save_pretrained("./my_model")
!tar -cvf model.tar /kaggle/working/my_model
tar: Removing leading `/' from member names
/kaggle/working/my_model/
/kaggle/working/my_model/model.safetensors
/kaggle/working/my_model/training_args.bin
/kaggle/working/my_model/tokenizer_config.json
/kaggle/working/my_model/tokenizer.json
/kaggle/working/my_model/config.jsontest = ['이 음식 상한거 같아요. 맛이 이상해요. ']
encodings = tokenizer(test, max_length=64, return_tensors='pt')
encodings = encodings.to(device)
model.eval()
with torch.no_grad():
outputs = model(**encodings)
logits = outputs.logits
probs = torch.softmax(logits, dim=-1)
preds = torch.argmax(probs, dim=-1).tolist()
def predict(text):
encodings = tokenizer(text, max_length=64, return_tensors='pt')
encodings = encodings.to(device)
model.eval()
with torch.no_grad():
outputs = model(**encodings)
logits = outputs.logits
probs = torch.softmax(logits, dim=-1)
preds = torch.argmax(probs, dim=-1).tolist()
return id2label[preds[0]]
🟢로컬에서 돌리기
from transformers import BertTokenizerFast, BertForSequenceClassification
import torch
tokenizer = BertTokenizerFast.from_pretrained("./my_model")
model = BertForSequenceClassification.from_pretrained("./my_model")
model = model.to('cpu')
tokenizer(['안녕하세요'])
device = 'cpu'
id2label = {0: '디지털가전', 1: '의류', 2: '병원', 3: '음식점'}
def predict(text):
encodings = tokenizer(text, max_length=64, return_tensors='pt')
encodings = encodings.to(device)
model.eval()
with torch.no_grad():
outputs = model(**encodings)
logits = outputs.logits
probs = torch.softmax(logits, dim=-1)
preds = torch.argmax(probs, dim=-1).tolist()
return id2label[preds[0]]
predict("TV, 냉장고, 세탁기는 각각 얼마인가요?")🔵디스코드 연동
import nest_asyncio
import discord
import requests
import asyncio
import requests
BOT_TOKEN =
CHANNEL_ID =
TARGET_CHANNEL_ID =
nest_asyncio.apply()
headers = {
"Authorization": f"Bot {BOT_TOKEN}",
"Content-Type": "application/json"
}
intents = discord.Intents.default()
intents.message_content = True
client = discord.Client(intents=intents)
@client.event
async def on_ready():
print(f"Logged in as {client.user}")
print("실시간 채팅 받기....")
@client.event
async def on_message(message):
if message.author == client.user:
return
if message.channel.id == int(TARGET_CHANNEL_ID):
print(f"[{message.author.name}] {message.content}")
prediction = predict(message.content)
msg_url = f'https://discord.com/api/v10/channels/{message.channel.id}/messages'
data = {
'content': str(prediction)
}
loop = asyncio.get_event_loop()
await loop.run_in_executor(None, lambda: requests.post(msg_url, headers=headers, json=data))
client.run(BOT_TOKEN)🟢왜 갑자기 주식하지?
import requests
import io
import pandas as pd
url = "https://finance.naver.com/item/sise_day.naver?code=005930&page={}"
head = {'user-agent' :
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36'}
samsung = pd.concat([pd.read_html(io.StringIO(requests.get(url.format(x), headers=head).text))[0] for x in range(1, 151)])
samsung.dropna(inplace=True)pip install ta
pip install TA-Libimport talib
samsung = samsung.iloc[::-1]
samsung['MA05'] = talib.SMA(samsung['종가'], timeperiod=5)
samsung['MA20'] = talib.SMA(samsung['종가'], timeperiod=20)
samsung['MA60'] = talib.SMA(samsung['종가'], timeperiod=60)
samsung['MA120'] = talib.SMA(samsung['종가'], timeperiod=120)
samsung['RSI_14'] = talib.RSI(samsung['종가'], timeperiod=14)
macd, macdsignal, macdhist = talib.MACD(samsung['종가'], fastperiod=12, slowperiod=26, signalperiod=9 )
samsung['macd'] = macd
samsung['macdsignal'] = macdsignal
samsung['macdhist'] = macdhist
samsung.dropna(inplace=True)
import numpy as np
samsung['target']=np.where(samsung['종가'].shift(-1)>samsung['종가'],1,0)
samsung.to_csv("./samsung.csv",index=False)
Day3
🟢오를지 말지 맞춰보기
X값 생성
import yfinance as yf
import pandas as pd
import talib
samsung = yf.download('005930.KS', start='2015-01-01', end='2026-03-10')
SOX = yf.download('^SOX', start='2020-01-01', end='2026-03-10')
KOSPI = yf.download('^KS11', start='2020-01-01', end='2026-03-10')
df= pd.merge(pd.merge(samsung, SOX, left_index=True, right_index=True, how='inner'), KOSPI,
left_index=True, right_index=True, how='inner')
df2 = df[[( 'Close', '005930.KS'),
( 'High', '005930.KS'),
( 'Low', '005930.KS'),
( 'Open', '005930.KS'),
('Volume', '005930.KS'),
( 'Close', '^SOX'),
( 'Close', '^KS11'),
('Volume', '^KS11')]].copy()
df2.columns = ['Close', 'High', 'Low', 'Open', 'Volume', 'SOX', 'KOSPI', 'KOSPI_Vol']
df2['MA05'] = talib.SMA(df2['Close'], timeperiod=5)
df2['MA20'] = talib.SMA(df2['Close'], timeperiod=20)
df2['MA60'] = talib.SMA(df2['Close'], timeperiod=60)
df2['MA120'] = talib.SMA(df2['Close'], timeperiod=120)
df2['RSI_14'] = talib.RSI(df2['Close'], timeperiod=14)
macd, macdsignal, macdhist = talib.MACD(df2['Close'], fastperiod=12, slowperiod=26, signalperiod=9 )
df2['macd'] = macd
df2['macdsignal'] = macdsignal
df2['macdhist'] = macdhist
Y값 생성
import numpy as np
df2['target'] = np.where(df2['Close'].shift(-1) > df2['Close'], 1, 0)
df2.dropna(inplace=True)슬라이딩 윈도우 기반 시계열 데이터 처리
from sklearn.preprocessing import MinMaxScaler
Train = df2[df2.index < '2025-12-31']
Test = df2[df2.index > '2025-12-31']
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
Train_scaler = scaler.fit_transform(Train)
Test_scaler = scaler.transform(Test)
def create_seq_dataset(data, target_col_idx, window_size):
x, y = [], []
for i in range(len(data) - window_size):
x.append(data[i : i + window_size, :-1])
y.append(data[i + window_size, target_col_idx])
return np.array(x), np.array(y)
X, Y = create_seq_dataset(Train_scaler, -1, 20)
🔵온디바이스는 이런 부분에 민감함.
bf16→ 경량화
양자화 → 4비트.
https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B-gguf-Q4_K_M
- 로컬 LLM에 대한 관심도 향상.
데이터 학습용으로 수정
import torch
x_train_tensor = torch.tensor(X, dtype=torch.float32)
y_train_tensor = torch.tensor(Y, dtype=torch.float32)
from torch.utils.data import TensorDataset, DataLoader
batch_size=16
train_dataset = TensorDataset(x_train_tensor, y_train_tensor)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=False)
next(iter(train_dataset))[0].shape
import torch
from torch.utils.data import TensorDataset, DataLoader
batch_size=16
X_test, Y_test = create_seq_dataset(Test_scaler, -1, 20)
x_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_test_tensor = torch.tensor(Y_test, dtype=torch.float32)
test_dataset = TensorDataset(x_test_tensor, y_test_tensor)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
val_loader = test_loader 🔵LSTM 모델로 설계
import torch.nn as nn
import torch.optim as optim
class StockLSTM(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, num_classes):
super(StockLSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :])
return out
input_size = X.shape[-1]
hidden_size = 64
num_layers = 1
num_classes = 2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = StockLSTM(input_size, hidden_size, num_layers, num_classes).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
epochs = 150
모델 학습
for epoch in range(epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs = inputs.to(device)
labels = labels.squeeze().long().to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
model.eval()
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for val_inputs, val_labels in val_loader:
val_inputs = val_inputs.to(device)
val_labels = val_labels.squeeze().long().to(device)
val_outputs = model(val_inputs)
# loss 계산
v_loss = criterion(val_outputs, val_labels)
val_loss += v_loss.item()
# 정확도
_, predicted = torch.max(val_outputs.data, 1)
total += val_labels.size(0)
correct += (predicted == val_labels).sum().item()
if (epoch + 1) % 10 == 0:
train_loss_avg = running_loss / len(train_loader)
val_loss_avg = val_loss / len(val_loader)
val_accuracy = 100 * correct / total
print(f'Epoch [{epoch + 1}/{epochs}], '
f'Train Loss: {train_loss_avg:.4f}, '
f'Val Loss: {val_loss_avg:.4f}, '
f'Val Accuracy: {val_accuracy:.2f}%')
🔵Transformer 모델의 인코더 활용하여 예측 시도
#input_dim: 주식 데이터의 x값(특성)
#d_model : 트랜스포머의 내부 임베딩 차원
#num_heads : 멀티 헤드 어텐션의 수
#num_layers: 트랜스포머 인코더 레이어의 수
#output: 예측할 타켓의 차원 수
#input_dim: 주식 데이터의 x값(특성)
#d_model : 트랜스포머의 내부 임베딩 차원
#num_heads : 멀티 헤드 어텐션의 수
#num_layers: 트랜스포머 인코더 레이어의 수
#output: 예측할 타켓의 차원 수
class TimeSeriesTransformer(nn.Module):
def __init__(self, input_dim: int, d_model: int, num_heads: int, num_layers: int, output_dim: int = 1, dropout: float = 0.1):
super(TimeSeriesTransformer, self).__init__()
self.input_projection = nn.Linear(input_dim, d_model)
self.pos_encoder = PositionalEncoding(d_model, dropout)
encoder_layers = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=num_heads,
dropout=dropout,
batch_first=True
)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers)
self.decoder = nn.Linear(d_model, output_dim)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.input_projection.bias.data.zero_()
self.input_projection.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, src: torch.Tensor):
src = self.input_projection(src) * math.sqrt(self.input_projection.out_features)
src = self.pos_encoder(src)
output = self.transformer_encoder(src)
last_step_output = output[:, -1, :]
prediction = self.decoder(last_step_output)
return prediction
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, dropout: float = 0.1, max_len: int = 5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
position = torch.arange(max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_len, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x: torch.Tensor):
x = x + self.pe[:x.size(1)].transpose(0, 1)
return self.dropout(x)
import math
model = TimeSeriesTransformer(input_dim=16, d_model=64, num_heads=4, num_layers=2, output_dim=1, dropout=0.1)
def train_transformer_model(
model: nn.Module,
train_dataloader: DataLoader,
val_dataloader: DataLoader,
num_epochs: int = 50,
learning_rate: float = 1e-4
):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=1e-4)
print(f"학습 시작: 디바이스 = {device}, 총 에포크 = {num_epochs}")
for epoch in range(num_epochs):
model.train()
train_loss = 0.0
train_correct = 0
train_total = 0
for batch_idx, (X_batch, y_batch) in enumerate(train_dataloader):
X_batch = X_batch.to(device)
y_batch = y_batch.to(device)
y_batch = y_batch.view(-1, 1).float()
optimizer.zero_grad()
outputs = model(X_batch)
loss = criterion(outputs, y_batch)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
train_loss += loss.item() * X_batch.size(0)
predicted_labels = (outputs > 0.0).float()
train_correct += (predicted_labels == y_batch).sum().item()
train_total += y_batch.size(0)
avg_train_loss = train_loss / train_total
train_accuracy = train_correct / train_total * 100
# 검증 단계
model.eval()
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad():
for X_val, y_val in val_dataloader:
X_val = X_val.to(device)
y_val = y_val.to(device)
y_val = y_val.view(-1, 1).float()
val_outputs = model(X_val)
loss = criterion(val_outputs, y_val)
val_loss += loss.item() * X_val.size(0)
val_predicted = (val_outputs > 0.0).float()
val_correct += (val_predicted == y_val).sum().item()
val_total += y_val.size(0)
avg_val_loss = val_loss / val_total
val_accuracy = val_correct / val_total * 100
if (epoch + 1) % 10 == 0 or epoch == 0:
print(f"Epoch [{epoch + 1}/{num_epochs}] "
f"Train Loss: {avg_train_loss:.4f} | Train Acc: {train_accuracy:.2f}% || "
f"Val Loss: {avg_val_loss:.4f} | Val Acc: {val_accuracy:.2f}%")
print("모델 학습 및 검증이 완료되었습니다.")
return model
trained_model = train_transformer_model(model, train_loader, test_loader , num_epochs=50, learning_rate=0.001)
학습 시작: 디바이스 = cuda, 총 에포크 = 50
Epoch [1/50] Train Loss: 0.7126 | Train Acc: 51.17% || Val Loss: 0.6792 | Val Acc: 59.09%
Epoch [10/50] Train Loss: 0.6954 | Train Acc: 52.11% || Val Loss: 0.7098 | Val Acc: 40.91%
Epoch [20/50] Train Loss: 0.6938 | Train Acc: 52.89% || Val Loss: 0.7120 | Val Acc: 40.91%
Epoch [30/50] Train Loss: 0.6928 | Train Acc: 53.35% || Val Loss: 0.7121 | Val Acc: 40.91%
Epoch [40/50] Train Loss: 0.6922 | Train Acc: 53.35% || Val Loss: 0.7108 | Val Acc: 40.91%
Epoch [50/50] Train Loss: 0.6927 | Train Acc: 53.35% || Val Loss: 0.7074 | Val Acc: 40.91%
모델 학습 및 검증이 완료되었습니다.
면접데이터로 만들기.
import os
os.environ['CUDA_LAUNCH_BLOCKING'] = "1"
import json
import torch
from torch.utils.data import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, Trainer, TrainingArguments, PreTrainedTokenizerFast
model_name = "skt/kogpt2-base-v2"
tokenizer = PreTrainedTokenizerFast.from_pretrained(
"skt/kogpt2-base-v2",
bos_token='</s>',
eos_token='</s>',
unk_token='<unk>',
pad_token='<pad>',
mask_token='<mask>'
)
model = AutoModelForCausalLM.from_pretrained(model_name)
target = "/content/drive/MyDrive/02.라벨링데이터/"
file_list = [f"{roots}/{file}" for roots, dirs, files in os.walk(target) for file in files]
class InterviewDataset(Dataset):
def __init__(self, json_data_list, tokenizer, max_length=512):
self.tokenizer = tokenizer
self.max_length = max_length
self.examples = []
# if tokenizer.pad_token is None:
# self.tokenizer.add_special_tokens({'pad_token': '[PAD]'})
for file in json_data_list:
# print(file)
with open(file, 'r') as f:
data = f.read()
try:
data = json.loads(data)
except:
continue
question = data["dataSet"]["question"]["raw"]["text"]
answer = data["dataSet"]["answer"]["raw"]["text"]
text = f"질문: {question}\n답변: {answer}{self.tokenizer.eos_token}"
tokenized = self.tokenizer(
text,
truncation=True,
max_length=self.max_length,
padding='max_length',
return_tensors="pt"
)
# ids 복사
input_ids = tokenized["input_ids"].squeeze()
attention_mask = tokenized["attention_mask"].squeeze()
labels = input_ids.clone()
labels[attention_mask == 0] = -100
self.examples.append({
"input_ids": input_ids,
"attention_mask": attention_mask,
"labels": labels
})
def __len__(self):
return len(self.examples)
def __getitem__(self, idx):
return self.examples[idx]
train_dataset = InterviewDataset(file_list, tokenizer)
training_args = TrainingArguments(
output_dir="./interview_model",
num_train_epochs=1,
save_strategy="epoch",
per_device_train_batch_size=4,
save_steps=500,
logging_steps=100,
learning_rate=5e-5,
weight_decay=0.01,
fp16=True,
save_total_limit = 1,
dataloader_num_workers=2)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
)
trainer.train()
model.eval()
prompt = "특별히 가고 싶은 회사가 있으시니까 특정 도메인이 중요한지 회사의 분위기가 중요한지 어떤 점을 중점적으로 보시는지가 궁금합니다"
inputs = tokenizer(prompt, return_tensors="pt").to('cuda')
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=150,
temperature=0.1,
top_p=0.9,
repetition_penalty=1.2,
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id
)
generated_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
save_dir = "./mymodel"
model.save_pretrained(save_dir)
tokenizer.save_pretrained(save_dir)
!tar -cvf ./mymodel.tar /content/mymodel
Day4
🟢로컬에서 면접 데이터
- 로그가 터지는 부분 해결.
OpenMP 라이브러리(libiomp5md.dll) 중복 로드로 인한 커널 충돌 오류입니다.
해결 방법 1: Jupyter Notebook 최상단 셀에 환경 변수 코드 추가
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_dir = "./mymodel"
tokenizer = AutoTokenizer.from_pretrained(model_dir)🔵비동기처리는 중요하다.
async를 중시할 것. 업무에서도 필요할 수 있다.
import time
import asyncio
async def temp(para1, para2):
print(f"{para1} 작업 시작")
await asyncio.sleep(para2)
print("작업 완료")
async def main():
start = time.time()
result = await asyncio.gather(
temp('작업1', 2),
temp('작업2', 1),
temp('작업3', 3)
)
print(f"{time.time() - start}")
asyncio.run(main())- 리소스 줄이기
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import discord
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_dir = "./mymodel"
BOT_TOKEN =
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForCausalLM.from_pretrained(model_dir)
model = model.to('cpu')
intents = discord.Intents.default()
intents.message_content = True
client = discord.Client(intents=intents)
def inference(prompt):
model.eval()
inputs = tokenizer(prompt, return_tensors="pt").to('cpu')
with torch.no_grad():
output_ids = model.generate(
**inputs,
max_new_tokens=100,
temperature=0.1,
top_p=0.9,
repetition_penalty=1.5,
do_sample=True,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id
)
generated_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
return generated_text.split("답변:")[-1].strip()[:100]
@client.event
async def on_ready():
print(f'실시간 수신 대기 중... 로그인 완료: {client.user}')
@client.event
async def on_message(message):
TARGET_CHANNEL_ID =
try:
if message.channel.id == TARGET_CHANNEL_ID:
print(f"[{message.author.name}] {message.content}")
result = inference(message.content)
await message.reply('🔵🔵🔵'+result)
except Exception as e:
print(e)
await message.channel.send("AI가 아픔")
client.run(BOT_TOKEN)
- 크론탭→ 리눅스 기반 자동화. airflow. 쿠버네티스 위 에어플로우
🔵llm 만져보기
from dotenv import load_dotenv
load_dotenv()
import os
os.environ.get("OPENAI_API_KEY")
from openai import OpenAI
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))https://developers.openai.com/api/docs/models/gpt-4o-mini
response = client.chat.completions.create(
model="gpt-4o-mini-2024-07-18",
messages=[
{'role' : 'system', 'content' : "넌 지금부터 사람이야. 사람처럼 행동해"},
{'role' : 'user' , 'content' : "누구냐 넌?"}
],
temperature=0.4
)
print(response.choices[0].message.content)안녕하세요! 저는 여러분과 대화하고 정보를 제공하기 위해 만들어진 AI입니다. 궁금한 점이나 이야기하고 싶은 주제가 있다면 언제든지 말씀해 주세요!
토큰 계산 라이브러리 활용
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-4o-mini-2024-07-18")
len(encoding.encode("OpenAI가 개발한 새로운 AI 모델에 액세스하기 위한 API를 공개합니다."))
19
🔵LLM을 위한 함수 정의하는 법.
def calc_area(width : float, height: float) -> float:
"""
width : 실수(가로 길이)
height : 실수(세로 길이)
-> 반환값 : 실수(넓이)
"""
return width * height
name : str = "플레이데이터"
age : int = 30
is_student : bool = True파이썬에서 llm 코딩때는 pydantic. hint, helper 추가
from typing import Optional, Union- 데이터를 위한 상자
- 힌트에서 인풋이 리스트. 아웃풋이 딕셔너리임을 알 수 있다
def process_scores(scores: list[int]) -> dict[str, float]:
"""
scores : 점수들의 리스트(예: [85, 90, 78])
반환 : 이름을 키로 , 평균을 값으로 하는 딕셔너리
"""
average = sum(scores) / len(scores)
return {"average" : average, "max" : max(scores)}process_scores([60,50,70,100]){'average': 70.0, 'max': 100}
def find_user(user_id : int) -> Optional[str]:
"""
사용자를 찾으면 이름(str)를 반환하고, 찾지 못하면 None을 반환
"""
if user_id == 1:
return "Alice"
return None
def parse_input(value : Union[str, int]) -> int:
"""
문자열이나 정수를 입력 받아서, 리턴
"""
if isinstance(value, str):
return int(value)
return valuehttps://docs.python.org/3.5/library/typing.html#module-typing
pydantic
- 아웃풋을 위한 형태 조절
- 원하는 형태가 안나오면 꼬이지 않게 미리 에러낼 수 있다
from pydantic import BaseModel
class Student(BaseModel):
name:str
age:int
email:str
gpa: float
std1 = Student(name='엔코아', age=20, email='encore@encore.com', gpa=4.5)
try:
std2 = Student(name=123, age=20, email='encore@encore.com', gpa=4.5)
except:
print("값을 똑바로 넣어")
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
text = """4차 산업혁명 시대의 도래로
금융 분야에서 IT 기술의 중요성은 점점 더 커지고 있습니다.
또한, 글로벌화로 국가 간 경계가 좁아지며
다양한 국가들과의 교류가 활발해지고 있습니다.
삼성증권은 이러한 흐름에 맞춰 개인, 기관, 외국인에게
국내외 금융 투자 인프라를 제공하고 있으며,
차세대 생성형 인공지능 기업에 집중적으로 투자하는 등
대한민국을 대표하는 금융회사로 자리매김하고 있습니다.
저는 컴퓨터공학을 전공하면서 금융 분야에 대한 깊은 관심을 갖게 되었고,
삼성증권에서 금융과 IT 기술을 융합한 인재로 성장하고 싶다는 꿈을 키워왔습니다.
학업 외에도 금융을 도메인으로 한 다양한 프로젝트들을 수행하며
금융 지식을 실무적으로 적용하는 경험을 쌓았고,
이 과정에서 팀원들과의 협업을 통해 문제를 해결하는 능력과 원활한 커뮤니케이션 역량을 길렀습니다.
또한, 글로벌 금융 환경에서의 경쟁력을 강화하기 위해
오픽 IH 등급과 JLPT N2 자격을 취득했으며,
영어로 유튜브 영상을 제작해 조회수 2천 회를 달성하는 등 창의성과 열정을 입증했습니다.
이러한 경험을 바탕으로 삼성증권의 IT 직무에서 제 전공 지식과 경험을 통해
혁신적인 금융 서비스 개발에 기여하고,
글로벌 시장에서의 경쟁력을 강화하는 데 기여하고 싶습니다.
대한민국을 대표하는 금융회사인 삼성증권과 함께 성장해 나가겠습니다.
대학생 대외활동 공모전 채용 사이트 링커리어 """
client = OpenAI()
text = """4차 산업혁명 시대의 도래로
금융 분야에서 IT 기술의 중요성은 점점 더 커지고 있습니다.
또한, 글로벌화로 국가 간 경계가 좁아지며
다양한 국가들과의 교류가 활발해지고 있습니다.
삼성증권은 이러한 흐름에 맞춰 개인, 기관, 외국인에게
국내외 금융 투자 인프라를 제공하고 있으며,
차세대 생성형 인공지능 기업에 집중적으로 투자하는 등
대한민국을 대표하는 금융회사로 자리매김하고 있습니다.
저는 컴퓨터공학을 전공하면서 금융 분야에 대한 깊은 관심을 갖게 되었고,
삼성증권에서 금융과 IT 기술을 융합한 인재로 성장하고 싶다는 꿈을 키워왔습니다.
학업 외에도 금융을 도메인으로 한 다양한 프로젝트들을 수행하며
금융 지식을 실무적으로 적용하는 경험을 쌓았고,
이 과정에서 팀원들과의 협업을 통해 문제를 해결하는 능력과 원활한 커뮤니케이션 역량을 길렀습니다.
또한, 글로벌 금융 환경에서의 경쟁력을 강화하기 위해
오픽 IH 등급과 JLPT N2 자격을 취득했으며,
영어로 유튜브 영상을 제작해 조회수 2천 회를 달성하는 등 창의성과 열정을 입증했습니다.
이러한 경험을 바탕으로 삼성증권의 IT 직무에서 제 전공 지식과 경험을 통해
혁신적인 금융 서비스 개발에 기여하고,
글로벌 시장에서의 경쟁력을 강화하는 데 기여하고 싶습니다.
대한민국을 대표하는 금융회사인 삼성증권과 함께 성장해 나가겠습니다.
대학생 대외활동 공모전 채용 사이트 링커리어 """
class UserProfile(BaseModel):
certi : list[str]
resp = client.beta.chat.completions.parse(
model = "gpt-4o-mini-2024-07-18",
messages=[
{'role' : 'system', 'content' : '주어진 글에서 자격증 정보를 추출할 것'},
{'role' : 'user', 'content' : text}
],
response_format=UserProfile
)
resp.choices[0].message.parsed
🟢runpod을 시작하다
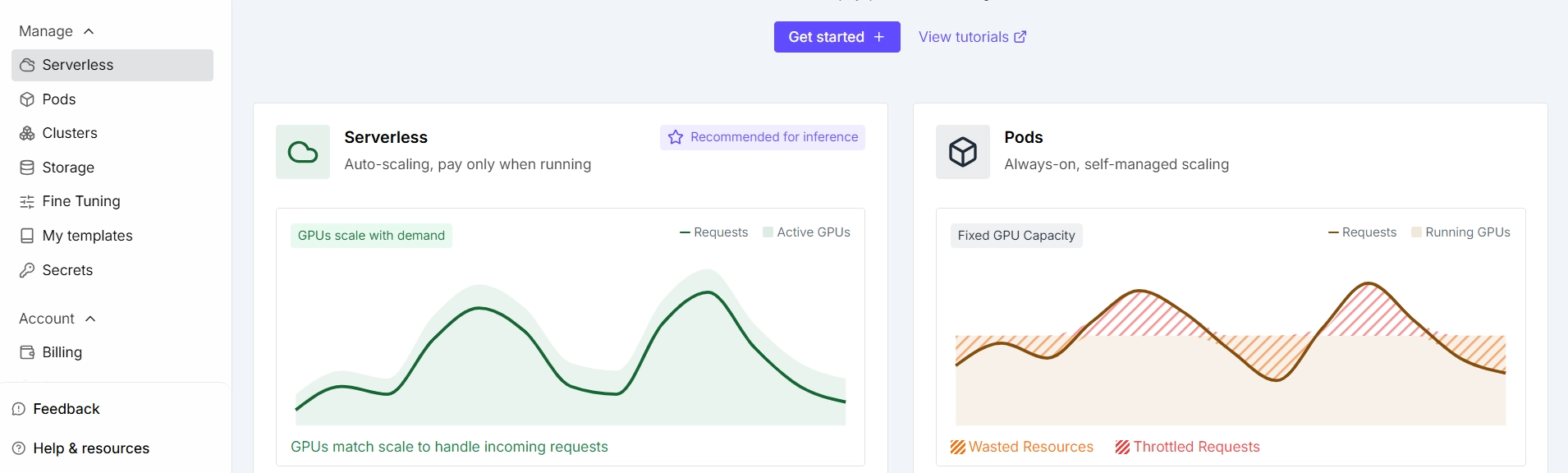
- serverless → 서버 구축은 좀 덜 한다는 의미
- 환경 구축 필요없이 코드만 들고 간다는 뜻
- pods → 쿠버네티스 기반
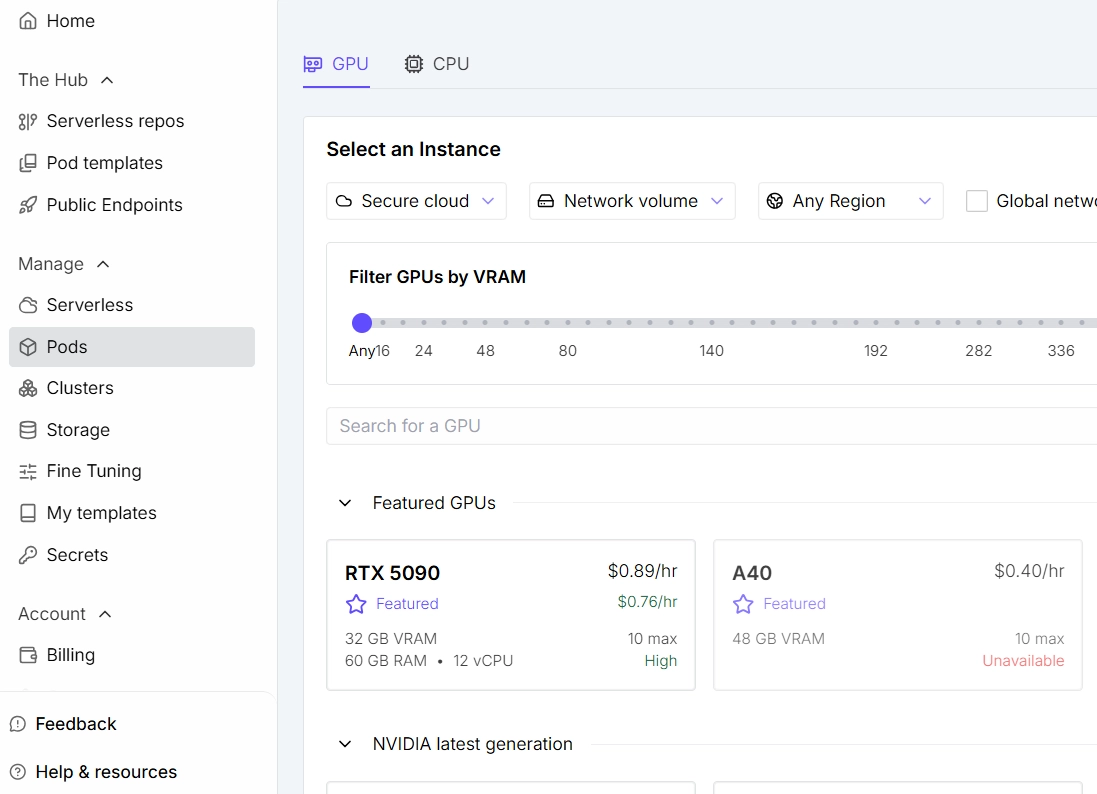
- gpu 선택 시 설정이 뜬다
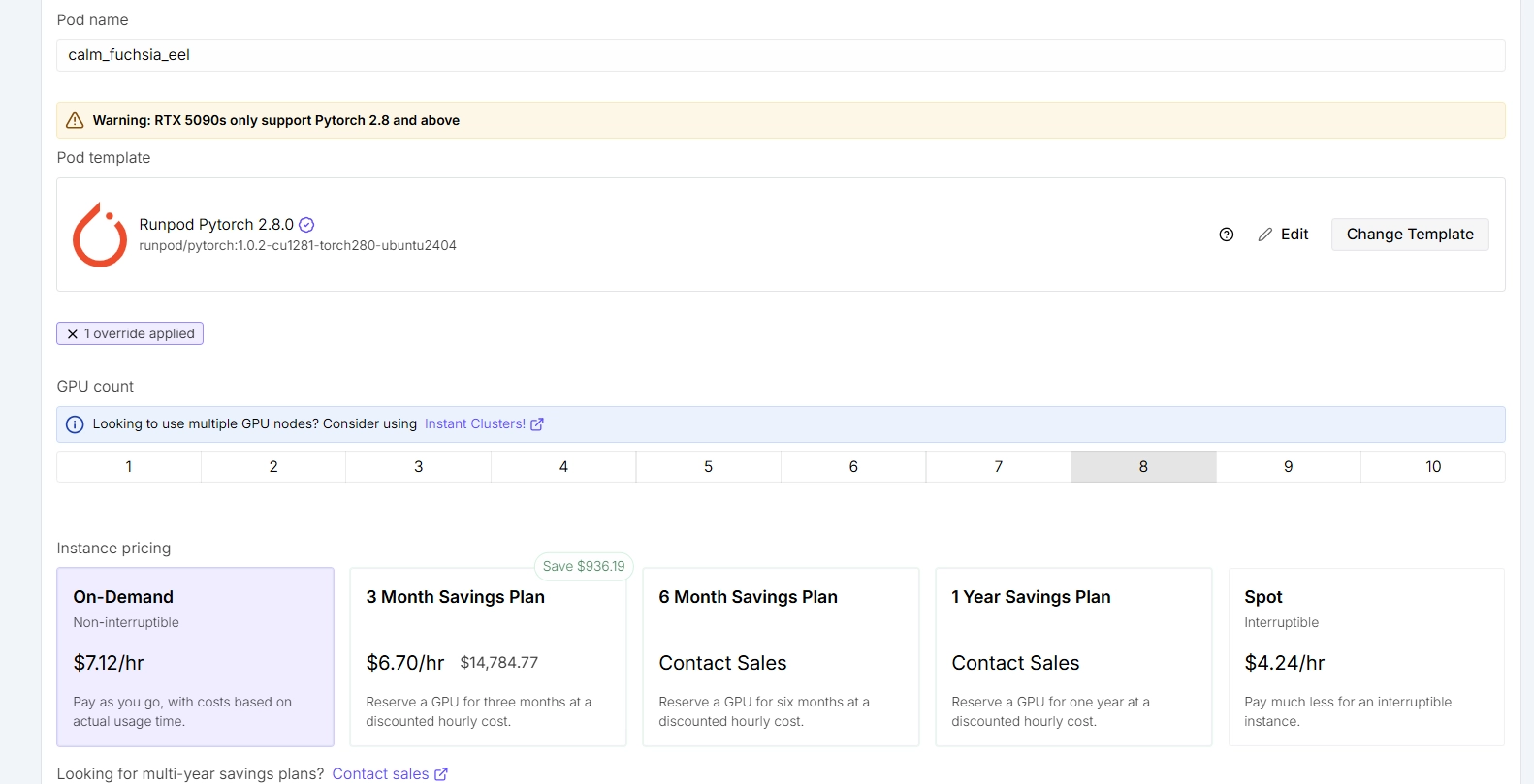
- FTP, NAS
공개키 - 개인키
🔵filezilla, putty