Day1
MongoDB
- NoSQL 중 하나
- json 형태로 저장한다.
- 1.1 RDB(관계형)와의 차이
- RDB: 테이블/행/열, 정규화, 조인 중심, 스키마 엄격
- MongoDB: 컬렉션/문서, 중첩 구조(embedded) 자연스러움, 조인도 가능하지만 기본은 문서 모델 중심
- 1.2 잘 맞는 상황
- 로그/이벤트/트래킹 데이터
- 콘텐츠 관리(CMS), 사용자 프로필(필드가 자주 변함)
- 빠르게 바뀌는 요구사항(필드 추가/변경 잦음)
- 마이크로서비스에서 서비스별 데이터 모델을 독립적으로 운영
- DB 분산처리를 위한 sharding
도커 실행
sudo service docker status
sudo service docker start
도커 이미지 설치
docker run -d \
--name mongodb \
-p 27017:27017 \
-v mg_data:/data/db \
-e MONGO_INITDB_ROOT_USERNAME=admin \
-e MONGO_INITDB_ROOT_PASSWORD=123 \
mongodb/mongodb-community-server:latest
docker ps
compass 설치
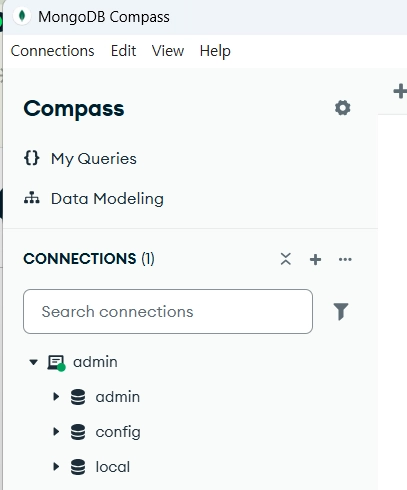
connection 시 접속 가능
파이썬으로 접속 시도
설치
pip install pymongofrom pymongo import MongoClient
uri = "mongodb://admin:123@localhost:27017/"
client = MongoClient(uri)
db = client['test_database']
collection = db['users']
collection.insert_one({'name' : 'bts', 'age' : 25})
InsertOneResult(ObjectId('69a62c5b31ccc3550396c926'), acknowledged=True)
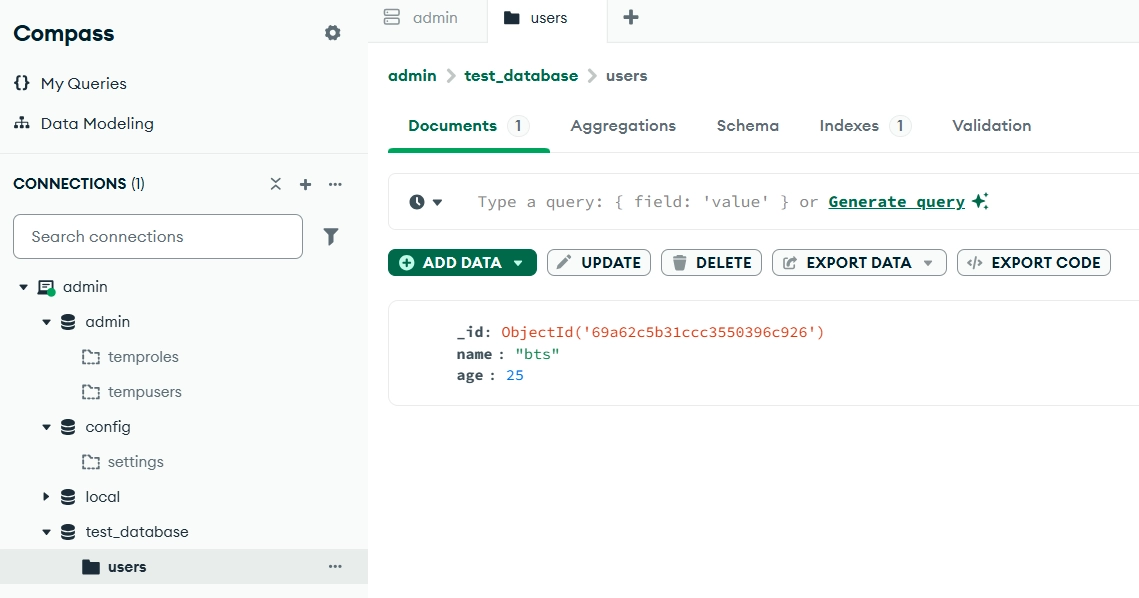
- collection : 테이블같은 느낌.
gpt 계열에서 사용하는 vectorizor
워드임베딩 - vector DB에 저장
vector DB 에서 데이터 받아 올 때의 쿼리 - 유사도 계산.
postgresql
- vector db도 받을 수 있고, rdb도 받을 수 있음
설치 명령어
sudo apt update
sudo apt install postgresql postgresql-contrib
상태 확인
sudo service postgresql statuspostgres 접속
sudo -i -u postgres
psql
create user skn25 with password '123';
DB 생성 , USER 생성
postgres=# create user skn25 with password '123';
CREATE ROLE
postgres=# create database encore owner skn25;
CREATE DATABASE
postgres=#
- 나가고 싶을 때는 exit, logout
DBeaver에서 연결
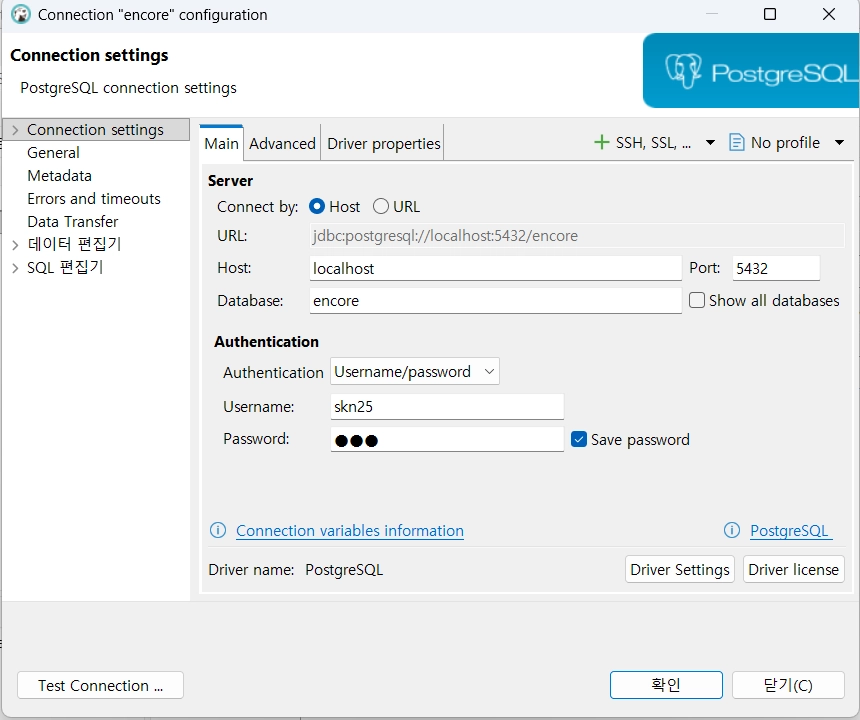
postgre로 vectordb 가능 확장팩 설치
sudo apt install postgresql-16-pgvector
sudo -u postgres psql
CREATE EXTENSION vector;CREATE EXTENSION
현재 데이터베이스 확인
postgres=# select current_database();
current_database
------------------
postgres
(1 row)접속 확인
postgres=# \c encore;
You are now connected to database "encore" as user "postgres".db 접속
ming9@DESKTOP-9B5C8HR:~$ sudo -u postgres psql
psql (16.11 (Ubuntu 16.11-0ubuntu0.24.04.1))
Type "help" for help.
postgres=# \c encore;
You are now connected to database "encore" as user "postgres".
encore=# select current_database();
current_database
------------------
encore
(1 row)encore=# CREATE EXTENSION vector;
CREATE EXTENSION
encore=# CREATE TABLE items (
id bigserial PRIMARY KEY,
embedding vector(1536)
);
CREATE TABLEollama 데이터 넣어보기
설치부터 ^^…!!
설치 후 명령어 쳐서 다운로드
ollama pull embeddinggemma:300m
pip install langchain_ollama
pip install psycopg2-binary pgvector
임베딩 파이썬으로 접속하여 시도
from langchain_ollama import OllamaEmbeddings
embedding = OllamaEmbeddings(model="embeddinggemma:300m")
len(embedding.embed_query("이제 봄입니다.")) #768
- 768차원으로 변경 가능
코사인 유사도로 변형
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
cosine_similarity(embedding.embed_query("usa"), embedding.embed_query("iran"))
np.float64(0.6436208141309766)
긴 텍스트 임베딩 시도
text = ["미국의 이란 공습 직전 미국 국방부 청사인 펜타곤 주변 피자가게 주문량이 증가한 것으로 나타났다. 피자 주문량을 통해 미국 국방부 움직임을 예측할 수 있는 비공식 지표인 '펜타곤 피자 지수'가 이번에도 적중한 것이다.", "X(엑스·옛 트위터) 계정 ‘펜타곤 피자 리포트’(Pentagon Pizza Report)에 따르면, 미국 동부 시각 지난달 28일 오전 1시 28분 기준 펜타곤 인근 피자 가게인 ‘피자토 피자’(Pizzato Pizza)의 주문량이 급증했다. 미국의 이란 공습과 얼마 차이나지 않는 시점이다. 계정은 지난달 27일에도 “오후 2시 42분 기준 펜타곤 인근 여러 피자가게가 높은 주문량을 기록하고 있다”고 밝혔다.",
"펜타곤 주변 피자 주문량을 의미하는 피자 지수는 미국의 대규모 군사 작전과 국방부 인근 피자가게의 주문량 사이 상관관계를 나타내는 비공식적 지표다. 과거 냉전 시대 때부터 펜타곤 인근의 피자 주문량과 군사 작전 사이에는 유의미한 상관관계가 있는 것으로 평가됐다."]
result = embedding.embed_documents(text)
len(result) #3임베딩 값 넣을 table 만들기
import psycopg2
from pgvector.psycopg2 import register_vector
conn = psycopg2.connect(dbname='encore', user='skn25', password='123', host='localhost', port='5432')
cur = conn.cursor()
register_vector(conn)
query ="""
create table documents(
id bigserial primary key,
content text,
embedding vector(768)
)
"""
cur.execute(query)
conn.commit()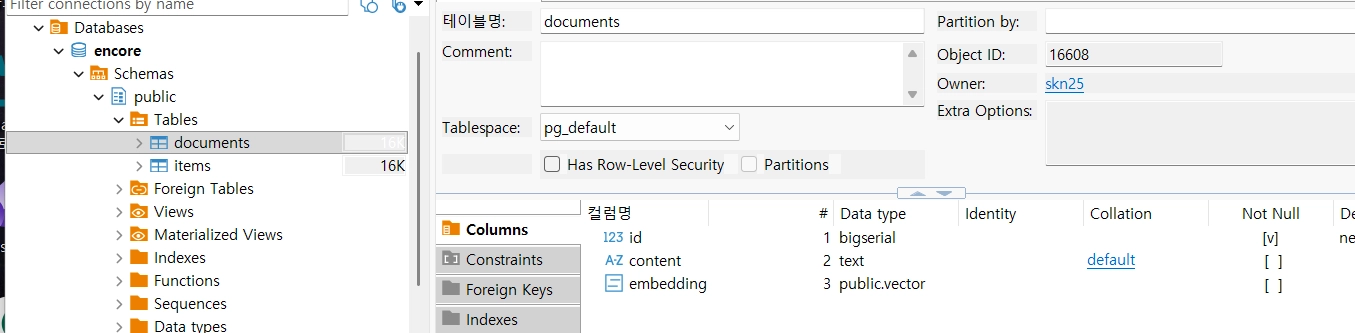
- 벡터 db , postgre에 확장팩 깔아서 사용 중임.
데이터 받아오기
import requests
client_id = "YXw4dmid0O2qTQNfhcY2"
client_secret = "BksteLLT_U"
url = "https://openapi.naver.com/v1/search/news.json"
headers = {
"X-Naver-Client-Id": client_id,
"X-Naver-Client-Secret": client_secret
}
params = {'query' : '이란', 'display' : 10, 'start': 1, "sort" : "sim"}
response = requests.get(url, headers=headers, params=params)
response.json()
{'lastBuildDate': 'Tue, 03 Mar 2026 11:30:17 +0900',
'total': 1045803,
'start': 1,
'display': 10,
'items': [{'title': '<b>이란</b>공격 중 사망한 미군 6명으로 늘어(종합)',
'originallink': 'https://www.yna.co.kr/view/AKR20260302077251071?input=1195m',
'link': 'https://n.news.naver.com/mnews/article/001/0015933214?sid=104',
'description': '이유미 특파원다시 몽고db로 생성
from pymongo import MongoClient
uri = "mongodb://admin:123@localhost:27017/"
client = MongoClient(uri)
db = client['naver']
collection = db['news']collection.insert_many([response.json()])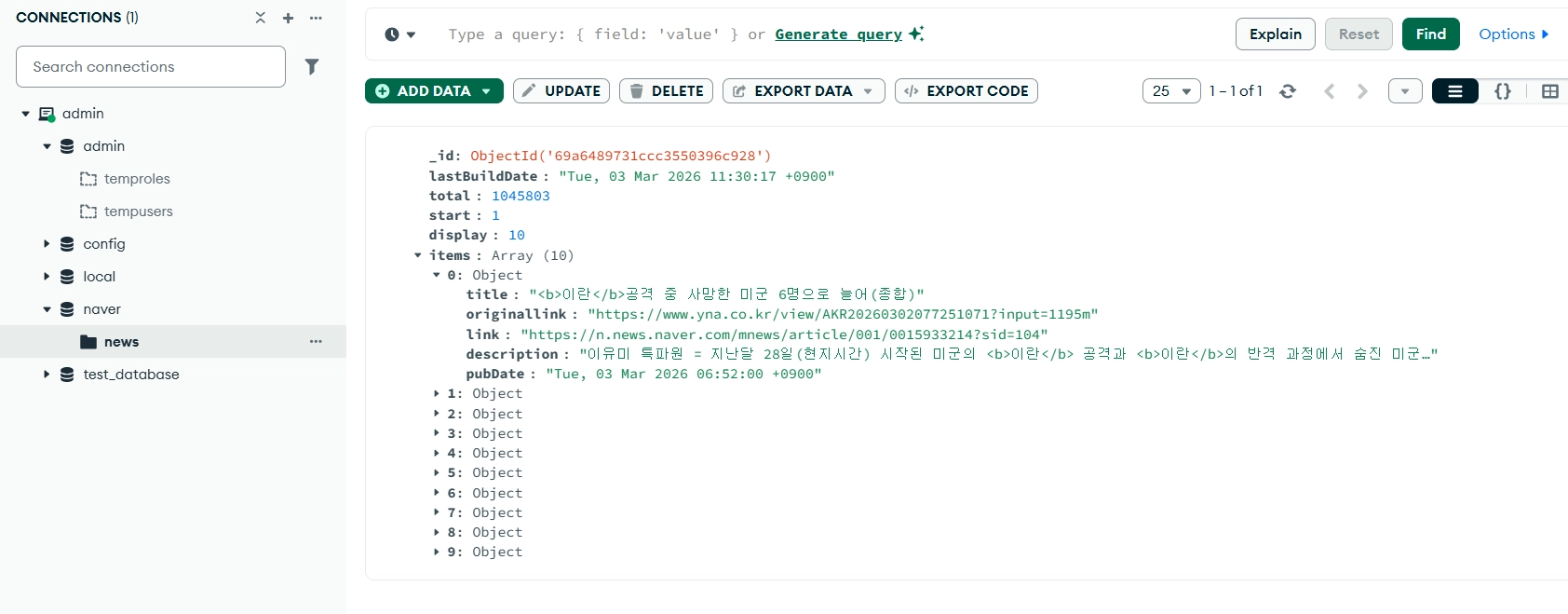
- compass에서 데이터 들어간 것 확인
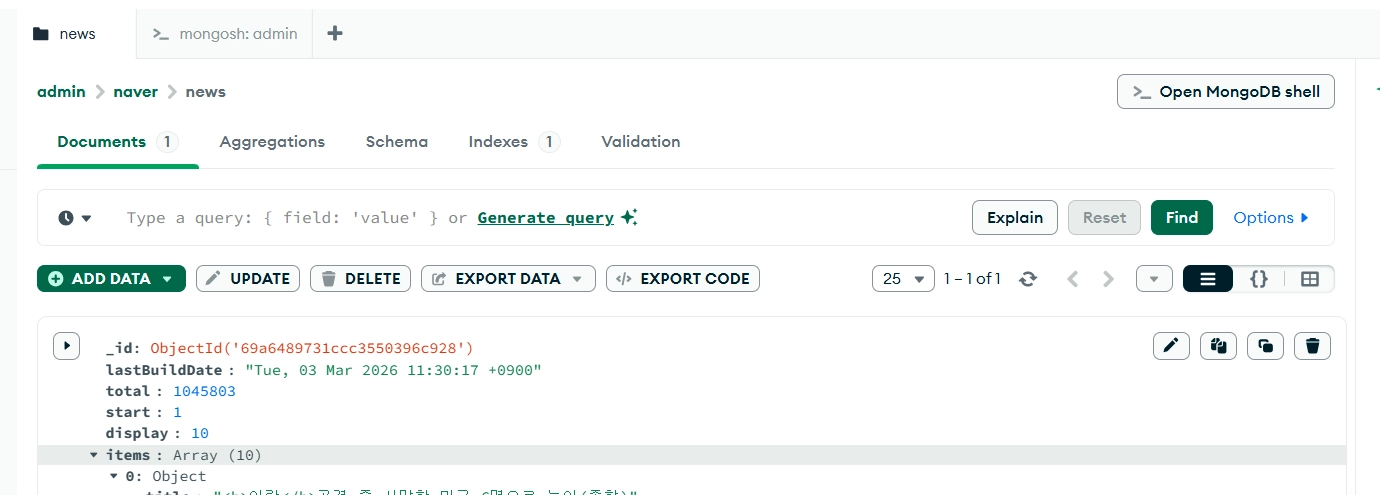
데이터 가져오기
results = collection.find()
for result in results:
print(result)- sql 없이 몽고db는 자체적으로 데이터 호출하는 문법 존재
특정 키워드 들어간 값만 추출하기
query = {"items.title": {"$regex": "트럼프"}}
projection = {"items.title": 1, "_id": 0}
results = collection.find(query,projection )
for result in results:
print(result)
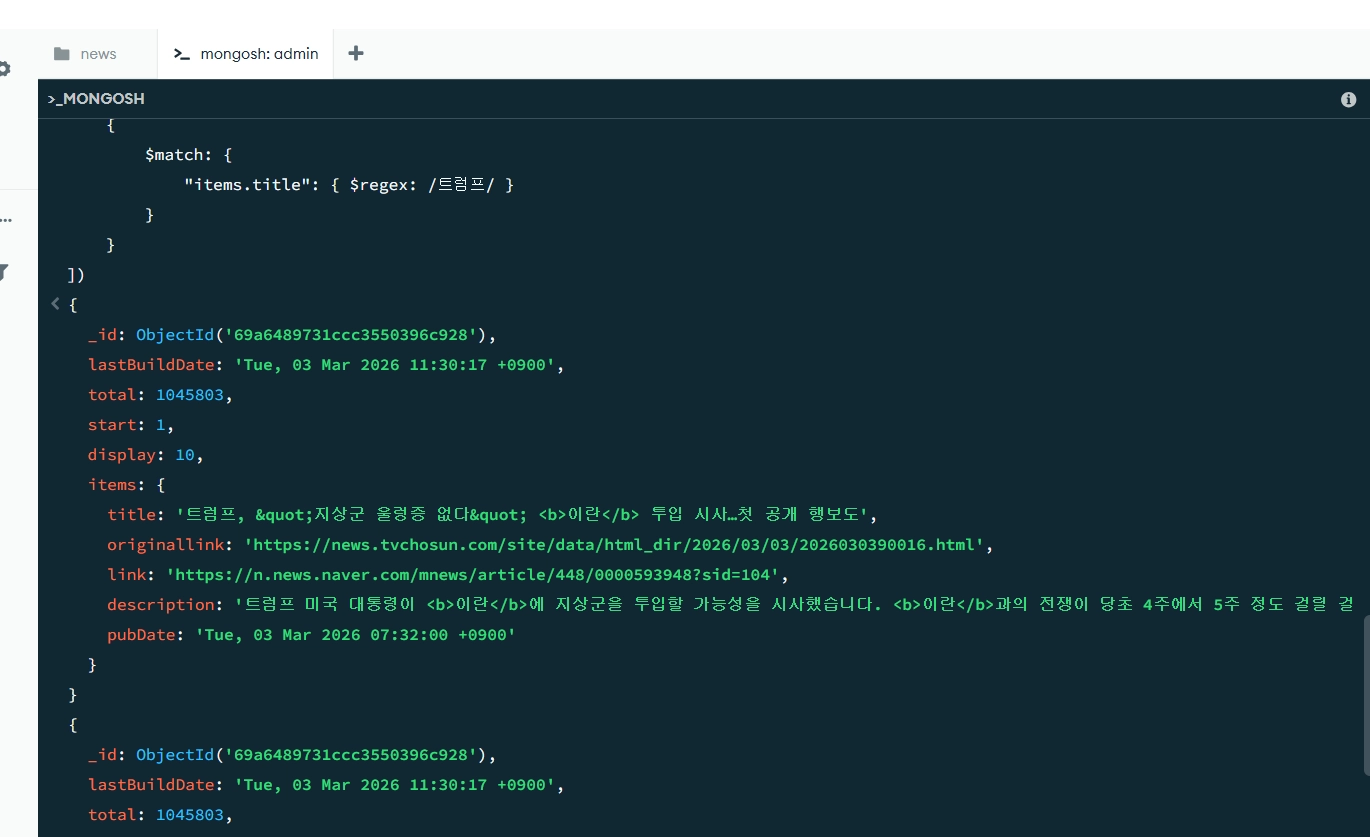
몽고 DB에서 적용되는 리스트 활용
pipeline = [
{"$unwind": "$items"},
{"$match": {"items.title": {"$regex": "트럼프"}}}]
rt = list(collection.aggregate(pipeline))
results = list(collection.find())
results[0]['items'][{'title': '<b>이란</b>공격 중 사망한 미군 6명으로 늘어(종합)',
'originallink': 'https://www.yna.co.kr/view/AKR20260302077251071?input=1195m',
'link': 'https://n.news.naver.com/mnews/article/001/0015933214?sid=104',
'description': '이유미 특파원 = 지난달 28일(현지시간) 시작된 미군의 <b>이란</b> 공격과 <b>이란</b>의 반격 과정에서 숨진 미군이 6명으로 늘어났다. 미 중부사령부는 2일 엑스(X·옛 트위터)에 올린 글에서 "미 동부시간 2일 오후 4시 현재 미군 장병... ',
'pubDate': 'Tue, 03 Mar 2026 06:52:00 +0900'},
{'title': '<b>이란</b> 공격 중 사망한 미군 6명으로 늘어',
'originallink': 'https://www.donga.com/news/Inter/article/all/20260303/133450977/1',
'link': 'https://n.news.naver.com/mnews/article/020/0003700853?sid=104',
'description': '미군의 <b>이란</b> 공격과 <b>이란</b>의 반격 과정에서 숨진 미군이 6명으로 늘어났다. 미 중부사령부는 2일 X를 통해 “미 동부시간 2일 오후 4시 현재 미군 장병 6명이 전사했다”고 밝혔다. 이어 “미군은 최근 <b>이란</b>의 초기 공격 당시... ',
'pubDate': 'Tue, 03 Mar 2026 07:54:00 +0900'},몽고 db가 제공하는 shell
db.news.aggregate([
{
$unwind: "$items"
},
{
$match: {
"items.title": { $regex: /트럼프/ }
}
}
])
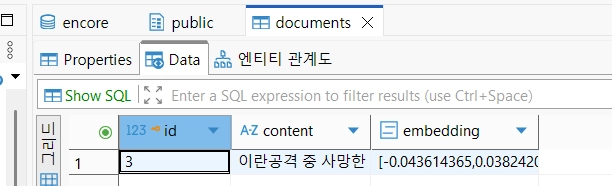
네이버 기사를 몽고db에 저장한 후 거기서 잘 뽑아낸 걸 postgre에 저장.
import psycopg2
from pgvector.psycopg2 import register_vector
conn = psycopg2.connect(dbname='encore', user='skn25', password='123', host='localhost', port='5432')
cur = conn.cursor()
register_vector(conn)
import re
clean = re.sub(r"<[^>]+>", "", items['title'])
clean_embedding = embedding.embed_query(clean)
cur.execute("insert into documents (content, embedding) values (%s, %s)" , (clean, clean_embedding))
conn.commit()
BPE
Byte Pair Encoding
- gpt가 사용함
- “양자역학에 대해서 설명해줘”
- → tokenizer(BPE) → embedding →
- 양자역학에 대해 서 설명해 줘
- 양자역학에 → [0,0,0,0,……………]
- 대해 → [0,0,0,0,……………]
- 서 → [0,0,0,0,……………]
- 설명해 → [0,0,0,0,……………]
- 줘 → [0,0,0,0,……………]
- 허깅페이스에 올라와있는 모델은 파이프라인으로만으로 불러올 수 있음.
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("text-generation", model="meta-llama/Llama-3.1-8B")- 혹은 모델 각각으로도 찾아올 수 있음
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.1-8B")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.1-8B")랭체인
pip install langchain==1.2.10
pip install langchain-community==0.4.1
벡터db
- chroma db, milvus,
도구 설치
- MCP Protocol 설계
- WebBaseLoader
- CrewAI → Multi Agent 설계
- 게임이론을 통해 설계
+) 소켓?
수집 및 활용
from langchain_community.document_loaders import WebBaseLoader
from bs4 import SoupStrainer
bs4_kwargs = {
'parse_only' : SoupStrainer("div", id="newsct_article")
}
rt = WebBaseLoader(rt[0]['items']['link'], bs_kwargs=bs4_kwargs)
rt.load()
rt.load()[0].page_content.strip()
db에 bts 정보 넣기
params = {'query' : 'bts', 'display' : 100, 'start': 1, "sort" : "sim"}
response = requests.get(url, headers=headers, params=params)
data = response.json()
data['items'].__len__()
collection.insert_many(data['items'])- redis → 메모리 기반의 오픈 소스 Key-Value 데이터 구조 저장소
- 챗봇 설계 시 활용 가능
- rabbitmq
- restapi 연동.
- celery
- 파이널 할 때는 붙이면 좋음.
- 분산 작업 큐로 처리하기
- fastapi, celery, redis
data_rt = collection.find()
embedding = OllamaEmbeddings(model="embeddinggemma:300m")
from tqdm import tqdm
for x in tqdm(data_rt[1:]):
url = x['link']
rt = WebBaseLoader(url, bs_kwargs=bs4_kwargs)
content = rt.load()[0].page_content.strip()
embedding_data = embedding.embed_query(content)
cur.execute("insert into documents (content, embbeding) values (%s, %s)" , (content, embedding_data))
conn.commit()
query = """
select content, 1 - (embbeding <=> %s::vector) as score
from documents
where content != ''
order by score desc limit 3
"""
my_question = embedding.embed_query("4월에 열리는 공연은?")
conn = psycopg2.connect(dbname='encore', user='skn25', password='123', host='localhost', port='5432')
cur = conn.cursor()
cur.execute(query, [my_question])
result_cos = cur.fetchall()
Day2
seq2seq
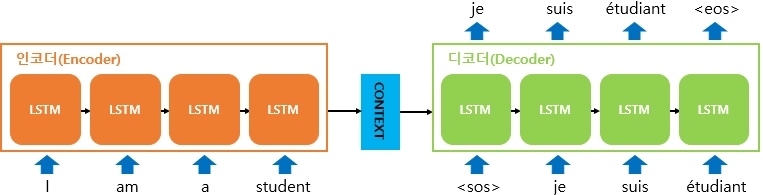
- lstm은 출력 게이트, 입력게이트, 망각 게이트 3개로 구성
- context 벡터 → 메모장
- 인코더 - 입력
- 디코터 - 출력
주요 NLP Task
- 텍스트분류(Text Classification)
- 스팸 이메일 감지, 감정분석, 뉴스 기사 분류 등이 여기에 해당됨
- precision 확인. 진짜 스팸일거만 체크
pydantic
- langchain에 힌트 넘겨주기 좋음
- 특히 ai에게 힌트 좋음
attention 기법
- 문장 중 어디가 중요한 지 수치값으로 넘겨 줌
RNN → LSTM → Seq2Seq → Attention Mechanism → Transformer(시계열 특징이 빠짐)
LLM temperature
- 창의성 지수 → 0으로 두면 항상 정석적으로 두기
- 값을 키우면 창의성이 커짐
GPT는 인과적인 모델
- 인과적 : 원인과 결과의 규칙적인 관계를 나타내는 말

- gpt는 BPE 방식으로 인코딩하기 때문에 모르는 단어, unknown 개념이 없다.
Attention
- Attention is All you need

- 내적을 통해 유사도를 도출해낼 수 있다.
- 삼각함수 활용 .
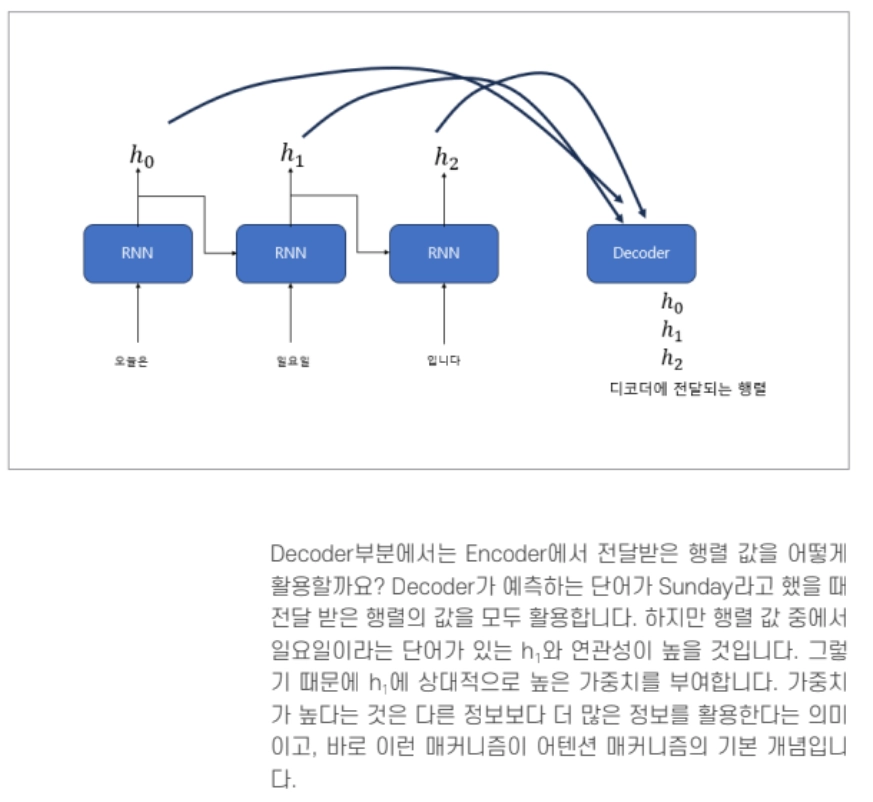
어텐션 매커니즘의 컨셉
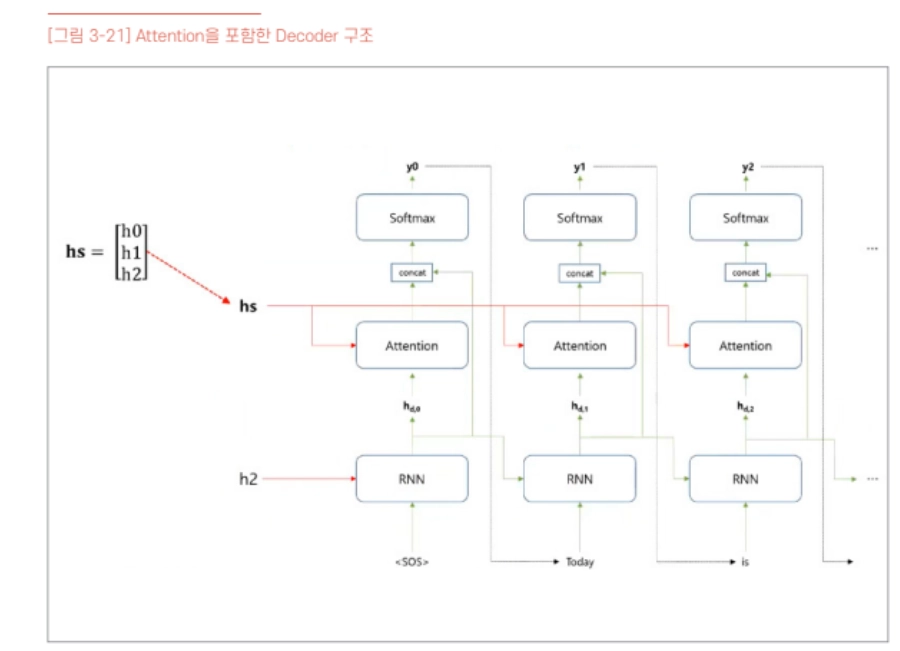
- 가중치의 범위 0~1
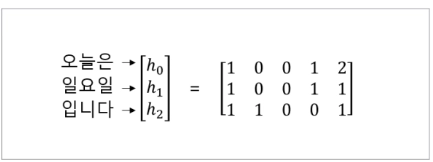

- 유사도 계산 - 속도가 빠른 내적 사용
이 값들을 어텐션 스코어(Attension Score)라고 합니다. 모든
어텐션 스코어의 값은 스칼라입니다.
어텐션 스코어의 값이 클수록 관련도가 크다는 것을 의미합니다. 위의 출력값을 그대로사용하지 않고 위에서 언급했듯이 가중치의 값은 0 ~ 1 사이의 확률 값을 갖는다고 하였습니다.
⇒ softmax 함수 적용

셀프 어텐션
설정 텐서 차원 순서 설명
batch_first=True (배치, 시퀀스, 특성) 배치가 첫 번째 차원
batch_first=False (시퀀스, 배치, 특성) 시퀀스가 첫 번째 차원
모델 코드로 짜보기
import torch
import torch.nn as nn
import torch.optim as optim
import random
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
인코더 설계
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim # 은닉층 차원(context 벡터의 크기)
self.n_layers = n_layers # Lstm 층 수
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=True) #(배치, 시퀀스, 특성)
self.dropout = nn.Dropout(dropout)
def forward(self,src):
embedded = self.dropout(self.embedding(src))# 원문 임베딩 후 드랍아웃 적용
# 2. LSTM을 통해 순방향 전파
# outputs: 모든 시간대의 hidden state (Attention용)
# hidden, cell: 마지막 시간대의 상태 (컨텍스트 벡터 역할)
outputs, (hidden, cell) = self.rnn(embedded)
return outputs, hidden, cell
- cell → context vector
디코더
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim # 출력 어휘 크기
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
# LSTM: 이전 단어와 컨텍스트를 받아 다음 상태 계산
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=True)
# 출력층: LSTM 출력을 어휘 크기의 확률 분포로 변환
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
# input: [batch_size] (현재 시간대의 단어, 1개씩 처리)
# 1. 입력 차원 확장: [batch_size] -> [batch_size, 1]
# LSTM은 (batch, seq_len, feature) 형태를 기대하므로 seq_len=1로 추가
input = input.unsqueeze(1)
# 2. 임베딩 적용
embedded = self.dropout(self.embedding(input))
# embedded: [batch_size, 1, emb_dim]
# 3. LSTM 통과
# hidden, cell: 인코더에서 전달받거나 이전 시간대의 상태
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
# output: [batch_size, 1, hid_dim]
# 4. 선형층을 통해 어휘 크기의 벡터로 변환
prediction = self.fc_out(output.squeeze(1))
# prediction: [batch_size, output_dim] (각 단어의 확률)
return prediction, hidden, cell

https://jbluke.tistory.com/573
- 값을 강제로 넣어줌.
- 학습의 안정을 위해서 교사 강요를 넣음
- I love you → 나는 너를 싫어해(오답, ) 사랑해로 교사 강요 가능.
- 중간 단어가 잘못된 예측이 나오면 뒤가 쭉 깨지기 때문에 존재하는 이론
seq2seq
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim # 출력 어휘 크기
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
# LSTM: 이전 단어와 컨텍스트를 받아 다음 상태 계산
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=True)
# 출력층: LSTM 출력을 어휘 크기의 확률 분포로 변환
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
# input: [batch_size] (현재 시간대의 단어, 1개씩 처리)
# 1. 입력 차원 확장: [batch_size] -> [batch_size, 1]
# LSTM은 (batch, seq_len, feature) 형태를 기대하므로 seq_len=1로 추가
input = input.unsqueeze(1)
# 2. 임베딩 적용
embedded = self.dropout(self.embedding(input))
# embedded: [batch_size, 1, emb_dim]
# 3. LSTM 통과
# hidden, cell: 인코더에서 전달받거나 이전 시간대의 상태
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
# output: [batch_size, 1, hid_dim]
# 4. 선형층을 통해 어휘 크기의 벡터로 변환
prediction = self.fc_out(output.squeeze(1))
# prediction: [batch_size, output_dim] (각 단어의 확률)
return prediction, hidden, cell
데이터 읽어오기.
import sentencepiece as spm
import json
with open("/kaggle/input/datasets/nerffia/kor-jpn/ko2ja_kpop_1_training.json","r") as f:
data=json.load(f)
data[:3]
[{'관리번호': 'KO-JA-2020-KPOP-000501',
'분야': 'K-POP(한류)/대중문화공연콘텐츠',
'한국어': '소속사 측은 두 사람이 친한 것은 맞지만 결혼설은 사실무근이라고 강조했다.',
'일본어': '所属事務所側は、2人が親しいのは事実だが、結婚説は事実無根だと強調した。',
'한국어어절수': 10,
'일본어글자수': 32,
'길이_분류': 2,
'출처': '
http://en.seoul.co.kr/news/newsView.php?id=20190921500037
',
'수행기관': '플리토'},
데이터 확인 및 한국어와 일본어 담기

ko_corpus = "temp_kopus.txt"
jp_corpus = "temp_jppus.txt"
ko_src = open(ko_corpus, "w")
jp_src = open(jp_corpus, "w")
for x in data:
ko_src.write(x['한국어'] + "\n")
jp_src.write(x['일본어'] + "\n")
ko_src.close()
jp_src.close()

sentencepiece
- bpe 기반.
spm.SentencePieceTrainer.train(
input=ko_corpus,
model_prefix='bpe_model',
vocab_size=32000,
model_type='bpe', # BPE 알고리즘 선택
character_coverage=0.9995,
max_sentencepiece_length=32, # 더 긴 서브워드 허용
split_by_whitespace=True,
split_by_unicode_script=True,
treat_whitespace_as_suffix=False, # 공백을 접두사로 (▁token 형태)
allow_whitespace_only_pieces=True, # 공백만으로 된 토큰 허용
normalization_rule_name='nmt_nfkc',
remove_extra_whitespaces=True,
input_sentence_size=10000000, # 천만 문장만 사용
shuffle_input_sentence=True,
seed_sentencepiece_size=1000000, # 초기 시드 크기
shrinking_factor=0.75, # EM 알고리즘 수축률 (unigram만)
num_threads=1 # 모든 코어 사용
)
DAG, pgvector
airflow, spark.가 DAG
랭체인, 랭그래프. 랭스미스
라마인덱스….
GS그룹, 라마인덱스 사용
CrewAI
영어 - 프랑스어 받아오기
import kagglehub
# Download latest version
path = kagglehub.dataset_download("ilhansevval/eng-fra")
print("Path to dataset files:", path)
import re
def normalize_string(s):
"""간단한 텍스트 전처리: 소문자 변환 및 구두점 분리"""
s = s.lower().strip()
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s.strip()
list(map(normalize_string,text[123].split('\t')))
class Vocabulary:
def __init__(self):
self.word2idx = {"<PAD>": PAD_IDX, "<SOS>": SOS_IDX, "<EOS>": EOS_IDX, "<UNK>": UNK_IDX}
self.idx2word = {PAD_IDX: "<PAD>", SOS_IDX: "<SOS>", EOS_IDX: "<EOS>", UNK_IDX: "<UNK>"}
self.idx = 4
def add_sentence(self, sentence):
for word in sentence.split(' '):
if word not in self.word2idx:
self.word2idx[word] = self.idx
self.idx2word[self.idx] = word
self.idx += 1
def __len__(self):
return len(self.word2idx)
import torch
import torch.nn as nn
import torch.optim as optim
import random
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim # 은닉층 차원(context 벡터의 크기)
self.n_layers = n_layers # Lstm 층 수
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=True) #(배치, 시퀀스, 특성)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
# (배치 크기, 원문 길이)
embedded = self.dropout(self.embedding(src))
# 2. LSTM을 통해 순방향 전파
# outputs: 모든 시간대의 hidden state (Attention용)
# hidden, cell: 마지막 시간대의 상태 (컨텍스트 벡터 역할)
outputs, (hidden, cell) = self.rnn(embedded)
return outputs, hidden, cell
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim # 출력 어휘 크기
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
# LSTM: 이전 단어와 컨텍스트를 받아 다음 상태 계산
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout, batch_first=True)
# 출력층: LSTM 출력을 어휘 크기의 확률 분포로 변환
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
# input: [batch_size] (현재 시간대의 단어, 1개씩 처리)
# 1. 입력 차원 확장: [batch_size] -> [batch_size, 1]
# LSTM은 (batch, seq_len, feature) 형태를 기대하므로 seq_len=1로 추가
input = input.unsqueeze(1)
# 2. 임베딩 적용
embedded = self.dropout(self.embedding(input))
# embedded: [batch_size, 1, emb_dim]
# 3. LSTM 통과
# hidden, cell: 인코더에서 전달받거나 이전 시간대의 상태
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
# output: [batch_size, 1, hid_dim]
# 4. 선형층을 통해 어휘 크기의 벡터로 변환
prediction = self.fc_out(output.squeeze(1))
# prediction: [batch_size, output_dim] (각 단어의 확률)
return prediction, hidden, cell
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src: [batch_size, src_len] (원문)
# trg: [batch_size, trg_len] (목표 문장, 번역문)
# teacher_forcing_ratio: 정답 단어를 사용할 확률 (학습 안정화용)
batch_size = trg.shape[0]
trg_len = trg.shape[1]
trg_vocab_size = self.decoder.output_dim
# 출력을 저장할 텐서 초기화
outputs = torch.zeros(batch_size, trg_len, trg_vocab_size).to(self.device)
# 1. 인코더를 통해 컨텍스트 벡터(hidden, cell) 생성
_, hidden, cell = self.encoder(src)
# 2. 디코더의 첫 입력은 <START> 토큰 (보통 인덱스 0 또는 1)
input = trg[:, 0] # 모든 배치의 첫 번째 토큰
# 3. 목표 문장 길이만큼 반복하며 단어 생성
for t in range(1, trg_len):
# 디코더로 다음 단어 예측
output, hidden, cell = self.decoder(input, hidden, cell)
# 예측 결과 저장
outputs[:, t, :] = output
# Teacher Forcing: 정답을 사용할지, 예측값을 사용할지 결정
# 학습 초기에는 정답을 많이 사용하고, 나중에는 모델 예측을 더 사용
teacher_force = random.random() < teacher_forcing_ratio
# 가장 확률 높은 단어 선택 (greedy decoding)
top1 = output.argmax(1)
# 다음 입력 결정: 정답(trg[:, t]) 또는 예측값(top1)
input = trg[:, t] if teacher_force else top1
return outputs
import kagglehub
# Download latest version
path = kagglehub.dataset_download("ilhansevval/eng-fra")
print("Path to dataset files:", path)
!ls -al /kaggle/input/datasets/ilhansevval/eng-fra
with open("/kaggle/input/datasets/ilhansevval/eng-fra/eng-fra.txt") as f:
text = f.read().strip().split('\n')
import re
def normalize_string(s):
"""간단한 텍스트 전처리: 소문자 변환 및 구두점 분리"""
s = s.lower().strip()
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s.strip()
list(map(normalize_string,text[123].split('\t')))
class Vocabulary:
def __init__(self):
self.word2idx = {"<PAD>": PAD_IDX, "<SOS>": SOS_IDX, "<EOS>": EOS_IDX, "<UNK>": UNK_IDX}
self.idx2word = {PAD_IDX: "<PAD>", SOS_IDX: "<SOS>", EOS_IDX: "<EOS>", UNK_IDX: "<UNK>"}
self.idx = 4
def add_sentence(self, sentence):
for word in sentence.split(' '):
if word not in self.word2idx:
self.word2idx[word] = self.idx
self.idx2word[self.idx] = word
self.idx += 1
def __len__(self):
return len(self.word2idx)
import torch
from torch.utils.data import Dataset, DataLoader
from torch.nn.utils.rnn import pad_sequence
class TranslationDataset(Dataset):
def __init__(self, file_path):
self.src_sentences = []
self.trg_sentences = []
self.src_vocab = Vocabulary()
self.trg_vocab = Vocabulary()
# 파일 읽기 및 단어장 구축
with open(file_path, 'r', encoding='utf-8') as f:
lines = f.read().strip().split('\n')
for line in lines:
parts = line.split('\t')
if len(parts) >= 2:
# 텍스트 전처리
src = normalize_string(parts[0])
trg = normalize_string(parts[1])
self.src_sentences.append(src)
self.trg_sentences.append(trg)
self.src_vocab.add_sentence(src)
self.trg_vocab.add_sentence(trg)
def __len__(self):
return len(self.src_sentences)
def __getitem__(self, i):
src_sentence = self.src_sentences[i]
trg_sentence = self.trg_sentences[i]
# 문자열을 인덱스 텐서로 변환 (<SOS>, <EOS> 추가)
src_tensor = [SOS_IDX] + [self.src_vocab.word2idx.get(w, UNK_IDX) for w in src_sentence.split(' ')] + [EOS_IDX]
trg_tensor = [SOS_IDX] + [self.trg_vocab.word2idx.get(w, UNK_IDX) for w in trg_sentence.split(' ')] + [EOS_IDX]
return torch.tensor(src_tensor, dtype=torch.long), torch.tensor(trg_tensor, dtype=torch.long)
# 특수 토큰 정의
PAD_IDX = 0
SOS_IDX = 1
EOS_IDX = 2
UNK_IDX = 3
dataset = TranslationDataset("/kaggle/input/datasets/ilhansevval/eng-fra/eng-fra.txt")
BATCH_SIZE = 128
def collate_fn(batch):
src_batch, trg_batch = [], []
for src_sample, trg_sample in batch:
src_batch.append(src_sample)
trg_batch.append(trg_sample)
# batch_first=True 로 설정하여 [batch_size, seq_len] 형태로 패딩
src_batch = pad_sequence(src_batch, padding_value=PAD_IDX, batch_first=True)
trg_batch = pad_sequence(trg_batch, padding_value=PAD_IDX, batch_first=True)
return src_batch, trg_batch
dataloader = DataLoader(
dataset,
batch_size=BATCH_SIZE,
shuffle=True,
collate_fn=collate_fn,
drop_last=True
)
tmp = next(iter(dataloader))
for i, (src_batch, trg_batch) in enumerate(dataloader):
print(f"입력(src) 배치 크기: {src_batch.shape}")
print(f"타겟(trg) 배치 크기: {trg_batch.shape}")
break
INPUT_DIM = len(dataset.src_vocab) # 영어의 어휘 크기
OUTPUT_DIM = len(dataset.trg_vocab) # 불어의 어휘 크기
EMB_DIM = 256 # 임베딩 차원 (단어를 256차원 벡터로 표현)
HID_DIM = 512 # 은닉층 차원 (메모장의 용량)
N_LAYERS = 2 # LSTM 층 수 (깊이)
DROPOUT = 0.5 # 드롭아웃 비율
# 모델 인스턴스 생성
enc = Encoder(INPUT_DIM, EMB_DIM, HID_DIM, N_LAYERS, DROPOUT)
dec = Decoder(OUTPUT_DIM, EMB_DIM, HID_DIM, N_LAYERS, DROPOUT)
model = Seq2Seq(enc, dec, device).to(device)
# 손실 함수: 패딩 토큰 무시하고 계산 (ignore_index=0 가정)
criterion = nn.CrossEntropyLoss(ignore_index=0)
# 옵티마이저: Adam 사용
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train(model, iterator, optimizer, criterion):
model.train() # 학습 모드 (드롭아웃 활성화)
epoch_loss = 0
for i, (src, trg) in enumerate(iterator):
src, trg = src.to(device), trg.to(device)
optimizer.zero_grad() # 기울기 초기화
# 순전파: teacher_forcing_ratio=0.5로 설정
output = model(src, trg, 0.5)
# output: [batch_size, trg_len, output_dim]
# trg: [batch_size, trg_len]
# 손실 계산을 위해 2D로 변환
output_dim = output.shape[-1]
output = output[:, 1:, :].reshape(-1, output_dim) # <START> 제외
trg = trg[:, 1:].reshape(-1) # <START> 제외
loss = criterion(output, trg)
loss.backward() # 역전파
# 기울기 클리핑 (폭발 방지)
torch.nn.utils.clip_grad_norm_(model.parameters(), 1)
optimizer.step() # 가중치 업데이트
epoch_loss += loss.item()
return epoch_loss / len(iterator)
epochs = 10
for x in range(epochs):
print(f"{x+1} epochs")
train(model, dataloader, optimizer, criterion)
추론 해보기
example_sentence = "i am running."
sentence = normalize_string(example_sentence)
tokens = sentence.split(' ')
src_vocab = dataset.src_vocab
token_indices = [src_vocab.word2idx.get("<SOS>")]
for token in tokens:
token_indices.append(src_vocab.word2idx.get(token, src_vocab.word2idx.get("<UNK>")))
token_indices.append(src_vocab.word2idx.get("<EOS>"))
src_tensor = torch.tensor(token_indices, dtype=torch.long).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
encoder_outputs, hidden, cell = model.encoder(src_tensor)
trg_vocab = dataset.trg_vocab
trg_indices = [trg_vocab.word2idx.get("<SOS>")]
MAX_LEN = 50
for i in range(MAX_LEN):
trg_tensor = torch.tensor([trg_indices[-1]], dtype=torch.long).to(device)
with torch.no_grad():
output, hidden, cell = model.decoder(trg_tensor, hidden, cell)
pred_token = output.argmax(1).item()
trg_indices.append(pred_token)
if pred_token == trg_vocab.word2idx.get("<EOS>"):
break
trg_tokens = []
for i in trg_indices:
trg_tokens.append(trg_vocab.idx2word.get(i, "<UNK>"))
trg_tokens
['', 'je', 'suis', 'en', 'train', 'de', 'dormir', '.', '']
‘
성능 향상 위한 어텐션 추가
class Attention(nn.Module):
def __init__(self, hid_dim):
super().__init__()
self.attn = nn.Linear(hid_dim * 2, hid_dim)
self.v = nn.Linear(hid_dim, 1, bias=False)
def forward(self, hidden, encoder_outputs):
# hidden: [batch_size, hid_dim] (디코더의 현재 상태)
# encoder_outputs: [batch_size, src_len, hid_dim] (인코더의 모든 출력)
src_len = encoder_outputs.shape[1]
# hidden을 src_len만큼 반복: [batch_size, src_len, hid_dim]
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
# 에너지(점수) 계산: [batch_size, src_len, hid_dim]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
# Attention 가중치: [batch_size, src_len]
attention = self.v(energy).squeeze(2)
# 소프트맥스로 정규화 (모든 가중치의 합=1)
return torch.softmax(attention, dim=1)
- 관계 있는 것에 어텐션 주기.
- 현재와 관련 있는 것에 가중치르 ㄹ준다.
https://colab.research.google.com/drive/1hXIQ77A4TYS4y3UthWF-Ci7V7vVUoxmQ?usp=sharing
https://github.com/jessevig/bertviz?tab=readme-ov-

어텐션디코더 선언
class AttnDecoder(nn.Module):
"""
Attention을 사용하는 디코더
"""
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout, attention):
super().__init__()
self.output_dim = output_dim
self.attention = attention
self.embedding = nn.Embedding(output_dim, emb_dim)
# 입력: 임베딩 + 컨텍스트 벡터(어텐션 결과)
self.rnn = nn.LSTM(emb_dim + hid_dim, hid_dim, n_layers, dropout=dropout, batch_first=True)
# 출력: hid_dim -> output_dim (어휘 크기)
self.fc_out = nn.Linear(emb_dim + hid_dim * 2, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell, encoder_outputs):
input = input.unsqueeze(1)
embedded = self.dropout(self.embedding(input))
# embedded: [batch_size, 1, emb_dim]
# Attention 가중치 계산
# hidden[-1]: LSTM의 마지막 층 hidden state 사용
attn_weights = self.attention(hidden[-1], encoder_outputs)
# attn_weights: [batch_size, src_len]
# 가중치를 encoder_outputs에 적용하여 컨텍스트 벡터 생성
attn_weights = attn_weights.unsqueeze(1) # [batch_size, 1, src_len]
context = torch.bmm(attn_weights, encoder_outputs) # [batch_size, 1, hid_dim]
# LSTM 입력: 임베딩 + 컨텍스트 연결
rnn_input = torch.cat((embedded, context), dim=2)
output, (hidden, cell) = self.rnn(rnn_input, (hidden, cell))
# 출력 생성: 임베딩 + hidden + context를 결합하여 예측
embedded = embedded.squeeze(1)
output = output.squeeze(1)
context = context.squeeze(1)
prediction = self.fc_out(torch.cat((embedded, output, context), dim=1))
return prediction, hidden, cell, attn_weights
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
batch_size = trg.shape[0]
trg_len = trg.shape[1]
trg_vocab_size = self.decoder.output_dim
# 텐서 생성 시 device 직접 지정
outputs = torch.zeros(batch_size, trg_len, trg_vocab_size, device=self.device)
# 인코더를 통과시켜 모든 타임스텝의 출력(encoder_outputs) 확보
encoder_outputs, hidden, cell = self.encoder(src)
# 디코더의 첫 입력은 <SOS> 토큰
input = trg[:, 0]
for t in range(1, trg_len):
# 디코더에 encoder_outputs를 추가로 전달
output, hidden, cell, _ = self.decoder(input, hidden, cell, encoder_outputs)
outputs[:, t, :] = output
teacher_force = random.random() < teacher_forcing_ratio
top1 = output.argmax(1)
input = trg[:, t] if teacher_force else top1
return outputs
모델 선언
attn = Attention(HID_DIM)
enc = Encoder(INPUT_DIM, EMB_DIM, HID_DIM, N_LAYERS, DROPOUT)
dec = AttnDecoder(OUTPUT_DIM, EMB_DIM, HID_DIM, N_LAYERS, DROPOUT, attn)
model = Seq2Seq(enc, dec, device).to(device)
epochs = 10
loss = []
for x in range(epochs):
print(f"{x+1} epochs")
error = train(model, dataloader, optimizer, criterion)
print(f"loss -> {error}")
loss.append(error)
추론해보기
example_sentence = "Her older daughter is married"
sentence = normalize_string(example_sentence)
tokens = sentence.split(' ')
src_vocab = dataset.src_vocab
token_indices = [src_vocab.word2idx.get("<SOS>")]
for token in tokens:
token_indices.append(src_vocab.word2idx.get(token, src_vocab.word2idx.get("<UNK>")))
token_indices.append(src_vocab.word2idx.get("<EOS>"))
src_tensor = torch.tensor(token_indices, dtype=torch.long).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
encoder_outputs, hidden, cell = model.encoder(src_tensor)
trg_vocab = dataset.trg_vocab
trg_indices = [trg_vocab.word2idx.get("<SOS>")]
MAX_LEN = 50
for i in range(MAX_LEN):
trg_tensor = torch.tensor([trg_indices[-1]], dtype=torch.long).to(device)
with torch.no_grad():
output, hidden, cell, attention = model.decoder(trg_tensor, hidden, cell, encoder_outputs)
# output, hidden, cell = model.decoder(trg_tensor, hidden, cell,encoder_outputs)
pred_token = output.argmax(1).item()
trg_indices.append(pred_token)
if pred_token == trg_vocab.word2idx.get("<EOS>"):
break
trg_tokens = []
for i in trg_indices:
trg_tokens.append(trg_vocab.idx2word.get(i, "<UNK>"))
미니쿠브 설치
- pods 용어 사용.
curl -LO https://github.com/kubernetes/minikube/releases/latest/download/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube && rm minikube-linux-amd64
minikube start

Day3
배경지식
- gpt - oss - 20b
- 오픈 ai에서 선심쓰듯이 낸 모델
- qwen
MoE
- 동시 연산이 아니라 전문가를 혼합하여 사용.
- 속도 이슈를 해결할 수 있음
- 조금 멍청…
Dense model & Sparse Model
BPE
- gpt 토크나이저.
- 바이트 페어 인코더.
class Attention(nn.Module):
def __init__(self, hid_dim):
super().__init__()
self.attn = nn.Linear(hid_dim * 2, hid_dim)
self.v = nn.Linear(hid_dim, 1, bias=False)
def forward(self, hidden, encoder_outputs):
# hidden: [batch_size, hid_dim] (디코더의 현재 상태)
# encoder_outputs: [batch_size, src_len, hid_dim] (인코더의 모든 출력)
src_len = encoder_outputs.shape[1]
# hidden을 src_len만큼 반복: [batch_size, src_len, hid_dim]
hidden = hidden.unsqueeze(1).repeat(1, src_len, 1)
# 에너지(점수) 계산: [batch_size, src_len, hid_dim]
energy = torch.tanh(self.attn(torch.cat((hidden, encoder_outputs), dim=2)))
# Attention 가중치: [batch_size, src_len]
attention = self.v(energy).squeeze(2)
# 소프트맥스로 정규화 (모든 가중치의 합=1)
return torch.softmax(attention, dim=1)
- 에너지 점수 수식 기반 연산
- 번역 테스크이므로, 어텐션이 지도 학습이다.
prompt
- CoT ,에이전트 만들 때 중요함
셀프 어텐션
- attention is all you need
- 상대적으로 시계열성을 무시한다고 볼 수 있다.
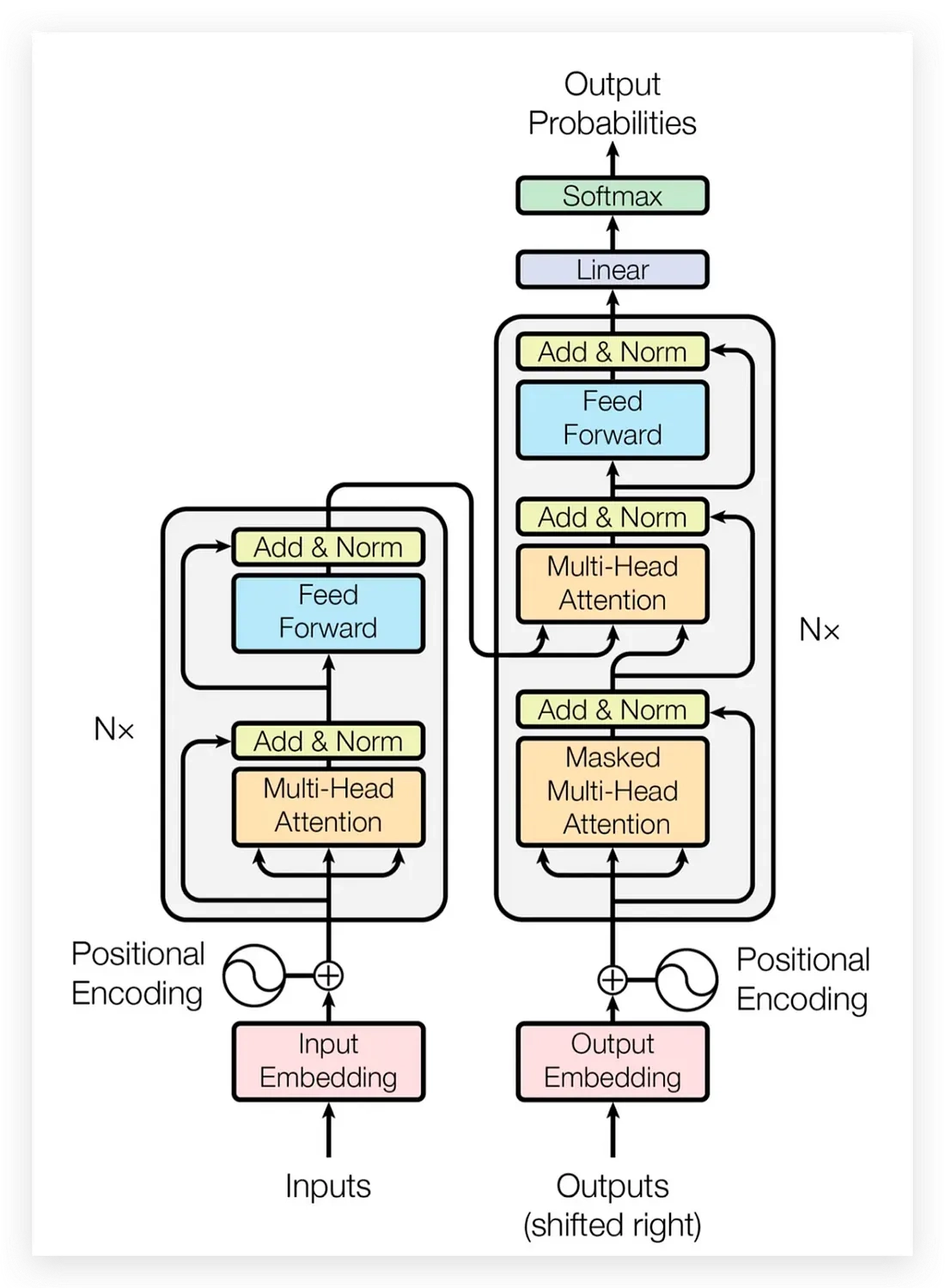
- multi head attention
chat gpt → 디코더 온리 모델
- 인코더의 구조는 N개로 설정
인코더의 구조
- 셀프 어텐션(Self-Attention)
- 멀티 헤드 어텐션(Multi-Head Attention)
- 위치 인코딩(Positional Encoding)
- 피드포워드 네트워크(Feed-Forward Network)
- Add & Norm 요소
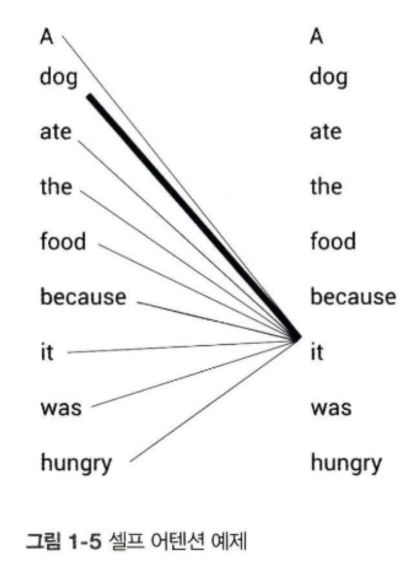

셀프 어텐션
- Key
- Query
- Value

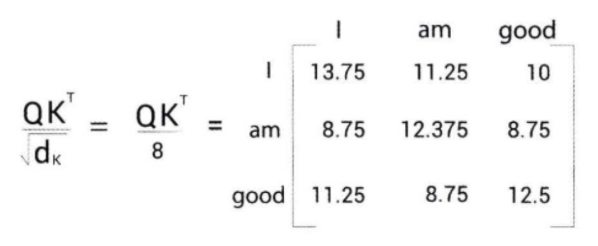
- 소프트맥스 함수를 활용하므로 가로 기준으로 더하면 1이 나온다.



- 정규화?
- 배치 정규화
- 레이어 정규화
- 켄쇼 하나은행.
from urllib import request
request.urlretrieve("https://raw.githubusercontent.com/songys/Chatbot_data/master/ChatbotData.csv", filename="ChatBotData.csv")
import pandas as pd
df = pd.read_csv("/kaggle/working/ChatBotData.csv")
import re
def preprocess_sentence(sentence):
sentence = re.sub(r"([?.!,])", r" \1 ", sentence)
sentence = sentence.strip()
return sentence
preprocess_sentence("안녕!! 오늘은 즐거운 목요일...???")questions = df['Q'].apply(preprocess_sentence).tolist()
answers = df['A'].apply(preprocess_sentence).tolist()import tensorflow_datasets as tfds
import tensorflow_datasets as tfds
tokenizer = tfds.deprecated.text.SubwordTextEncoder.build_from_corpus(
questions + answers, target_vocab_size=2**13)
전체 크기 대비 차이 계산하여 0 값을 더해서 패딩해버림
START_TOKEN = [tokenizer.vocab_size]
END_TOKEN = [tokenizer.vocab_size + 1]
VOCAB_SIZE = tokenizer.vocab_size + 2
MAX_LENGTH = 40
tmp = START_TOKEN+ tokenizer.encode(questions[2]) + END_TOKEN
if len(tmp) < MAX_LENGTH:
tmp2 = (MAX_LENGTH - len(tmp)) * [0]
tmp + tmp2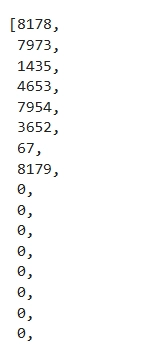
def pad_seq(seq, maxlen=MAX_LENGTH):
if len(seq) < maxlen:
return seq + [0] * (maxlen - len(seq))
return seq[:maxlen]
def tokenize_and_filter(inputs, outputs):
tokenized_inputs, tokenized_outputs = [], []
for (sentence1, sentence2) in zip(inputs, outputs):
sentence1 = START_TOKEN + tokenizer.encode(sentence1) + END_TOKEN
sentence2 = START_TOKEN + tokenizer.encode(sentence2) + END_TOKEN
tokenized_inputs.append(sentence1)
tokenized_outputs.append(sentence2)
tokenized_inputs = [pad_seq(seq) for seq in tokenized_inputs]
tokenized_outputs = [pad_seq(seq) for seq in tokenized_outputs]
return np.array(tokenized_inputs), np.array(tokenized_outputs)
questions, answers = tokenize_and_filter(questions, answers)
from torch.utils.data import Dataset, DataLoader
import torch
class ChatbotDataset(Dataset):
def __init__(self, question, answer):
self.question = question
self.answer = answer
def __len__(self):
return len(self.question)
def __getitem__(self, idx):
return (torch.tensor(self.question[idx], dtype=torch.long),
torch.tensor(self.answer[idx][:-1], dtype=torch.long),
torch.tensor(self.answer[idx][1:], dtype=torch.long))
data = ChatbotDataset(questions, answers)
a, b, c = next(iter(data))
BATCH_SIZE = 64
data = ChatbotDataset(questions, answers)
dataloader = DataLoader(data, batch_size=BATCH_SIZE, shuffle=True)
test = next(iter(dataloader))
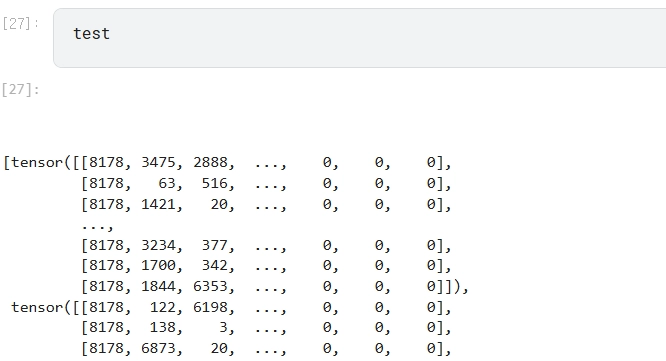
import torch.nn as nn
import torch
import math
import torch.nn.functional as F
def scaled_dot_product_attention(query, key, value, mask=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask, -1e9)
p_attn = F.softmax(scores, dim=-1)
return torch.matmul(p_attn, value), p_attn
seq_len = 3
d_k = 4
query = torch.rand(1, seq_len, d_k)
key = torch.rand(1, seq_len, d_k)
value = torch.rand(1, seq_len, d_k)
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=9000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1), :]
def create_padding_mask(x):
# (batch_size, 1, 1, seq_len)
return (x == 0).unsqueeze(1).unsqueeze(2)
def create_look_ahead_mask(x):
# (seq_len, seq_len)
seq_len = x.size(1)
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
if x.is_cuda:
mask = mask.cuda()
return mask
def scaled_dot_product_attention(query, key, value, mask=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask, -1e9)
p_attn = F.softmax(scores, dim=-1)
return torch.matmul(p_attn, value), p_attn
멀티 헤드 어텐션 설계
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.query_dense = nn.Linear(d_model, d_model)
self.key_dense = nn.Linear(d_model, d_model)
self.value_dense = nn.Linear(d_model, d_model)
self.dense = nn.Linear(d_model, d_model)
def split_heads(self, x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.depth)
return x.transpose(1, 2)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
scaled_attention, _ = scaled_dot_product_attention(query, key, value, mask)
scaled_attention = scaled_attention.transpose(1, 2).contiguous()
concat_attention = scaled_attention.view(batch_size, -1, self.d_model)
return self.dense(concat_attention)
class EncoderLayer(nn.Module):
def __init__(self, dff, d_model, num_heads, dropout):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
self.layernorm1 = nn.LayerNorm(d_model, eps=1e-6)
self.layernorm2 = nn.LayerNorm(d_model, eps=1e-6)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x , mask):
attn_output = self.mha(x, x, x, mask)
attn_output = self.dropout1(attn_output)
out1 = self.layernorm1(x + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output)
out2 = self.layernorm2(out1 + ffn_output)
return out2
class DecoderLayer(nn.Module):
def __init__(self, dff, d_model, num_heads, dropout):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
self.layernorm1 = nn.LayerNorm(d_model, eps=1e-6)
self.layernorm2 = nn.LayerNorm(d_model, eps=1e-6)
self.layernorm3 = nn.LayerNorm(d_model, eps=1e-6)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, enc_output, look_ahead_mask, padding_mask):
attn1 = self.mha1(x, x, x, look_ahead_mask)
attn1 = self.dropout1(attn1)
out1 = self.layernorm1(x + attn1)
attn2 = self.mha2(out1, enc_output, enc_output, padding_mask)
attn2 = self.dropout2(attn2)
out2 = self.layernorm2(out1 + attn2)
ffn_output = self.ffn(out2)
ffn_output = self.dropout3(ffn_output)
out3 = self.layernorm3(out2 + ffn_output)
return out3
class Transformer(nn.Module):
def __init__(self, vocab_size, num_layers, dff, d_model, num_heads, dropout):
super(Transformer, self).__init__()
self.d_model = d_model
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model)
self.enc_layers = nn.ModuleList([EncoderLayer(dff, d_model, num_heads, dropout) for _ in range(num_layers)])
self.dec_layers = nn.ModuleList([DecoderLayer(dff, d_model, num_heads, dropout) for _ in range(num_layers)])
self.dropout = nn.Dropout(dropout)
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, inputs, dec_inputs):
# 1. 마스크 생성
enc_padding_mask = create_padding_mask(inputs)
dec_padding_mask = create_padding_mask(inputs)
look_ahead_mask = torch.max(
create_look_ahead_mask(dec_inputs),
create_padding_mask(dec_inputs)
)
# 2. 인코더
enc_out = self.embedding(inputs) * math.sqrt(self.d_model)
enc_out = self.dropout(self.pos_encoding(enc_out))
for layer in self.enc_layers:
enc_out = layer(enc_out, enc_padding_mask)
# 3. 디코더
dec_out = self.embedding(dec_inputs) * math.sqrt(self.d_model)
dec_out = self.dropout(self.pos_encoding(dec_out))
for layer in self.dec_layers:
dec_out = layer(dec_out, enc_out, look_ahead_mask, dec_padding_mask)
return self.fc_out(dec_out)
NUM_LAYERS = 2
D_MODEL = 256
NUM_HEADS = 8
DFF = 512
DROPOUT = 0.1
EPOCHS = 50
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class CustomSchedule:
def __init__(self, d_model, warmup_steps=4000):
self.d_model = d_model
self.warmup_steps = warmup_steps
def __call__(self, step):
step = step + 1 # 0으로 나누는 것을 방지
arg1 = step ** -0.5
arg2 = step * (self.warmup_steps ** -1.5)
return (self.d_model ** -0.5) * min(arg1, arg2)
import math
model = Transformer(VOCAB_SIZE, NUM_LAYERS, DFF, D_MODEL, NUM_HEADS, DROPOUT).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = torch.optim.Adam(model.parameters(), lr=1.0, betas=(0.9, 0.98), eps=1e-9)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=CustomSchedule(D_MODEL))
import torch.nn.functional as F
for epoch in range(EPOCHS):
model.train()
total_loss = 0
for batch_idx, (inputs, dec_inputs, outputs) in enumerate(dataloader):
inputs, dec_inputs, outputs = inputs.to(device), dec_inputs.to(device), outputs.to(device)
optimizer.zero_grad()
predictions = model(inputs, dec_inputs)
# predictions shape: (batch_size, seq_len, vocab_size)
# outputs shape: (batch_size, seq_len)
loss = criterion(predictions.view(-1, VOCAB_SIZE), outputs.view(-1))
loss.backward()
optimizer.step()
scheduler.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}/{EPOCHS} Loss: {total_loss/len(dataloader):.4f}")
def evaluate(sentence):
sentence = preprocess_sentence(sentence)
# 수정 포인트: START_TOKEN과 END_TOKEN을 감싸고 있던 대괄호 [] 제거
sentence_tensor = torch.tensor(START_TOKEN + tokenizer.encode(sentence) + END_TOKEN).unsqueeze(0).to(device)
output_tensor = torch.tensor(START_TOKEN).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
for i in range(MAX_LENGTH):
predictions = model(sentence_tensor, output_tensor)
# 현재(마지막) 시점의 예측 단어를 가져옵니다.
predictions = predictions[:, -1:, :]
predicted_id = torch.argmax(predictions, dim=-1)
if predicted_id.item() == END_TOKEN[0]:
break
output_tensor = torch.cat([output_tensor, predicted_id], dim=-1)
return output_tensor.squeeze(0).cpu().numpy()
def predict(sentence):
prediction = evaluate(sentence)
predicted_sentence = tokenizer.decode(
[i for i in prediction if i < tokenizer.vocab_size])
print('Input: {}'.format(sentence))
print('Output: {}'.format(predicted_sentence))
return predicted_sentence
predict("누구냐 넌?")
'저는 마음을 이어주는 위로봇입니다 .’
필요한 가중치와 토크나이저 저장하기
torch.save(model.state_dict(), "./mymodel.pth")
tokenizer.save_to_file("./tokenizer")
로컬로 옮겨보기.
**model.py 만들기**
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
import torch
torch.set_num_threads(1)
import torch.nn as nn
import torch.nn.functional as F
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=9000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:, :x.size(1), :]
def create_padding_mask(x):
return (x == 0).unsqueeze(1).unsqueeze(2)
def create_look_ahead_mask(x):
seq_len = x.size(1)
mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
if x.is_cuda:
mask = mask.cuda()
return mask
def scaled_dot_product_attention(query, key, value, mask=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask, -1e9)
p_attn = F.softmax(scores, dim=-1)
return torch.matmul(p_attn, value), p_attn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.query_dense = nn.Linear(d_model, d_model)
self.key_dense = nn.Linear(d_model, d_model)
self.value_dense = nn.Linear(d_model, d_model)
self.dense = nn.Linear(d_model, d_model)
def split_heads(self, x, batch_size):
x = x.view(batch_size, -1, self.num_heads, self.depth)
return x.transpose(1, 2)
def forward(self, query, key, value, mask=None):
batch_size = query.size(0)
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
scaled_attention, _ = scaled_dot_product_attention(query, key, value, mask)
scaled_attention = scaled_attention.transpose(1, 2).contiguous()
concat_attention = scaled_attention.view(batch_size, -1, self.d_model)
return self.dense(concat_attention)
class EncoderLayer(nn.Module):
def __init__(self, dff, d_model, num_heads, dropout):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
self.layernorm1 = nn.LayerNorm(d_model, eps=1e-6)
self.layernorm2 = nn.LayerNorm(d_model, eps=1e-6)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.mha(x, x, x, mask)
attn_output = self.dropout1(attn_output)
out1 = self.layernorm1(x + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output)
return self.layernorm2(out1 + ffn_output)
class DecoderLayer(nn.Module):
def __init__(self, dff, d_model, num_heads, dropout):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = nn.Sequential(
nn.Linear(d_model, dff),
nn.ReLU(),
nn.Linear(dff, d_model)
)
self.layernorm1 = nn.LayerNorm(d_model, eps=1e-6)
self.layernorm2 = nn.LayerNorm(d_model, eps=1e-6)
self.layernorm3 = nn.LayerNorm(d_model, eps=1e-6)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
def forward(self, x, enc_output, look_ahead_mask, padding_mask):
attn1 = self.mha1(x, x, x, look_ahead_mask)
attn1 = self.dropout1(attn1)
out1 = self.layernorm1(x + attn1)
attn2 = self.mha2(out1, enc_output, enc_output, padding_mask)
attn2 = self.dropout2(attn2)
out2 = self.layernorm2(out1 + attn2)
ffn_output = self.ffn(out2)
ffn_output = self.dropout3(ffn_output)
return self.layernorm3(out2 + ffn_output)
class Transformer(nn.Module):
def __init__(self, vocab_size, num_layers, dff, d_model, num_heads, dropout):
super(Transformer, self).__init__()
self.d_model = d_model
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model)
self.enc_layers = nn.ModuleList([EncoderLayer(dff, d_model, num_heads, dropout) for _ in range(num_layers)])
self.dec_layers = nn.ModuleList([DecoderLayer(dff, d_model, num_heads, dropout) for _ in range(num_layers)])
self.dropout = nn.Dropout(dropout)
self.fc_out = nn.Linear(d_model, vocab_size)
def forward(self, inputs, dec_inputs):
enc_padding_mask = create_padding_mask(inputs)
dec_padding_mask = create_padding_mask(inputs)
look_ahead_mask = torch.max(
create_look_ahead_mask(dec_inputs),
create_padding_mask(dec_inputs)
)
enc_out = self.embedding(inputs) * math.sqrt(self.d_model)
enc_out = self.dropout(self.pos_encoding(enc_out))
for layer in self.enc_layers:
enc_out = layer(enc_out, enc_padding_mask)
dec_out = self.embedding(dec_inputs) * math.sqrt(self.d_model)
dec_out = self.dropout(self.pos_encoding(dec_out))
for layer in self.dec_layers:
dec_out = layer(dec_out, enc_out, look_ahead_mask, dec_padding_mask)
return self.fc_out(dec_out)
주피터에서 돌려보기
from model import Transformer
import tensorflow_datasets as tfds
tokenizer = tfds.deprecated.text.SubwordTextEncoder.load_from_file("./tokenizer")
VOCAB_SIZE = tokenizer.vocab_size + 2
NUM_LAYERS = 2
D_MODEL = 256
NUM_HEADS = 8
DFF = 512
DROPOUT = 0.1
model = Transformer(
vocab_size=VOCAB_SIZE,
num_layers=NUM_LAYERS,
dff=DFF,
d_model=D_MODEL,
num_heads=NUM_HEADS,
dropout=DROPOUT
).to('cpu')
#mac은 mps
import torch
model_dict = torch.load("./mymodel.pth", map_location='cpu')
model.load_state_dict(model_dict)
import re
def preprocess_sentence(sentence):
sentence = re.sub(r"([?.!,])", r" \1 ", sentence)
sentence = sentence.strip()
return sentence
START_TOKEN = [tokenizer.vocab_size]
END_TOKEN = [tokenizer.vocab_size + 1]
VOCAB_SIZE = tokenizer.vocab_size + 2
device = 'cpu'
MAX_LENGTH=40
def evaluate(sentence):
sentence = preprocess_sentence(sentence)
# 수정 포인트: START_TOKEN과 END_TOKEN을 감싸고 있던 대괄호 [] 제거
sentence_tensor = torch.tensor(START_TOKEN + tokenizer.encode(sentence) + END_TOKEN).unsqueeze(0).to(device)
output_tensor = torch.tensor(START_TOKEN).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
for i in range(MAX_LENGTH):
predictions = model(sentence_tensor, output_tensor)
# 현재(마지막) 시점의 예측 단어를 가져옵니다.
predictions = predictions[:, -1:, :]
predicted_id = torch.argmax(predictions, dim=-1)
if predicted_id.item() == END_TOKEN[0]:
break
output_tensor = torch.cat([output_tensor, predicted_id], dim=-1)
return output_tensor.squeeze(0).cpu().numpy()
def predict(sentence):
prediction = evaluate(sentence)
predicted_sentence = tokenizer.decode(
[i for i in prediction if i < tokenizer.vocab_size])
print('Input: {}'.format(sentence))
print('Output: {}'.format(predicted_sentence))
return predicted_sentence
predict("누구냐 넌?")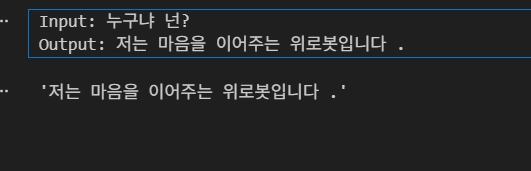
Day4
쿠버네티스?
서버 ← restapi, chatting, stock
가상화 기술 - hypervisor
- vmware, citirx,
- 리눅스 공부할 때 vmware 사용 추천.
- 하나의 서버에서 작업을 요청하면 vmware가 cpu랑 조절.
- 오버헤드가 없다.(이게 무슨 말이지)
- 속도가 느린 경향이 있음
서버(컨테이너(가상 머신))
- cpu랑 다이렉트로 소통함
- 도커
- Devops
- MLops
- LLMops
- AIops
- CI/CD
- k8s를 깊게는 안하지만, 알아야 ops 개념
- Airflow
컨테이너를 관리하는 방법이 있을까? 오케스트레이션
- 컨테이너 오케스트레이션
- 여러 개의 서버를 관리한다 - k8s.
- 서버에 사람이 너무 몰리면 알아서 분산해줌.
- k8s의 역할.
MSA(마이크로 서비스 아키텍쳐)
- 하나의 서비스를 뭉탱이가 아니라 마이크로 서비스로 쪼갠다
- 장애에 강하다
은행은 ibm 프레임워크
- kbank에서 처음으로 redhat 도입
minikube를 킨다.
minikube startk9s
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
echo >> /home/ming9/.bashrc
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv bash)"' >> /home/ming9/.bashrc
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv bash)"source ~/.bashrc
brew install derailed/k9s/k9s
k9s
0 치면
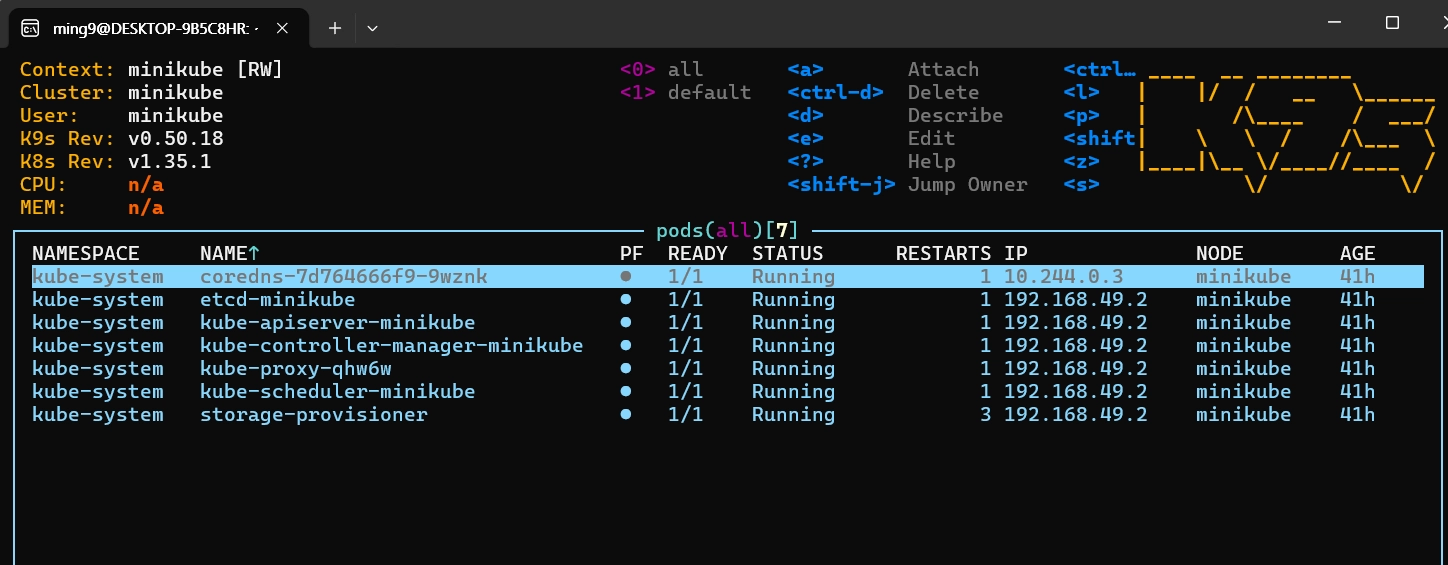
- 쿠버네티스가 구동하기 위한 필수 프로그램 볼 수 있음
- kube, 서버를 노드라고 함
- load balancer .
- 네트워크 지식이 필요하다.
- pods 안에 컨테이너가 들어갈 수 있다,

- pods 안에 있는 리스트들은 죽여도 살아나도록 설계되어있다.
- airflow를 통해 주기적으로 돌아가게 해볼 수 있다.
minikube kubectl get nodes
- 노드가 하나만 있다.
vim ~/.bashrc 
source ~/.bashrc- 환경파일 기반 업데이트

- 환경설정 vim에서 작업하는 것이 딥러닝 리눅스에서 돌릴 때 중요
pods 띄우기
kubectl -- run hello-world --image=hello-world --restart=Always

리스트 확인
kubectl get all
pods 지우기
kubectl delete pod hello-worldk9s에서는 명령어

로 지우기 가능
mkdir k8s && cd k8s
- yml → 설정 파일
- 띄어쓰기에 민감
vim nginx.yml
apiVersion: v1
kind: Pod
metadata:
name: nginx01
spec:
containers:
- name: nginx-skn25
image: nginx:latest
#minikube에선 -- apply
kubectl -- apply -f nginx.yml
디폴로이먼트
- 레플리카셋을 관리.
레플리카셋
- pod 여러 개 관리
- pod 안에서 container 관리
쿠버네티스 - 구글에서 만듦.
kubectl create deployment deploy-nginx --image=nginx --replicas=3
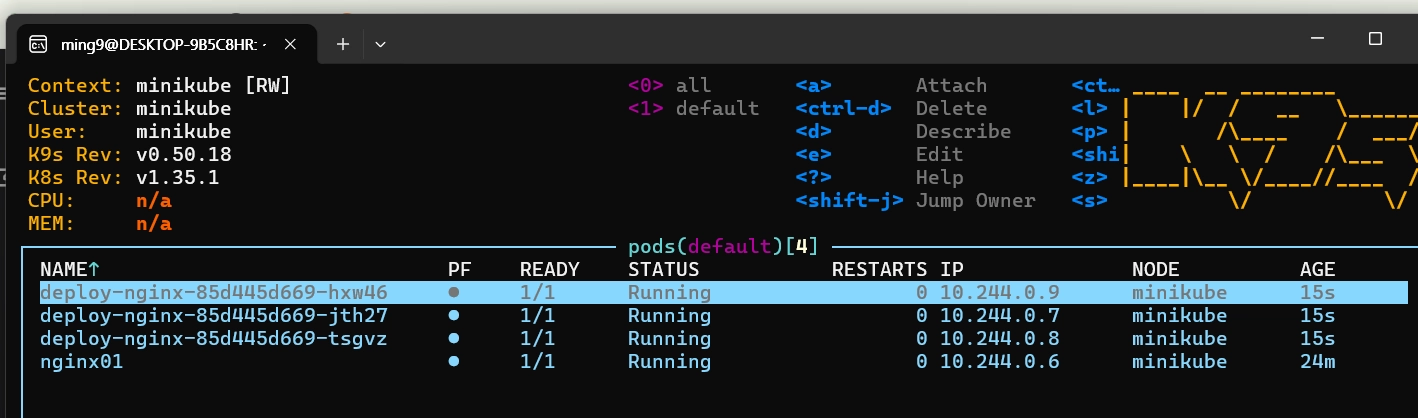
- deployment를 만들어보았다.
kubectl get deploy,rs,pod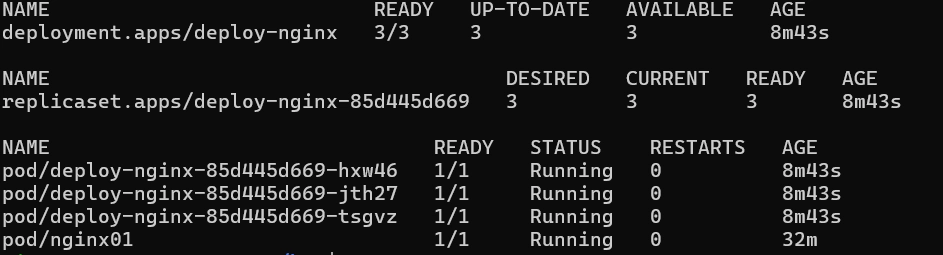
하위 개념은 죽여도 살아남
완전히 제거하려면 상위 개념을 죽여야 함
kubectl delete deployment deploy-nginx
제대로 서버 띄우기
vim myserver.yml
# nginx-minikube.yaml
# API 버전: apps/v1은 Deployment를 위한 안정적인 API
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-web
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.25.3
ports:
- containerPort: 80
resources:
requests:
memory: "64Mi"
cpu: "100m"
limits:
memory: "128Mi"
cpu: "200m"
---
# Service 정의: 외부 접속을 위한 진입점
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
nodePort: 30080
selector:
app: nginx
kubectl apply -f myserver.yml
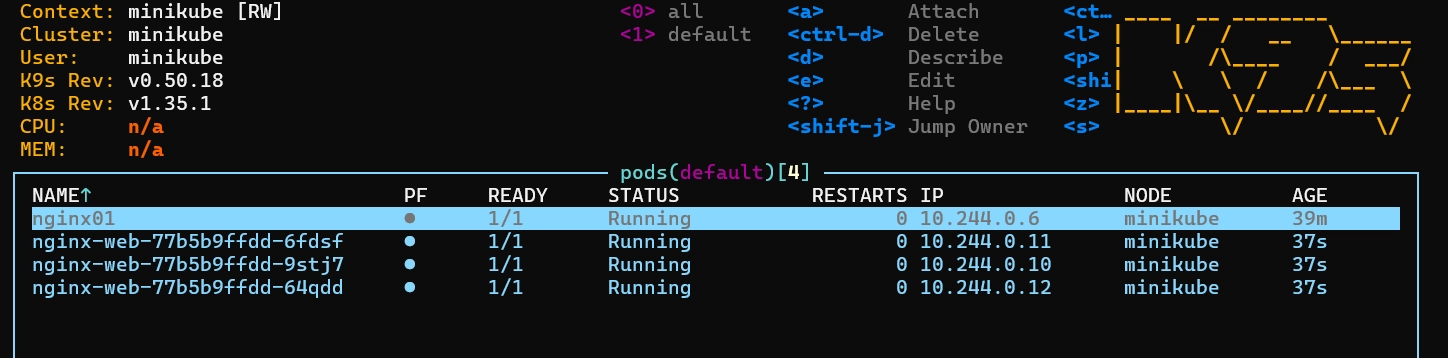
서버 켜기
minikube service nginx-service --url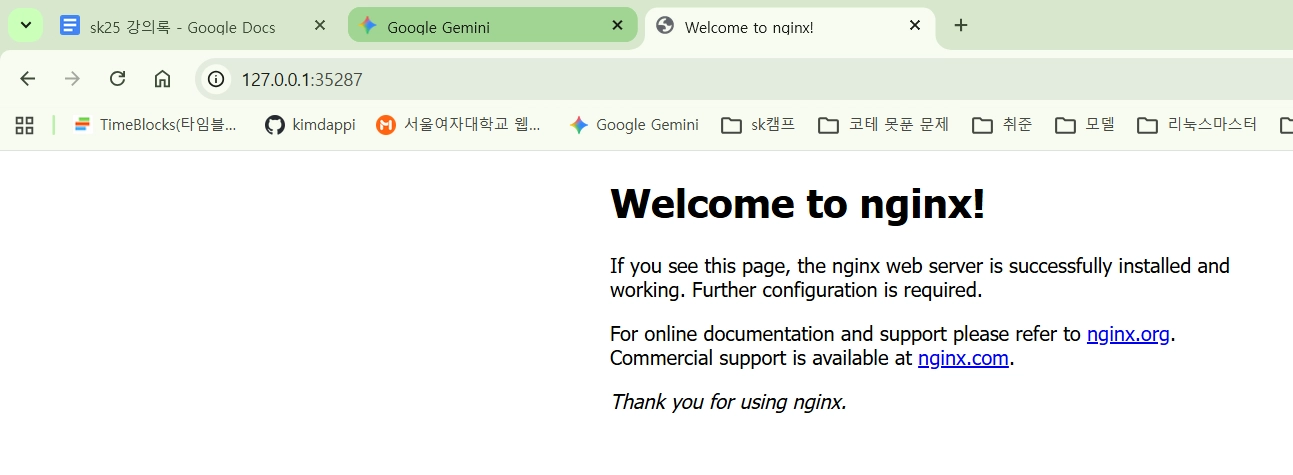

kubectl get deploy,rs,po -o wide
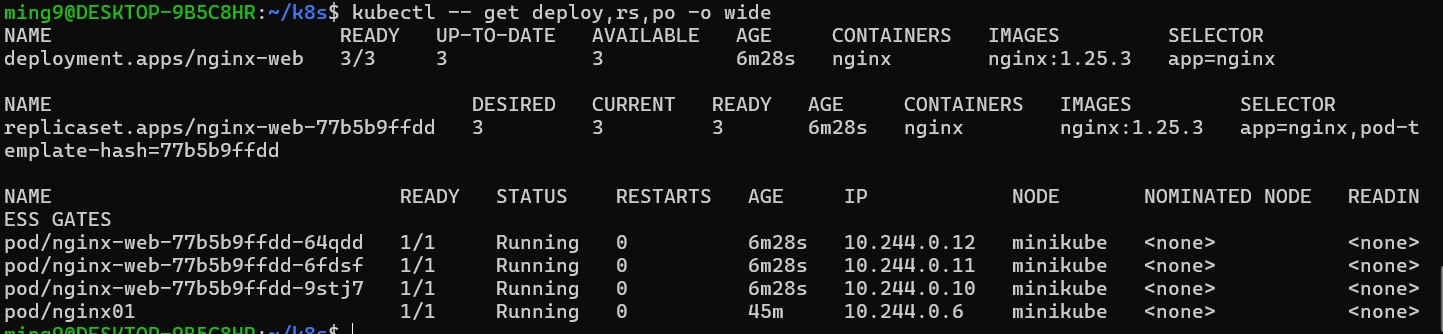
kubectl port-forward service/nginx-service 8000:80
- 포트포워딩됨
minikube stop 