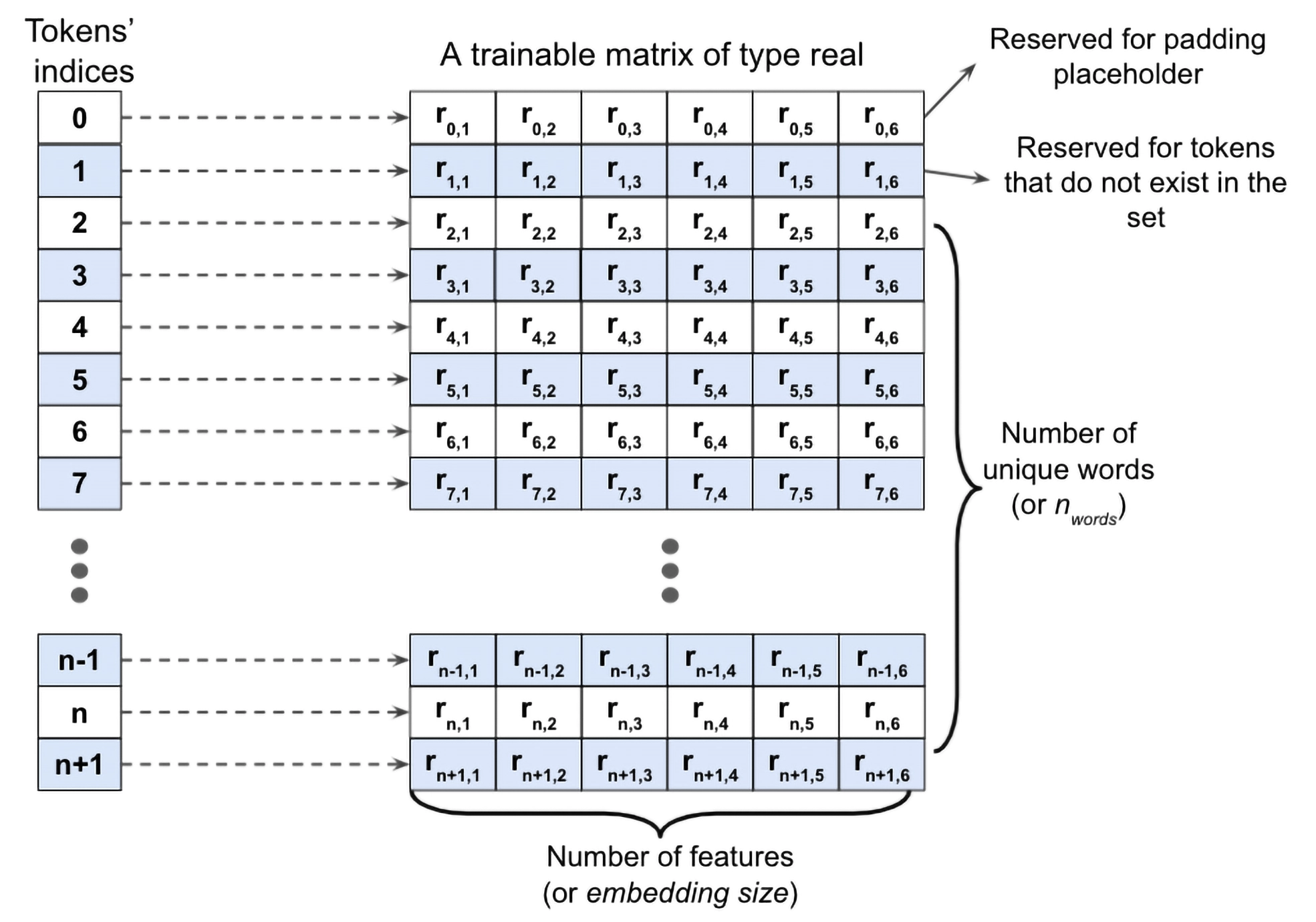
Day1
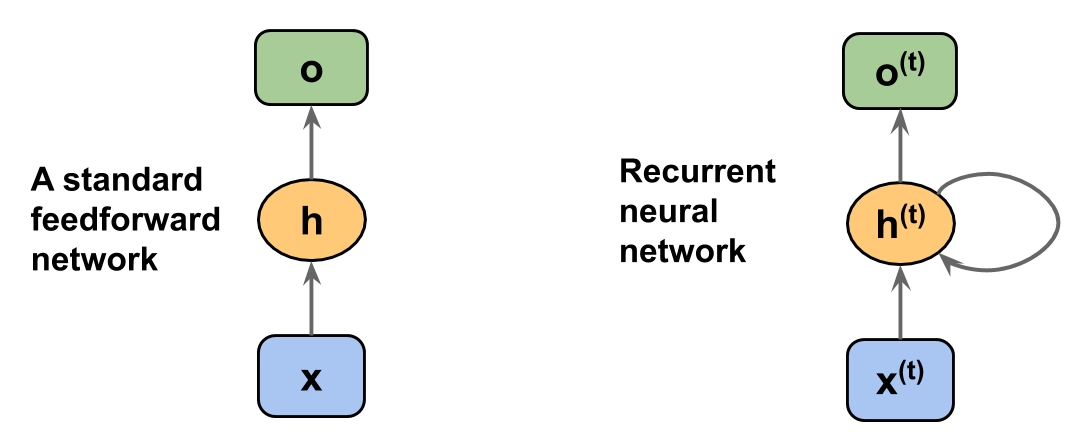
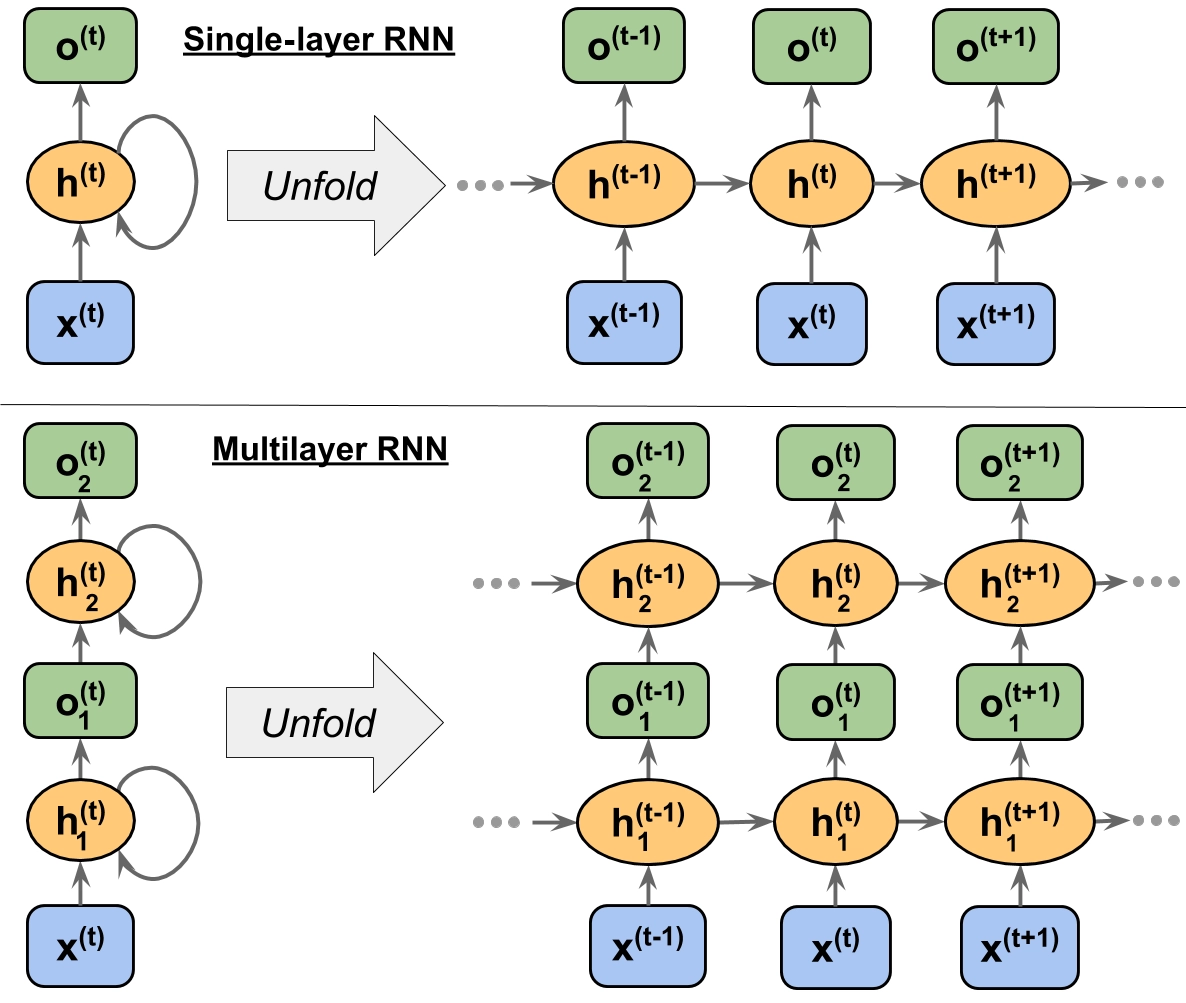
🟢RNN을 시작한다
활성화 함수는 tanh를 사용한다.
🔵은닉 상태
- 긴 소설을 읽으며 메모장에 요약을 적어내려갈 때, 내용이 계속 누적되는 것을 의미한다
- 길이가 계속 길어질 수록, 과거의 데이터는 소실된다.
import torch
import torch.nn as nn
torch.manual_seed(1)
rnn_layer = nn.RNN(input_size=5, hidden_size=2, num_layers=1, batch_first=True)
w_hh = rnn_layer.weight_hh_l0
w_xh = rnn_layer.weight_ih_l0
b_hh = rnn_layer.bias_hh_l0
b_xh = rnn_layer.bias_ih_l0
print('W_xh 크기:', w_xh.shape)
print('W_hh 크기:', w_hh.shape)
print('b_xh 크기:', b_xh.shape)
print('b_hh 크기:', b_hh.shape)x_seq = torch.tensor([[1.0]*5, [2.0]*5, [3.0]*5]).float()
output, hn = rnn_layer(torch.reshape(x_seq, (1, 3, 5)))
print(output)
print(hn)tensor([[[-0.3520, 0.5253],
[-0.6842, 0.7607],
[-0.8649, 0.9047]]], grad_fn=)
tensor([[[-0.8649, 0.9047]]], grad_fn=)
out_man = []
for t in range(3):
xt = torch.reshape(x_seq[t], (1,5))
print(f"타입 스텝 {t} -> 입력 {xt.numpy()}")
ht = torch.matmul(xt, torch.transpose(w_xh, 0, 1)) + b_xh
print(f' 은닉 -> {ht.detach().numpy()}')
if t>0:
prev_h = out_man[t-1]
else:
prev_h = torch.zeros((ht.shape))
ot = ht + torch.matmul(prev_h, torch.transpose(w_hh, 0, 1)) + b_hh
ot = torch.tanh(ot)
out_man.append(ot)
print( f" 출력(수동) --> {ot.detach().numpy()} ")
print( f" RNN 출력 --> {output[:, t].detach().numpy()} ")
time step 0 => [[1. 1. 1. 1. 1.]]
hidden => {ht}
출력 수동 => [[-0.3519801 0.52525216]]
rnn 출력 => [[-0.3519801 0.52525216]]
time step 1 => [[2. 2. 2. 2. 2.]]
hidden => {ht}
출력 수동 => [[-0.68424344 0.76074266]]
rnn 출력 => [[-0.68424344 0.76074266]]
time step 2 => [[3. 3. 3. 3. 3.]]
hidden => {ht}
출력 수동 => [[-0.8649416 0.90466356]]
rnn 출력 => [[-0.8649416 0.90466356]]
→ 수동과 자동 값이 같으므로, 자동 함수 안에는 이미 tanh가 내장되어있다고 판단할 수 있음
집중해야할 점 : 기울시 소실 문제가 있다. 과거 은닉층을 활용하므로 첫번째 인덱스를 위한 스텝을 만들어준다.
- rnn → 과거값이 무조건 필요하기 때문에, 병렬성이 떨어진다는 문제가 있다.
imdb 데이터& RNN & 감정분석(이진분류)
from datasets import load_dataset
dataset = load_dataset("imdb")
train_dataset = dataset['train']
test_dataset = dataset['test']
import torch
from torch.utils.data.dataset import random_split
torch.manual_seed(1)
train_dataset, valid_dataset = random_split(
list(train_dataset), [20000, 5000])
import re
from collections import Counter, OrderedDict
token_counts = Counter()정규표현식 기반 이모티콘 제거
def tokenizer(text):
text = re.sub('<[^>]*>', '', text)
emoticons = re.findall('(?::|;|=)(?:-)?(?:\)|\(|D|P)', text.lower())
text = re.sub('[\W]+', ' ', text.lower()) +\
' '.join(emoticons).replace('-', '')
tokenized = text.split()
return tokenized
for data in train_dataset:
tokens = tokenizer(data['text'])
token_counts.update(tokens)수 확인
len(token_counts) #69023빈도수 확인
sorted_by_freq_tuples =sorted(token_counts.items(),key= lambda x:x[1],reverse=True)
sorted_by_freq_tuples('the', 267877), ('and', 130797), ('a', 130057)
딕셔너리로 변환
from collections import Counter, OrderedDict
ordered_dict= OrderedDict(sorted_by_freq_tuples)시각화
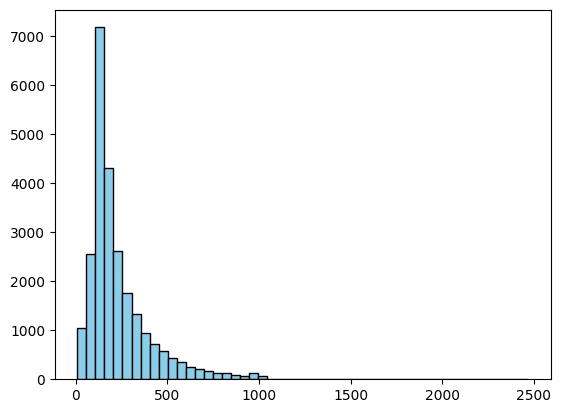
import pandas as pd
import matplotlib.pyplot as plt
dataset = load_dataset("imdb", split="train")
df = pd.DataFrame(dataset)
df['word_count'] = df['text'].apply(lambda x: len(x.split()))
plt.hist(df['word_count'], bins=50, color='skyblue', edgecolor='black')
plt.show()
vocab = {"<pad>" : 0 , "<unk>" : 1}
for key, val in enumerate(ordered_dict.keys()):
vocab[val] = key+2
print([vocab[token] for token in ['this','is','an','example']])
# [11, 7, 35, 457]import torch.nn as nn
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
text_pipeline = lambda x: [vocab.get(token, 1) for token in tokenizer(x)]
label_pipeline = lambda x: float(x)def collate_batch(batch):
label_list, text_list, lengths = [], [], []
for _sample in batch:
_label = _sample['label']
_text = _sample['text']
label_list.append(label_pipeline(_label))
processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)
lengths.append(processed_text.size(0))
label_list = torch.tensor(label_list, dtype=torch.float32)
lengths = torch.tensor(lengths, dtype=torch.int64)
padded_text_list = nn.utils.rnn.pad_sequence(
text_list, batch_first=True, padding_value=0
)
return padded_text_list.to(device), label_list.to(device), lengths.to(device)
from torch.utils.data import DataLoader
batch_size = 32
train_dl = DataLoader(train_dataset, batch_size=batch_size,
shuffle=True, collate_fn=collate_batch)
valid_dl = DataLoader(valid_dataset, batch_size=batch_size,
shuffle=False, collate_fn=collate_batch)
test_dl = DataLoader(test_dataset, batch_size=batch_size,
shuffle=False, collate_fn=collate_batch)
text_batch, label_batch, length_batch = next(iter(train_dl))
- next(iter(train_dl))의 값
(tensor([[3288, 304, 1659, ..., 0, 0, 0],
[ 125, 48, 2, ..., 0, 0, 0],
[ 430, 2, 5806, ..., 0, 0, 0],
...,
[ 49, 7711, 237, ..., 0, 0, 0],
[ 15, 229, 15, ..., 0, 0, 0],
[ 35, 1535, 345, ..., 0, 0, 0]]),
tensor([0., 0., 0., 0., 1., 1., 1., 0., 0., 1., 0., 1., 0., 0., 0., 1., 0., 1.,
0., 1., 1., 0., 1., 1., 0., 0., 0., 1., 0., 0., 0., 1.]),
tensor([253, 330, 527, 111, 390, 188, 860, 271, 911, 190, 134, 111, 116, 102,
129, 43, 140, 246, 631, 98, 219, 403, 44, 166, 116, 130, 975, 400,
295, 65, 140, 178]))
embedding = nn.Embedding(num_embeddings=10,
embedding_dim=3,
padding_idx=0)
#그냥 샘플
text_encoded_input = torch.LongTensor([[1,2,4,5],[4,3,2,0]])
embedding(text_encoded_input) tensor([[[ 0.4307, 0.5097, -0.5304],
[ 0.5287, -0.7687, 0.5857],
[ 1.9878, 0.7470, 0.0336],
[ 0.8769, -0.7887, -1.8020]],
[[ 1.9878, 0.7470, 0.0336],
[-0.2052, 1.0510, -1.3474],
[ 0.5287, -0.7687, 0.5857],
[ 0.0000, 0.0000, 0.0000]]], grad_fn=<EmbeddingBackward0>)rnn 모델 샘플 코드 제작
class RNN(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.rnn = nn.RNN(input_size, hidden_size, num_layers=2, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self,x):
_, hidden = self.rnn(x)
out = hidden[-1, :, :]
out = self.fc(out)
return out
model = RNN(64,32)print(model)RNN(
(rnn): RNN(64, 32, num_layers=2, batch_first=True)
(fc): Linear(in_features=32, out_features=1, bias=True)
)
torch로 랜덤값 임의로 넣어보기
model(torch.randn(5,3,64))tensor([[0.0451],
[0.2233],
[0.0690],
[0.0843],
[0.3114]], grad_fn=)
본격적인 RNN 구조 설계
class RNN(nn.Module):
def __init__(self, vocab_size, embed_dim, rnn_hidden_size, fc_hidden_size):
super().__init__()
self.embedding = nn.Embedding(vocab_size,
embed_dim,
padding_idx=0)
self.rnn = nn.RNN(embed_dim, rnn_hidden_size,
batch_first=True)
self.fc1 = nn.Linear(rnn_hidden_size, fc_hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(fc_hidden_size, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, text, lengths):
out = self.embedding(text)
out = nn.utils.rnn.pack_padded_sequence(out, lengths.cpu().numpy(), enforce_sorted=False, batch_first=True)
out, hidden = self.rnn(out)
out = hidden[-1, :, :]
out = self.fc1(out)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
return out
파라미터 설정 및 모델 설정
vocab_size = len(vocab)
embed_dim = 20
rnn_hidden_size = 64
fc_hidden_size = 64
torch.manual_seed(1)
model = RNN(vocab_size, embed_dim, rnn_hidden_size, fc_hidden_size)
model = model.to(device)
학습 코드 및 평가 코드
def train(dataloader):
model.train()
total_acc, total_loss = 0, 0
for text_batch, label_batch, lengths in dataloader:
optimizer.zero_grad()
pred = model(text_batch, lengths)[:, 0]
loss = loss_fn(pred, label_batch)
loss.backward()
optimizer.step()
total_acc += ((pred>=0.5).float() == label_batch).float().sum().item()
total_loss += loss.item()*label_batch.size(0)
return total_acc/len(dataloader.dataset), total_loss/len(dataloader.dataset)
def evaluate(dataloader):
model.eval()
total_acc, total_loss = 0, 0
with torch.no_grad():
for text_batch, label_batch, lengths in dataloader:
pred = model(text_batch, lengths)[:, 0]
loss = loss_fn(pred, label_batch)
total_acc += ((pred>=0.5).float() == label_batch).float().sum().item()
total_loss += loss.item()*label_batch.size(0)
return total_acc/len(list(dataloader.dataset)), total_loss/len(list(dataloader.dataset))
손실 함수 기반 학습 시도
loss_fn = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
num_epochs = 10
torch.manual_seed(1)
for epoch in range(num_epochs):
print(f"epoch -> {epoch}")
acc_train, loss_train = train(train_dl)
acc_valid, loss_valid = evaluate(valid_dl)
print(f'에포크 {epoch} 정확도: {acc_train:.4f} 검증 정확도: {acc_valid:.4f}')
LSTM
- RNN의 장기의존성 문제를 해결한다.
컨베이어 벨트 위에 여러 개의 게이트를 설치한 것과 같다.
- 망각 게이트 : 필요없으면 버리기
- 시그모이드 함수로, 완전히 잊으면 0 , 완전히 기억하면 1의 값을 가짐
- 입력 게이트 : 가방에 넣기
- 새 정보의 중요도와 , 새로운 정보 후보군에 대해 연산
- 출력 게이트 : 당장 이 물건 필요
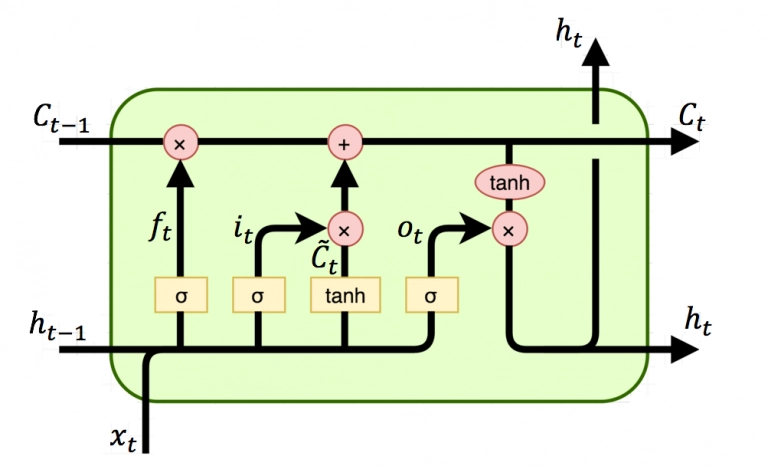
Cell state , Hidden state
cell update 사용 때 사용하는 곱 → 아마다르 곱.
GRU
LSTM을 간소화한 구조.. 성능은 lstm보다 별로지만 빠르다
면접장에서는 rnn과 lstm에 대해 물어보실 수 있음
attention활용하는 모델 - transformer
Transformer
- 인코더 디코더
- GPT는 디코더 온리 모델
- 인코더 온리 모델도 존재한다.
캐글 기반 감정분석 실습
pip install konlpy
from konlpy.tag import Okt
okt = Okt()
okt.morphs("아버지가방에들어가신다")
import urllib.request
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt", filename="ratings_train.txt")
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt", filename="ratings_test.txt")
import pandas as pd
df = pd.read_csv("/kaggle/working/ratings_train.txt", encoding='utf-8', sep='\t')
df['label'].value_counts()label
0 75173
1 74827
Name: count, dtype
df.head(3)id document label
0 9976970 아 더빙.. 진짜 짜증나네요 목소리 0
1 3819312 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 1
2 10265843 너무재밓었다그래서보는것을추천한다 0
df.drop_duplicates(subset=['document']).shape
df.drop_duplicates(subset=['document'],inplace = True)
- 중복 제거 후에 데이터 개수 확인
정규식에서의 대괄호 → 집합
import re
STOPWORDS = set(['의', '가', '이', '은', '들', '는', '좀', '잘', '걍', '과', '도', '를', '으로', '자', '에', '와', '한', '하다'])
re.findall("[^가-힣\\s]", "가나다 123")
re.sub("[^가-힣\\s]",'', "가나다 123 ㅋㅋㅋ")필요한 함수 선언
어간 추출
def preprocessing_text(text):
if not isinstance(text, str):
return []
text = re.sub("[^가-힣\\s]",'', text )
# 어간 추출
tokens = okt.morphs(text, stem=True)
tokens = [word for word in tokens if word not in STOPWORDS]
return tokens- gpt → BBPE 토큰화 활용.
로컬 llm
- lm studio
- ollama
- hugging face
from collections import Counter
counter = Counter()
for token in df.preprocessing:
counter.update(token)
max_vocab_size = len(counter)
vocab = {'<PAD>': 0, '<UNK>': 1}
for word, _ in counter.most_common(max_vocab_size - 2):
vocab[word] = len(vocab)단어 함수 형성
def build_vocab(tokenized_data, max_vocab_size):
counter = Counter()
for tokens in tokenized_data:
counter.update(tokens)
# <PAD>는 시퀀스 길이 맞춤용, <UNK>는 사전에 없는 단어용
vocab = {'<PAD>': 0, '<UNK>': 1}
# 빈도수 상위 단어들을 사전에 추가
for word, _ in counter.most_common(max_vocab_size - 2):
vocab[word] = len(vocab)
return vocab
인코딩 함수
def encode_text(tokens, vocab, max_seq_len):
encoded = [vocab.get(word, vocab['<UNK>']) for word in tokens]
# 패딩(Padding) 및 자르기(Truncation)
if len(encoded) < max_seq_len:
encoded += [vocab['<PAD>']] * (max_seq_len - len(encoded))
else:
encoded = encoded[:max_seq_len]
return encoded
데이터셋 클래스 선언
from torch.utils.data import Dataset, DataLoader
MAX_SEQ_LEN = 30 #하이퍼파라미터로서 조절이 필요
VOCAB_SIZE = 20000
class SentimentDataset(Dataset):
def __init__(self, filepath, vocab=None, is_train=True):
df = pd.read_csv(filepath, sep='\t')
df = df.dropna(subset=['document'])
df = df.drop_duplicates(subset=['document'])
df['tokens'] = df['document'].apply(preprocessing_text)
df = df[df['tokens'].map(len) > 0]
if is_train:
self.vocab = build_vocab(df['tokens'], VOCAB_SIZE)
else:
self.vocab = vocab
self.inputs = [encode_text(tokens, self.vocab, MAX_SEQ_LEN) for tokens in df['tokens']]
self.labels = df['label'].tolist()
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
x = torch.tensor(self.inputs[idx], dtype=torch.long)
y = torch.tensor(self.labels[idx], dtype=torch.float)
return x, y
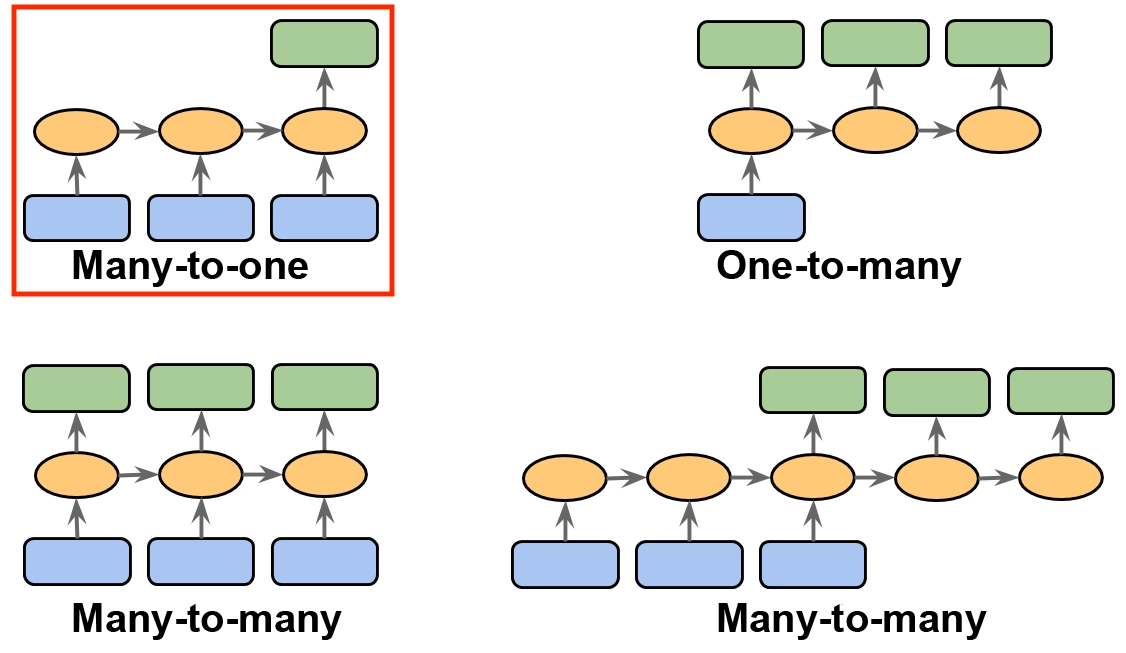
- 감정분석은 여기서 Many-to-one에 해당
모델 클래스 선언
import torch.nn as nn
class SentimentLSTM(nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim):
super(SentimentLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.lstm = nn.LSTM(embed_dim, hidden_dim, batch_first=True)
self.fc = nn.Linear(hidden_dim, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
embedded = self.embedding(x)
lstm_out, (hidden, cell) = self.lstm(embedded)
last_hidden = hidden[-1]
# lstm_out[:, -1, :]
output = self.fc(last_hidden) # (batch_size, 1)
return self.sigmoid(output).squeeze()
데이터셋 값 초기화
train_dataset = SentimentDataset("/kaggle/working/ratings_train.txt")
vocab = train_dataset.vocabtest_dataset = SentimentDataset("/kaggle/working/ratings_test.txt", vocab = vocab, is_train=False)하이퍼파라미터 설정& 모델 선언
BATCH_SIZE = 64
LR = 0.001
EPOCHS = 5
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
import torch
import torch.optim as optim
EMBED_DIM = 128
HIDDEN_DIM = 256
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SentimentLSTM(len(vocab), EMBED_DIM, HIDDEN_DIM).to(DEVICE)
criterion = nn.BCELoss() # 이진 교차 엔트로피 손실 함수
optimizer = optim.Adam(model.parameters(), lr=LR)
for epoch in range(EPOCHS):
model.train()
total_loss = 0
correct = 0
total = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
# 0.5 이상이면 긍정(1), 미만이면 부정(0)으로 예측
predicted = (outputs >= 0.5).float()
correct += (predicted == labels).sum().item()
total += labels.size(0)
train_acc = correct / total
avg_loss = total_loss / len(train_loader)
print(f"Epoch {epoch+1}/{EPOCHS} - Loss: {avg_loss:.4f}, Accuracy: {train_acc:.4f}")
Epoch 1/5 - Loss: 0.6656, Accuracy: 0.6127 Epoch 2/5 - Loss: 0.5080, Accuracy: 0.7447 Epoch 3/5 - Loss: 0.3437, Accuracy: 0.8490 Epoch 4/5 - Loss: 0.2875, Accuracy: 0.8775 Epoch 5/5 - Loss: 0.2341, Accuracy: 0.9048
학습시킨 모델에 대한 추론
def predict_sentiment(model, vocab, sentence):
model.eval()
tokens = preprocessing_text(sentence)
encoded_ids = encode_text(tokens, vocab, MAX_SEQ_LEN)
input_tensor = torch.tensor([encoded_ids], dtype=torch.long).to(DEVICE)
with torch.no_grad():
output = model(input_tensor)
probability = output.item()
label = "긍정" if probability >= 0.5 else "부정"
print(f"입력 문장: \"{sentence}\"")
print(f"예측 결과: {label} (확률: {probability*100:.2f}%)\n")
predict_sentiment(model, vocab, "밍구망구")
입력 문장: "밍구망구"
예측 결과: 부정 (확률: 37.44%)
Day2
오전엔 정형외과 다녀 옴. 오후도 화이팅이다 !
오전 수업 내용
https://wikibook.co.kr/textmining
p131
나이브 베이즈 기반 스팸메일 분류하기
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn.naive_bayes import MultinomialNB
emails = [
"무료 쿠폰 지급 클릭하세요",
"당첨되셨습니다 지금 수령하세요",
"무료 상품권 당첨 축하합니다",
"회의 일정 확인 부탁드립니다",
"프로젝트 제출 마감일 안내",
"내일 점심 약속 확인",
"무료 체험단 모집 중입니다",
"월간 보고서 검토 요청",
]
labels = [1,1,1,0,0,0,1,0]
X_train, X_test, y_train, y_test = train_test_split(
emails, labels, test_size=0.25, random_state=42
)
# 한국어에서 강력한 기본 베이스라인 (형태소 없이도 성능 좋음)
vectorizer = CountVectorizer(analyzer="char", ngram_range=(2,4))
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(X_test)
print("학습 데이터 shape:", X_train_vec.shape)
model = MultinomialNB(alpha=1.0) # 라플라스 스무딩
model.fit(X_train_vec, y_train)
preds = model.predict(X_test_vec)
print("정확도:", accuracy_score(y_test, preds))
print("혼동행렬:")
print(confusion_matrix(y_test, preds))
proba = model.predict_proba(X_test_vec)
for mail, p in zip(X_test, proba):
print(f"메일: {mail}")
print(f" 스팸 확률: {p[1]:.3f}")
메일 보내기(강사님 계정 → 내 계정)
gmail -> 이메일 받기 -> 스팸메일 필터 개발(나이즈 베이즈) -> 배포(fastapi, docker) -> gmail 에 메일 보내기
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.utils import formatdate
id_ = "seowoong362@gmail.com"
pass_ = 'yciu epuq dsry iuzs'
to_ = 'skdusrla1025@gmail.com'
smtp = smtplib.SMTP_SSL("smtp.gmail.com", 465)
smtp.login(id_, pass_)
- 회사에서 smtp 사용?
- 회사에서는 이메일 보내는 프로그램 사용 >outlook!
email_from = id_
email_to = to_
email_date = formatdate(localtime=True)
email_subject = "영화 달콤한 인생 - 명대사"
email_message = """
안녕하세요.
제가 좋아하는 영화의 좋아하는 대사를 적어봅니다.
어느 맑은 봄날, 바람에 이리저리 휘날리는 나뭇가지를 바라보며 제자가 물었다.
스승님, 저것은 나뭇가지가 움직이는 겁니까, 바람이 움직이는 겁니까?
스승은 제자가 가리키는 곳은 보지도 않은 채, 웃으며 말했다.
무릇, 움직이는 것은 나뭇가지도 아니고, 바람도 아니며, 네 마음뿐이다.
"""
msg = MIMEMultipart('alternative')
# 보내는 사람
msg['From'] = email_from
# 받는 사람
msg['To'] = email_to
# 날짜
msg['Date'] = email_date
# 제목
msg['Subject'] = email_subject
msg.attach(MIMEText(email_message))
smtp.sendmail(id_, email_to, msg.as_string())

메일 받기
import imaplib
mail = imaplib.IMAP4_SSL("imap.gmail.com", 993)
mail.login(id_, pass_)
mail.select("inbox")
status, messages = mail.search(None, "UNSEEN")
mail.fetch(messages[0].split()[0], "(RFC822)")
status , msg_data = mail.fetch(messages[0].split()[0], "(RFC822)")
import email
msg = email.message_from_bytes(msg_data[0][1])
msg.get("From")
if msg.is_multipart():
for part in msg.walk():
content_type = part.get_content_type()
content_disposition = str(part.get("Content-Disposition"))
if content_type == "text/plain" and "attachment" not in content_disposition:
body = part.get_payload(decode=True).decode("utf-8", errors="ignore")
print(f"내용:\n{body[:200]}...") # 앞 200자만 출력
break
else:
body = msg.get_payload(decode=True).decode("utf-8", errors="ignore")
print(f"내용:\n{body[:200]}...")내 메일로 확인하기
import imaplib
import email
from email.header import decode_header
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
id_ = "skdusrla1025@gmail.com"
pass_ = 'rgkjraiszcqidzvc'
mail = imaplib.IMAP4_SSL("imap.gmail.com", 993)
mail.login(id_, pass_)
mail.select("inbox")
status, messages = mail.search(None, "UNSEEN")
text=[]
for i in range(10):
status , msg_data = mail.fetch(messages[0].split()[i], "(RFC822)")
msg = email.message_from_bytes(msg_data[0][1])
raw_subject = decode_header(msg['Subject'])[0]
subject_content = raw_subject[0]
encoding = raw_subject[1]
if isinstance(subject_content, bytes):
# bytes 타입인 경우에만 인코딩 정보로 디코딩
if encoding:
subject = subject_content.decode(encoding)
else:
subject = subject_content.decode('utf-8', errors='ignore')
else:
# 이미 str 타입인 경우 그대로 사용
subject = subject_content
#print(subject)
msg.get("From")
if msg.is_multipart():
for part in msg.walk():
content_type = part.get_content_type()
content_disposition = str(part.get("Content-Disposition"))
if content_type == "text/plain" and "attachment" not in content_disposition:
body = part.get_payload(decode=True).decode("utf-8", errors="ignore")
#print(f"내용:\n{body[:200]}...") # 앞 200자만 출력
break
else:
body = msg.get_payload(decode=True).decode("utf-8", errors="ignore")
#print(f"내용:\n{body[:200]}...")
text.append(body[:500])
## 평가 데이터셋 준비
text_data= np.array(text)
## 모델 선언 및 학습##
emails = [
"무료 쿠폰 지급 클릭하세요",
"당첨되셨습니다 지금 수령하세요",
"무료 상품권 당첨 축하합니다",
"회의 일정 확인 부탁드립니다",
"프로젝트 제출 마감일 안내",
"내일 점심 약속 확인",
"무료 체험단 모집 중입니다",
"월간 보고서 검토 요청",
]
labels = [1,1,1,0,0,0,1,0]
X_train, X_test, y_train, y_test = train_test_split(
emails, labels, test_size=0.25, random_state=42
)
# 귀찮으니 test 사용은 때려친다.
# 한국어에서 강력한 기본 베이스라인
vectorizer = CountVectorizer(analyzer="char", ngram_range=(2,4))
X_train_vec = vectorizer.fit_transform(X_train)
X_test_vec = vectorizer.transform(text_data)
# 내가 만든 데이터로 변형
model = MultinomialNB(alpha=1.0) # 라플라스 스무딩
# 학습 시키기
model.fit(X_train_vec, y_train)
# 내가 만든 데이터로 확률 뽑기
proba = model.predict_proba(X_test_vec)
for mail, p in zip(text, proba):
print("******************************************************************")
print("******************************************************************")
print(f"메일 내용 : {mail}")
print(f"스팸 확률: {p[1]:.3f}")
print("******************************************************************")
print("*******************************다음 메일 **************************")
countvectorizer
- 컬럼 → 코퍼스의 토큰이 들어감
- 값으로는 토큰이 나온 횟수, 개수가 나옴
GaussianNB
MultinomialNB
강사님 코드로 스팸메일 탐지
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
corpus = [
"동해물과 백두산이",
"넌 나에게 모욕감을 줬어",
"맥북 싸게 팔아요",
"맥북 프로 가격 얼마인가요, 맥북 에어도 있어요"
]
X = vectorizer.fit_transform(corpus)
pd.DataFrame(X.toarray(), columns=vectorizer.get_feature_names_out())

df = pd.read_csv("./spam_ham_3000.csv")
df['text'] = df['subject'] + df['body']
x=df['text']
y=df['label']
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=42)
vectorizer = CountVectorizer(
max_features=5000,)
x_train_vec = vectorizer.fit_transform(x_train)
x_test_vec = vectorizer.transform(x_test)
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB(alpha=1.0)
model.fit(x_train_vec, y_train)
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
y_pred = model.predict(x_test_vec)
data_vec = vectorizer.transform(["내일 오전 10시에 여의도에서 당첨 확률 100% 리딩방 오세요"])
model.predict_proba(data_vec)
model.predict(data_vec)