main components
1) Detection: interset point 식별
2) Description: feature descriptor 추출
3) Matching: 이미지들의 descriptor간의 correspondence 결정
sobel filter나 laplace filter 같은 kernel을 통해 object detection을 했다면 두 물체가 같은 물체에 해당하는지 matching을 위해 descriptor을 생성해야 한다.

위 그림과 같이 rotation이나 scaling같은 geometric transformation이 발생하거나 intensity change와 같은 photometric transformation이 발생할 경우 두 물체가 같은 물체인지 matching하기 어려운 경우가 생긴다.
Descriptor
descriptor는 invariacne와 discriminality 라는 두 특성을 만족해야 한다.
invariance: transformation이 발생하더라고 descriptor는 변하지 않아야 한다.
discriminality: descriptor는 각 점에 대해 unique해야 한다.
image patch
patch에서 픽셀 값만을 사용하는 가장 naive한 방법으로 살짝의 변형만 줘도 matching이 잘 안된다. 또한 fine한 이미지일수록 matching이 잘 안된다. downscaling을 통해픽셀 주변값들을 묶어서 변형에 조금 robust할 수 있으나 여전히 한계가 명확하다.

binary discriptor
픽셀값의 difference를 사용하여 전체적으로 밝든 어둡든 어떤 부분이 밝아진다는 것에 집중하여 absolute pixel value에 robust한 descriptor로 양과 음 이진법으로 표현한다. 이 방법은 모양 자체에 변형을 주는 defomation에는 성능이 안좋다는 단점이 있다.
color histogram
patch내의 RGB의 색을 세어서 히스토그램으로 만든 것으로 small defomation이나 rotation이 발생해도 color histogram은 invariant하다는 장점이 있으나 공간정보가 없어서 비스한 색의 분포를 가지는 전혀 다른 object를 같은 object로 인식한다는 단점이 있다.

이러한 문제점을 해결하기 위해 patch를 여러 cell로 나누어 cell마다 color histogram을 구하는 방식으로 위 현상을 완화할 수 있으나 이럴 경우 rotation에 robust한 장점이 사라지는 문제가 발생하기도 하여 근본적인 해결책이 될 수 없다.

orientation normalization
위와 같은 문제점을 해결하기 위해 image gradient를 계산하여 가장 큰 값을 가지는 gradient의 방향을 기준으로 회전각도를 보정해주는 방법으로 예를 들어 한 이미지의 image gradient를 계산한 결과 0도였고 다른 이미지는 90도였다면 이미지를 90도 rotation하여 matching할 수 있게 된다.
Haar like features
사람의 얼굴에는 특별한 패턴이 있는데, 두 눈은 명암이 어둡고 코는 명암이 밝은 등의 명암을 이용해 패턴을 구하는 방법이 haar like features이다. 이미지에 흑백의 사각형을 겹쳐 놓은 다음 하얀 영역에 속한 픽셀 값들의 평균에서 검음 영역에 속한 픽셀값들의 평균의 차이를 구한 다음 임계값 이상일 경우 이 영역을 haar like features로 지정할 수 있게 된다.
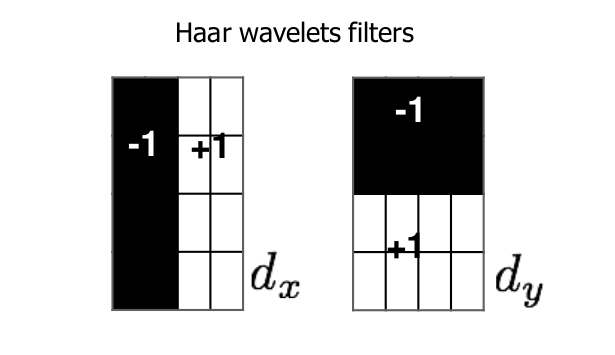
이러한 filter를 16개를 모아놓은 filter bank를 사용하여 다음 이 값들을 바탕으로 값이 유사하면 같은 물체로 matching할 수 있게 된다.
그러나 이러한 방법들은 연산이 너무 많이 걸린다는 단점이 있다. 이를 해결하기 위해 integral image를 사용한다.
integral image

위 이미지와 같이 accumulative pixel value를 저장한 것을 integral image라고 한다. integral image를 사용하여 원하는 영역의 pixel값의 합을 더 효율적으로 계산할 수 있다.

Local binary pattern (LBP)
block의 가운데 pixel 값을 임계값으로 하여 0과 1로 binary하게 나타내어 이진수나 십진수로 표현하는 방법으로 gray level의 intensity change에는 invariant하며 연산적으로 단순하다는 장점이 있다.
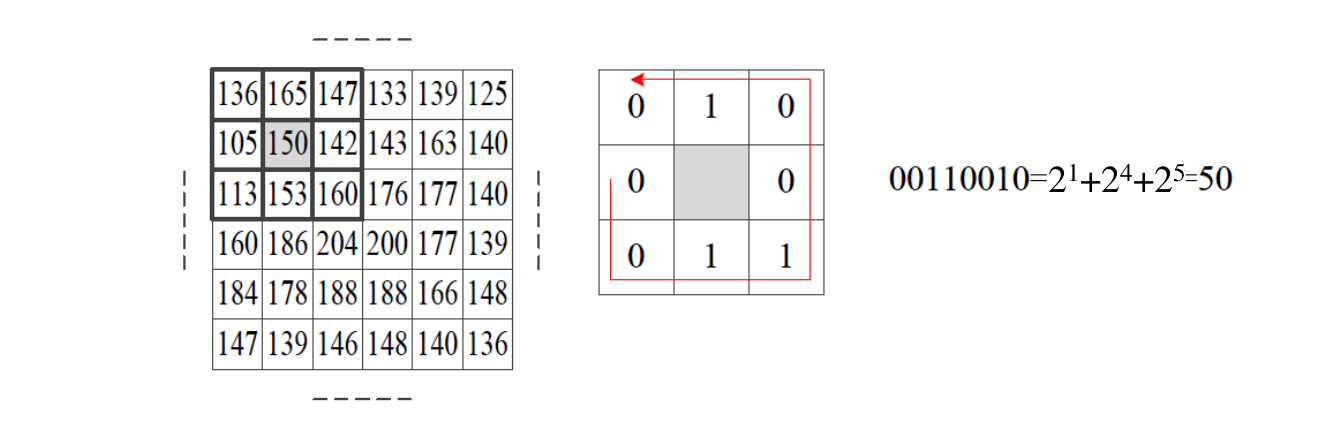
이렇게 구한 LBP 이미지를 바탕으로 histogram을 생성할 수도 있다.

Local ternary patterns
n을 block의 가운데 pixel값이라고 하고 p를 current pixel value라고 할 때, (n - p) < - t 일 때, -1로 (n - p) > t일 때 1로 -t < (n - p) < t 일 때 0으로 할당하여 case를 3개로 나누어 좀 더 자세한 패턴을 추출할 수 있게 된다.
HOG Descriptor
cell을 나누고 gradient를 계산한 후 direction별 magnitude를 계산하여 histogram으로 바꾼 후 각 cell들의 histogram을 하나로 합쳐 이를 비교하여 유사도를 계산하는 방식이다.
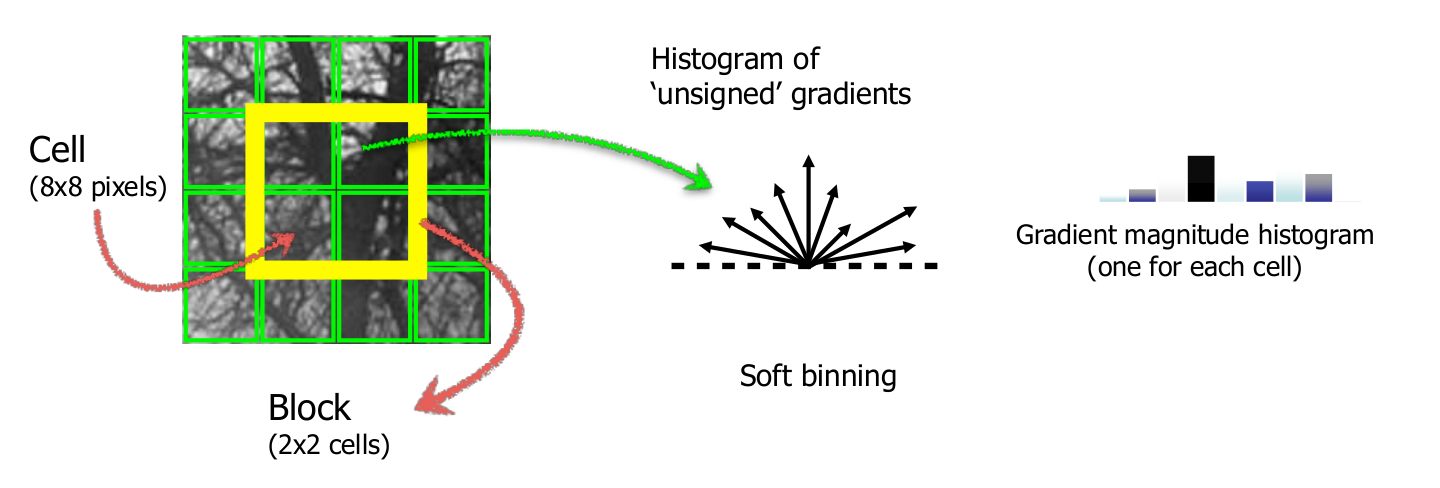
이때, directoin을 임의의 개수의 bins로 나누어 히스토그램을 구하는데 픽셀값이 bins에 딱 맞지 않을 경우 비율에 따라 나뉘어져 accumulate된다.
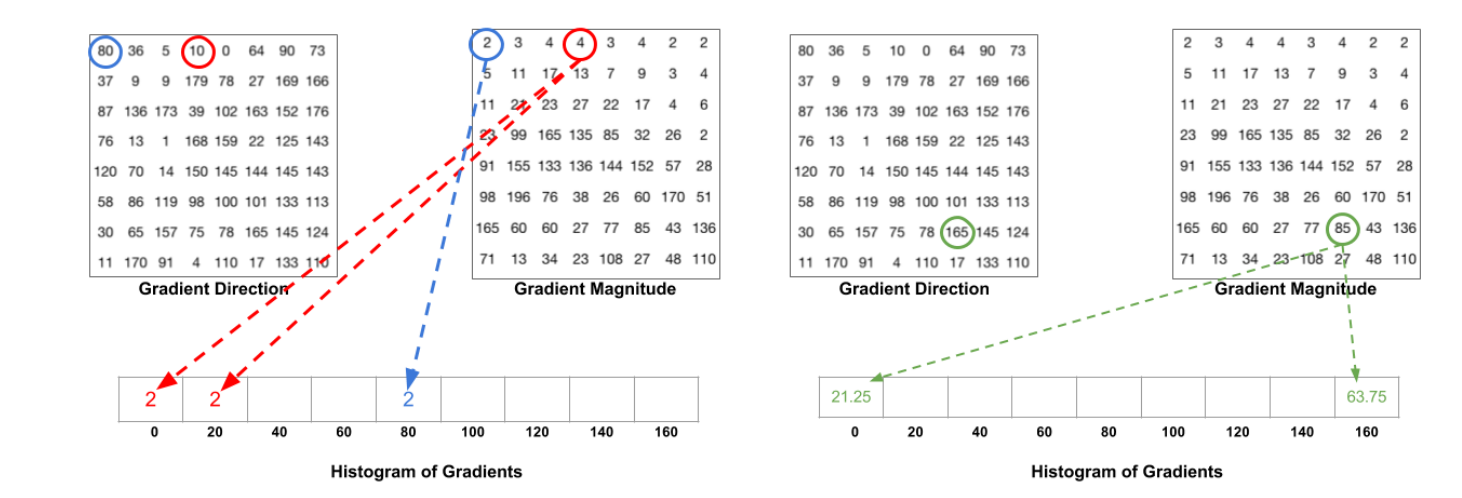
한개의 block 2 X 2 cell이고 한개의 cell은 8 X 8이므로 한개의 block은 16 X 16 pixel을 가지며 하나의 cell은 9bins인 9 X 1 vector이며 4개의 histograms이므로 36 X 1 vector 형태가 되고 block단위로 normalization 진행하여 block단위로 gradient feature vector를 계산한다.
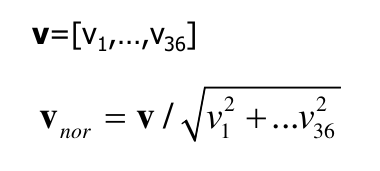
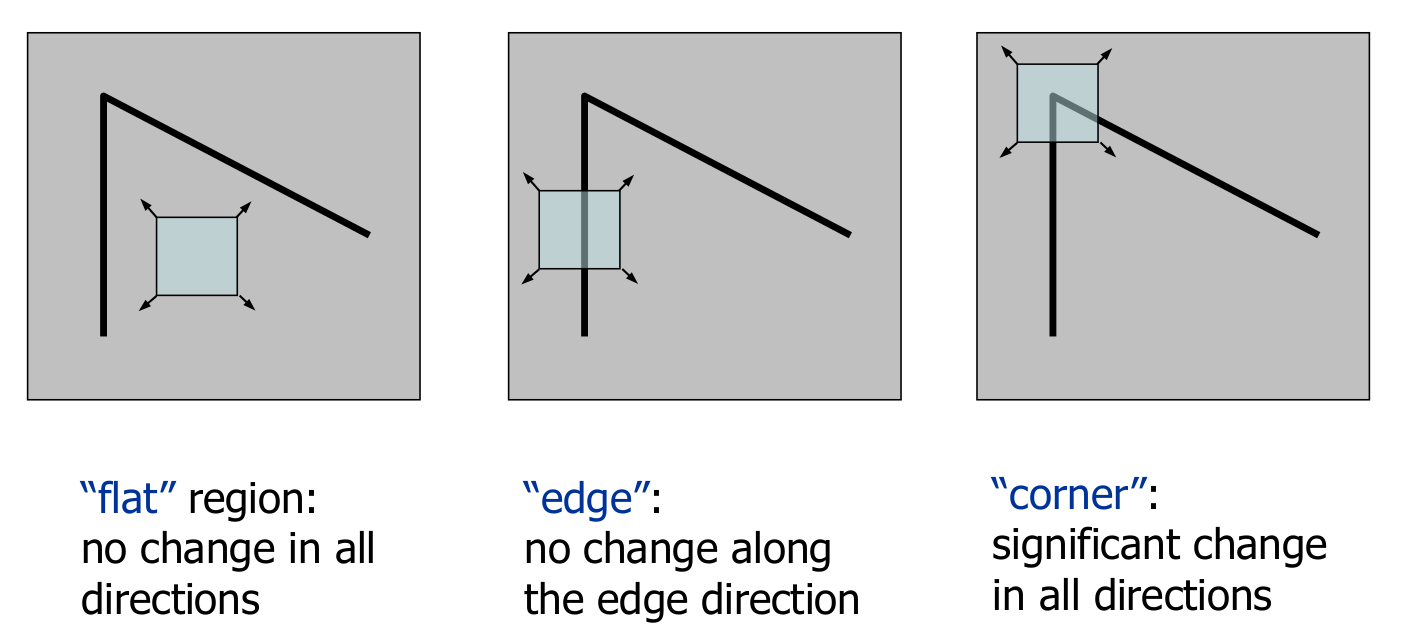
local measures of uniqueness
interest point를 찾기 위한 방법으로 pixel을 움직여 봤을 때, 변화에 따라 공간의 case를 판단하는 방법으로 모든 방향에서 변화가 없으면 "flat", edge방향에서 변화가 없으면 "edge", 모든 방향에서 변화가 있으면 "corner"판단한다.
픽셀의 변화량을 측정하는 수학적 공식은 다음과 같다.
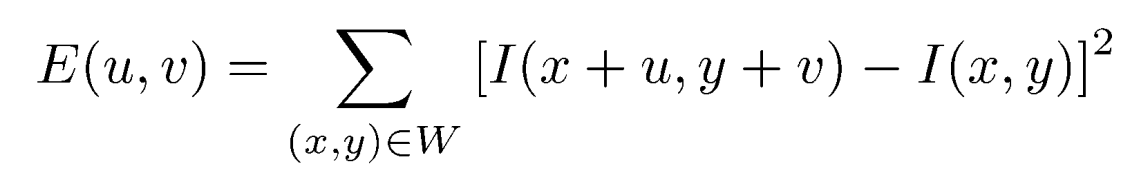
Talyor Series
gradient를 이용해서 x축으로 u만큼 y축으로 v만큼 움직였을 때의 pixel값을 유추하는 방법으로 테일러 급수를 사용한다.
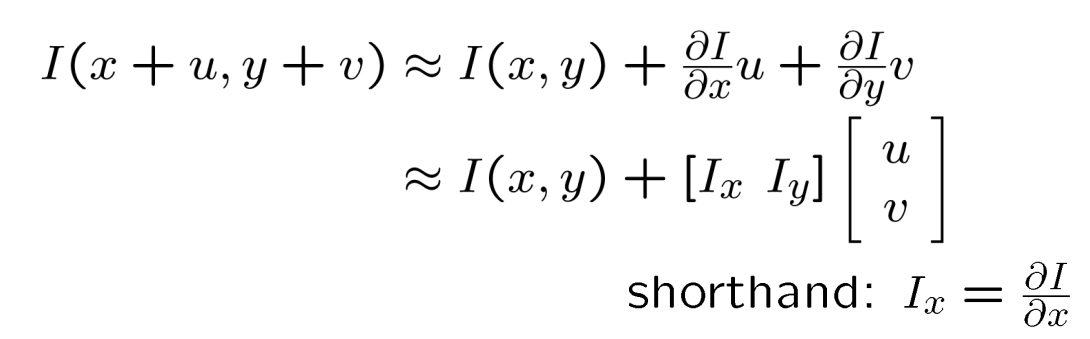
위 테일러 급수를 픽셀 변화량 측정하는 공식에 대입하면 아래와 같이 표현할 수 있다.
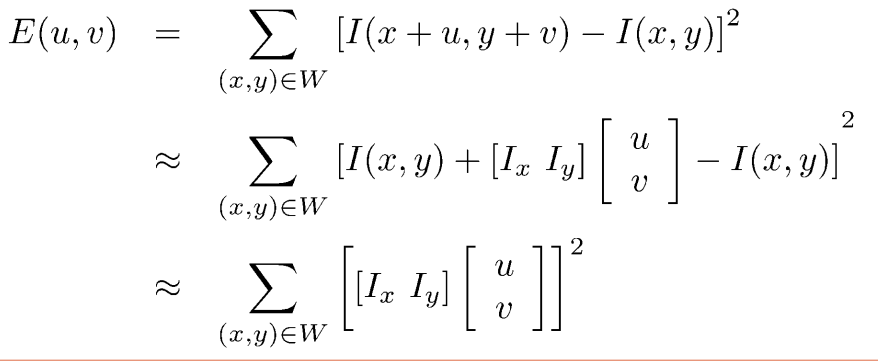
아래와 같이 풀었을 때 2 X 2 matrix를 structure tensor라고 부른다.
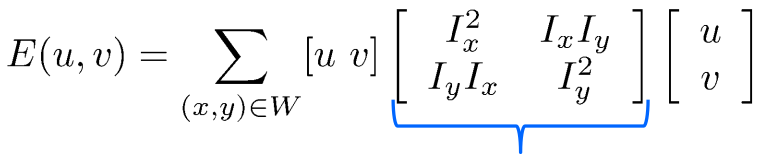
위 structure tensor에서 eigenvalue를 계산할 때, eignvalue가 크다면 해당 eignvector 방향으로 이동할 때 변화량이 크다는 것을 의미한다. 만약 더 작은 eignvalue 조차 크다면 해당영역은 corner이며 두 eignvalue 사이의 차이가 크면 edge이며 두 eignvalue값이 다 작으면 flat이라고 할 수 있다.
