-
현재 DB
내가 현재 근무하는 곳의 데이터 베이스는 PostgreSQL을 사용한다
-
문제 상황
여기서 초에 30번 이상 저장되는 실시간 좌표 저장 DB 테이블이 있는데 설계 당시에 이렇게 많이 저장할 것을 생각을 못해서 지금은 약 500만개 이상의 데이터가 있는데 조회 하는데 속도가 느려지는 문제가 발생
-
예상 해결 방법
어떻게 DB 쿼리 튜닝을 할지 고민해보고 가장 간단한 방법이 INDEX 라고 한다.
왜 INDEX가 언급되는지, 어떻게 쓰는지, 왜 쓰는지 ❓ 를 알아보자
INDEX
INDEX 테이블의 조회 속도를 높여주는 자료구조
데이터의 위치를 빠르게 찾아주는 역할이다.
예를 들어자면 백과사전을 이용할때 ㄱ-ㅎ 까지 색인 중 원하는 단어의 색인을 먼저 찾아 보는것과 비슷하다고 생각
MySQL에서는 INDEX를 설정하면 MYI라는 파일에 저장된다고 한다.
인덱스를 설정하지 않으면 원하는 데이터를 찾을때 까지 전체 스캔을 하기 때문에 성능저하가 일어날 수 밖에 없음
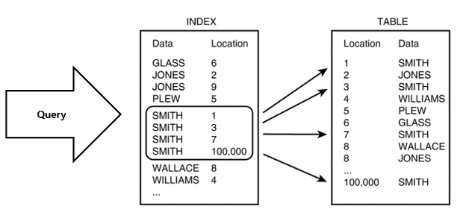
위 그림을 보면 기존 테이블과 달리 인덱스는 Data별로 정렬이 되어있다.
그렇기 떄문에 Data의 정렬대로 조회하기 때문에 조회 속도가 빠르다.
그럼 이제 저런 구조인건 알겠고 정렬을 어떻게 하며 왜 INDEX를 써야 빠르냐에 대해서 깊게 한번 알아보자
INDEX 사용 이유
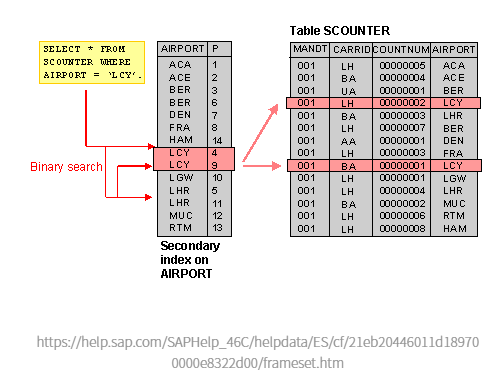
이 예시를 한번 보자
AIRPORT LCY 라는 값을 테이블에서 조회한다고 가정해보자
TABLE에서 바로 단순하게 SELECT으로 조회시 모두 테이블 ROW를 조회할 것이다.
만약에 내 상황처럼 데이터가 500만개 이상인데 매 초마다 저장된 좌표값을 받아온느 것은 엄청난 시간 낭비이다.
이런 문제를 방지하는 것이 IDNEX 이다.
INDEX의 동작은 어떤식인가 알아보자
AIRPORT를 인덱스로 설정하면 AIRPORT 컬럼에 대한 인덱스가 생성된다.
SELECT을 통해서 테이블 조회를 할때 AIRPORT 컬럼에 대한 where 문 쿼리가 실행될떄 인덱스 테이블에 저장된 key-value 값을 참조해서 테이블에서 결과값 반환
동작 순서
- INDEX 테이블에서 where 절 포함 값 찾음 (key - value)
- 해당 값의 table_id (PK) 가져옴
- 가져온 table_id(PK) 값으로 원본 테이블에서 값 조회
대표적으로 DBMS가 INDEX를 관리하는 알고리즘은 B-Tree 알고리즘이다
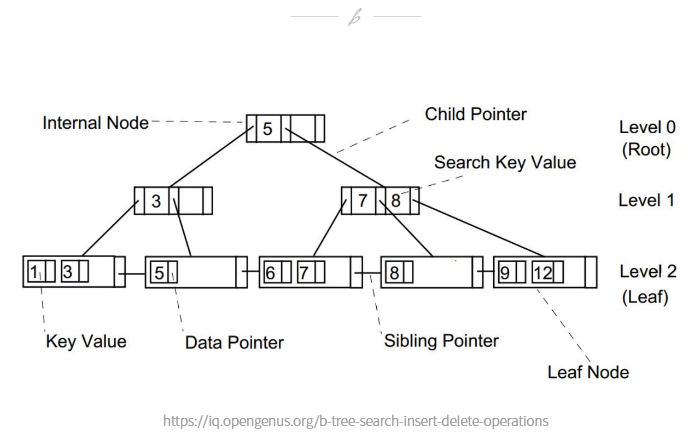
흔히 트리와 비슷하게 리프노드, 루트 노드가 있고 논리 노드가 있다.
간략하게 생각하면 idrk 1-100까지 있을때 51번 ID를 검색하면 1에서 51까지 검색하는게 아니라 절반으로 나눈 50 이상인가 이하인가를 판단하고 50보다 크니 51-100 사이를 다시 반으로 쪼개서 검색한다고 라고 생각하면 된다.
B+Tree 알고리즘은 업데이트 예정 💬
💡 인덱스를 사용하는 결정적 이유는 외부적인 하드웨어 향상 같은게 아닌 DBMS 자체에서 인덱스 설정을 통해서 쿼리 조회 속도를 높이는 가장 간단하고 쉬운 방법이다.
1차적으로 속도 튜닝을 위해서 인덱스 설정
INDEX 종류
인덱스라고 단순하게 인덱스 하나만 존재하는게 아닌 여러 인덱스가 있다
Key 에 따른 인덱스
기본 인덱스 (Primary Index)
기본키를 포함하는 인덱스( 키의 순서가 레코드 순서)보조 인덱스 (Secondary Index)
기본 인덱스 이외의 인덱스 (PK 순서와 레코드 순서 일치 X)
파일 조직에 따른 인덱스
집중 인덱스
데이터 레코드의 물리적 순서가 그 파일에 대한 인덱스 엔트리 순서와 동일하게 유지비집중 인덱스
집중 형태가 아닌 인덱스
데이터 범위에 따른 인덱스
밀집 인덱스
데이터 레코드 각각에 대해 하나의 인덱스 엔트리가 있는 인덱스희소 인데긋
레코드 그룹, 데이터 블록에 대해 하나의 엔트리가 만들어지는 인덱스
등 여러 인덱스의 종류가 있다.
다만 처음 들어보는 내용도 너무 많으며 어떤 인덱스가 어떤 상황에 적합한지에 대한 판단 또한 없다.
그렇기 떄문에 가장 쉽게 사용 하고 내가 본 케이스인 key에 따른 인덱스를 추후 직접 사용할 예정이다.
인덱스를 사용하는 시기
인덱스 테이블
인덱스는 하나의 테이블에 값을 저장하고 사용한다.
그래서 다른 테이블에 의존적인 하나의 테이블을 생겨 부분별한 인덱스는 오히려 성능 저하
인덱스 테이블은 이진트리 검색을 사용한다. 기본적으로 정렬되어 있음
인덱스 테이블에서 삽입, 삭제, 수정이 자주 일어나면 계속 정렬해야해서 성능 저하 생길 수 있음
배민에서 사용자가 지역별 음식점을 조회하고 검색하는 기능이 서비스의 주요 기능이고
많은 음식점이 있기에 인덱스를 잘 사용하면 빠르게 조호 ㅣ가능해질 것이ㅏㄷ.
SNS에서는 게시글이 미친듯이 생겨나기에 인덱스를 쓰면 오히려 정렬시키는데 시간이 더 오래걸려서 성능 저하 가능성 생김
각 테이블의 특성에 맞게 인덱스를 적절하게 사용
새로운 데이터의 삽입이나, 업데이트 정도에 따라서 고르면 좋을 것으로 판단됨
인덱스 생성 쿼리
단일 인덱스
CREATE TABLE table1(
uid INT(11) NOT NULL auto_increment,
id VARCHAR(20) NOT NULL,
name VARCHAR(50) NOT NULL,
address VARCHAR(100) NOT NULL,
PRIMARY KEY('uid'),
key idx_name(name),# index
key idx_address(address) # index
)다중 인덱스
CREATE TABLE table2(
uid INT(11) NOT NULL auto_increment,
id VARCHAR(20) NOT NULL,
name VARCHAR(50) NOT NULL,
address VARCHAR(100) NOT NULL,
PRIMARY KEY('uid'),
key idx_name(name, address)
)테이블 생성 시 지정도 가능하고
-- 단일 인덱스
CREATE INDEX 인덱스이름 ON 테이블이름(필드이름1)
-- 다중 컬럼 인덱스
CREATE INDEX 인덱스이름 ON 테이블이름(필드이름1, 필드이름2, ...)추후에 추가도 가능하다.
-- 단일
CREATE UNIQUE INDEX 인덱스 이름 ON 테이블이름(필드이름1)
-- 다중
CREATE UNIQUE INDEX 인덱스 이름 ON 테이블이름(필드이름1, 필드이름2, ...)UNIQUE를 사용해서 중복을 허용하지 않는 인덱스도 가능하다.
생성시 ASC, DESC 를 추가해서 어떻게 정렬할지도 정해줄 수 있다.
여러가지 상세한 내용이 추가되어 있겠지만 드리플 프로젝트에서 사용할 방법을 구상하며 한번 다시 해보려함
