백엔드 공부를 하며 DB는 필연적으로 잘 알아야하는 분야이며
특히 설계하는 것이 아주 어렵다.
쿼리 최적화 등 여러 문제는 레퍼런스를 찾으면 어떻게든 되지만 설계는 현재 상황에 맞게 잘 설계하는 것이 중요하며 추후 수정이 어렵기 때문에 정말 중요하다.
그럼 좋은 설계는 어떤 것이며 어떻게 DB를 설계하는지 한번 알아보자
좋은 데이터 베이스 설계
관계형 데이터베이스 3가지 초점에 기반해서 설계 해야 한다.
- 무결성
데이터베이스 내에 모든 값은 언제나 정확한 값을 유지해야한다. - 유연성
데이터베이스 구조는 요구사항 변화에 대해 수정이 쉬워야한다. - 확장성
데이터베이스 구조는 기능 확장에 대해서 수정이 쉬워야한다.
3가지의 초점을 모두 고려하고 동시에 성능 까지 조화된 것이 좋은 설계라고 할 수 있다.
그럼 이 3가지를 고려한다고 하면 어떤식으로 설계를 해야하는 건지 알아보자
개념적 모델링
현실세계의 개념을 데이터 테이블로 투영시키는 것이 데이터 모델링이다.
즉 현실세계의 개념이 어떻게 상호작용하는지 파악하는 단계
entity, attribute, relation을 정의하는 단계이다.
이떄 ERD(Entity Relation Diagram)이라고 불리는 결과물이 나옴
-
entity(개체)
현실세계의 정보들을 그룹화 한것이다.
추후에 ERD 테이블의 이름이 된다.
✅JPA에서는 엔티티 컴포넌트 이름 -
Attribute(속성)
현실세계의 정보, 속성이 모여서 엔티티가 된다.
테이블의 컬럼에 맵핑된다 -
Relation(관계)
1:n n:m등을 결정하는 요소
JPA에서는 OneToMany 등 어노테이션으로 정의
엔티티 클래스 예시를 보자
class User{
int id
string name
Card[] cards
}클래스명인 user 가 엔티티, id,name은 속성, Card는 관계이다
웹 개발을 기준으로 화면기획서를 기반해서 모든 테이블, 체크박스, 라디오 박스등 사용자의 모든 입력을 어디엔가는 저장해야한다.
attribute를 묶어 entity를 만들고 다른 entity와의 relation을 만든다!
논리적 모델링
DB설계에서 가장 중요한 부분이라고 알 ㅅ ㅜ있따.
논리적 모델링이 잘 수행되지 않으면 추후 이상현상, 불필요한 반복과정이 생길 수 있따.
여기서 이상현상은 다음과 같다.
삽입 과정에서 불필요한 데이터가 있어야 삽입이 가능하고, 삭제시 필요한 정보까지 삭제되야해서 어떤 추가 과정이 필요한 경우이다.
이는 논리적 모델링에서 정규화 단계가 포함되어 있기 때문이다.
정처기 시험에서 배운 정규화 과정이 중요한 이유
정규화는 테이블을 쪼개서 불필요한 데이터 중복은 제거하는 것이다.
정규화된 데이터를 통해서 DB용량을 줄이지만 Trade-off 관계로 join 비용의 증가로 이를 줄이는 기 위해서 테이블을 합치는 걸 반정규화 라고 한다.
3정규화 이상이 수행되면 일반적으로 정규화된 테이블이라고 명명
1. 제1정규화
모든 속성이 도메인 원자값으로 구성되어 있도록 바꾸는 과정

이런 테이블이 있다고 할때 John의 핸드폰이 2개이다.
이때 정규화를 수행하자
- 잘못된 정규화

이렇게 되면 무한히 테이블의 컬럼이 증가할 수 있음
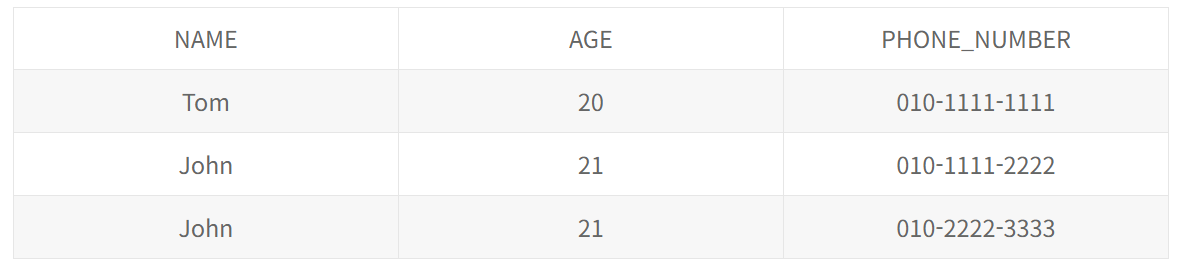
이렇게 한다면 무한히 테이블의 row가 증가할 수 있음
즉 정규화란 테이블 쪼개서 중복을 최소화 하는 거다.
여기서 좋은 정규화는 사용자 정보와, 핸드폰 정보를 분리하는 것이다.

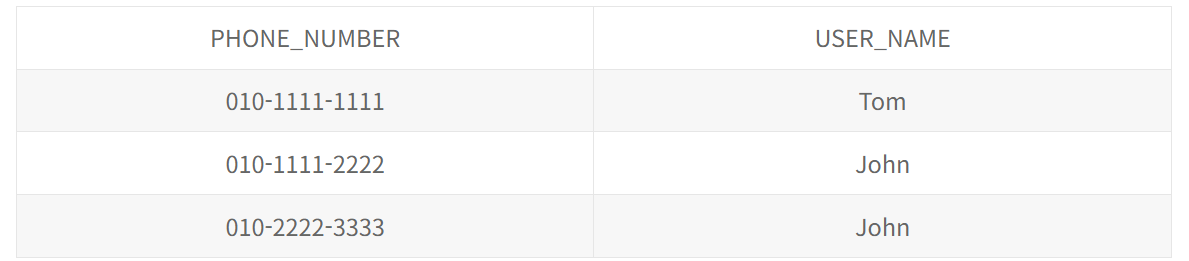
이런식으로 유저 테이블, 핸드폰 테이블을 분리해서 모든 속성이 도메인 원자값이라 제1정규화를 만족한다.
1. 제2정규화
1정규형을 만족하면서 기본키가 아닌 속성이 기본키에 완전 함수 종속
흔히 부분 함수 종속을 제거한다고도 함
기본키가 아닌 것들은 기본키가 결정되면 모두 결정되도록 만들어줌
테이블에서 기본키와 후보키가 모여서 중복키가 돼서 나머지를 결정 지을수 있다면 제 2정규화 진행
말로하면 잘 이해가 안되니 예시를 통해서 한번 알아보자

여기 예시를 보면 뭔가 기본키가 후보키가 모여서 나머지를 결정지으면 안되는데 위 테이블에서는 그런 상황이 보인다.
이 테이블을 찬찬히 보면 학번에 따라서 학생의 정보가 변경되는것은 당연하며 학번이 결정되면 이름, 학과, 성별이 결정되는 것은 문제가 없다.
하지만 학번과 과목코드를 합친 [학번, 과목코드]를 통해서도 나이나, 성별을 알 수 있다.
근데 나이나 성별은 학번에 종속된 속성이다.
기본키 중에 특정 컬럼에만 종속된 컬럼이 존재할 경우에 2차 정규형에 위배
이런 과정을 해결하기 위해서 제2 정규화를 실행한다.


이렇게 성적 정보를 분리해서 학번은 이름, 학과 , 성별등 학번에 종속되는 컬럼으로 구성하고
성적 정보는 학번, 과목코드에만 종속되게끔 한다.
핵심은 PK에 대한 종속을 고려한다.
3. 제3정규화
제1,제2 정규형 만족 이후 이행 함수종속을 제거하면 제3정규형이다.
이행함수 종속이란 기본키가 결정되면 나머지 것이 결정되야 하지만
기본키가 결정돼서 그 중 하나의 값이 결정되는 순간 나머지가 결정되는 상황을 의미
아래 예시를 보자
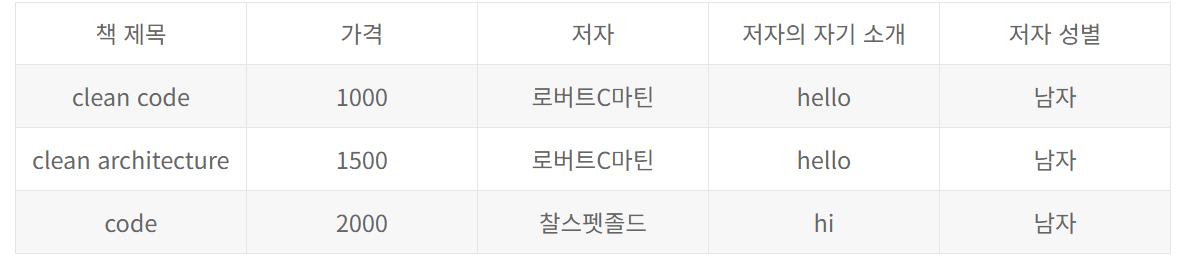
기본키가 책 제목이다.
책 제목, 즉 책이 결정되면 가격, 저자가 결정되고 저자가 결정되면 저자의 소개, 성별등이 결정 이걸 이행 함수 종속
저자는 여러권을 책을 집필할 수 있고 책과 저자는 1:n의 관계를 가진다.
n쪽인 책에다가 외래키를 걸어주자
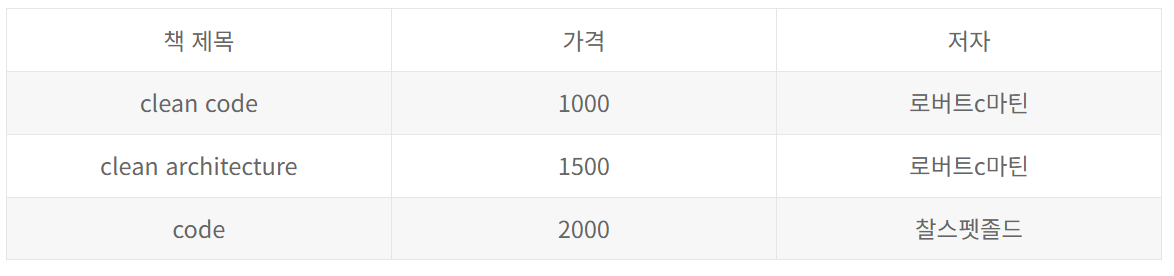

이런식으로 저자와 책을 분리하고 책에서 저자의 성별까지 필요한 경우 Join연산을 통해서 필요한 부분만 합치면 된다.
1:n 관계에서 1인 쪽에 외래키를 걸면 스키마가 오염된다
물리적 모델링
물리적 모델링은 DDL을 작성하고 물리적인 테이블을 만드는 과정이다.
테이블 구조로 슬로우쿼리를 분석하는 것은 어려운 일중 하나이다.
조회가 중요한 테이블은 INDEX를 설정하고 확장 여지가 없는 테이블에는 반정규화를 고려하는 것이 물리적 모델링 과정이다.
이는 추후 프로젝트 과정에서 다시 상세하게 다룰 예정이다.
DB 스키마 오염
DB 스키마는 개념적 모델링을 제대로 하지 못하면 오염이 일어난다.
확장을 고려하지 않고, 엔티티를 불분명하게 선정하거나, 논리적 모델링 단계에서 정규화를 제대로 하지 않으면 테이블에 필드를 추가할때 쉽게 오염이 생김
오염이 위험한 이유는 이미 사용하는 데이터가 있기 때문에 수정이 쉽지가 않다.
DB 테이블을 설계하는 것은 쉬운일이 아니다. 한번 제대로 설계하지 못하면 그로 인한 오는 리스크를 쉽게 처리하기가 힘들다.
자사의 DB도 너무 서로 얽혀있고 특히 NULL 값이 많은건 개인적으로 문제라고 생각된다.
이런 걸 어떻게 고려해서 설계해야하는지는 앞으로 배워갈 과정 중 하나라고 생각해본다
