서울시 공공자전거 ETL 파이프라인 구축기 (1) - 프로젝트 소개 & 아키텍처 설계
서울시 공공자전거 ETL 파이프라인 구축기 (1) - 프로젝트 소개 & 아키텍처 설계
개발자에서 데이터 엔지니어로 전향하기 위해 진행한 포트폴리오 프로젝트입니다.
서울시 공공자전거(따릉이) 실시간 데이터를 수집하고 분석하는 ETL 파이프라인을 구축했습니다.
🎯 프로젝트를 시작한 이유
개발자로 일하면서 Informatica라는 데이터 플랫폼을 개발하고 구축하는 업무를 맡게 되었고 데이터의 중요성을 점점 더 느끼게 되었습니다. 다양한 데이터 처리 도구를 통해 서비스에서 발생하는 데이터를 어떻게 수집하고, 정제하고, 분석할 수 있는 형태로 만드는 지에 대한 관심을 가지게 되었고, 이 과정을 직접 경험해보고 싶었습니다. 실제 API 데이터를 활용한 프로젝트를 통해 데이터 엔지니어링의 전체 흐름을 경험해보고자 이 프로젝트를 시작했습니다.
📌 프로젝트 개요
| 항목 | 내용 |
|---|---|
| 프로젝트명 | 서울시 공공자전거 ETL 파이프라인 |
| 목표 | 실시간 공공자전거 데이터 수집 및 분석 마트 구축 |
| 기간 | 2024.12 ~ 2025.01 (약 4주) |
| GitHub | seoul-bike-etl-pipeline |
왜 서울시 공공자전거 데이터인가?
데이터 엔지니어링 프로젝트의 데이터 소스를 선정할 때 고려한 점은 다음과 같습니다.
- 실시간 데이터: 정적인 CSV가 아닌, 실제로 갱신되는 데이터
- 안정적인 API: 학습 목적으로 사용하기에 안정적인 공공 API
- 적당한 데이터 규모: 너무 작지도, 너무 크지도 않은 규모
- 비즈니스 의미: 실제 분석 가치가 있는 데이터
서울시 공공자전거 API는 이 모든 조건을 충족했습니다. 약 2,600개 대여소의 실시간 정보가 5분마다 갱신되고, 무료로 사용할 수 있습니다.
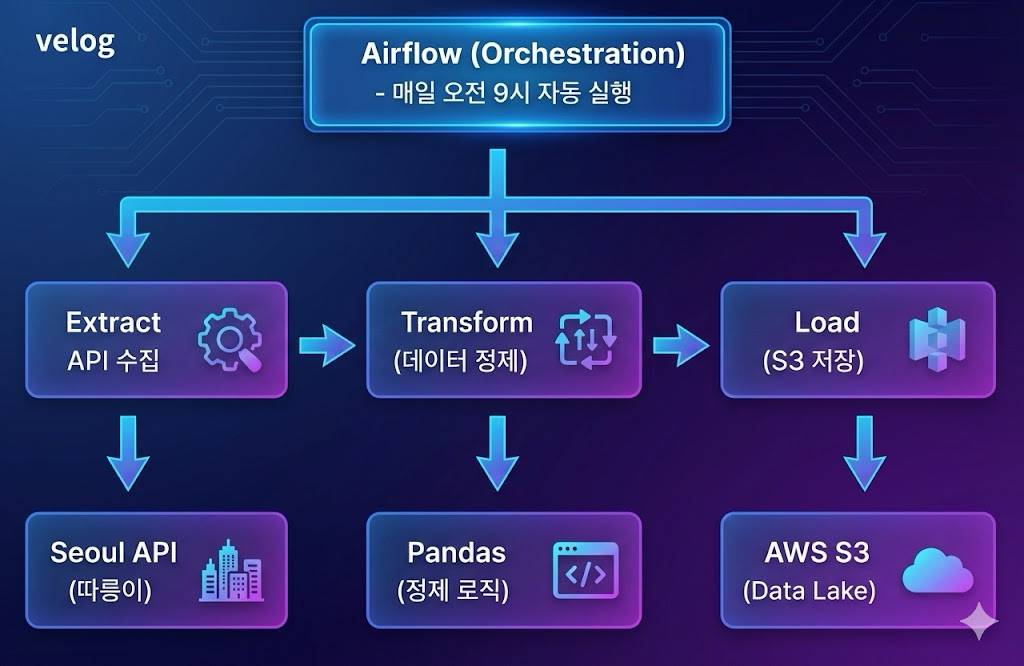
🏗️ 아키텍처 설계
전체 파이프라인 구조
기술 스택
| 분류 | 기술 | 선택 이유 |
|---|---|---|
| Language | Python 3.9+ | 데이터 처리 생태계가 풍부함 |
| Orchestration | Apache Airflow 2.10 | 업계 표준, 스케줄링 및 모니터링 UI 제공 |
| Storage | AWS S3 | 확장성 있는 Data Lake 구축 가능 |
| Container | Docker, Docker Compose | 재현 가능한 개발 환경 |
| Data Processing | Pandas | 중소 규모 데이터 처리에 적합 |
| File Format | JSON, Parquet | Raw는 원본 보존, Cleaned는 효율적 저장 |
왜 Airflow인가?
처음에는 단순히 Python 스크립트를 cron으로 실행하는 방법도 고려했습니다. 하지만 Airflow를 선택한 이유는 다음과 같습니다.
- 의존성 관리: Task 간 순서와 의존 관계를 명확히 정의
- 재시도 로직: 실패 시 자동 재시도 (API 서버 일시 장애 대응)
- 모니터링: 웹 UI로 실행 상태, 로그, 히스토리 확인
- 확장성: 추후 Task 추가나 복잡한 워크플로우 구성 용이
- 실무 표준: 대부분의 DE 채용 공고에서 Airflow 경험 요구
왜 S3인가?
로컬 파일 시스템이나 데이터베이스 대신 S3를 선택한 이유입니다.
- 확장성: 데이터 양이 늘어나도 걱정 없음
- 비용 효율: 사용한 만큼만 과금 (프리티어로 충분)
- Data Lake 패턴: 실무에서 사용하는 아키텍처 경험
- 다양한 포맷 지원: JSON, Parquet 등 자유롭게 저장
왜 Parquet인가?
Cleaned Layer와 Mart Layer에서 Parquet 포맷을 사용한 이유입니다.
| 특성 | JSON | Parquet |
|---|---|---|
| 저장 용량 | 큼 | 작음 (압축) |
| 읽기 속도 | 느림 | 빠름 (컬럼 기반) |
| 스키마 | 없음 | 있음 |
| 용도 | 원본 보존 | 분석용 |
Raw Layer는 원본 보존을 위해 JSON으로, 이후 레이어는 분석 효율을 위해 Parquet으로 저장합니다.
📊 데이터 레이어 설계
Data Lake의 핵심은 레이어 분리입니다. 각 레이어는 명확한 목적을 가지고 있습니다.
┌─────────────────────────────────────────────────────────────┐
│ S3 Bucket │
├─────────────────────────────────────────────────────────────┤
│ │
│ 📁 raw/ ← Raw Layer │
│ └── bike_rental/ │
│ └── dt=2025-01-12/ │
│ └── data.json (API 원본 그대로) │
│ │
│ 📁 cleaned/ ← Cleaned Layer │
│ └── bike_rental/ │
│ └── dt=2025-01-12/ │
│ └── data.parquet (정제된 데이터) │
│ │
│ 📁 mart/ ← Mart Layer │
│ ├── daily_station_summary/ │
│ ├── hourly_pattern/ │
│ └── station_ranking/ (분석용 집계 데이터) │
│ │
└─────────────────────────────────────────────────────────────┘Raw Layer
- 목적: API 응답 원본 그대로 보존
- 포맷: JSON
- 파티션: 일자별 (
dt=YYYY-MM-DD) - 특징: 어떤 가공도 하지 않음 (문제 발생 시 원본 확인용)
Cleaned Layer
- 목적: 분석 가능한 형태로 정제
- 포맷: Parquet
- 파티션: 일자별 (
dt=YYYY-MM-DD) - 처리 내용:
- 컬럼명 정리 (camelCase → snake_case)
- 타입 변환 (문자열 → 숫자)
- 결측치 처리
- 이상치 필터링
- 파생 컬럼 추가
Mart Layer
- 목적: 특정 분석 목적에 맞는 집계 데이터
- 포맷: Parquet
- 종류:
daily_station_summary: 일별 대여소 요약hourly_pattern: 시간대별 이용 패턴station_ranking: 대여소 랭킹
📁 프로젝트 구조
seoul-bike-etl-pipeline/
├── dags/
│ └── bike_etl_dag.py # Airflow DAG 정의
├── scripts/
│ ├── extract.py # API 데이터 수집
│ ├── load_raw.py # S3 Raw 저장
│ ├── transform.py # 데이터 정제
│ ├── validate.py # 품질 검증
│ ├── load_cleaned.py # S3 Cleaned 저장
│ ├── mart.py # 마트 생성
│ └── load_mart.py # S3 Mart 저장
├── docker-compose.yml # Airflow 실행 환경
├── .env.example # 환경변수 예시
├── .gitignore
└── README.md🔄 파이프라인 흐름
최종 구현된 파이프라인의 Task 흐름입니다.
extract → load_raw → transform → validate → load_cleaned → create_mart
│ │ │ │ │ │
▼ ▼ ▼ ▼ ▼ ▼
API S3에 데이터 품질 S3에 분석용
호출 JSON 정제 검증 Parquet 마트 생성
저장 저장| Task | 설명 | 실패 시 |
|---|---|---|
| extract | 서울시 API에서 데이터 수집 | 자동 재시도 (최대 2회) |
| load_raw | S3 Raw Layer에 JSON 저장 | 자동 재시도 |
| transform | 데이터 정제 및 변환 | 자동 재시도 |
| validate | 데이터 품질 검증 | 검증 실패 시 파이프라인 중단 |
| load_cleaned | S3 Cleaned Layer에 Parquet 저장 | 자동 재시도 |
| create_mart | 분석용 마트 테이블 생성 | 자동 재시도 |
🔗 링크
- GitHub: seoul-bike-etl-pipeline
- 시리즈: 서울시 공공자전거 ETL 파이프라인 구축기
태그
데이터엔지니어링 ETL Airflow AWS S3 Python DataLake 포트폴리오 따릉이 공공데이터
