📑 Reranking이란?
RAG 방식의 도입을 통해 LLM의 할루시네이션 현상을 줄이고 최신 정보를 반영하여 보다 정확한 답변을 생성할 수 있게 되었다.
하지만 RAG 시스템이 복잡한 실제 어플리케이션에 적용되면서 기본적인 RAG 파이프라인 구성으로는 프로덕션 수준의 요구사항을 만족시키기 어렵다는 문제점에 도달했다.
이 문제를 해결하기 위해 Reranking 이라는 기법이 사용될 수 있다.
Reranking은 RAG가 생성한 후보 문서들에 대해 질문에 대한 관련성 및 일관성을 판단하여 문서의 우선순위를 재정렬하여 답변의 정확도를 올리는 기법이다.
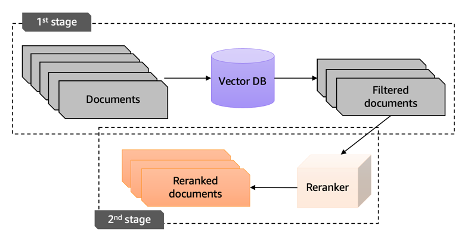
이미지 출처: https://aws.amazon.com/ko/blogs/tech/korean-reranker-rag/
Reranker의 종류는 아래의 문서를 참고하자
🌱 Cross Encoder Reranker
Cross Encoder Reranker는 Hugging Face의 cross encoder 모델 또는 BAAI/bge-reranker와 같은 모델을 사용해 reranker를 구현하는 방법이다.
!pip install faiss-cpu sentence_transformers
!pip install langchain_huggingfacevector store & retriever 셋업
인공지능과 관련된 자료를 나무위키로부터 가져와 vector store에 저장했다.
retriever를 통해 반환된 질문과 관련된 문서는 다음과 같다.
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 문서 로드
documents = TextLoader("..인공지능이란.txt").load()
# 텍스트 분할기 설정
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# 텍스트 분할
texts = text_splitter.split_documents(documents)
# 임베딩 모델 설정
embeddingsModel = HuggingFaceEmbeddings(
model_name="sentence-transformers/msmarco-distilbert-dot-v5"
)
# 문서로부터 FAISS 인덱스 생성 및 검색기 설정
retriever = FAISS.from_documents(texts, embeddingsModel).as_retriever(
search_kwargs={"k": 20}
)
>>>Document 1:
포함되는 경우도 존재하며, 이러한 세부 목표는 다시 특정 행동계획과 결합하여 의도를 구성한다. 따라서 의도는 필연적으로 트리나 리스트의 형태인 자료구조를 구성하게 되는데, 이에 따라 일반적으로 구현하는 관점에서 의도 구조체(intention structure)라고 부르기도 한다.
----------------------------------------------------------------------------------------------------
Document 2:
다만 “인공지능이 스스로 세상을 이해하느냐?” 라는 질문에 대해서는 업계 인물들의 반응이 엇갈린다. 앤드류 응, 제프리 힌튼, 렉스 프리드먼 등 학계에서 일하는 연구원들의 경우 대개 이를 긍정하지만, 안드레 카파시 등 산업계 종사자들은 이를 부정하는 인물이 많은 편이다.
----------------------------------------------------------------------------------------------------
Document 3:
인공지능에 어떠한 질문(신호)이 주어질 때 각 노드 별로 질문에 반응하며 다음 노드에 신호를 전달한다. 그래서 신호를 받는 개별 노드는 자신에게 주어진 편향(bias/기준치)에 따라 신호를 거르고 다시 산출하는데, 그렇게 걸러진 산출된 신호들의 총합이 바로 인공지능이 우리에게 전달하는 '대답'이 된다.query = "인공지능의 역사에 대해 알려줘"
docs = retriever.invoke(query)
pretty_print_docs(docs)CrossEncoderReranker를 통한 Reranking
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncodermodel = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-base")
compressor = CrossEncoderReranker(model=model, top_n=3)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
query = "인공지능의 역사에 대해 알려줘"
docs = compression_retriever.invoke(query)
pretty_print_docs(docs)
>>>Document 1:
정교한 인간에 대한 연구는 말할 것도 없다. 2017년에는 현재 기술 수준으론 선충은 고사하고 1975년에 출시한 구닥다리 칩[11]조차 뭔가를 해보는 게 불가능하다는 논문이 나오기도 했다.
----------------------------------------------------------------------------------------------------
Document 2:
[18] AI의 존재가 위협이 된다는 논의는 가까운 시기에 닥칠 문제에 대한 접근성을 떨어뜨린다며 일단 출시하고 발전시켜 나가는 방식을 지지한다.
[19] 먼 훗날의 이야기에 가깝고, 가까운 시기에 미칠 파급력이 너무나 크기 때문에 리드 호프먼과 의견을 공유한다. 애초에 이 사람은 현재 학습모델 구현 방식에 문제를 제기하고 있으며, AGI의 도래는 한참 남았다거 생각하는 듯 하다. 그의 저서 'The Coming Wave'를 통해 그의 주장을 옅볼 수 있다.
[20] 로봇은 지능형 도구에 가까운 형태로 발전할 것이라고 예측했다. 다만 이 분은 로봇공학자이며 기계공학을 전공한 비전공자이다.
----------------------------------------------------------------------------------------------------
Document 3:
물론, '인간과 같은 종류의 사고'를 하는 것을 목표로 하는 연구도 활발히 진행되고 있으며, 대표적인 예가 가상 신경망이다. 가상 신경망의 연구 역시 인간 사고 모방만이 아닌 실용적인 문제를 해결하는 쪽으로도 활용되고 있다. 대표적인 예로 통상적인 컴퓨터 알고리즘으로는 해결할 수 없는 불가능한 비가역적 연산 과정이 있는 패턴 인식이 필요한 경우. 새로운 뇌를 만든다 참고.
출처

To infinity and beyond!