
GraphQL을 왜 사용하냐고 물어보면
Under-Fetching과 Over-Fetching의 장점을 얘기 할 수 있어요
REST-API의 문제점
Over-Fetching
필요한 데이터 이상으로 서버에서 데이터를 받아오는 것을 의미해요
만약에 게시판리스트 화면을 제작할때 제목, 내용, 날짜, 작성자만 노출한다면
"data": {
"fetchLists": [
{
"_id": "202202161136190074",
"title": "제목이에요.",
"contetns": "내용입니다~",
"regDt": "2022-02-16 11:41:39.0",
"likecnt": 3, // 필요하지 않은 데이터
"writer": "쎄오",
"commentCount": "1", // 필요하지 않은 데이터
"files": [ // 필요하지 않은 데이터
{
"fileId": "FILE_202202161141390217",
"orignlFileNm": "사진.jpg",
"fileSize": "68945",
"fileExt": "jpg",
"fileKnd": "attach"
}
]
},
{
"_id": "202202161136190075",
"title": "제목이에요.",
"contetns": "내용입니다~",
"regDt": "2022-02-16 11:42:39.0",
"likecnt": 1, // 필요하지 않은 데이터
"writer": "짱구",
"commentCount": "1", // 필요하지 않은 데이터
"files": [ // 필요하지 않은 데이터
{
"fileId": "FILE_202202161141390219",
"orignlFileNm": "사진.jpg",
"fileSize": "68945",
"fileExt": "jpg",
"fileKnd": "attach"
}
]
}]
}
}필요하지 않은 데이터들까지 다같이 출력되기때문에 서버와 네트워크의 자원이 불필요하게 추가로 사용되요
Under-Fetching
한 번의 요청으로 필요한 데이터를 모두 받아오지 못해 여러 번의 요청을 수행하는 것을 의미한다.
Under-Fetching은 기능이 확장이되어 마이페이지에서 내정보를 보임과 동시에 추가로 내가 찜한 리스트를 노출 해주게 했다면
내정보와 내가 찜한 리스트를 보여주어야하는데 API의 endpoint가
Get/users/{id}(내정보) 와 Get/users/{id}/favorite(내가 찜한 리스트) 이러헤 나뉘어있다면 하나의 endpoints에서 모두 받아 올 수 없기에 2번을 호출해야하고 그렇게되면 네트워크 오버헤드가 추가되기 때문에 사용자가 앱 사용시 느린 속도로 인한 불편함을 느낄 수 있어요
GraphQL도 사실은 REST-API?!
REST-API를 개선한것이 GraphQL이에요
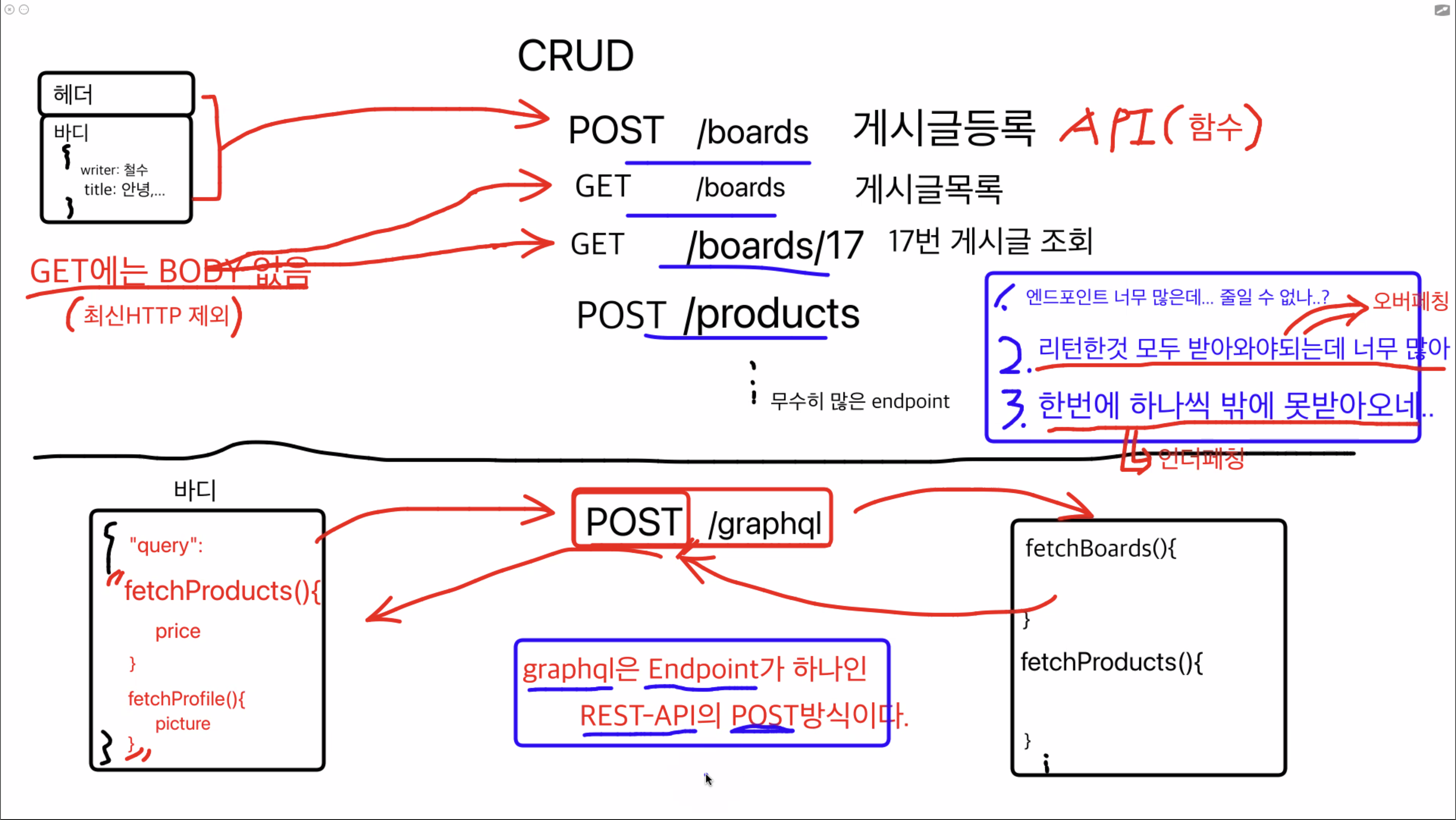
GraphQL-API는 타입에러가 나오지 않는이상 항상 200으로 나오기에 에러메세지는 각각의 바디를 참조 해야해요
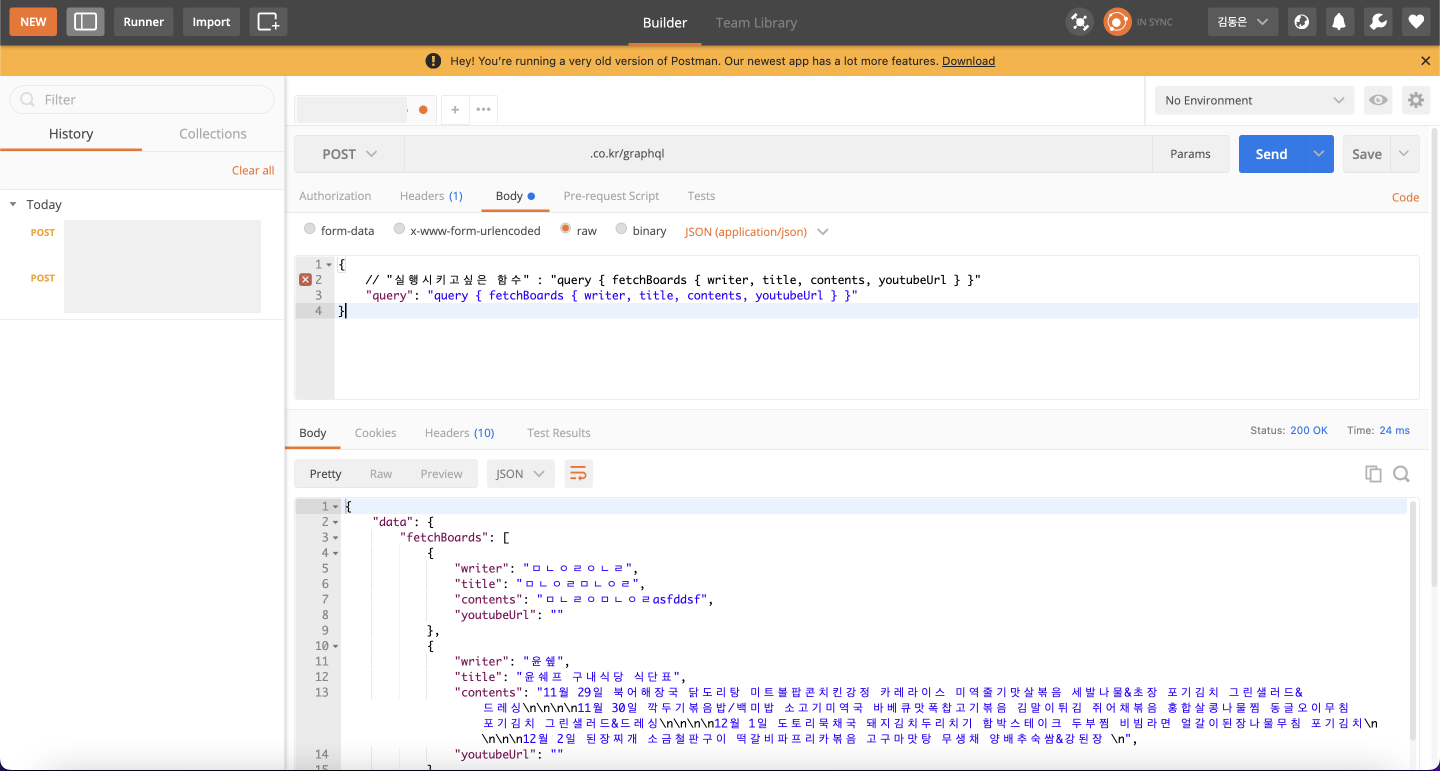
GraphQL을 REST-API로 호출해보기
GraphQL의 qurey를 postman으로 호출
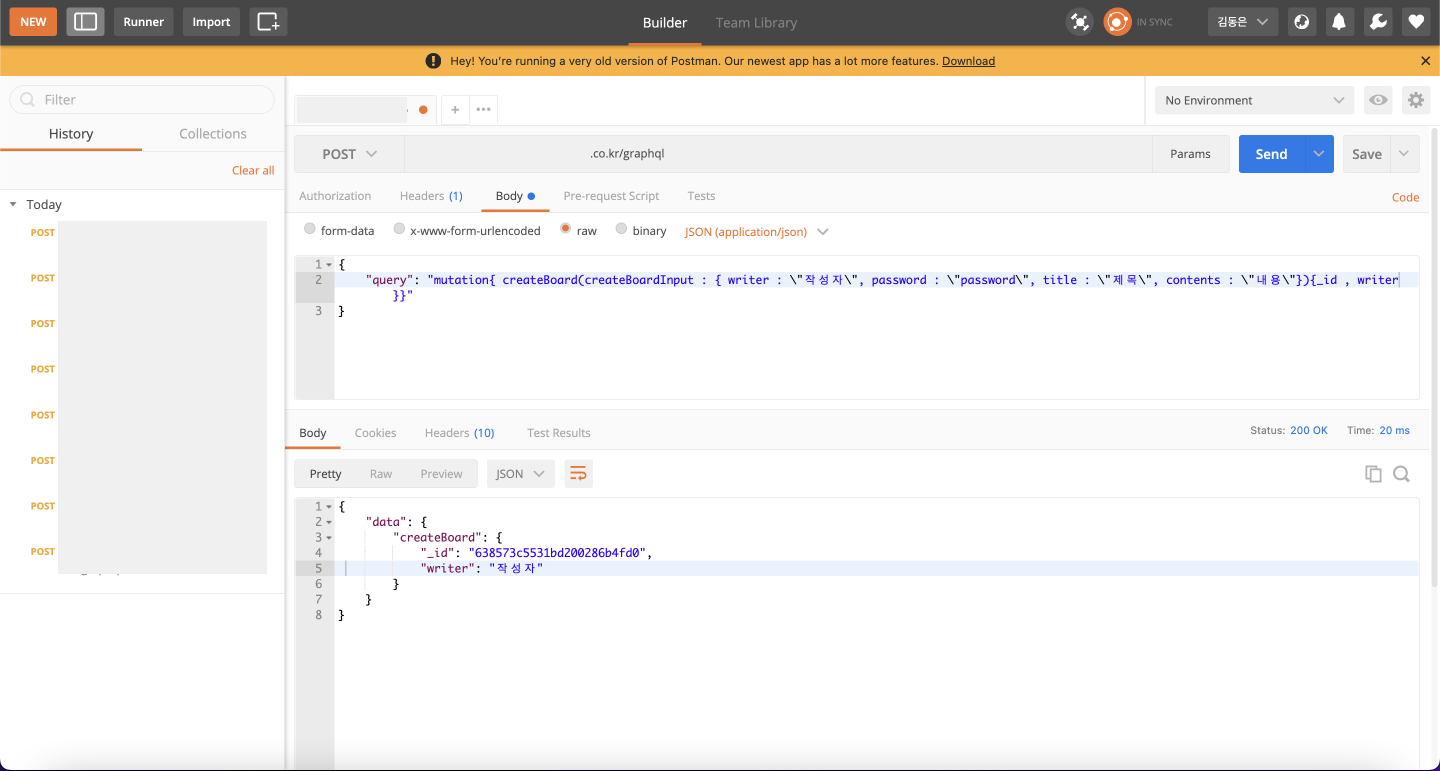
GraphQL의 mutation을 postman으로 호출

다채로운 프론트엔드 개발자