1. MobileNet v1
연구 목표:
모바일 및 임베디드 기기에서 실시간으로 동작할 수 있는 경량화된 딥러닝 모델을 개발하고자 함
연산량과 모델 크기를 줄이면서도 정확도를 최대한 유지하는 것을 목표로 함.
구조부터 살펴보자면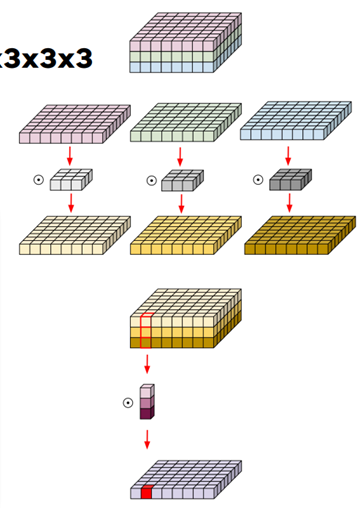
입력 3x8x8
각 채널마다 공간축으로 depthwise conv 수행
nn.Conv2d(3,3,3 groups= 3) 수행
각 채널마다 내부적으로는 Conv2d(1,1,3) 수행
weight shape=(3,1,3,3)
3개의 입력을 받았고 각 채널별로 하나의 필터(3x3)가 적용
그러고 나서 채널축으로 separable conv 수행
nn.Conv2d(3, 1, 1)
weight shape=(1,3,1,1)
방법론:
위의 그림을 어려운 말로
심층분리합성곱(Depthwise Separable Convolution)라고 하는데
일반적인 합성곱 연산을 두 가지로 분해하는 것이다.
Depthwise Convolution: 각 입력 채널에 대해 별도의 필터를 적용하여 공간적 정보를 학습.
Pointwise Convolution: 1x1 conv 을 통해 채널 간의 상호작용을 학습.
이처럼 분리된 연산을 통해 연산량과 파라미터 수를 크게 감소시킴

→ InceptionNet에서 1x1 conv의 채널축 연산으로
채널간 학습에 도움을 줄 수 있다는 것은 이미 밝혀진 사실
결과:
기존 모델 대비 파라미터 수와 연산량을 약 8~9배 감소시킴.
ImageNet 데이터셋에서 비교적 높은 정확도를 유지하며, 모바일 환경에서의 실시간 처리 가능성을 보여줌.
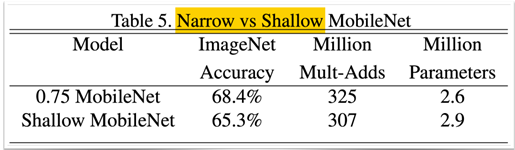
→ 레이어를 줄이는 것(depsep 삭제)과 채널 수를 줄이는 것(width multiplier)의 파라미터 수가 비슷하다면 width multiplier의 성능이 더 좋음
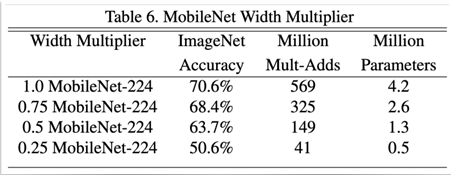
→ 정확도면에선 alpha=1.0
비용과 시간도 고려한다면 alpha=0.75
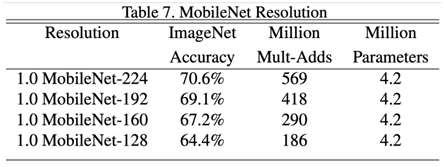
→ 정확도면에선 해상도 224
비용과 시간도 고려한다면 해상도 192
2. MobileNet v2
연구 목표:
MobileNetv2의 발상의 시작: Relu가 정보손실을 야기하는 것 같음..
- Residual block에서는 채널 수도 줄어드는데.. 정보손실이 너무 많은 거 아니야?
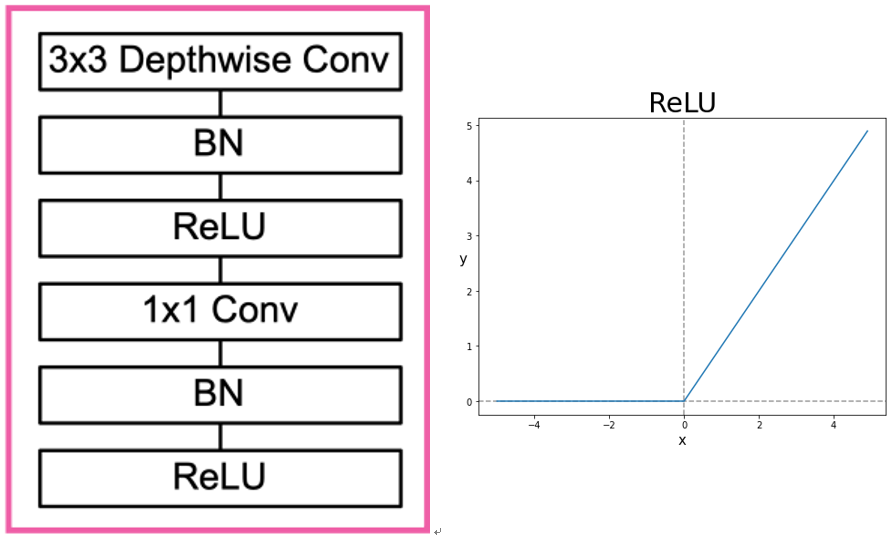
방법론:
Inverted Residuals와 Linear Bottleneck 도입:
Inverted Residuals:
기존의 잔차 블록과 반대로, 입력 차원을 (축소한후) 확장하여 잔차 연결을 적용.
연산량을 줄이면서도 표현력을 높임.
Linear Bottleneck:
activation function 대신에 Linear Bottleneck을 써서 정보손실을 줄이자.(비선형성이 떨어지더라도..)
결과:
v1 보다도 파라미터 수를 줄이고 성능도 더 좋아짐
3. MobileNet v3
연구 목표:
SENet에서 SE-block 좋아보이던데 성능 높일겸 SE-block 써볼까?
이름부터 모바일넷인데 Sigmoid는 너무 무겁네 모바일환경에서도 쓰일만한 다른 활성화 함수 찾아보자
방법론:
- 새로운 activation => Hard Sigmoid => Hard Swish
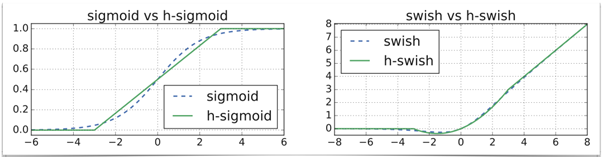
→ mobile환경에서는 부담스러운 ‘sigmoid’를 변환했음
(성능 손해 없고 메모리는 가볍게)
- SE-block 적용
SE-block을 썼다니 뭐 그건 알겠는데..
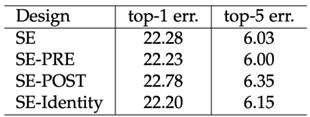
SENet에서는 SE 블록 위치에 따라 성능이 조금씩 달라지던데 여기선 inverted residual인데 위치를 어디에 두냐가 궁금했고 위치를 정한 배경적 지식을 조사해보았다.
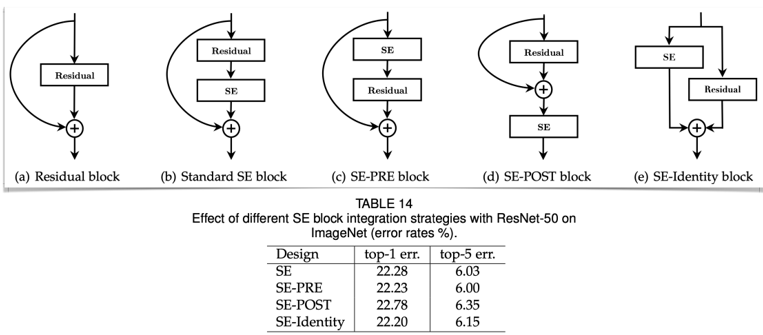
Standard SE-block 에서는 SE-block을 residual의 출력 이후에 위치시켰는데 =모든 공간적 정보를 추출한 후에 SE-Block을 적용하는 것이 채널 간 중요도를 효과적으로 학습하는 데 적합
그렇다면 MobileNetv3에서는 inverted residual을 썼는데 se-block을 어디에 위치시키는게 좋을까?
-
채널 수를 먼저 확장해서(dep conv의 역할), 모든 공간적 특징을 추출한 후에 SE-Block을 적용하는 것이 채널별 중요도를 더 효과적으로 학습시킬 수 있다. 때문에 MobileNetv3는 SE-block을 depsep 가운데에다가 위치시킴
-
residual의 채널 수 추이 ↘↗
→ SE↘↗ (채널이 축소되기 전에 SE-block 배치가 정확도는 제일 좋음)
- 근데 ↘↗SE 를 사용함..
inverted residual의 채널 수 추이 ↗↘
→ ↗SE↘ (dep conv로 채널이 확장되고 SE-block을 배치) -
1x1 conv(separable conv) 이후에는 채널들이 다 합쳐지니까 그 전에 SE-block을 위치시켜야 채널간 중요도와 상관관계를 학습하기 쉽다
-
사실 SENet에서도 SE-block의 앞 뒤 위치가 “큰” 차이를 보인건 아니었음
- 입출력 구조 변경
입력 - 제일 처음 필터 수를 32 -> 16으로 변경
H-Swish를 사용함으로 인해 굳이 32개 안써도 성능이 나오더라
파라미터 수 줄여서 비용면에서 이득을 봤으니..
출력 – 기존 [ 1x1 - GAP – FC ]에서 [ GAP 이후에 1x1 conv ]
GAP 이후 1x1conv => FC
FC-FC => MLP의 부활
결과:
이전 버전 대비 정확도와 효율성 모두 향상된 모델을 제시.
MobileNet v3-Large는 ImageNet에서 상위-1 정확도 75.2% 달성.
실제 모바일 환경에서의 추론 속도와 에너지 효율성 측면에서 우수한 성능을 입증.
