1.Abstract

Inception 제안
- 같은 컴퓨팅자원으로 네트워크의 깊이와 넓이를 증가시킬 수 있는 design
- 22개의 layer -> GoogleNet 등장
- Hebbian principle and Multi-Scale processing 적용
2.GoogleNet
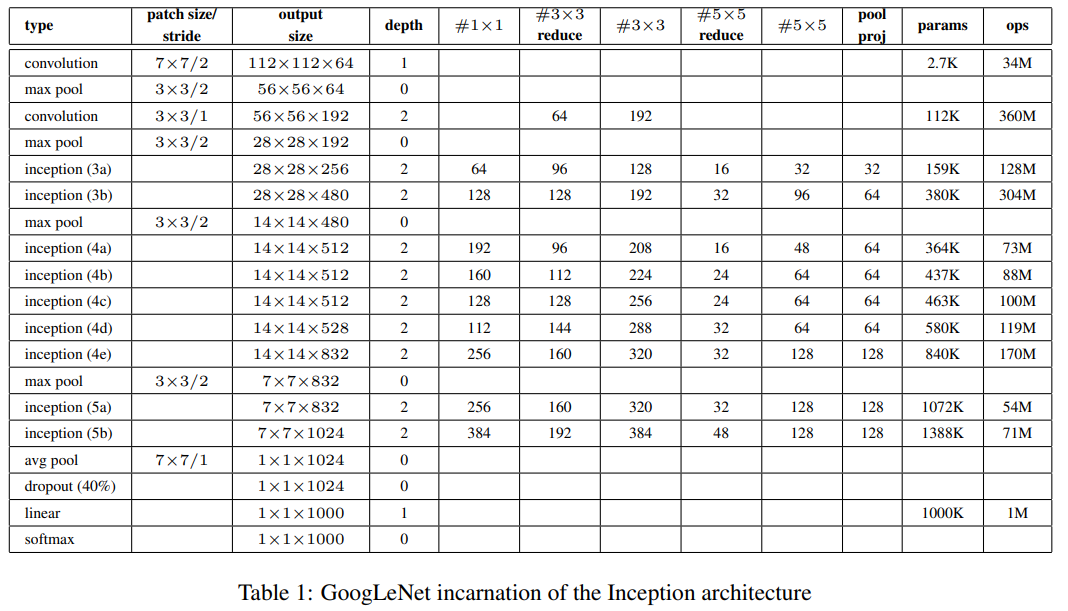
심층신경망의 성능을 개선한 방법
- depth 증가(layer의 수 증가)
- width 증가(level의 유닛 수 증가)
고려사항
- 크기가 커진다는건 곧 파라미터가 늘어나는 것을 의미하므로 데이터 수가 적을 때는 오버피팅이 일어날 수도 있음
- 네트워크가 커질수록 Computing Resource 사용량이 늘어남
-> 성능은 많이 ↑, 연산은 조금 ↑
특징
convolutional layer를 거치기 전 1x1 필터로 차원을 축소시킨 후 연산을 진행하는 구조
3. GoogleNet Architecture 구현
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, AveragePooling2D, concatenate, Input, Dense, Dropout, Flatten
from tensorflow.keras.models import Model
필요한 모듈을 import
def inception_module(x, filters):
conv1x1 = Conv2D(filters[0], (1, 1), padding='same', activation='relu')(x)
conv3x3_reduce = Conv2D(filters[1], (1, 1), padding='same', activation='relu')(x)
conv3x3 = Conv2D(filters[2], (3, 3), padding='same', activation='relu')(conv3x3_reduce)
conv5x5_reduce = Conv2D(filters[3], (1,1), padding='same', activation='relu')(x)
conv5x5 = Conv2D(filters[4], (5,5), padding = 'same', activation='relu')(conv5x5_reduce)
pool_proj = MaxPooling2D((3, 3), strides=(1, 1), padding='same')(x)
pool_proj = Conv2D(filters[5], (1, 1), padding='same', activation='relu')(pool_proj)
output = concatenate([conv1x1, conv3x3, conv5x5, pool_proj], axis=-1)
return output-
각 layer마다 fileters 인덱스를 지정해주고 필터의 크기와 패딩을 지정하고 활성화함수는 relu로 inception module을 구축해준다.
-
NxN_reduce layer는 NxN의 convolutional layer를 거치기 전 차원을 축소시키는 1x1 필터를 의미한다.
-
따라서 NxN convolutional layer의 input data는 NxN_reduce의 output이 되야한다.
def googlenet(input_shape=(224, 224, 3), num_classes=1000):
input_layer = Input(shape=input_shape)
# Initial Conv and MaxPooling layers
x = Conv2D(64, (7, 7), strides=(2, 2), padding='same', activation='relu')(input_layer)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = Conv2D(64, (1, 1), padding='same', activation='relu')(x)
x = Conv2D(192, (3, 3), padding='same', activation='relu')(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
# Inception Modules
x = inception_module(x, [64, 96, 128, 16, 32, 32]) # Inception 3a
x = inception_module(x, [128, 128, 192, 32, 96, 64]) # Inception 3b
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = inception_module(x, [192, 96, 208, 16, 48, 64]) # Inception 4a
x = inception_module(x, [160, 112, 224, 24, 64, 64]) # Inception 4b
x = inception_module(x, [128, 128, 256, 24, 64, 64]) # Inception 4c
x = inception_module(x, [112, 144, 288, 32, 64, 64]) # Inception 4d
x = inception_module(x, [256, 160, 320, 32, 128, 128]) # Inception 4e
x = MaxPooling2D((3, 3), strides=(2, 2), padding='same')(x)
x = inception_module(x, [256, 160, 320, 32, 128, 128]) # Inception 5a
x = inception_module(x, [384, 192, 384, 48, 128, 128]) # Inception 5b
# Final layers
x = AveragePooling2D((7, 7), strides=(1, 1))(x)
x = Dropout(0.4)(x)
x = Flatten()(x)
x = Dense(num_classes, activation='softmax')(x)
model = Model(input_layer, x, name='googlenet')
return model
# Create the model
model = googlenet(input_shape=(224, 224, 3), num_classes=1000)
model.summary()
- 차례로 Architecture 구성과 동일한값을 inception module의 filters index에 주의하여
입력한다.
max_pooling2d_10 (MaxPooli (None, 7, 7, 832) 0 ['concatenate_6[0][0]']
ng2D)
conv2d_46 (Conv2D) (None, 7, 7, 160) 133280 ['max_pooling2d_10[0][0]']
conv2d_48 (Conv2D) (None, 7, 7, 32) 26656 ['max_pooling2d_10[0][0]']
max_pooling2d_11 (MaxPooli (None, 7, 7, 832) 0 ['max_pooling2d_10[0][0]']
ng2D)
conv2d_45 (Conv2D) (None, 7, 7, 256) 213248 ['max_pooling2d_10[0][0]']
conv2d_47 (Conv2D) (None, 7, 7, 320) 461120 ['conv2d_46[0][0]']
conv2d_49 (Conv2D) (None, 7, 7, 128) 102528 ['conv2d_48[0][0]']
conv2d_50 (Conv2D) (None, 7, 7, 128) 106624 ['max_pooling2d_11[0][0]']
concatenate_7 (Concatenate (None, 7, 7, 832) 0 ['conv2d_45[0][0]',
) 'conv2d_47[0][0]',
'conv2d_49[0][0]',
'conv2d_50[0][0]']
conv2d_52 (Conv2D) (None, 7, 7, 192) 159936 ['concatenate_7[0][0]']
conv2d_54 (Conv2D) (None, 7, 7, 48) 39984 ['concatenate_7[0][0]']
max_pooling2d_12 (MaxPooli (None, 7, 7, 832) 0 ['concatenate_7[0][0]']
ng2D)
conv2d_51 (Conv2D) (None, 7, 7, 384) 319872 ['concatenate_7[0][0]']
conv2d_53 (Conv2D) (None, 7, 7, 384) 663936 ['conv2d_52[0][0]']
conv2d_55 (Conv2D) (None, 7, 7, 128) 153728 ['conv2d_54[0][0]']
conv2d_56 (Conv2D) (None, 7, 7, 128) 106624 ['max_pooling2d_12[0][0]']
concatenate_8 (Concatenate (None, 7, 7, 1024) 0 ['conv2d_51[0][0]',
) 'conv2d_53[0][0]',
'conv2d_55[0][0]',
'conv2d_56[0][0]']
average_pooling2d (Average (None, 1, 1, 1024) 0 ['concatenate_8[0][0]']
Pooling2D)
dropout (Dropout) (None, 1, 1, 1024) 0 ['average_pooling2d[0][0]']
flatten (Flatten) (None, 1024) 0 ['dropout[0][0]']
dense (Dense) (None, 1000) 1025000 ['flatten[0][0]']
==================================================================================================
Total params: 6998552 (26.70 MB)
Trainable params: 6998552 (26.70 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
4. Conclusion


결론 및 특징
Inception 구조는 Sparse 구조를 Dense 구조로 근사화하여 성능을 개선하였다. 이는 기존에 CNN 성능을 높이기 위한 방법과는 다른 새로운 방법이었으며, 성능은 대폭 상승하지만 연산량은 약간만 증가한다는 장점이 있다.
Inception 구조는 CNN 성능을 높이기 위해 새로운 방법을 제안하였음.
1. Sparse 구조를 Dense 구조로 변환
2. 성능은 대폭 상승하고 연산량은 아주 조금 증가함
참고문헌
1. https://phil-baek.tistory.com/entry/3-GoogLeNet-Going-deeper-with-convolutions-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
2. https://velog.io/@hyesukim1/GoogLeNet-Going-deeper-with-convolutions

Ai 공부중