Hadoop Eco System 이란?
하둡의 코어 프로젝트(Framework)는 HDFS, MapReduce이지만 그 외에도 다양한 서브 프로젝트들이 많다. 하둡 에코 시스템은 그 Framework를 이루고 있는 다양한 서브 프로젝트들의 모임입니다.
그림을 보면 이해가 훨씬 쉬울 것이다.
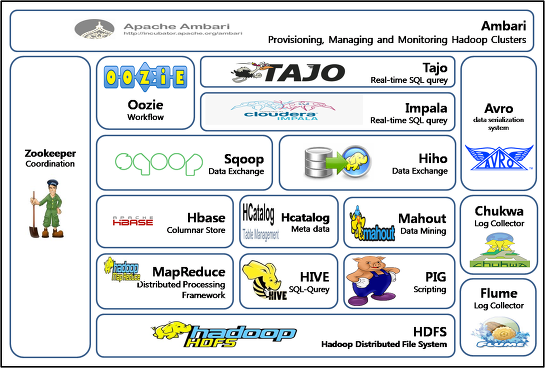
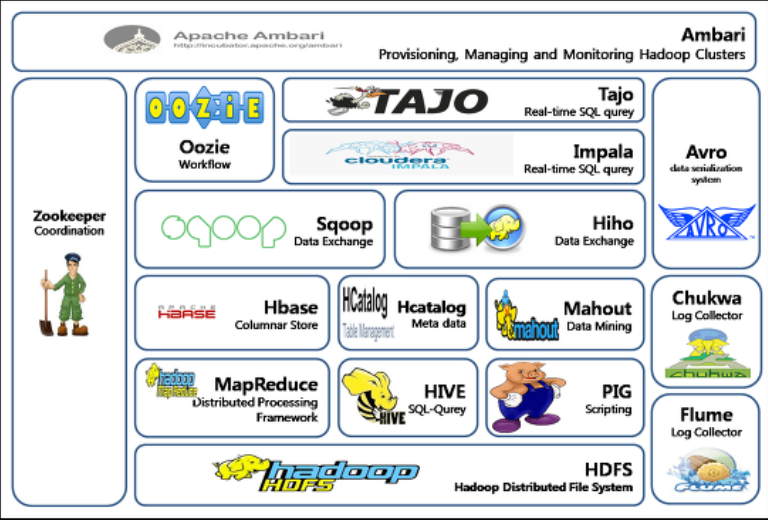 [하둡에코시스템(Hadoop Eco System) Ver 1.0]
[하둡에코시스템(Hadoop Eco System) Ver 1.0]
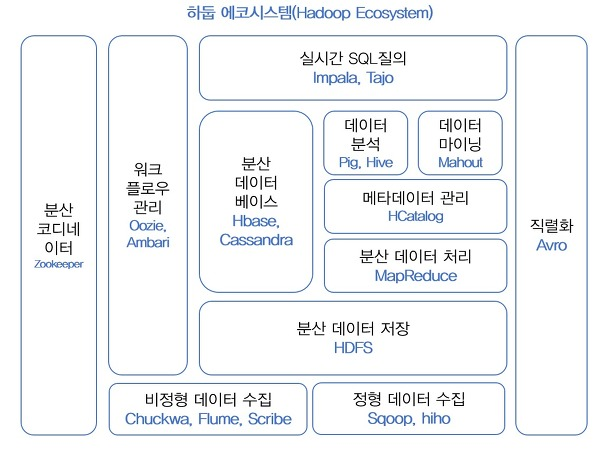 [하둡에코시스템]
[하둡에코시스템]
(출처 : 시작하세요! 하둡 프로그래밍(위키북스))
하둡의 서브 프로젝트에 대해서 간단하게 정리해보겠습니다.
Hadoop Framework 종류
Zookeeper (분산 코디네이터)
- 분산 환경에서 서버들간의 상호 조정이 필요한 다양한 서비스 제공
- 하나의 서버에서 처리하 결과를 다른 서버들과도 동기화 -> 데이터 안정성 보장!
- 운영(active) 서버에서 문제가 발생하여 서비스 제공할 수 없는 경우 -> 다른 대기중인 서버를 운영 서버로 바꿔 서비스 중지없이 제공되게 해줌
- 분산 동기화 제공 -> 하나의 서버에만 서비스가 집중되지 않도록 서비스를 알맞게 분산하여 동시에 처리하게 해줌
- 중앙 집중식 서비스로 알맞은 분산처리 및 분산 환경을 구성하는 서버 설정을 통합적으로 관리
Ooozie (워크플로우 및 코디네이터 시스템)
- 하둡의 작업을 관리하는 워크플로우 및 코디네이터 시스템
- Java servlet 컨테이너에서 실행되는 자바 웹 어플리케이션 서버로, MapReduce 작업이나 Pig 작업 같은 특화된 액션들로 구성된 워크플로우를 제어
Avro (데이터 직렬화)
- RPC (Remote Procedure Call)과 데이터 직렬화를 지원하는 Framework
- JSON을 이용한 데이터 형식과 프로토콜을 정의
- 작고 빠른 Binary 포맷으로 데이터를 직렬화함
분산 리소스 관리
YARN
- 작업 스케줄링, 클러스터 리소스 관리를 위한 Framework
- MapReduce, Hive, Impala, Spark 등 다양한 애플리케이션들을 YARN에서 작업 실행
Mesos (Cloud환경에 대한 리소스 관리)
- Linux 커널과 동일한 원칙을 사용
- 컴퓨터에 API(Hadoop, Spark, Kafka, Elasticsearch)를 제공
- Facebook, Twitter, Ebay 등 다양한 기업들이 Mesos 클러스터 자원을 관리하고 있음
HCatalog
- 하둡으로 생성한 데이터를 위한 테이블 및 스토리지 관리 서비스
- 가장 큰 장점으로는 하둡 에코시스템들간의 상호 운용성의 향상 -> (ex) Hive에서 생성한 테이블이나 데이터 모델을 Pig 나 MapReduce에서 손쉽게 이용할 수 있다.
데이터 저장
HBase (분산 DB)
- HDFS의 컬럼(열) 기반 데이터베이스
- Google Bigtable 논문을 기반으로 개발된 비관계형 DB
- 실시간 랜덤 조회 및 업데이트 가능
- 각각의 프로세스들은 개인의 데이터를 비동기적(동시성 X)으로 업데이트 할 수 있음. 단 MapReduce는 일괄처리 방식으로 수행!
- Hadoop 및 HDFS위에 Bigtable과 같은 기능을 제공
HDFS (분산 파일 데이터 저장)
- 하둡에서의 저장소 역할
- 하둡 네트워크에 연결된 기기에 데이터를 저장하는 분산형 파일 시스템
- 애플리케이션 데이터에 대한 높은 처리량의 액세서를 제공하는 분산 파일 시스템
Kudu (컬럼 기반 스토리지)
- 속성 기반 스토리지로 하둡 에코 시스템에 새로 추가됨
- 빠르게 변화하는 데이터에 대한 빠른 분석을 위한 설계됨
- Cloudera에서 시작된 프로젝트 -> 15년 말 Apache 인큐베이션 프로젝트로 선정
Tajo
- 고려대학교 정보통신대학 컴퓨터학과 DB연구실 박사 과정학생들이 주도해서 개발한 하둡 기반의 DW 시스템
- 데이터 저장소는 HDFS를 사용하되, 표준 DB언어인 SQL을 통해 실시간으로 데이터 조회 가능
- Hive보다 2~3배 빠르며, 클라우데라의 Impala와는 비슷한 속도를 보여줌 -> Impala는 클라우데라의 하둡을 써야하는 제약이 있음. BUT Tajo는 특정 업체 솔루션에 종속되지 않는 장점이 있음
데이터 수집
Chukwa
- 분산 환경에서 생성되는 데이터를 안정적으로 HDFS에 저장하는 Platform
- 분산된 각 서버에서 agent를 실행 -> collector가 agent로부터 데이터를 받아 HDFS에 저장 -> collector는 100개의 agent당 하나씩 구동되며, 데이터 중복 제거 등의 작업은 MapReduce로 처리
- 대규모 분산 시스템을 Monitoring하기 위한 시스템
- HDFS 및 MapReduce에 구축되어 수집된 데이터를 최대한 활용하기 위한 Monitoring 및 유연한 툴킷을 포함
Flume
- Chukwa 처럼 분산된 서버에 agent가 설치 -> agent로부터 데이터를 전달받는 collector로 구성
- vs Chukwa : 전체 데이터의 흐름을 관리하는 Master Server 가 있어서 데이터를 어디서 수집하고, 어떤 방식으로 전송하고, 어디에 저장할지를 동적으로 변경가능!
- 많은 양의 데이터를 수집, 집계 및 이동하기 위한 분산형 서비스
Scribe
- 페이스북에서 개발한 데이터 수집 Platform
- vs Chukwa : 데이터를 중앙서버 로 전송하는 방식, 최종 데이터는 HDFS외에 다양한 저장소를 활용 가능 (HDFS에 저장하기 위해서는 JNI (Java Native Interface)를 이용해야함)
- 설치와 구성이 쉽고, 다양한 프로그래밍 언어를 지원함
Kafka
- 분산 스트리밍 플랫폼으로, 데이터 파이프 라인을 구축할 때 주로 사용되는 오픈소스 솔루션
- 데이터 Stream(흐름)을 실시간으로 관리하기 위한 분산 시스템
- 대용량 실시간 로그처리에 특화되어 있는 솔루션 -> 데이터를 유실없이 안전하게 전달하는 것이 주목적!
- 고장 방지(Fault-Tolerant)와 안정적인 아키텍처와 빠른 퍼포먼스로 데이터를 처리할 수 있음
데이터 전송
Sqoop
- 대용량 데이터 전송 솔루션
- HDFS, RDBMS, DW, NoSQL 등 다양한 저장소에 대용량 데이터를 신속하게 전송할 수 있는 방법을 제공
- Oracle, MS-SQL, DB2 등과 같은 상용 RDBMS와 MySQL, PostgresSQL과 같은 오픈소스 RDBMS등을 지원
Hiho
- Sqoop과 같은 대용량 데이터 전송 솔루션
- 현재 github에서 공개되어 있음
- 하둡에서 데이터를 가져오기 위한 SQL을 지정할 수 있고, JDBC 인터페이스를 지원
데이터 처리
Pig
- 하둡에 저장된 데이터를 MapReduce Program을 만들지 않고 SQL과 유사한 스크립트를 이용하여 데이터를 처리
- 복잡한 MapReduce 프로그래밍을 대체할 Pig Latin이라는 자체 언어를 제공
- MapReduce API를 매우 단순화한 형태로 설계됨 (SQL과 유사한 형태임)
Mahout
- 하둡 기반 데이터 마이닝 알고리즘을 구현한 오픈소스
- 분석 머신러닝에 필요한 알고리즘을 구축하기 위한 오픈소스 Framework
- 현재 {분류, 군집, 추천 및 협업 필터링, 패턴 마이닝, 회귀 분석, 차원 축소, 진화 알고리즘 등} 주요한 알고리즘을 지원
- Mahout 그대로 사용할 수 있지만, 자신의 비즈니스 환경에 맞게 최적화하여 사용하는 경우가 대부분
Spark
- 대규모 데이터 처리를 위한 빠른 속도로 실행시켜 주는 엔진
- 병렬 애플리케이션을 쉽게 만들 수 있는 80개 이상의 고급 연산자를 제공
- Python, R 등에서 대화형(인터프리터)으로 사용 가능
Impala
- Cloudera에서 개발한 하둡 기반의 실시간 SQL 질의 시스템
- 하둡 기반 분산 엔진으로, MapReduce를 사용하지 않고 C++로 개발한 인메모리 엔진(자체 개발한 엔진)을 사용하여 빠른 성능을 보여줌 (성능 높여줌)
- Impala는 데이터 조회를 위한 인터페이스로 HiveQL을 사용하며, 수초 내에 SQL 질의 결과를 확인할 수 있으며, HBase와도 연동이 가능
Hive
- 하둡 기반의 데이터 웨어하우징용 솔루션
- Facebook에서 개발
- 하둡 기반 데이터 솔루션으로 Java를 몰라도 데이터 분석을 할 수 있게 도와줌
- SQL과 유사한 HiveQL이라는 언어를 이용하여 데이터 분석을 쉽게 할 수 있도록 도와줌 (.hql 파일) -> HiveQL은 내부적으로 MapReduce Job으로 변환되어 실행된다.
MapReduce
- 대용량 데이터를 분산 처리하기 위한 프로그래밍 모델 (소프트웨어 Framework)
- 정렬된 데이터를 분산 처리(Map)하고 이를 다시 합치는(Reduce) 과정을 수행
- MapReduce Framework를 이용하면 대규모 분산 컴퓨팅 환경에서, 대량의 데이터를 병렬로 분석 가능
- 하둡에서 대용량 처리를 위한 기술들 중 가장 인기있음

Computer Science!!