Pandas란?
계량 경제학 용어인 panel data와 analysis의 합성어이다. 구조화된 데이터를 빠르고 쉬우면서 다양한 형식으로 가공할 수 있는 풍부한 자료구조와 함수를 제공한다. (기본구조는 Numpy 입니다.)
쉽게 사용 가능한 자료구조이며, 자료들 간 빠른 연산 속도 및 데이터 분석이 가능하다.
DB테이블, 엑셀 파일과 같은 테이블 형태의 데이터를 다룬다. 데이터에 레이블을 붙여 가독성을 높임.
Pandas 배워보기
Pandas에는 Series와 DataFreame이라는 두 종류의 자료구조가 있다. 지금부터 예제를 진행하겠습니다.
- .Series()
- Series는 1차원 배열과 같은 자료구조이다. 파이썬에는 리스트와 튜플이라는 1차원 배열과 같은 자료구조가 존재하는데 굳이 Series를 만든 이유가 무엇일까?
-> 리스트, 튜플과 달리 Series 객체는 값뿐만 아니라 각 값에 연결된 index값도 동시에 저장한다. (딕셔너리와 비슷하다고 생각하면 된다(?))
import pandas as pd
D = [3, 5, 10, 2] # 리스트(1차원 배열)
data = pd.Series(D) # Series 객체 생성
print(data, "\n")
print(data[2],"\n") # 3번째 index의 값 가져오기
print(data.get(2)) # 위와 동일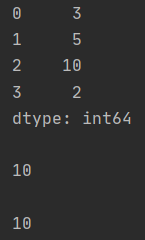
- 인덱스에 naming을 할 수 있다.
D = [3, 5, 10, 2] # 리스트(1차원 배열)
data = pd.Series(D) # Series 객체 생성
print(data, "\n")
data = pd.Series(D, index=["a", "b", "c", "d"])
print(data)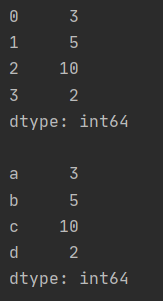
- .DataFrame()
- Series 객체들이 모인 2차원 데이터 (리스트로 DataFrame 생성이 가능하다.)
- List로 부터 생성
a1 = [1,2,3,4]
b1 = [5,6,7,8]
c1 = [9,10,11,12]
scoreType = ["국어","영어","수학","과학"]
students = ["철수", "지영", "길동"]
# 행과 열의 naming을 할 수 있다.
df = pd.DataFrame((a1, b1, c1), columns=scoreType, index=students)
print(df)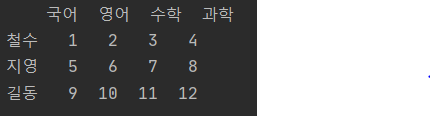
- Series로 부터 생성
a1 = [1, 2, 3, 4]
b1 = [5, 6, 7, 8]
c1 = [9, 10, 11, 12]
scoreType = ["국어", "영어", "수학", "과학"]
aS = pd.Series(a1, index=scoreType)
print(aS, "\n") # DataFrame의 하나의 행이라고 생각하면 된다.
# Series 의 index는 DataFrame의 column이다.
bS = pd.Series(b1, index=scoreType)
cS = pd.Series(c1, index=scoreType)
students = ["철수", "지영", "길동"]
df = pd.DataFrame((aS, bS, cS), index=students)
print(df)
- DataFrame에 하나의 instance를 삽입해보자.
a1 = [1, 2, 3, 4]
b1 = [5, 6, 7, 8]
c1 = [9, 10, 11, 12]
scoreType = ["국어", "영어", "수학", "과학"]
aS = pd.Series(a1, index=scoreType)
bS = pd.Series(b1, index=scoreType)
cS = pd.Series(c1, index=scoreType)
# "국어"의 열의 값이 없는 Series(리스트) 생성
dL = [4, 5, 6]
dS = pd.Series(dL, index=["영어", "수학", "과학"])
df1 = pd.DataFrame((aS, bS, cS, dS), index=["철수", "지영", "길동", "기영"])
print(df1)
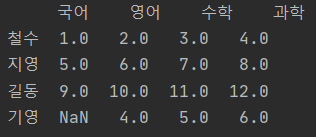
- 기영이의 "국어" 점수가 NaN(Not a Number) 형태로 출력된다.
행, 열 선택
- 위의 만들어진 DataFrame df1을 이용하여 행과 열을 선택해보자.
# 열 선택하기
print(df1["국어"], "\n")
print(df1[["국어", "과학"]], "\n")
# 행 선택하기
print(df1[0:2], "\n")
print(df1[0:3:2], "\n")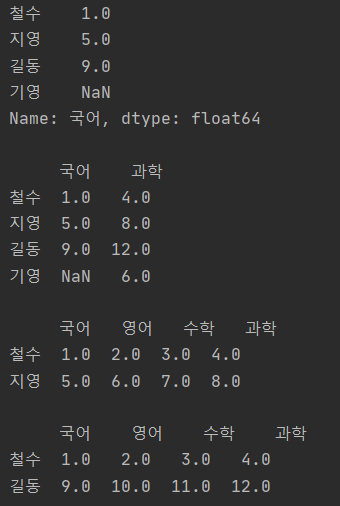
행/열 선택
- 행/열을 동시에 만족하는 데이터를 선택해보자.
# (행, 열) 선택하기
print(df1.iloc[::, 0:1:], "\n") # iloc : 숫자로 행/열 선택
print(df1.loc["철수":"길동", "국어"::2]) # loc : column명과 index명으로 행/열 선택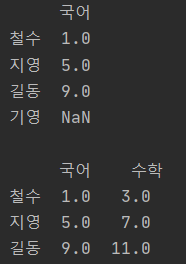
데이터 필터링
- 주어진 조건에 만족하는 데이터를 출력해보자.
print(df1[df1["국어"] > 5], "\n") # 국어가 5점 초과인 모든 행을 출력
데이터 정렬
print(df1.sort_values("과학"), "\n") # 과학점수를 기준으로 오름차순 정렬
print(df1.sort_values("과학", ascending=False)) # 위와 동일하나 내림차순 정렬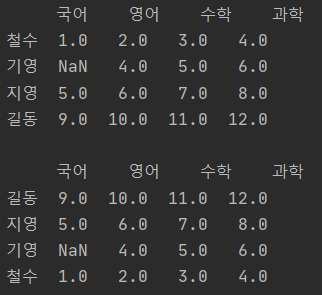

3개의 댓글

Pandas는 데이터 조작을 위한 강력한 Python 라이브러리입니다. Series(1D)와 DataFrame(2D)와 같은 구조화된 데이터를 다루기 쉽게 만들어 주며, 데이터베이스나 엑셀 파일처럼 다양한 테이블 형태의 데이터를 빠르게 처리하고 분석할 수 있게 해줍니다.
DS4Windows는 PS4 컨트롤러를 Windows PC에서 사용할 수 있게 해주는 소프트웨어로, 버튼 및 성능 설정을 사용자 맞춤으로 조정할 수 있습니다. Pandas가 데이터 분석을 효율적으로 돕는 것처럼, DS4Windows는 게임 경험을 향상시키고 컨트롤러 설정을 간편하게 만들어줍니다. https://ds4-window.com/

DS4Windows is a powerful and user-friendly tool designed to let you use a PlayStation DualShock 4 or DualSense controller on a Windows PC. It works by emulating an Xbox 360 controller, enabling compatibility with a wide range of PC games that don’t natively support Sony’s controllers.
https://ds4-windows.us/
Pandas는 표 형식 데이터를 조작하고 분석하는 데 매우 강력하고 유용한 rice purity test Python 라이브러리입니다. Series 및 DataFrame을 포함한 Pandas 기본 사항과 이를 생성하고 조작하는 방법에 대한 명확한 개요를 제공해 주셔서 감사합니다. 실제 사례가 포함된 그림은 독자가 이러한 개념을 쉽게 이해할 수 있도록 도와줍니다.