다이나믹 프로그래밍(Dynamic Programming)이란?

현실에서 우리가 컴퓨터를 이용하여 문제를 해결하려 할 때 컴퓨터로도 해결하기 어려운 문제들이 있을 것이다. 보통 최적의 해를 구하는데 시간이 매우 오래걸리거나 메모리 공간이 많이 필요한 문제 등이 해결하기 어려운 문제들이다. 컴퓨터는 연산 속도에 한계가 있고, 메모리 공간을 사용할 수 있는 데이터의 개수도 한정적이라는 점이 많은 제약을 발생시킨다. 그래서 우리는 연산 속도와 메모리 공간을 최대한으로 활용할 수 있는 효율적인 알고리즘을 작성해야하는데 이러한 문제를 해결할 수 있는 대표적인 방법이 다이나믹 프로그래밍 (Dynamic Programming)이다.
글에서는 다이나믹 프로그래밍을 줄여서 DP라고 표현하겠다.
-
DP란 '동적 계획법'이라고도 불리는 알고리즘
-
큰 문제를 작은 문제로 나누어 푸는 문제를 일컫는 말 / 한 번 계산한 문제는 다시 계산하지 않도록 하는 알고리즘
-
DP는 다음의 조건을 만족할 때 사용할 수 있음
- 최적 부분 구조 (Optimal Substructure)
큰 문제를 작은 문제로 나눌 수 있고, 작은 문제의 답을 모아 큰 문제를 해결할 수 있는 경우를 의미
- 중복되는 부분 문제 (Overlapping Subproblem)
동일한 작은 문제를 반복적으로 해결해야 하는 경우
- 최적 부분 구조 (Optimal Substructure)
※ 일반적인 프로그래밍 분야에서 동적(Dynamic)의 의미는?
-
자료구조에서 동적 할당(Dynamic Allocation)은 '프로그램이 실행되는 도중에 실행에 필요한 메모리를 할당하는 기법'을 의미한다.
-
반면에 DP에서 Dynamic은 별다른 의미가 없다. 알고리즘을 만든 사람도 멋있다는 이유로 Dynamic이란 단어를 프로그래밍에 결합했다.
피보나치 수열
피보나치 수열은 DP로 해결할 수 있는 문제들 중 하나이다.
- 피보나치 수열이란 이전 두 항의 합을 현재의 항으로 설정하는 특징을 가진 수열이다.
(Ex) 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, ...
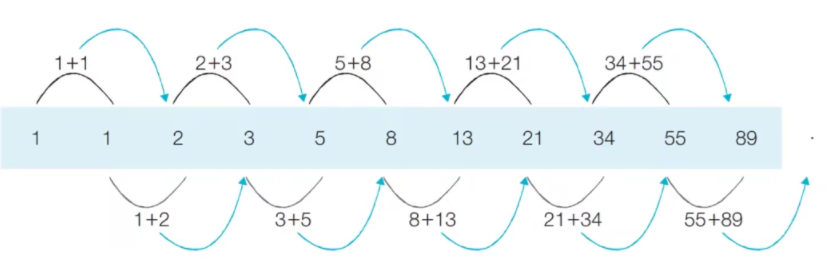
피보나치 수열을 점화식으로 표현해보자.
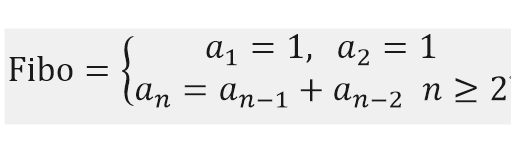
수학적 점화식을 프로그래밍으로 표현하려면 단순 재귀함수를 사용하면 간단하다. Python 코드로 작성해보자.
def fibo(x):
if x == 1 or x == 2:
return 1
return fibo(x - 1) + fibo(x - 2)
print(fibo(4))
>> 3
재귀함수의 호출을 그림으로 표현하면 아래와 같다.
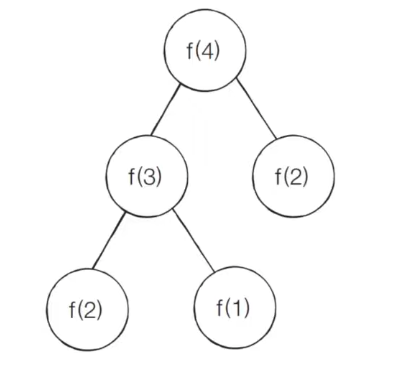
피보나치 수열을 단순 재귀함수로 구현했을 때의 문제점
위와 같이 코드를 작성하게 되면 심각한 문제가 생길 수 있다. f(n)함수에서 n이 커지면 커질수록 수행 시간이 기하급수적으로 늘어나기 때문이다. 아래 그림을 보자.
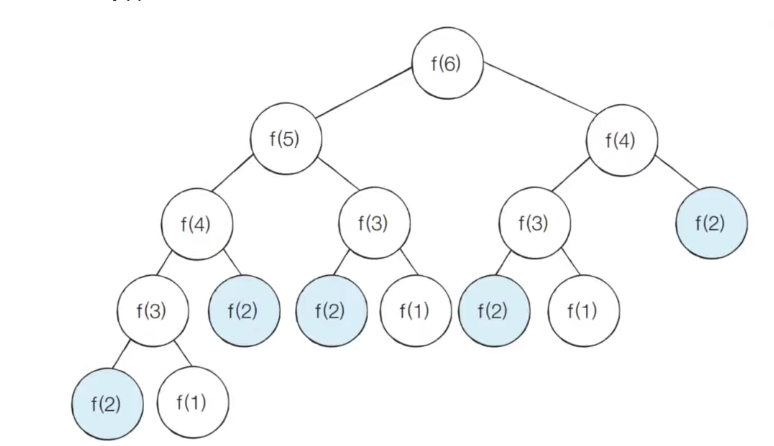
f(6)을 계산할 때에 그림과 같이 f(2)가 여러 번 호출되는 것을 확인할 수 있다. (중복되는 부분 문제) 즉, 같은 연산을 여러 번 수행하므로 시간 복잡도가 엄청 커지게 된다.
피보나치 수열의 시간 복잡도는 O(2 ** N)이다. 예를 들어 f(30)을 계산하기 위해 약 10억번의 연산을 수행해야 한다. 우리는 DP를 사용하면 이러한 문제를 효율적으로 해결할 수 있다.
DP로 피보나치 수열 계산하기
DP는 항상 사용할 수 없기 때문에 DP의 사용 조건을 만족하는지 확인해보자.
-
큰 문제를 작은 문제로 나눌 수 있다.
-
작은 문제에서 구한 정답은 그것을 포함하는 큰 문제에서도 동일하다.
피보나치 수열은 위 2가지 조건을 만족하므로 DP를 사용할 수 있다! 이 문제를 메모이제이션 (Memoization) 기법을 사용해서 해결해보자.
※ 메모이제이션 (Memoization) 이란?
DP를 구현하는 방법 중 한 종류이다.
한 번 구한 결과를 메모리 공간에 메모해두고 --> 같은 식을 호출하면 메모한 결과를 그대로 가져오는 기법이다. (값을 기록해 놓는다는 점에서 캐싱(Caching)이라고도 한다.)
# 메모이제이션하기 위한 리스트 초기화
memoization = [0] * 100
# 피보나치 함수를 재귀함수로 구현 (Top-down DP)
def fibo(x):
if x == 1 or x == 2:
return 1
# 이미 계산한 적 있으면 그대로 반환
if memoization[x] != 0:
return memoization[x]
# 계산한 적 없으면 점화식에 따라 피보나치 결과 반환
memoization[x] = fibo(x - 1) + fibo(x - 2)
return memoization[x]
print(fibo(6))
메모이제이션을 사용하여 f(6)을 구하는 과정은 아래의 그림과 같다.
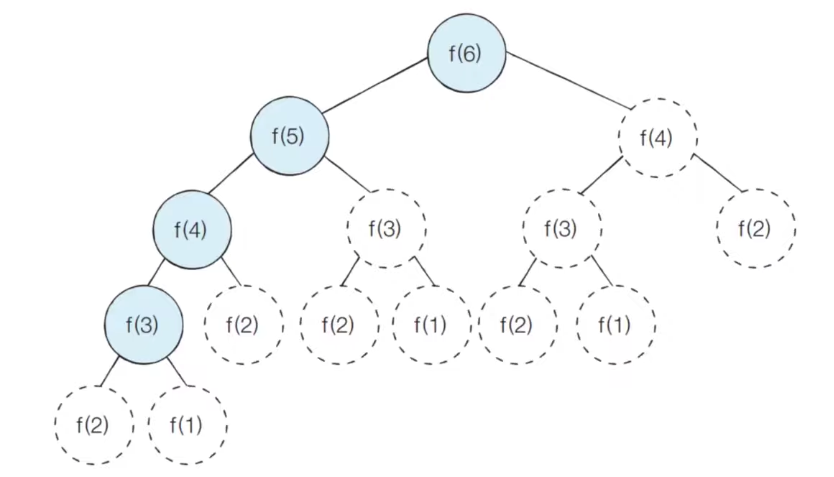
메모이제이션을 사용하게 되면 그림의 색칠된 노드만 방문하게 된다.
실제 코드에서 호출되는 함수만 보게되면 아래의 그림과 같이 방문한다.
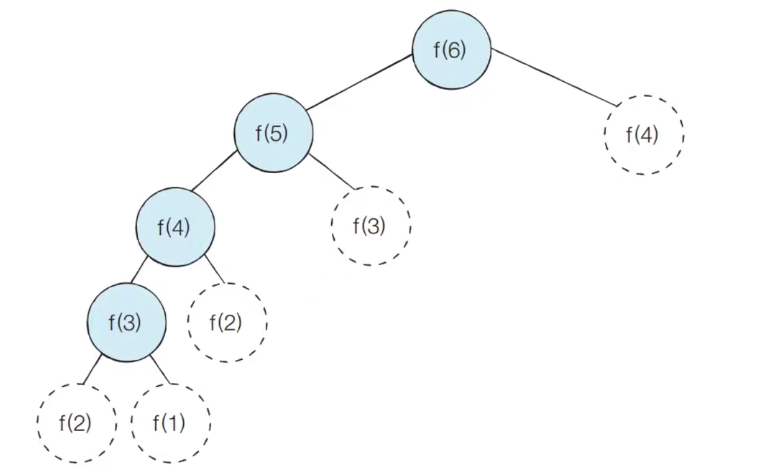
f(6) -> f(5) -> f(4) -> f(3) -> f(2) -> f(1) -> f(2) -> f(3) -> f(4)
DP를 적용했을 때의 피보나치 수열 알고리즘의 시간 복잡도는 O(N)이다. 왜냐하면 f(1)을 구한 다음 그 값이 f(2)를 구하는 데 사용되고, f(2)의 값이 f(3)을 푸는 데 사용되는 방식으로 이어지기 때문이다. 또한, 메모이제이션 때문에 한 번 구한 결과는 다시 구해지지 않는다.
탑다운(Top-Down) vs 바텀업(Bottom-Up)
갑자기 탑다운(Top-Down), 바텀업(Bottom-Up)이란 단어가 나와서 당황했을 수도 있다.
DP 문제를 푸는 방법은 탑다운(Top-Down)과 바텀업(Bottom-Up)이 있다. 두 방법 모두 큰 문제를 여러 개의 부분 문제들로 나누어 풀지만, 차이점이 존재한다.
DP의 전형적인 형태는 바텀업(Bottom-Up) 방식이다. 결과 저장용 리스트는 'DP 테이블'이라고 부른다.
탑다운(Top-Down)
-
큰 문제를 해결하기 위해 작은 문제를 호출하는 방식
-
탑다운(메모이제이션) 방식은 '하향식'이라고도 한다.
-
점화식을 이해하기 쉬운 장점이 있다.
※ DP와 메모이제이션 개념을 혼용해서 사용하는 경우도 있는데, 엄밀히 말하면 메모이제이션은 이전에 계산된 결과를 일시적으로 기록해 놓은 넓은 개념을 의미하므로 DP와는 별도의 개념이다. --> 한 번 계산된 결과를 담아 놓기만 하고 DP를 위해 활용하지 않을수도 있다.
바텀업(Bottom-Up)
-
가장 작은 문제들부터 답을 구해가며 전체 문제의 답을 찾는 방식
-
바텀업 방식은 '상향식'이라고도 한다.
-
재귀 호출을 하지 않기 때문에 시간과 메모리 사용량을 줄일 수 있는 장점이 있다.
위에 설명했던 피보나치 수열을 바텀업 방식으로 구현하면 아래와 같다. (탑다운 방식으로는 위에 이미 구현했음!) 동일한 원리를 적용하되 단순히 반복문을 이용하여 문제를 해결한 것으로 이해하면 된다!
# 앞서 계산된 결과를 저장하기 위한 DP 테이블 초기화
dp = [0] * 100
dp[1] = 1
dp[2] = 1
n = 99
# 피보나치 수열 반복문으로 구현(Bottom-Up DP)
for i in range(3, n + 1):
dp[i] = dp[i - 1] + dp[i - 2]
print(dp[n])
vs 분할 정복 (Divide and Conquer)
-
DP와 분할 정복은 모두 '최적 부분 구조'를 가질 때 사용할 수 있다. (공통점) --> 큰 문제를 작은 문제로 나눌 수 있고, 작은 문제의 답을 모아 큰 문제를 해결할 수 있는 경우
-
DP와 분할 정복의 차이점은 '부분 문제의 중복'이다.
- DP 문제에서는 각 부분 문제들이 서로 영향을 미치며 부분 문제가 중복된다.
- 반면에 분할 정복 문제에서는 동일한 부분 문제가 반복적으로 계산되지 않는다.
분할 정복의 대표적인 예시인 퀵 정렬을 보자. 한 번 기준 원소(Pivot)가 자리를 변경해서 자리를 잡으면 그 기준 원소의 위치는 바뀌지 않는다. 분할 이후 해당 피벗을 다시 처리하는 부분 문제는 호출하지 않는다.
분할 후 한쪽 정렬이 끝났으면 이후에는 정렬을 할 필요(부분 문제 반복 X)가 없다고 생각하면 된다.
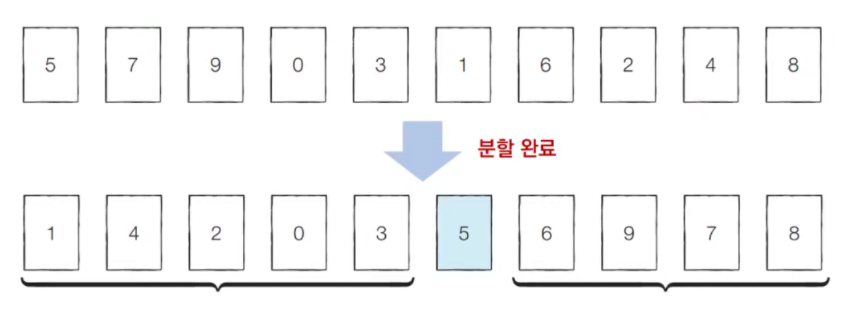
사진 출처 : 링크
TIP
-
주어진 문제가 DP 유형인지 파악하는 것이 중요
- 먼저 그리디, 시뮬레이션, 완전탐색 등의 알고리즘으로 문제를 풀 수 있는지 검토한 후 풀 수 없다고 생각이 들면 DP를 사용해보자!
-
수열은 배열이나 리스트로 표현할 수 있다고 했는데, 메모이제이션은 때에 따라서 다른 자료형, 예를 들어 딕셔너리 자료형을 이용할 수도 있다. --> 사전 자료형은 수열처럼 연속적이지 않을 때 유용하다.
-
DP를 사용할 때, 일단 단순히 재귀 함수로 비효율적인 프로그램을 작성한 뒤에 (Top-Down) 작은 문제에서 구한 답이 큰 문제에서 그대로 사용될 수 있으면, 즉 메모이제이션을 적용할 수 있으면 코드를 개선하는 방법도 좋은 방법이다.
- 위의 피보나치 수열의 예제 코드처럼 재귀 함수를 작성한 뒤에 나중에 메모이제이션 기법을 적용해 소스코드를 수정하는 것도 좋다!!
참고 : https://ko.wikipedia.org/wiki/%EB%8F%99%EC%A0%81_%EA%B3%84%ED%9A%8D%EB%B2%95
https://namu.wiki/w/%EB%8F%99%EC%A0%81%20%EA%B3%84%ED%9A%8D%EB%B2%95
https://www.zerocho.com/category/Algorithm/post/584b979a580277001862f182
https://galid1.tistory.com/507
https://freedeveloper.tistory.com/276
https://semaph.tistory.com/16
