
데이터 전처리 (Data preprocessing)
데이터 전처리란?
- 특정 분석에 적합하게 데이터를 가공하는 작업을 의미한다.
- 업무활동이나 현업에서 발생하는 데이터는 분석, 머신러닝(딥러닝)에 적합하지 않은 경우가 많다. 의미 없는 값이 포함되어 있거나, NA값이 존재하거나 수많은 변수는 데이터의 품질을 떨어뜨린다. 이를 방지하기 위한 작업을 의미한다. (실제 현업에서의 데이터는 rough한 경우가 많다고 한다...)
"데이터 과학의 80%는 데이터 클리닝에 소비되고, 나머지 20%는 데이터 클리닝하는 시간을 불평하는데 쓰인다."
- kaggle 창립자 Anthony Goldbloom -
데이터 분석 프로세스
[문제 정의] --> [데이터 수집] --> [데이터 전처리] --> [데이터 분석] --> [리포팅/피드백]

! 데이터를 보는 Insight가 중요하다.
! Accuracy를 높이지 않고 문제를 더 명확하게 하는 것이 더 좋은 프로세스이다.
1. 문제 정의 단계
데이터 분석 프로세스에서 가장 중요한 단계이자 어려운 단계이다. 문제가 제대로 설정되지 않는다면 [문제 정의] 단계로 다시 되돌아오는 경우가 발생한다. 또한 분석 단계에서 내내 방황하다가 성과없이 끝내기 쉽다.
- 분석의 대상, 분석의 목적
- 정의된 문제를 해결하기 위한 구체적인 계획이 수립되어야 한다.
- 문제를 정의할 분야에 대한 비즈니스 지식이 필요하다.
- 모든 사람들이 명료하게 이해할 수 있도록 구체적이여야 한다.
2. 데이터 수집 단계
분석에 필요한 데이터를 찾고 모으는 단계이다. 데이터 엔지니어의 역할이 큰 비중을 차지한다. 데이터의 양이 많다고 좋은 데이터가 아니다. 때때로는 내가 소유하고 있는 데이터가 빅데이터보다 가치있는 경우가 있다.
- 데이터 수집 단계가 어려운 이유는 데이터가 존재하지 않거나, 너무 많기 때문이다.
- 비용과 법적인 문제가 발생할 수 있으니 조심해야 한다.
- 최근 데이터 수집 방법에는 데이터 구매, 실험환경에서 수집(스스로 데이터 생성), 웹 크롤링, open datasets을 활용하여 수집한다.
Open datasets
- 국내 : AI hub , 공공 데이터 포털
- 국외 : UCI Repository , MNIST
- 기타 : Fashion-MNIST , Open Images Dataset , Kaggle
3. 데이터 탐색 및 전처리 단계
가장 많은 노력과 고생이 필요한 단계이다. 전처리 과정없이 수집한 데이터를 바로 분석에 적용하는 경우는 거의 없다. 전처리가 필요한 경우가 대부분이다. 왜냐하면 데이터를 생성할 때 분석을 전제로 데이터를 생성하지 않았기 때문이다.
데이터 탐색 단계는 데이터의 특성을 파악하고 여러 관계를 찾는 단계이다. 여러 관계를 찾아야 하기 때문에 많은 방법이 있을 수 있고 가장 핵심적인 부분 중 하나이다.
<데이터 전처리>
- 분석에 부적합한 구조, 누락된 항목, NA(결측값) 존재 등으로 인해 전처리 과정이 필요하다.
- 노이즈 제거 , 중복값 제거 , 결측값 보정 , 데이터 연계/통합 , 데이터 구조 변경(차원 변경)
- 데이터 벡터화 , outlier detection, Feature Engineering 등이 있다.
<데이터 탐색>
- EDA(Exploratory Data Analysis) - 탐색적 데이터 분석
- 상관 관계 , 분포 확인 , 인과 관계
4. 데이터 모델링 단계
원하는 결과를 도출하기 위해서 예측이든 분류, 회귀를 위한 작업을 진행하는 단계이다. 즉 전처리된 데이터를 관점별로 나누고 쪼개어 본다. 성능을 높이기 위해 parameter 튜닝 작업을 진행하게 된다.
- 많은 비용이 문제가 발생할 수 있다.
- 머신러닝 기법들 (DT, randomForest, SVM, k-NN 등등...)
5. 시각화 및 해석 단계
모델링을 통해 결과가 도출되면 이를 처음 정의했던 문제와 연관시켜 문제를 해결하는 방법을 모색하는 단계이다. 시각화를 통해 도출된 결과를 알아보기 쉽게 표현하고, 이를 근거로 활용할 수 있다.
데이터 속성
Data size
- ~건, 용량(GB...)
- ~ of instances(row)
- ~ of attributes(column)
-> 데이터를 표현할 때에는 위 처럼 표현해야 한다. (ex) 몇 건이 있나 , 몇 GB가 있나 , 몇 개의 행과 열로 이루어져 있나
Data schema(meta info.)
- 데이터베이스의 구조(뼈대)와 제약조건에 관해 전반적인 명세를 기술한 것
- 개체의 특성을 나타내는 속성(Attribute) + 속성들의 집합으로 이루어진 개체(Entity) + 개체들 사이의 관계(Relation) + 지켜야할 제약조건(Constraint) = Data schema
- 쉽게 설명하여, DB내 어떤 구조로 데이터가 어떻게 저장되는가를 나타내는 DB의 구조를 스키마라 한다.
Data types
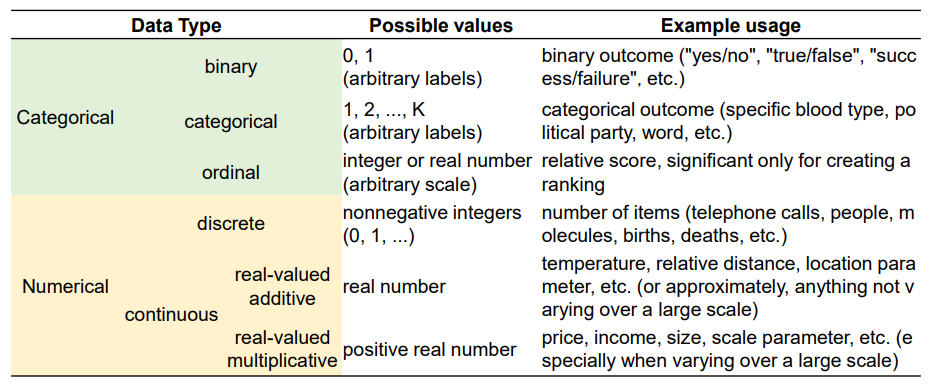
Categorical
- 관측 결과가 몇 개의 범주 또는 항목의 형태로 나타나는 자료형
- 빈도수
- Mode : 빈도수가 가장 높은 Categorical data types
Numerical
- 관측된 값이 수치로 측정되는 자료형
- 평균, 중앙값, 표준편차(std), 최대/최소, 사분위수
Data types (format)
정형 데이터 (Structured data)
데이터베이스의 사전에 정의된 규칙에 맞게 들어간 데이터 중에 수치 만으로 의미 파악이 쉬운 데이터를 의미한다.
- 데이터 스키마 지원 (비정형 데이터는 없다.)
- 스키마 구조를 통해 탐색 가능 -> 스키마 정보를 관리하는 DBMS를 통해 탐색
- (ex) RDBMS의 Tables , 스프레드 시트
비정형 데이터 (Unstructed data)
비정형 데이터는 정형 데이터와 반대되는 단어이다. 비정형 데이터는 형태가 없고, 연산이 불가능한 데이터를 의미한다. 정해진 규칙이 없기 때문에 데이터의 의미를 쉽게 파악하기 힘들다.
- Data set이 아닌 하나의 데이터가 객체화 되어있다.
- 구조화 X -> 이해하기 힘듬
- 이진 파일 형태 데이터이면 종류별로 응용SW를 이용하여 탐색
- script 파일 형태 데이터이면 데이터를 parsing하여 처리
- (ex) 동영상(이진) , 이미지(이진) , 음성 , SNS 데이터의 text(script) , 시계열 데이터
반정형 데이터 (Semi-structed data)
반정형 데이터의 반은 Semi를 의미한다. 즉 완전한 정형이 아닌 약한 정형 데이터이다. 데이터베이스는 아니지만 스키마를 가지고 있는 형태이고, 연산이 불가능한 데이터이다.
- 스키마에 해당하는 메타 데이터가 데이터 내부에 존재
- 데이터 내부에 있는 규칙성을 파악하여 parsing 규칙 적용
- (ex) HTML, XML, JSON, 웹로그, IoT 센서 데이터

일반적으로 데이터베이스는 데이터를 저장하는 장소와 스키마가 분리되어 있어 테이블을 생성, 데이터를 저장하게 된다. 하지만 반정형 데이터는 위 그림처럼 한 txt파일에 column과 value를 모두 출력하게 된다.
