Crawler
- 웹상의 다양한 정보를 자동으로 검색하고 색인하기 위해 검색 엔진을 운영하는 사이트에서 사용하는 SW이다. 스파이더(spider), 봇(bot), 지능 에이전트라고도 한다.
- 사람들이 수작업으로 해당 사이트의 정보를 검색하는 것이 아닌 컴퓨터 프로그램의 미리 입력된 방식에 따라 새로운 웹 페이지를 찾아 종합, 찾은 결과를 이용해 새로운 정보를 찾아 색인을 추가하는 작업을 반복 수행한다.

- Parser : Downloader에서 전송된 HTML 문서를 가공하여 필요한 정보만 추출하여 DB로 전송한다.
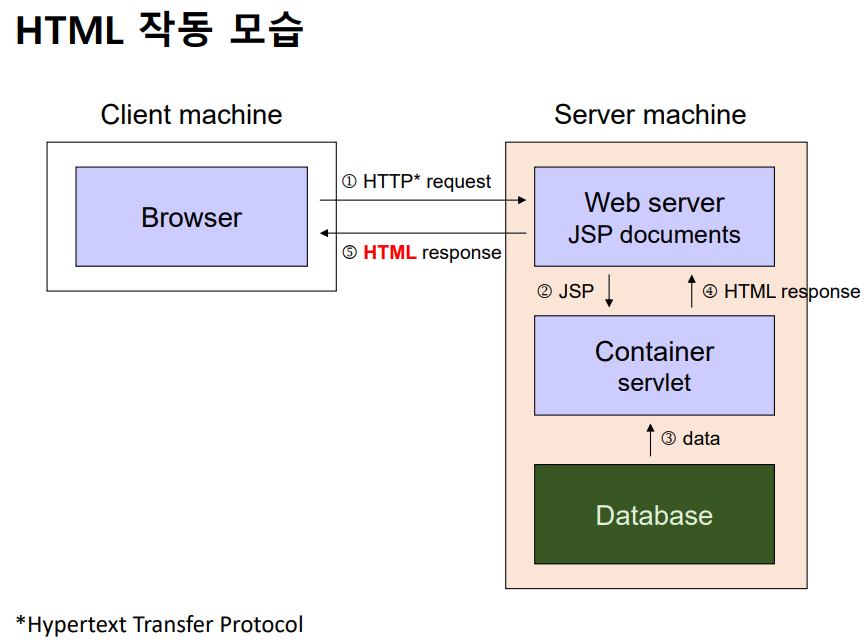
HTML (HyperText Markup Language)
- 하이퍼텍스트를 표기하는 언어 (프로그래밍 언어 X)
- 하이퍼텍스트란? 선형으로 제한되지 않는 텍스트이며, 다른 텍스트에 대한 링크를 포함하는 텍스트이다.
- 웹 브라우저를 통해 번역된다.
- HTML 요소(tag)로 구성되어 있다.
하이퍼링크
- 다른 문서로 연결
<a href="문서 위치">~</a>- 해당 문서 위치로 이동 (ex) www.naver.com이 문서 위치이면 naver로 이동하게 된다.
이미지
- 그림을 문서에 입력
<img src="그림 위치">- 닫는 태그 필요 X
Python Selenium 예제
-
Selenium : 웹 브라우저를 컨트롤하여 웹 UI를 Automation하는 도구 중 하나이다.
-
먼저 Pycharm에 Selenium을 설치해보자.
pip install selenium

- 다음으로 chromedriver를 설치해보자. Download go go
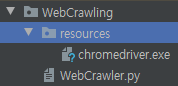
Project안에 하위 디렉토리를 생성하여 그 안에 chromedriver를 설치하였다.
1. open URL
# selenium 모듈에 있는 webdriver 함수 사용
from selenium import webdriver
driver_path = 'resources/chromedriver' # chrome driver 상대 경로
url = 'https://play.google.com/store/apps/top/category/GAME' # 접속할 url 주소
browser = webdriver.Chrome(executable_path=driver_path) # Chrome driver
browser.get(url) # browser 객체에 url 주소 get
browser.quit()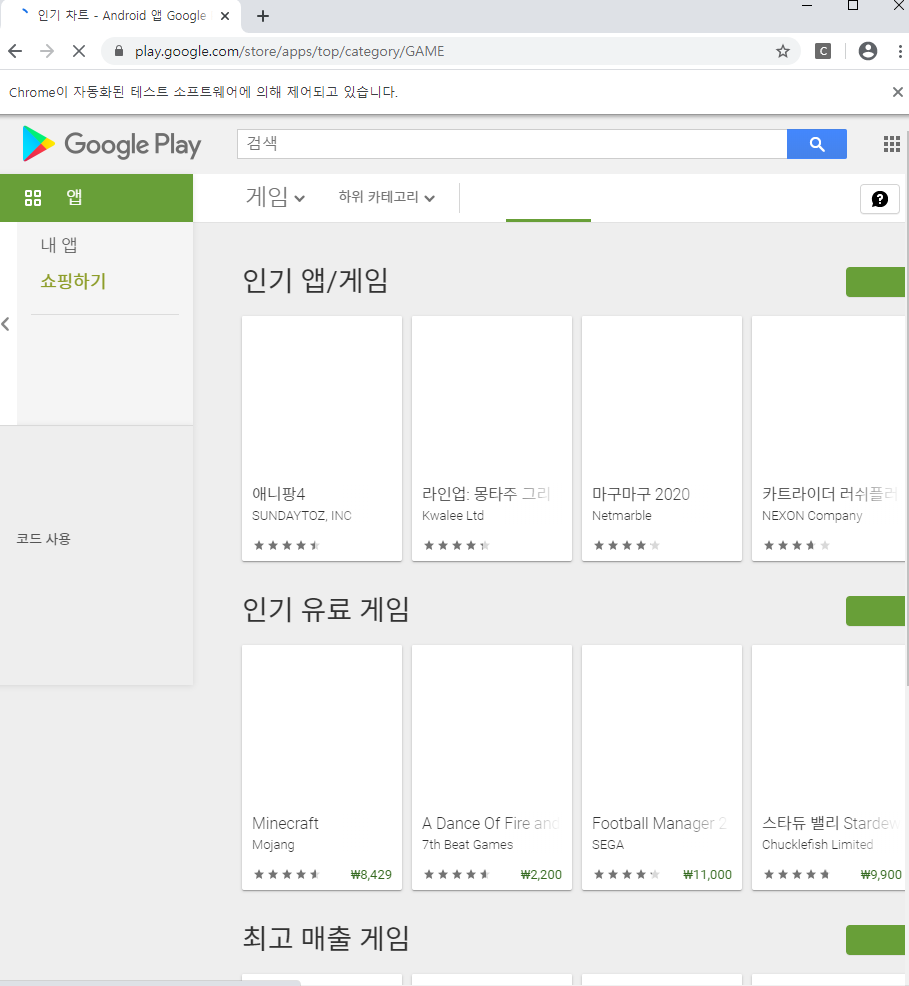
2. open multiple URLs
from selenium import webdriver
driver_path = 'resources/chromedriver'
urls = [
"https://play.google.com/store/apps/category/GAME_EDUCATIONAL",
"https://play.google.com/store/apps/category/GAME_WORD",
]
browser = webdriver.Chrome(executable_path=driver_path) # Chrome driver
for url in urls:
browser.get(url)
browser.quit()for문을 이용하여 urls 안에 있는 주소로 반복 접속한다.
Python Beautifulsoup 예제
- BeautifulSoup : HTML 코드를 Python이 이해하는 객체 구조로 변환하는 Parsing을 맡고 있으며, 이 라이브러리(모듈)을 통해 의미있는 정보를 추출할 수 있게 된다.
- BeautifulSoup를 설치해보자
pip install beautifulsoup4
3. Beautiful soup test
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# html_doc의 내용을 html 코드로 변환하고 Python의 객체 구조로 변환
soup = BeautifulSoup(html_doc, 'html.parser')
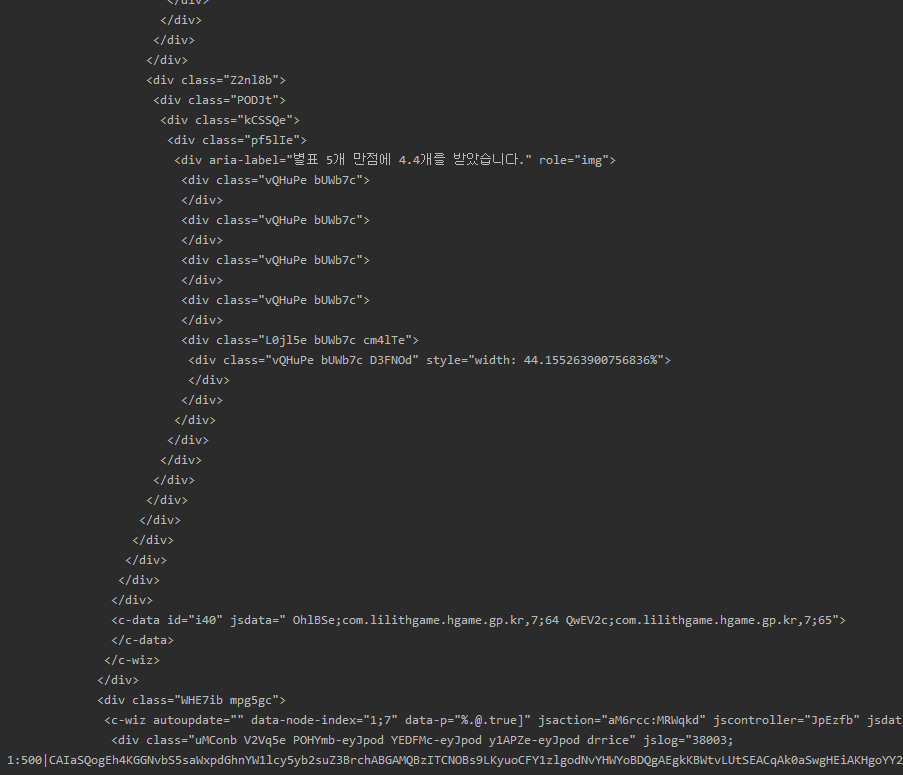
print(soup.prettify()) # html 코드를 보기 편하게 출력4. parse top game charts
from selenium import webdriver
from bs4 import BeautifulSoup
driver_path = 'resources/chromedriver'
url = 'https://play.google.com/store/apps/top/category/GAME'
browser = webdriver.Chrome(executable_path=driver_path)
browser.get(url) # 처음 chrome브라우저를 통해 url 주소로 접속
page = browser.page_source # page 변수에 url 주소 저장
browser.quit()
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify()) 실행 결과

Computer Science!!