데이터 전처리 시리즈에 있는 Web Crawling 글과 겹치는 부분이 많습니다. 코드에 대한 복습도 진행할 겸 Python 라이브러리인 requests, selenium, Beautifulsoup에 대해 다시 공부하는 시간을 가져보도록 하겠습니다.
Requests
- HTTP Request를 웹 브라우저가 아닌 Python에서 모듈로서 가능하게 해주는 모듈이다.
- 즉, Python에서 HTTP 관련된 작업을 편리하게 할 수 있도록 해주는 모듈이다.
- 동적 페이지 요소를 처리하지 못한다. (selenium 모듈이 requests 모듈의 단점을 보완해준다.)
HTTP Request란?
chrome 브라우저 기준으로 F12를 누르고 Network탭을 클릭하여 나타나는 항목 중 아무거나 누르고, Headers를 눌러보게 되면 HTTP Request에 대해 한 눈에 볼 수 있다.
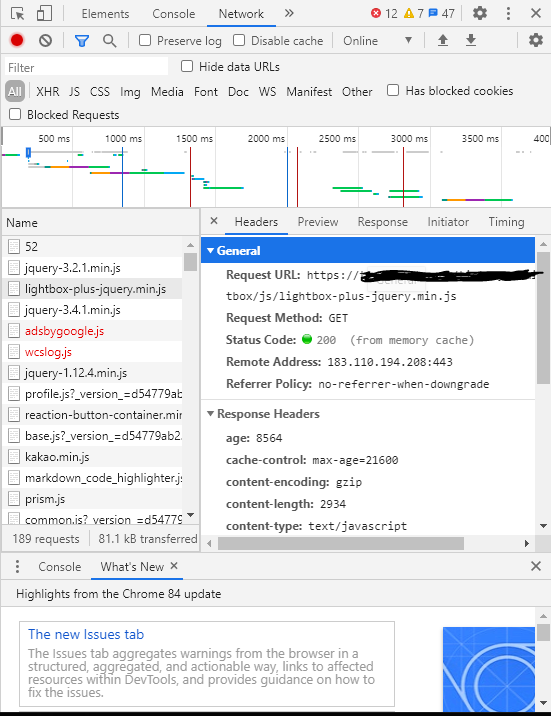
HTTP Request의 종류
보통 우리는 인터넷에 접속해서 페이지를 띄울 때에는 GET 방식을 이용하게 된다. (GET, POST, PUT 등 다양한 방식이 존재하는데 이 부분에 대해서는 추후에 글을 작성하도록 하겠다.)
(ex) https://www.google.com/에 접속한다고 예시를 들어보자.
-
https://www.google.com/의 서버에게 GET 방식으로 요청을 보낸다. (현재 내가 접속했으니 데이터를 불러주세요 라는 요청이라고 생각하면 쉽다.)
-
서버에서는 이에 대한 요청의 응답으로 html 파일을 보내게 된다. (여기 너에게 답장 보낼게~)
-
서버에서 받은 응답을 클라이언트(나)는 웹 브라우저(chrome, safari 등등...)를 통해 웹페이지를 보게 된다. (반드시 웹 브라우저를 사용할 필요는 없다.)
<코드 예제>
import requests
# url 주소에 대한 html 문서를 get 한다는 의미.
# 프로그램을 통해 방문하는 것이 X -> 브라우저를 통해 접속했다고 거짓말 하는 방식
# 여기서는 Mozilla 5.0 브라우저를 통해 방문했다고 거짓말 침
raw = requests.get("http://147.46.178.16:33333/table.html", headers={'User-Agent':'Mozilla/5.0'})
print(raw.text)이 주소로 들어가게 된다.
Requests & BeautifulSoup
- 이 부분을 참고하면 되겠다.
수업에서 배운 코드를 작성하였다.
<코드 예제>
import requests
raw = requests.get("http://147.46.178.16:33333/table.html", headers={'User-Agent':'Mozilla/5.0'})
from bs4 import BeautifulSoup
html = BeautifulSoup(raw.content, "html.parser", from_encoding='utf-8')
# print(html) # html 문서 전부 출력
print(html.select_one("tr th")) # 해당하는 첫번째줄 태그만 추출
print(html.select_one("tr th").text) # 태그안의 텍스트만 추출
print(html.select_one("tr th").get('class'))
result = html.select("tr td")
# tr 태그의 자식 태그들 중 td인 것들만 추출
for r in result:
print(r.string)
print(r.text)requests 모듈을 통해 url 주소를 불러오고, BeutifulSoup 모듈을 이용하여 Crawling을 수행하였다.
string vs text
-
.string : 태그 하위에 문자열을 객체화한다. -> 문자열이 없으면 None을 반환하여 정확한 parsing이 가능하다. (빈 것들을 지나치지 않고 None으로 반환시켜줌)
(ex) 요일, None, PM10, None -
.text : 하위 자식태그의 텍스트까지 문자열로 반환한다. (유니코드 형식 , 빈 것들을 생략하고 존재하는 text만 반환)
(ex) 요일, PM10
위 예제코드를 이해하려면 HTML 문서의 문법을 알아야한다. 예시를 통해 간단하게 설명하고자 한다.
예시 이미지의 url입니다.
(ex)
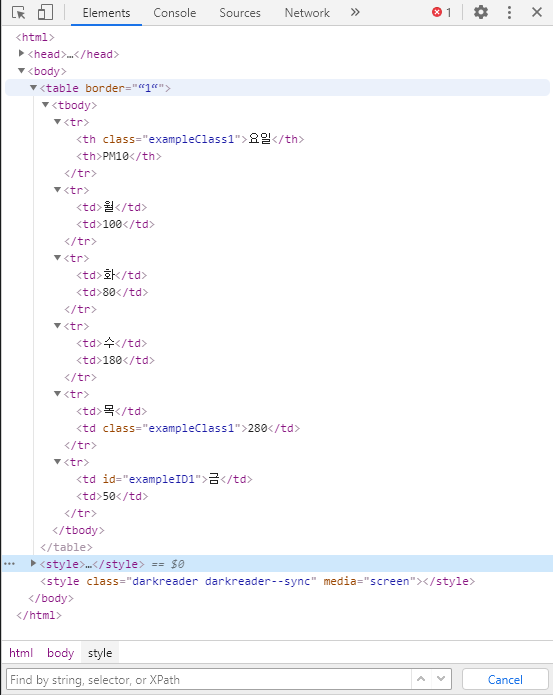
Tag
- Tag는 웹문서(HTML)에 어떤 표시를 해주는 것이라고 생각하면 된다.
- HTML의 문서의 뼈대로, HTML 문서는 여러 태그들로 구성되어 있다.
- Tag는 <>형태로 이루어져 있다. 위 그림을 보면 <>안에 tbody, tr, th 등이 있는 것을 볼 수 있다. 이 것들을 tag라고 부른다.
Class
- HTML 문서의 선택자이다.
- 그룹으로 묶어서 스타일(css)을 지정할 때 쓰는 이름이다.
- 표시는 .이름 으로 표현한다.

앞에 점이 존재하는데, class의 이름이 "exampleClass1"인 것을 찾아줘 라는 의미이다. selector를 통해 찾을 수 있다.
id
- HTML 문서의 선택자이다.
- 한 가지만 지정해서 스타일(css)을 적용할 때 쓰는 이름이다.
- ★class와 다르게 하나의 문서에 고유한 id 하나만 사용할 수 있다.
- 표시는 #이름으로 표현한다.

앞에 #이 존재하는데, id의 이름이 "exampleID1"인 것을 찾아줘 라는 의미이다. 위와 같이 selector를 이용하였다.
OR (또는)

, 를 태그나 class, id 사이에 사용하면 된다. 여기서는 태그명이 th이거나 td인 것을 모두 찾아줘 라는 의미이다.
AND (그리고)

태그나 class, id를 바로 붙여서 쓰게 되면 그리고 라는 의미이다. 여기서는 th 태그명을 가지고 있고 그리고 class명이 "exampleClass1"인 것을 찾아줘 라는 의미이다.
Space (공백)

태그 사이에 공백(space)를 쓰게 되면 부모-자식간의 관계를 찾아줘 라는 의미이다. 여기서는 tr태그의 하위 태그(자식 태그)가 td인 것을 찾아줘 라는 의미이다.
Selenium
- 동적 페이지를 활용하지 못하는 requests의 단점을 selenium의 모듈을 이용하여 극복해보자.
- Python에서 동적 페이지를 활용하거나 javascript를 활용하여 작업을 할 때에는 Selenium을 사용하는 것이 좋습니다.
from selenium import webdriver
path = 'resources/chromedriver'
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
wd = webdriver.Chrome(executable_path=path, options=options)
wd.get("http://147.46.178.16:33333/javascript.html")
# 난수 생성이 안된 상태
print(wd.page_source)
print("----------------------------------")
# body 태그의 자식 태그들 중 태그명이 a인 태그들 중에서 제일 첫번째 a 태그를 click 해줘
# -> 웹에서의 난수 생성기 버튼 클릭으로 난수를 생성하기 위한 Python코드
wd.find_element_by_css_selector("body a").click()
print(wd.page_source) # 난수 생성이 되었고, 난수들의 정보를 추출할 수 있음
selenium 모듈을 활용하여 웹에서의 난수 생성기에서 생성된 난수들의 정보를 추출할 수 있습니다.
네이버 블로그 페이지에서 id, 제목, 공감 크롤링하기
from selenium import webdriver
import time
path = 'resources/chromedriver'
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
wd = webdriver.Chrome(executable_path=path, options=options)
# 1페이지 ~ 5페이지까지 크롤링을 진행
for i in range(1, 6):
wd.get("https://section.blog.naver.com/BlogHome.nhn?directoryNo=0¤tPage=" + str(i) + "&groupId=0")
# time.sleep() 코드를 안넣어주면 중간에 웹 크롤링이 종료된다.
# 동기화 문제인건가... 정확히 어떤 문제인지 알아보아야 겠다.
time.sleep(2)
boxes = wd.find_elements_by_css_selector("div.info_post") # 블로그 글 1개의 레이아웃 부분
for box in boxes:
try:
try:
replies = box.find_element_by_css_selector(".reply em").text
except:
replies = "0"
title = box.find_element_by_css_selector(".title_post").text
authors = box.find_element_by_css_selector(".name_author").text
print(replies + "\t" + title + "\t" + authors)
except:
print("에러 발생")
print(end="\n\n")
