Python Beautifulsoup 예제2
- BeutifulSoup : HTML 코드를 Python이 이해하는 객체 구조로 변환하는 Parsing을 맡고 있으며, 이 라이브러리(모듈)을 통해 의미있는 정보를 추출할 수 있게 된다.
여기에 이어서 예제를 살펴보겠습니다.
3-1. Navigate structures
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# html_doc의 내용을 html 코드로 변환하고 Python의 객체 구조로 변환
soup = BeautifulSoup(html_doc, 'html.parser')
# print(soup.prettify())
# 3-1. navigate structures
tag = soup.a # soup 객체의 a 태그를 저장
print(tag) # a tag 한줄 전체 -> <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
print(tag.name) # a tag 의 이름 -> a
print(tag.attrs) # a tag 의 속성 -> href 값, class 값, id 값
print(tag.string) # a tag 제외한 웹에서 출력되는 실질적인 내용 -> Elsie
print(tag['class']) # a tag 의 class 값 -> sister
print(soup.title) # soup 객체의 title tag 전체
print(soup.title.name) # soup 객체의 title tag 의 이름 -> title
print(soup.title.string) # soup 객체의 title tag 제외한 웹에서 출력되는 실질적인 내용 -> The Dormouse's story
print(soup.title.parent.name) # soup 객체의 title tag 의 부모 tag 의 이름 -> head
print(soup.title.parent.title.name) # soup 객체의 title tag 의 부모 title tag 의 이름 -> title
print(soup.head.contents[0].string) # soup 객체의 head tag 자식의 0번째의 내용 -> The Dormouse's story
print(soup.p) # 많은 p tag 들 중에서 무조건 첫번째로 나오는 tag 만 추출
print(soup.p['class'])
print(soup.a)
print(soup.find_all('a')) # soup 객체의 a tag 전부 추출
print(soup.find(id='link3'))
print(soup.find(id='link3').string)
# 반복문으로 a tag의 href 값 전부 추출
for link in soup.find_all('a'):
print(link.get('href')) # 위 아래 결과 같음
print(link['href'])
print(soup.get_text()) # soup 객체에서 웹에서 실질적으로 출력되는 내용들만 추출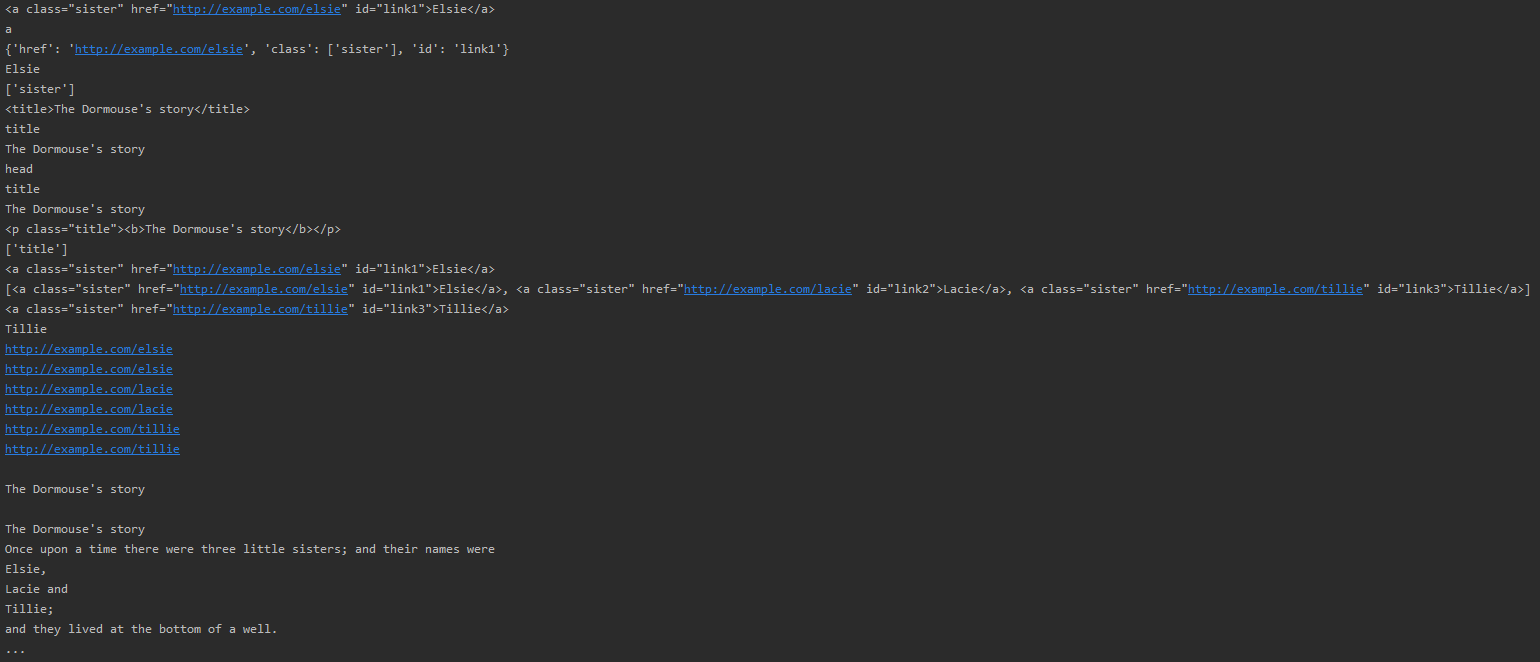
5. Extract links to game ranks
구글의 플레이스토어에서 인기있는 게임앱 목록의 웹을 Python에서 open 하는 코드입니다.
from selenium import webdriver
from bs4 import BeautifulSoup
driver_path = "resources/chromedriver"
url = "https://play.google.com/store/apps/top/category/GAME"
browser = webdriver.Chrome(executable_path=driver_path)
browser.get(url)
page = browser.page_source
soup = BeautifulSoup(page, 'html.parser')
links = soup.find_all('div', {'class':'W9yFB'}) # div 클래스의 자식들 중에서 class="W9yFB" 인 것에서 game ranks 추출 가능
for link in links:
new_url = link.a['href']
print('https://play.google.com' + new_url)
browser.get('https://play.google.com' + new_url)
browser.quit()

Computer Science!!