
spark에 조인 종류가 많다?
spark를 다루다가 spark.explain으로 plan을 살펴보면 shuffle-sort-merge-join이라는 걸 볼 수가 있다. 이 join은 언제 일어나는 것이고 다른 join들에는 어떤 것들이 있을까하는 궁금증에 구글링을 해보았고 이를 토대로 정리를 해보려고 한다.
들어가기에 앞서 hash join이란?
돌아다니다가 유튜브를 발견했는데, 이보다 더 hash join을 더 잘 설명해주는 걸 본 적이 없었다. hash join이전에 nested loop join과 merge join을 이해하면 왜 hash join이 위대한지를 알 수 있는데, 천천히 알아보자.
nested loop join
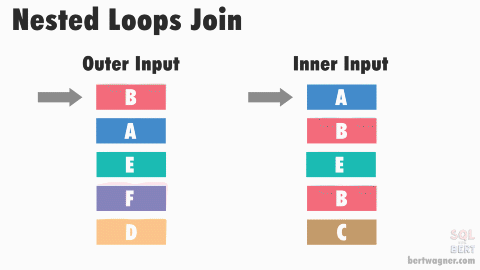 위 그림 링크
위 그림 링크
아주아주 무식하면서 심플한 방법이다. 위 그림처럼 왼쪽 테이블과 오른쪽 테이블을 조인한다고 생각해보자. nested loop join은 왼쪽 테이블의 첫번째 row의 join key값을 들고 오른쪽 테이블의 처음부터 마지막 row까지 돌면서 동일한 key 값이 있으면 매칭한다. 그 다음에는 왼쪽 테이블의 두번째 row의 key값을 들고 오른쪽 테이블을 전수조사하는 방식이다. 이런 식으로 하다보면 O(T1 * T2)만큼의 시간이 걸리는 비효율적인 방식인 셈이다.
merge join
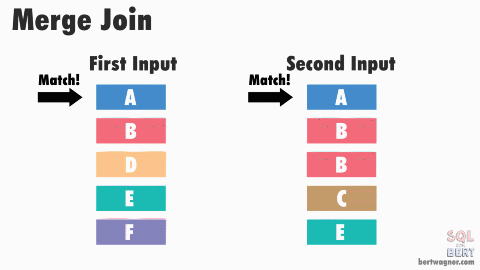 위 그림 링크
위 그림 링크
merge join은 조금의 트릭을 쓴 조인이다. 매칭을 시작하기 전에 양 테이블을 키값을 기준으로 소팅을 한다. 매칭 로직은 nested loop join과 동일하게 시작한다. 왼쪽 테이블의 A값을 들고 오른쪽 테이블의 첫번째 row부터 살펴본다 매칭되는 애가 있으면 매칭을 시키고 다음 row로 넘어간다. 이를 반복하다가 다른 key값이 나오면 멈춘다. 왜냐하면 이미 소팅이 되어있기 때문에, 뒤에는 같은 key값이 없을 것이기 때문이다. 그럼 다음 key값인 B를 들고 오른쪽 테이블의 (중요) 처음부터가 아니라 아까 멈춘 곳부터 매칭을 시작한다. 이도 마찬가지로 미리 소팅되어 있기 때문에 이 전의 row에는 같은 key값이 있을 수 없다! 이런 식으로 하다보면 O(T1logT1 + T2logT2)만큼의 시간이 걸린다고 볼 수 있다.
hash join
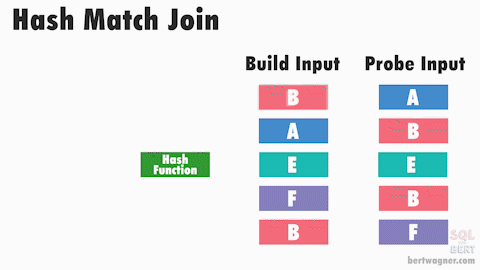
위 그림 링크
hash join은 이름에서도 알 수 있듯이 hash function을 사용하기 때문에 hash가 붙은것이다. 왼쪽테이블의 모든 key값을 hash function을 통과시켜 hash 테이블에 배치한다. 그러면 동일한 key값은 동일한 hash 버킷에 들어갈 것이다. 물론 collision이 일어날 수도 있는데, 그렇다고 오류가 생기지는 않는다. 이 방식으로 왼쪽 테이블을 모두 hash 테이블에 뿌린 후에 동일한 방식으로 오른쪽 테이블에 동일한 hash function을 적용해보자. 새로운 hash 테이블의 버킷에 오른쪽 테이블의 row가 들어갈텐데, 미리 만들어둔 hash 테이블 버킷에 들어있는 key값과 동일하다면 매칭시킨다. 이 방식으로 오른쪽 테이블의 모든 row를 매칭시킨다. hash function은 O(1)의 시간이 들 것이고, collision이 일어나지 않는 상황을 가정한다면 O(T1 + T2)만큼의 시간이 걸릴 것이다.
broadcast hash join
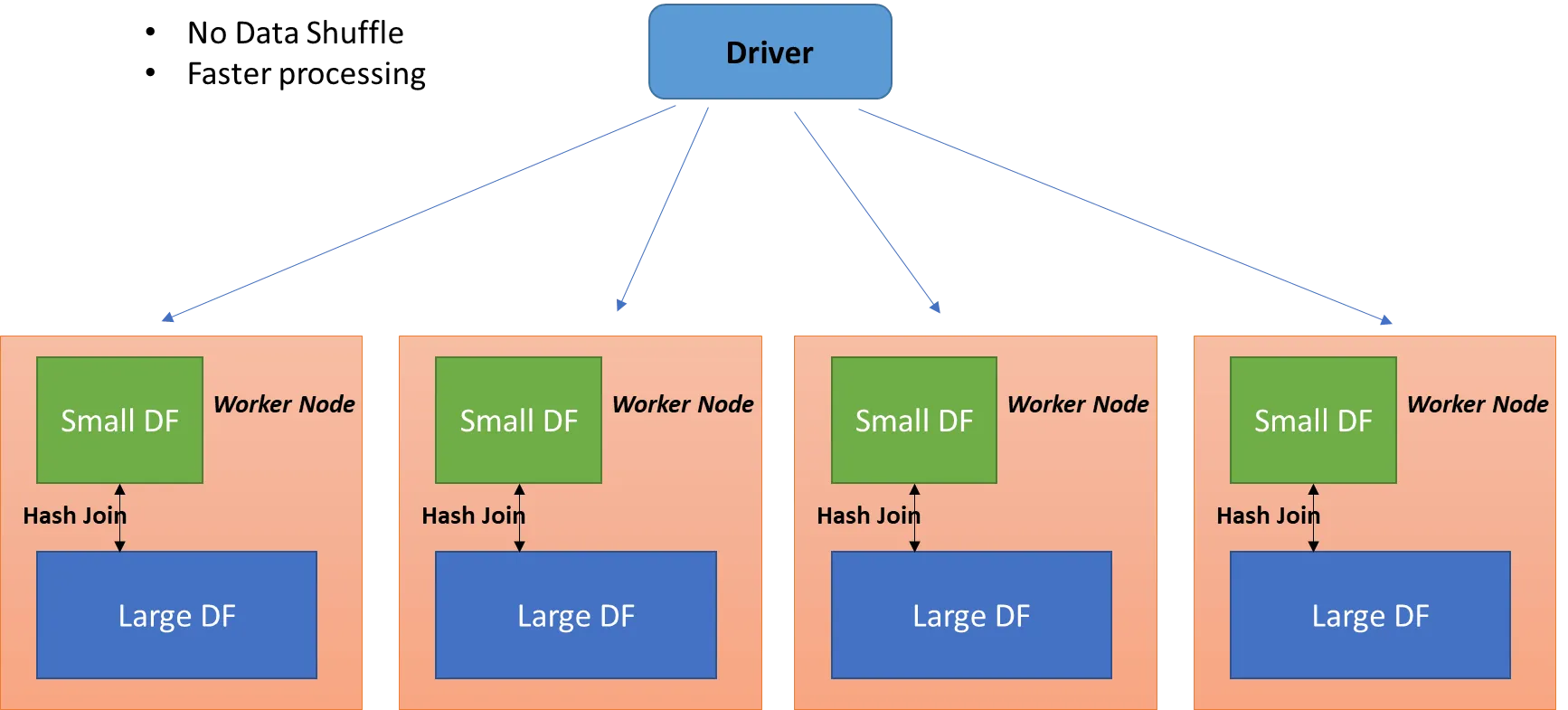
브로드캐스트 해시 조인은 한 테이블이 충분히 작을 때 사용이 가능하다. 여기서 충분히 작다는 뜻은 스파크의 드라이버 노드에 올릴 수 있을 정도여야하고 드라이버로부터 워커노드에 모두 뿌릴수(broadcast) 있을 수 있을 정도로 작아야한다는 뜻이다. 작은 테이블을 드라이버로부터 각 executor로 뿌린다. 각 executor에서는 파티셔닝된 DF와 드라이버로부터 받은 작은 테이블을 위에 설명한 hash join을 한다.
shuffle hash join

이는 브로드캐스트 해시 조인을 할 수 없을 때 사용할 수 있는데(즉 두 테이블 모두 충분히 작지 않은 상황), join key값에 따라서 셔플링을 한다. 셔플링을 하게 되면 같은 key값을 가진 두 테이블의 row들은 동일한 executor에 배치가 되는 결과를 얻을 수 있다. 그 이후에 각 executor내에서 두 DF에 대해 hash join을 수행한다.
shuffle sort merge join
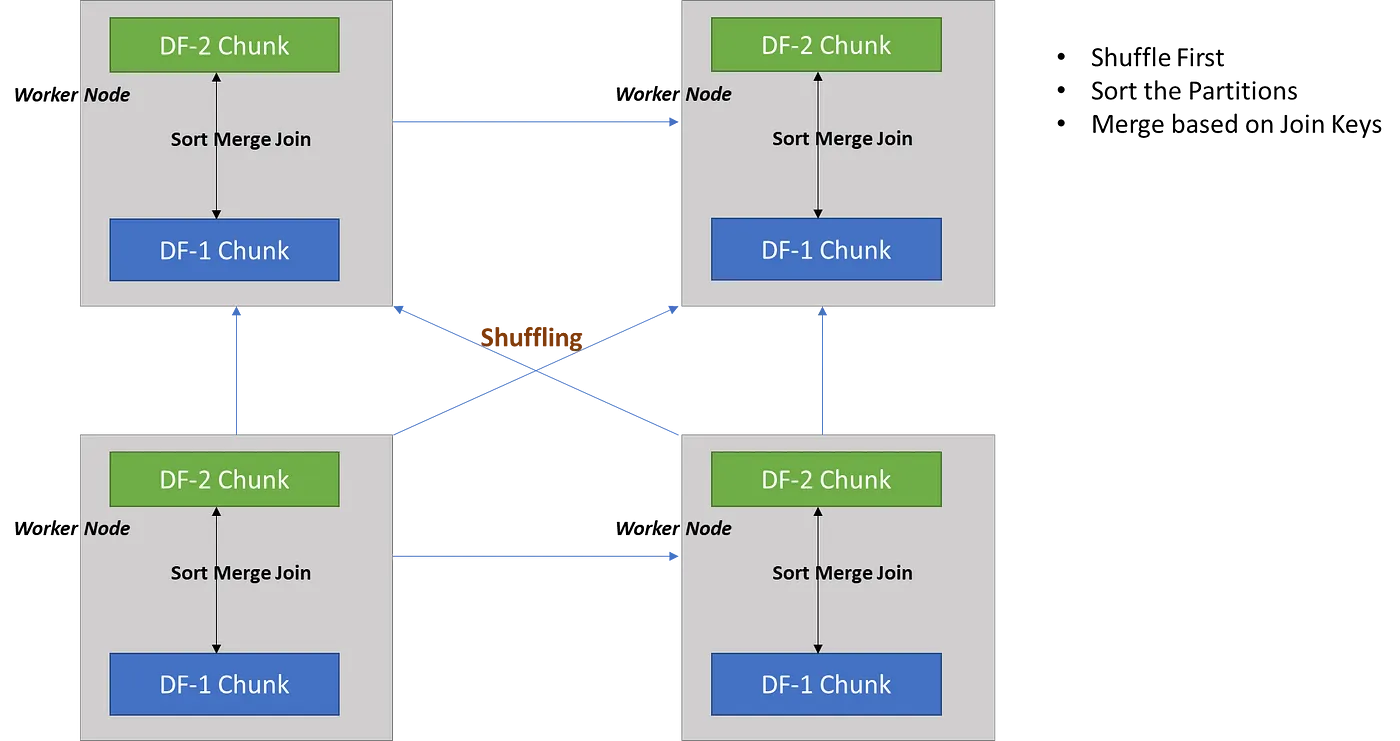
이는 위와 마찬가지로 join key값에 따라서 셔플링을 통해 executor에 DF를 배치를 한다. 그 이후에 sort merge join을 하는 방식이다.
- 참고자료
https://yeo0.tistory.com/entry/Spark-BroadCast-Hash-JoinBHJ-Shuffle-Sort-Merge-JoinSMJ
https://medium.com/@ghoshsiddharth25/apache-spark-join-strategies-deep-dive-26bf7e85db28
https://mjs1995.tistory.com/227
https://medium.com/@ghoshsiddharth25/apache-spark-join-strategies-deep-dive-26bf7e85db28
