
앞의 포스트에서도 얘기가 나왔지만 대용량의 데이터를 시뮬레이션을 위해서 시계열 순으로 순차적으로 저장해야할 일이 있었다. 오늘은 어떻게 저장을 했는지에 대해서 알아보자. 대용량의 데이터를 아래의 조건을 가진 채로 적재를 해보자. (이번 포스팅까지 시간이 오래걸렸는데, 내부적으로 돌아가는 것을 리서치하고 확인하는데 오래걸렸기 때문이다..ㅠ)
- 날짜 파티션인 p_dt, 시간 파티션인 hh로 디렉토리를 구분해서 저장을 해야할 것.
- 각 파티션 디렉토리안에서는 col1, col2, col3 순으로 저장을 할 것.
설계
여기서 처음 생각한 것은 이렇다. p_dt,hh에 맞춰서 파티셔닝을 한 후(이 경우에는 24개의 파티션으로 나누는 것을 의미한다.) 각 파티션 내에서 소팅을 작업하고 각 executor가 담당한 hh에 맞춰서 적재를 하면 되지 않을까? 아래의 순서대로 코드를 보고 무엇이 문제가 되었는지 확인해보자.
첫번째 방법
res_df.repartition("p_dt","hh")\
.sortWithinPartitions('col1','col2','col3')\
.write\
.partitionBy("p_dt","hh")\
.option("compression", "gzip")\
.option("delimiter", ",")\
.mode('overwrite')\
.csv("/path")여기서 문제가 있는데, 우선 repartition메소드는 설정값을 지정해주지 않으면 디폴트(200)의 파티션으로 나눈다는 것이다. 그럼 이게 왜 문제가 될까? 그 이유는 맨 처음에 설계한대로 하려면 200개가 아니라 24개의 파티션으로 나누지 못하기 때문이다. 이 부분은 결과만 보면 크게 문제가 생기진 않지만 처음에 설계한 대로 맞춰서 진행해보자.
두번째 방법
res_df.repartition(24,"p_dt","hh")\
.sortWithinPartitions('col1','col2','col3')\
.write\
.partitionBy("p_dt","hh")\
.option("compression", "gzip")\
.option("delimiter", ",")\
.mode('overwrite')\
.csv("/path")이렇게 했을 때 문제가 없어보인다. 하루는 24개의 시간으로 이루어져있고, 각각에 맞춰서 hh가 알아서 들어갈 것이기 때문이다. 그런데 실제로 코드를 돌려보면 24개의 태스크(파티션)가 실행될 때, 4~5개의 태스크만 오래 걸리는 것을 확인할 수 있다. 이건 뭘 의미하는 걸까? 실제로 스파크 실행 UI에 들어가서 각 executor가 각각 얼마나 많은 양을 처리하는지 살펴보면 0바이트인 executor들이 많은 걸 확인할 수 있다. 이는 repartition이 우리가 의도한대로 동작하지 않았다는 뜻이다. spark_partition_id 메소드를 통해서 파티션 아이디를 확인할 수 있는데(dataframe에 withColumn로 파티션 아이디만을 담아서 show로 확인해보자 stackoverflow참고), 다른 hh임에도 같은 파티션 아이디가 들어가 있는 것을 확인할 수 있다. 이건 어찌보면 당연한 일인 것 같다. 하나의 executor에서 다 처리할 수 있는데, 굳이 여러개의 executor를 쓸 필요가 있을까? 하지만 나는 설계한대로 하고 싶다는 굳은 의지로 다른 방법을 찾아냈다.
세번째 방법
res_df.repartitionByRange(24,"p_dt","hh")\
.sortWithinPartitions('col1','col2','col3')\
.write\
.partitionBy("p_dt","hh")\
.option("compression", "gzip")\
.option("delimiter", ",")\
.mode('overwrite')\
.csv("/path")repartitionByRange를 사용하면 col의 오름차순으로 파티션을 생성한다. 여기서는 하나의 파티션에 하나의 hh만 가지게 하는 것이다.(hh=00이면 0번 파티션, hh=01이면 1번 파티션... 그런데 찾아보니 데이터 크기가 작으면 마찬가지로 하나의 executor에 다른 hh값이 들어갈 수도 있다고 한다. 더 확실하게 하려면 executor메모리 값을 간당간당하게 해서 두개 이상의 값은 가지지 못하게 하는 것도 방법일 것 같다. stackoverflow참고) 이는 우리의 설계대로이다. 이렇게 오름차순으로 되는 것이 중요하다. 그 이유는 결국 csv로 저장할 때 part-xxxxx_의 형태로 저장이 될것인데, xxxxx가 파티션 넘버를 의미하기 때문이다. 만약 오름차순이 아니라 뒤죽박죽으로 저장하게된다면 part-00001, part-00002 순으로 col이 소팅되지 않을 것이다. 물론 각 파일안에서는 소팅이 되어있겠지만 기왕이면 파일간에도 소팅이 되는 게 좋지 않겠나? 그런데도 문제가 있다.(이 부분이 찾는데 시간이 좀 오래 걸렸다.)
결과물이 참고와 같이 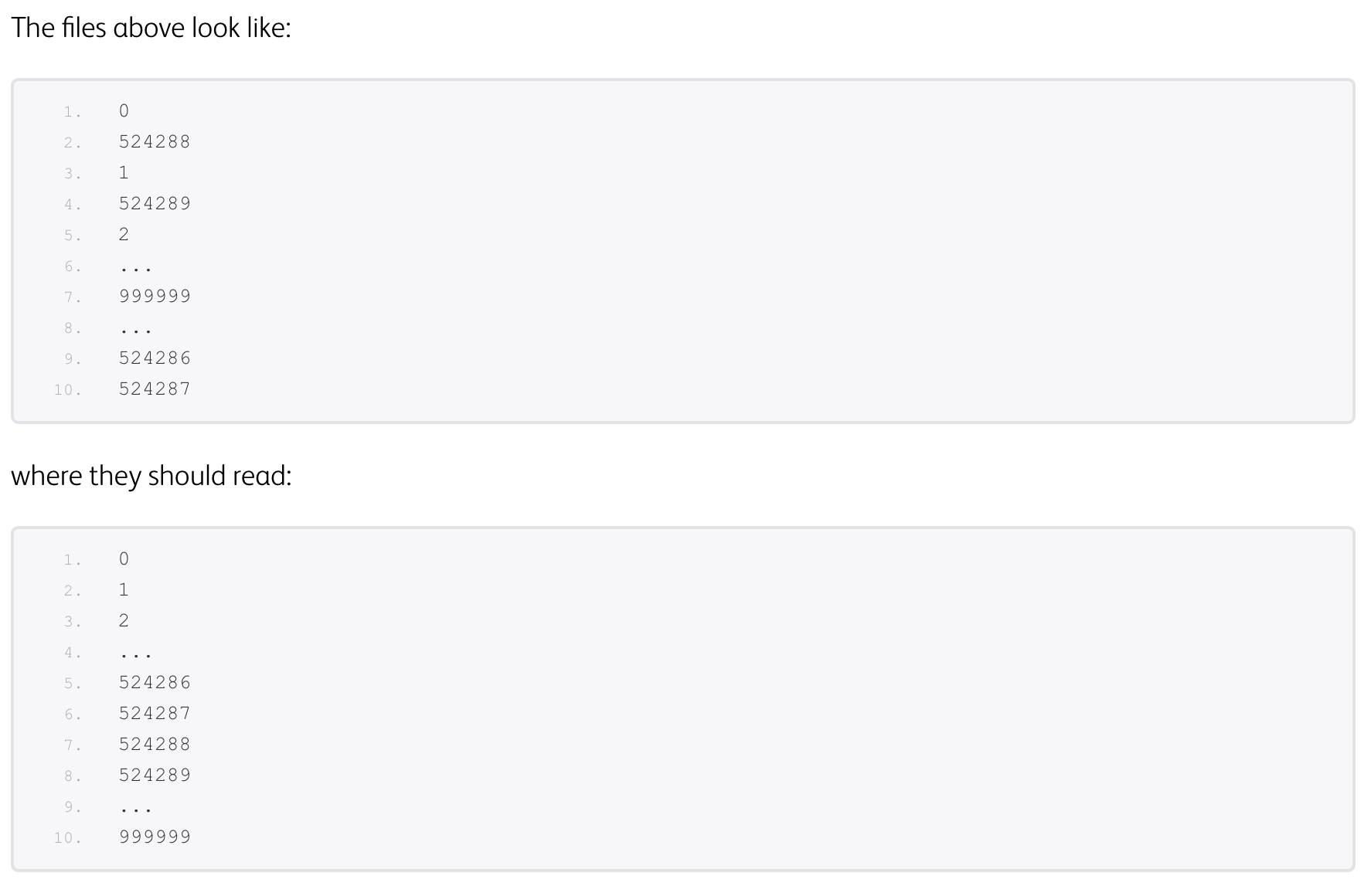 이런식으로 나온다. 이는 확실히 잘못되었다. 나의 경우에도 col1이 순서대로 1,2,3이 된 것이 아니고 1, 50000, 2, 50001... 식으로 소팅이 되어 저장이 된 것이다. 이는 왜 그렇고 어떻게 해결할 수 있을까..
이런식으로 나온다. 이는 확실히 잘못되었다. 나의 경우에도 col1이 순서대로 1,2,3이 된 것이 아니고 1, 50000, 2, 50001... 식으로 소팅이 되어 저장이 된 것이다. 이는 왜 그렇고 어떻게 해결할 수 있을까..
네번째 방법
res_df.repartitionByRange(24,"p_dt","hh")\
.sortWithinPartitions('col1','col2','col3')이 부분에 partition_id를 추가한 후 show로 살펴보자. 우선 각 파티션내에 col1, col2, col3끼리는 아주 잘 소팅이 되어있다... 그럼 이 부분은 문제가 아니라는 것인데.. 구글링을 해보니 위와 같은 현상은 spill이 일어나서 생기는 것이었다. 결과값을 자세히보면 홀수 인덱스끼리만 살펴보면 1,2,3... 이고 짝수 인덱스끼리 살펴보면 50001,50002와 같이 되어있다. 그렇네..! 그럼 write와 partitionBy에서 생긴 문제인 것이다.(정확히는 partitionBy때문이겠지..) spill에 대해서는 정확히 알고 있지 않지만, 데이터 모두를 executor 메모리에 올릴 수 없을 정도로 크게 되면 발생하는 것으로 알고 있다. 그런데 이를 sorting을 통해서 나눈다고... 그래서 위와 같은 문제가 발생했던 것이다. 그럼 executor메모리를 무조건적으로 키워야하나..? 그것말고는 방법이 없는 것일까..? 라고 구글링을 어마무시하게 했더니 한 줄기 빛을 발견했다. 위 현상이 일어나는 이유는 스파크의 write가 구현된 방식때문이었는데, write를 할 때 값을 앞의 내가 소팅한 방식대로 제대로 지정해주지 않으면 지맘대로 소팅을 한다는 것이었다. 스파크는 아래의 정렬을 필요로한다.
requiredOrdering = partitionColumns ++ bucketIdExpression ++ sortColumns
여기서 partitionColumns가 내가 sortWithinPartitions에 해당하는 것이고 bucketIdExpression, sortColumns은 해당사항없다. partitionBy를 할 때 나는 "p_dt", "hh"에 대해서 해서 스파크가 파티션들이 "p_dt", "hh"에 대해서 소팅이 되어 있나?를 확인하는데 내가 따로 해주지 않았으니 스파크가 내가 설정한 sorting을 무시하고 맘대로 소팅한것이다.ㅠㅠ 그래서 이를 해결하려면 sortWithinPartitions에 "p_dt", "hh"도 포함시켜야했던 것이다. 그래서 최종적으로 완성한 코드는 아래와 같다.
res_df.repartitionByRange(24,"p_dt","hh")\
.sortWithinPartitions("p_dt","hh",'col1','col2','col3')\
.write\
.partitionBy("p_dt","hh")\
.option("compression", "gzip")\
.option("delimiter", ",")\
.mode('overwrite')\
.csv("/path")(번외) repartition과 partitionBy
stackoverflow를 살펴보면 정확히 이해할 수 있다. repartition은 파티션을 설정하기 위한 메소드이다. 그리고 partitionBy는 각 파티션이 수행할 작업에 대한 것인데, 예를 들면 쉽게 이해할 수 있다. 예를 들어, col1으로 파티션을 6개로 나누자.(각각의 파티션에는 데이터가 있을 수도 있고 없을 수도 있다.) 그 후에 partitionBy로 write를 한다고 했을 때, 이 partitionBy는 각각의 파티션 내부에서 동작한다. 이 때문에 만약에 4개의 유니크 값을 가진 col2에 대해서 partitionBy를 한다고 하면 1번 파티션(executor)이 데이터를 가지고 있다면 최대 4개의 col2 디렉토리에 part-00001로 시작하는 파일을 저장할 것이다. 2~6번 파티션도 모두 동일한 작업을 수행해 각각 part-00002~00006의 파티션을 만들것이다. 그런데 파티션이 꼭 데이터가 들어가 있는 것은 아니니 최대 4x6=24개의 파일을 생성할 것이다. 각 col1에 따라 유니크한 col2의 값의 종류가 차이가 있을 수 있고 파티션에 데이터가 다 있는 것은 아닐 확률이 있으니 이보다 파일 개수가 적을 가능성이 높다.
참고 링크
다음 포스팅 예고
- spill?
